 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for Network Width with Bilaterally Coupled Network
Mar 25, 2022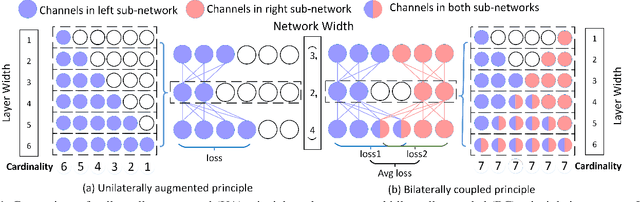
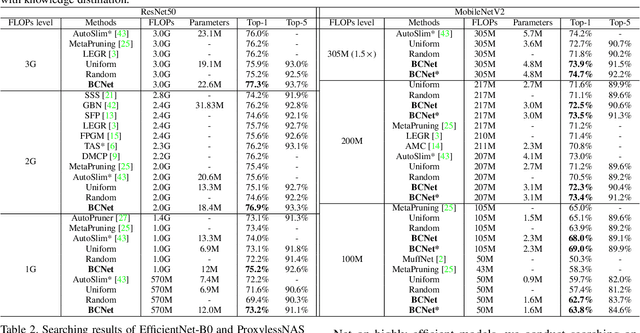
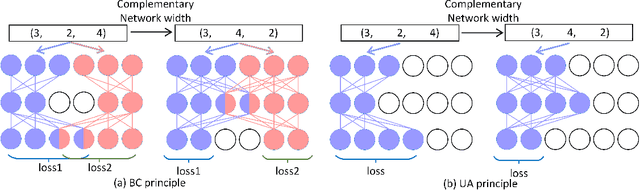
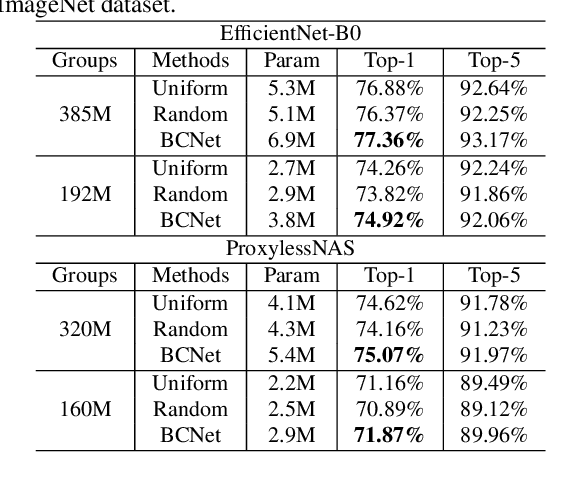
Searching for a more compact network width recently serves as an effective way of channel pruning for the deployment of convolutional neural networks (CNNs) under hardware constraints. To fulfill the searching, a one-shot supernet is usually leveraged to efficiently evaluate the performance \wrt~different network widths. However, current methods mainly follow a \textit{unilaterally augmented} (UA) principle for the evaluation of each width, which induces the training unfairness of channels in supernet. In this paper, we introduce a new supernet called Bilaterally Coupled Network (BCNet) to address this issue. In BCNet, each channel is fairly trained and responsible for the same amount of network widths, thus each network width can be evaluated more accurately. Besides, we propose to reduce the redundant search space and present the BCNetV2 as the enhanced supernet to ensure rigorous training fairness over channels. Furthermore, we leverage a stochastic complementary strategy for training the BCNet, and propose a prior initial population sampling method to boost the performance of the evolutionary search. We also propose the first open-source width benchmark on macro structures named Channel-Bench-Macro for the better comparison of width search algorithms. Extensive experiments on benchmark CIFAR-10 and ImageNet datasets indicate that our method can achieve state-of-the-art or competing performance over other baseline methods. Moreover, our method turns out to further boost the performance of NAS models by refining their network widths. For example, with the same FLOPs budget, our obtained EfficientNet-B0 achieves 77.53\% Top-1 accuracy on ImageNet dataset, surpassing the performance of original setting by 0.65\%.
Relational Self-Supervised Learning
Mar 16, 2022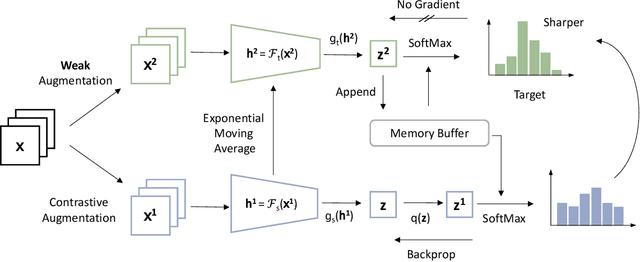
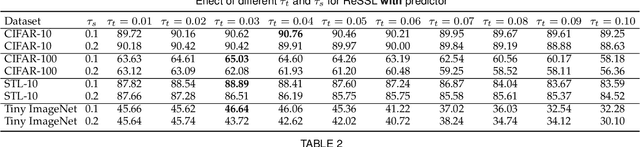
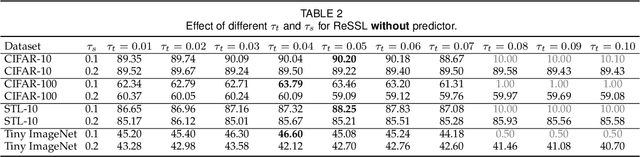

Self-supervised Learning (SSL) including the mainstream contrastive learning has achieved great success in learning visual representations without data annotations. However, most methods mainly focus on the instance level information (\ie, the different augmented images of the same instance should have the same feature or cluster into the same class), but there is a lack of attention on the relationships between different instances. In this paper, we introduce a novel SSL paradigm, which we term as relational self-supervised learning (ReSSL) framework that learns representations by modeling the relationship between different instances. Specifically, our proposed method employs sharpened distribution of pairwise similarities among different instances as \textit{relation} metric, which is thus utilized to match the feature embeddings of different augmentations. To boost the performance, we argue that weak augmentations matter to represent a more reliable relation, and leverage momentum strategy for practical efficiency. The designed asymmetric predictor head and an InfoNCE warm-up strategy enhance the robustness to hyper-parameters and benefit the resulting performance. Experimental results show that our proposed ReSSL substantially outperforms the state-of-the-art methods across different network architectures, including various lightweight networks (\eg, EfficientNet and MobileNet).
A Machine Learning Method for Material Property Prediction: Example Polymer Compatibility
Feb 28, 2022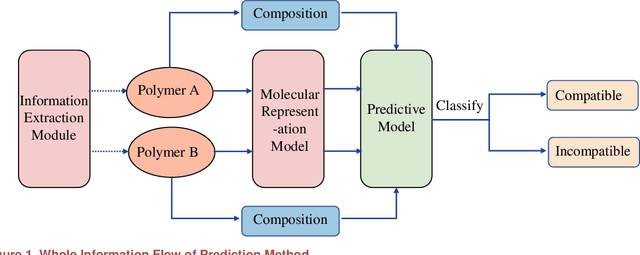
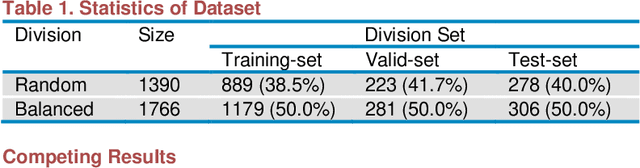
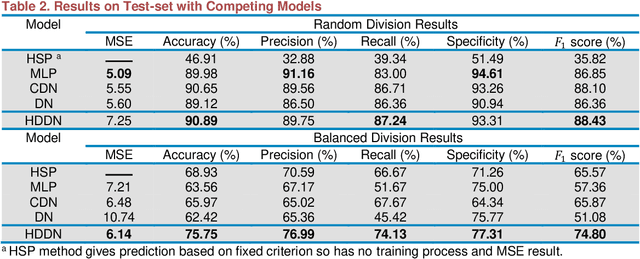
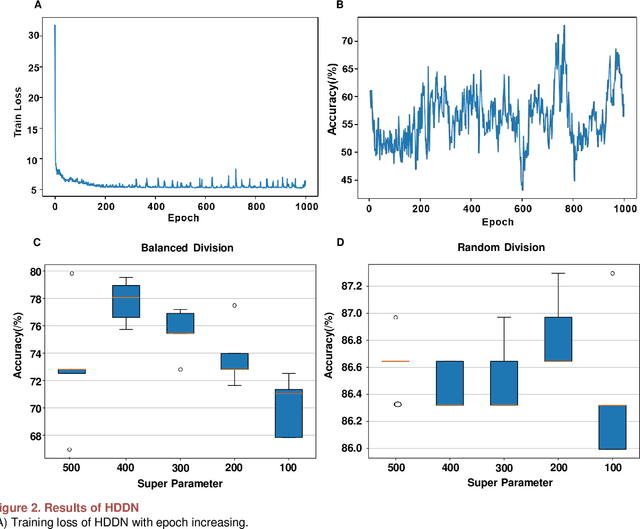
Prediction of material property is a key problem because of its significance to material design and screening. We present a brand-new and general machine learning method for material property prediction. As a representative example, polymer compatibility is chosen to demonstrate the effectiveness of our method. Specifically, we mine data from related literature to build a specific database and give a prediction based on the basic molecular structures of blending polymers and, as auxiliary, the blending composition. Our model obtains at least 75% accuracy on the dataset consisting of thousands of entries. We demonstrate that the relationship between structure and properties can be learned and simulated by machine learning method.
A Theoretical View of Linear Backpropagation and Its Convergence
Dec 21, 2021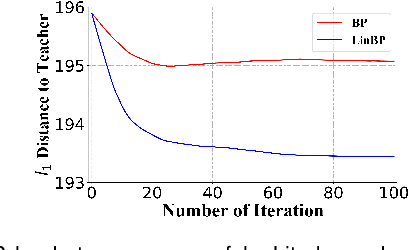
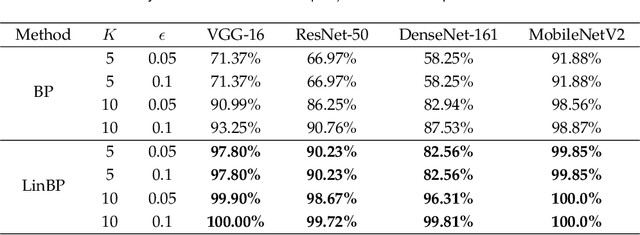
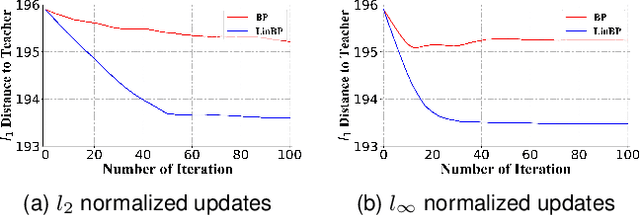
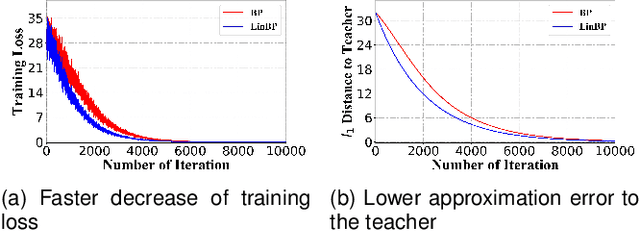
Backpropagation is widely used for calculating gradients in deep neural networks (DNNs). Applied often along with stochastic gradient descent (SGD) or its variants, backpropagation is considered as a de-facto choice in a variety of machine learning tasks including DNN training and adversarial attack/defense. Recently, a linear variant of BP named LinBP was introduced for generating more transferable adversarial examples for black-box adversarial attacks, by Guo et al. Yet, it has not been theoretically studied and the convergence analysis of such a method is lacking. This paper serves as a complement and somewhat an extension to Guo et al.'s paper, by providing theoretical analyses on LinBP in neural-network-involved learning tasks including adversarial attack and model training. We demonstrate that, somewhat surprisingly, LinBP can lead to faster convergence in these tasks in the same hyper-parameter settings, compared to BP. We confirm our theoretical results with extensive experiments.
Learned ISTA with Error-based Thresholding for Adaptive Sparse Coding
Dec 21, 2021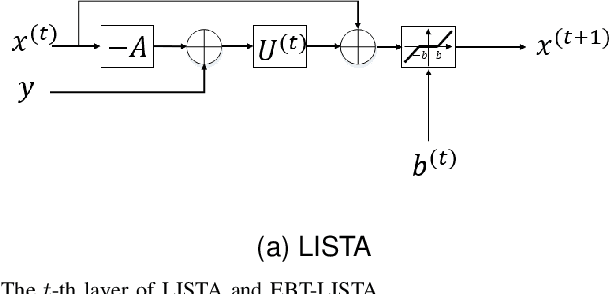
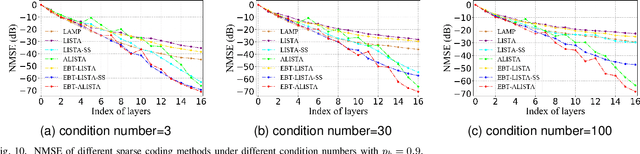
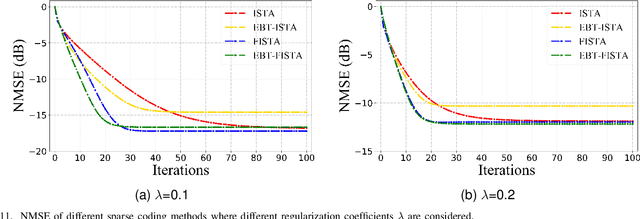
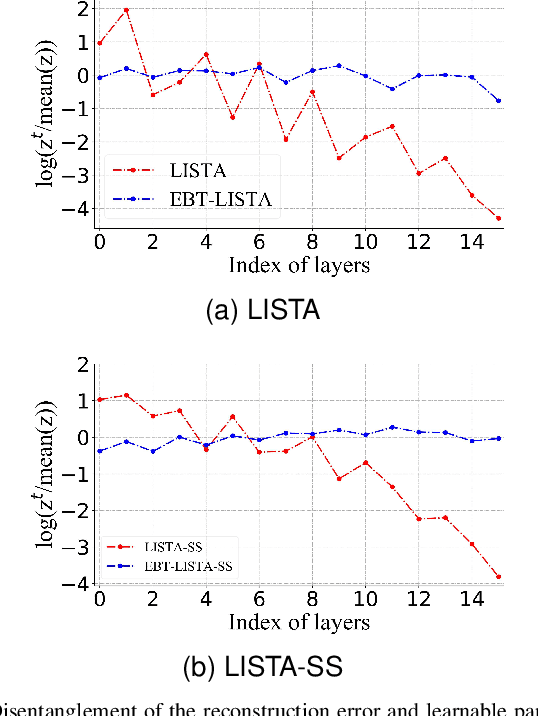
The learned iterative shrinkage thresholding algorithm (LISTA) introduces deep unfolding models with learnable thresholds in some shrinkage functions for sparse coding. Drawing on some theoretical insights, we advocate an error-based thresholding (EBT) mechanism for LISTA, which leverages a function of the layer-wise reconstruction error to suggest an appropriate threshold value for each observation on each layer. We show that the EBT mechanism well disentangles the learnable parameters in the shrinkage functions from the reconstruction errors, making them more adaptive to the various observations. With rigorous theoretical analyses, we show that the proposed EBT can lead to a faster convergence on the basis of LISTA and its variants, in addition to its higher adaptivity. Extensive experimental results confirm our theoretical analyses and verify the effectiveness of our methods.
GreedyNASv2: Greedier Search with a Greedy Path Filter
Nov 24, 2021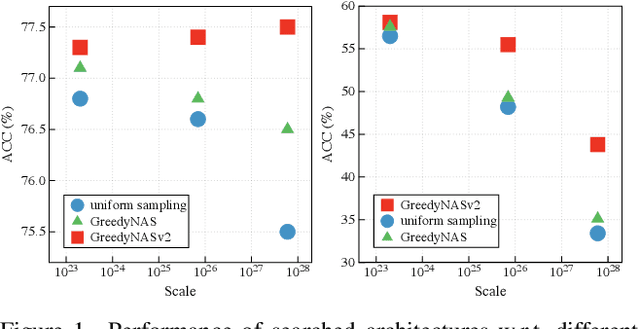

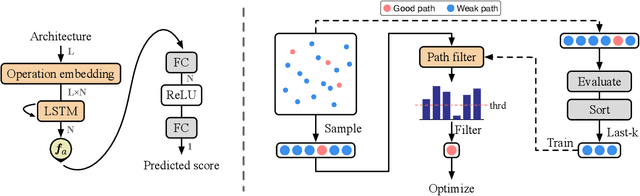
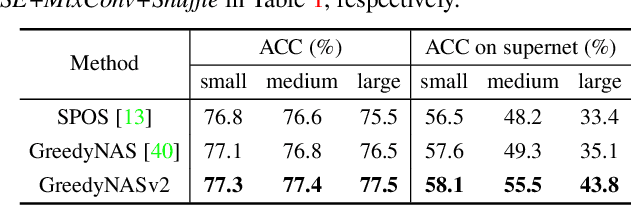
Training a good supernet in one-shot NAS methods is difficult since the search space is usually considerably huge (e.g., $13^{21}$). In order to enhance the supernet's evaluation ability, one greedy strategy is to sample good paths, and let the supernet lean towards the good ones and ease its evaluation burden as a result. However, in practice the search can be still quite inefficient since the identification of good paths is not accurate enough and sampled paths still scatter around the whole search space. In this paper, we leverage an explicit path filter to capture the characteristics of paths and directly filter those weak ones, so that the search can be thus implemented on the shrunk space more greedily and efficiently. Concretely, based on the fact that good paths are much less than the weak ones in the space, we argue that the label of "weak paths" will be more confident and reliable than that of ``good paths" in multi-path sampling. In this way, we thus cast the training of path filter in the positive and unlabeled (PU) learning paradigm, and also encourage a \textit{path embedding} as better path/operation representation to enhance the identification capacity of the learned filter. By dint of this embedding, we can further shrink the search space by aggregating similar operations with similar embeddings, and the search can be more efficient and accurate. Extensive experiments validate the effectiveness of the proposed method GreedyNASv2. For example, our obtained GreedyNASv2-L achieves $81.1\%$ Top-1 accuracy on ImageNet dataset, significantly outperforming the ResNet-50 strong baselines.
CATRO: Channel Pruning via Class-Aware Trace Ratio Optimization
Oct 21, 2021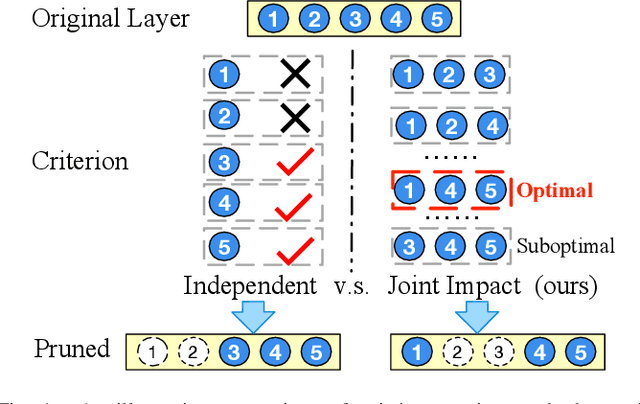
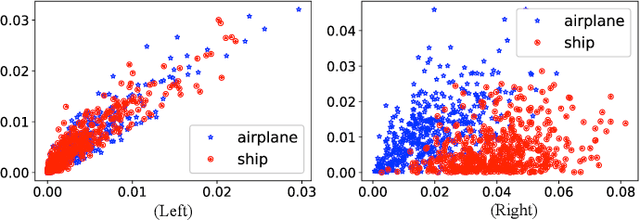
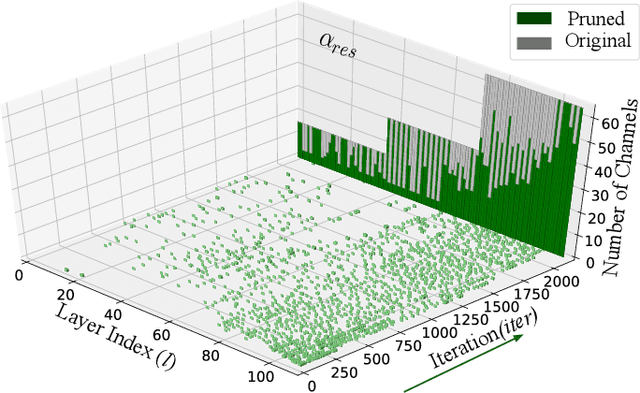
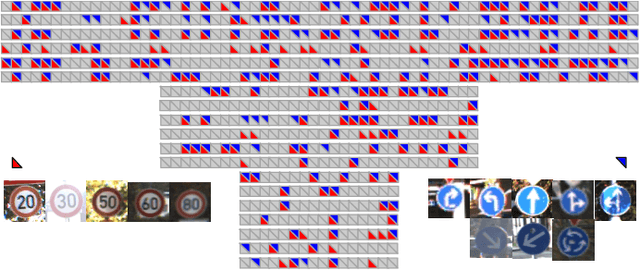
Deep convolutional neural networks are shown to be overkill with high parametric and computational redundancy in many application scenarios, and an increasing number of works have explored model pruning to obtain lightweight and efficient networks. However, most existing pruning approaches are driven by empirical heuristics and rarely consider the joint impact of channels, leading to unguaranteed and suboptimal performance. In this paper, we propose a novel channel pruning method via class-aware trace ratio optimization (CATRO) to reduce the computational burden and accelerate the model inference. Utilizing class information from a few samples, CATRO measures the joint impact of multiple channels by feature space discriminations and consolidates the layer-wise impact of preserved channels. By formulating channel pruning as a submodular set function maximization problem, CATRO solves it efficiently via a two-stage greedy iterative optimization procedure. More importantly, we present theoretical justifications on convergence and performance of CATRO. Experimental results demonstrate that CATRO achieves higher accuracy with similar computation cost or lower computation cost with similar accuracy than other state-of-the-art channel pruning algorithms. In addition, because of its class-aware property, CATRO is suitable to prune efficient networks adaptively for various classification subtasks, enhancing handy deployment and usage of deep networks in real-world applications.
Weakly Supervised Contrastive Learning
Oct 10, 2021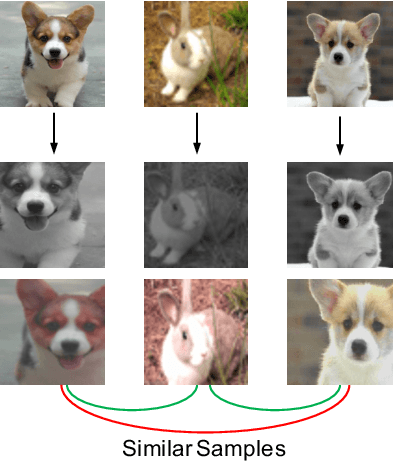
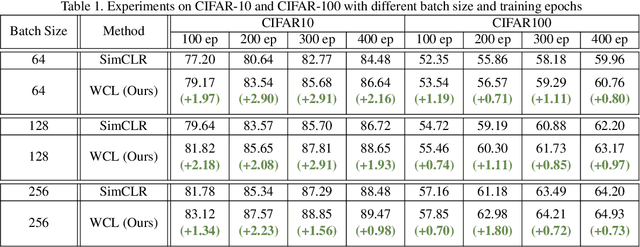
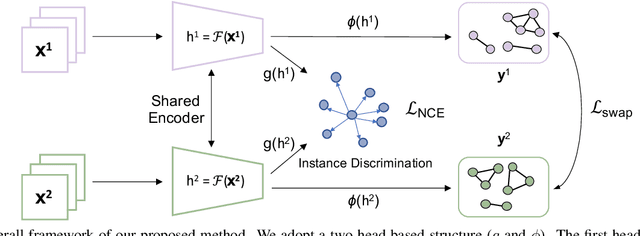
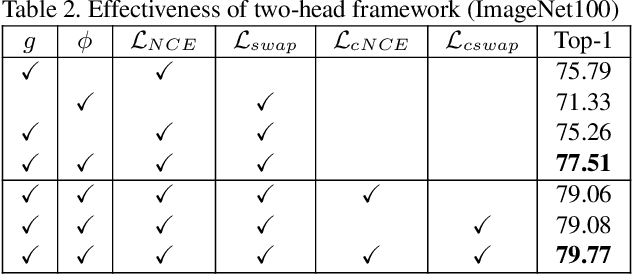
Unsupervised visual representation learning has gained much attention from the computer vision community because of the recent achievement of contrastive learning. Most of the existing contrastive learning frameworks adopt the instance discrimination as the pretext task, which treating every single instance as a different class. However, such method will inevitably cause class collision problems, which hurts the quality of the learned representation. Motivated by this observation, we introduced a weakly supervised contrastive learning framework (WCL) to tackle this issue. Specifically, our proposed framework is based on two projection heads, one of which will perform the regular instance discrimination task. The other head will use a graph-based method to explore similar samples and generate a weak label, then perform a supervised contrastive learning task based on the weak label to pull the similar images closer. We further introduced a K-Nearest Neighbor based multi-crop strategy to expand the number of positive samples. Extensive experimental results demonstrate WCL improves the quality of self-supervised representations across different datasets. Notably, we get a new state-of-the-art result for semi-supervised learning. With only 1\% and 10\% labeled examples, WCL achieves 65\% and 72\% ImageNet Top-1 Accuracy using ResNet50, which is even higher than SimCLRv2 with ResNet101.
Correcting the User Feedback-Loop Bias for Recommendation Systems
Sep 13, 2021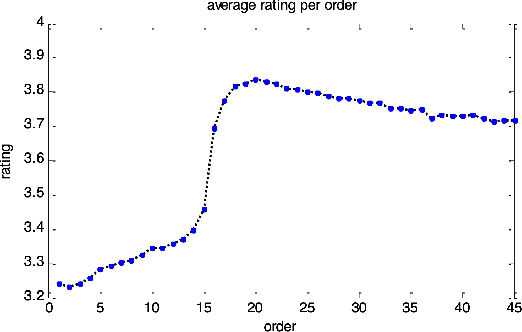

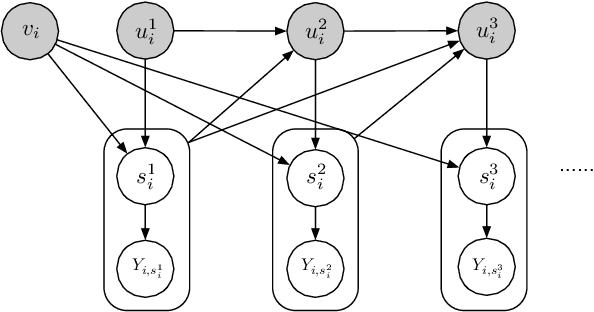
Selection bias is prevalent in the data for training and evaluating recommendation systems with explicit feedback. For example, users tend to rate items they like. However, when rating an item concerning a specific user, most of the recommendation algorithms tend to rely too much on his/her rating (feedback) history. This introduces implicit bias on the recommendation system, which is referred to as user feedback-loop bias in this paper. We propose a systematic and dynamic way to correct such bias and to obtain more diverse and objective recommendations by utilizing temporal rating information. Specifically, our method includes a deep-learning component to learn each user's dynamic rating history embedding for the estimation of the probability distribution of the items that the user rates sequentially. These estimated dynamic exposure probabilities are then used as propensity scores to train an inverse-propensity-scoring (IPS) rating predictor. We empirically validated the existence of such user feedback-loop bias in real world recommendation systems and compared the performance of our method with the baseline models that are either without de-biasing or with propensity scores estimated by other methods. The results show the superiority of our approach.
Exophoric Pronoun Resolution in Dialogues with Topic Regularization
Sep 10, 2021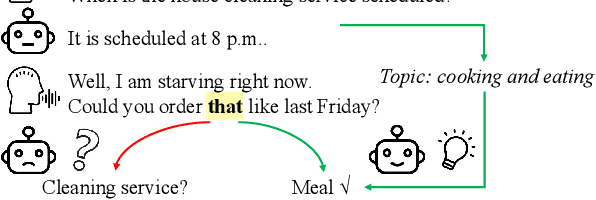


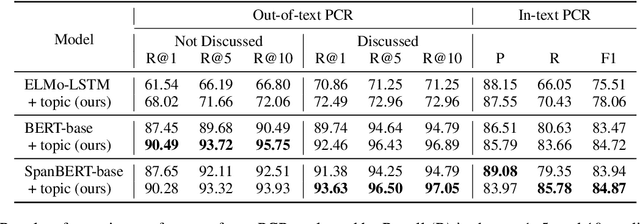
Resolving pronouns to their referents has long been studied as a fundamental natural language understanding problem. Previous works on pronoun coreference resolution (PCR) mostly focus on resolving pronouns to mentions in text while ignoring the exophoric scenario. Exophoric pronouns are common in daily communications, where speakers may directly use pronouns to refer to some objects present in the environment without introducing the objects first. Although such objects are not mentioned in the dialogue text, they can often be disambiguated by the general topics of the dialogue. Motivated by this, we propose to jointly leverage the local context and global topics of dialogues to solve the out-of-text PCR problem. Extensive experiments demonstrate the effectiveness of adding topic regularization for resolving exophoric pronouns.