 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Facts Change: Probing LLMs on Evolving Knowledge with evolveQA
Oct 22, 2025LLMs often fail to handle temporal knowledge conflicts--contradictions arising when facts evolve over time within their training data. Existing studies evaluate this phenomenon through benchmarks built on structured knowledge bases like Wikidata, but they focus on widely-covered, easily-memorized popular entities and lack the dynamic structure needed to fairly evaluate LLMs with different knowledge cut-off dates. We introduce evolveQA, a benchmark specifically designed to evaluate LLMs on temporally evolving knowledge, constructed from 3 real-world, time-stamped corpora: AWS updates, Azure changes, and WHO disease outbreak reports. Our framework identifies naturally occurring knowledge evolution and generates questions with gold answers tailored to different LLM knowledge cut-off dates. Through extensive evaluation of 12 open and closed-source LLMs across 3 knowledge probing formats, we demonstrate significant performance drops of up to 31% on evolveQA compared to static knowledge questions.
WebGraphEval: Multi-Turn Trajectory Evaluation for Web Agents using Graph Representation
Oct 22, 2025Current evaluation of web agents largely reduces to binary success metrics or conformity to a single reference trajectory, ignoring the structural diversity present in benchmark datasets. We present WebGraphEval, a framework that abstracts trajectories from multiple agents into a unified, weighted action graph. This representation is directly compatible with benchmarks such as WebArena, leveraging leaderboard runs and newly collected trajectories without modifying environments. The framework canonically encodes actions, merges recurring behaviors, and applies structural analyses including reward propagation and success-weighted edge statistics. Evaluations across thousands of trajectories from six web agents show that the graph abstraction captures cross-model regularities, highlights redundancy and inefficiency, and identifies critical decision points overlooked by outcome-based metrics. By framing web interaction as graph-structured data, WebGraphEval establishes a general methodology for multi-path, cross-agent, and efficiency-aware evaluation of web agents.
RGMDT: Return-Gap-Minimizing Decision Tree Extraction in Non-Euclidean Metric Space
Oct 21, 2024



Deep Reinforcement Learning (DRL) algorithms have achieved great success in solving many challenging tasks while their black-box nature hinders interpretability and real-world applicability, making it difficult for human experts to interpret and understand DRL policies. Existing works on interpretable reinforcement learning have shown promise in extracting decision tree (DT) based policies from DRL policies with most focus on the single-agent settings while prior attempts to introduce DT policies in multi-agent scenarios mainly focus on heuristic designs which do not provide any quantitative guarantees on the expected return. In this paper, we establish an upper bound on the return gap between the oracle expert policy and an optimal decision tree policy. This enables us to recast the DT extraction problem into a novel non-euclidean clustering problem over the local observation and action values space of each agent, with action values as cluster labels and the upper bound on the return gap as clustering loss. Both the algorithm and the upper bound are extended to multi-agent decentralized DT extractions by an iteratively-grow-DT procedure guided by an action-value function conditioned on the current DTs of other agents. Further, we propose the Return-Gap-Minimization Decision Tree (RGMDT) algorithm, which is a surprisingly simple design and is integrated with reinforcement learning through the utilization of a novel Regularized Information Maximization loss. Evaluations on tasks like D4RL show that RGMDT significantly outperforms heuristic DT-based baselines and can achieve nearly optimal returns under given DT complexity constraints (e.g., maximum number of DT nodes).
Collaborative AI Teaming in Unknown Environments via Active Goal Deduction
Mar 22, 2024With the advancements of artificial intelligence (AI), we're seeing more scenarios that require AI to work closely with other agents, whose goals and strategies might not be known beforehand. However, existing approaches for training collaborative agents often require defined and known reward signals and cannot address the problem of teaming with unknown agents that often have latent objectives/rewards. In response to this challenge, we propose teaming with unknown agents framework, which leverages kernel density Bayesian inverse learning method for active goal deduction and utilizes pre-trained, goal-conditioned policies to enable zero-shot policy adaptation. We prove that unbiased reward estimates in our framework are sufficient for optimal teaming with unknown agents. We further evaluate the framework of redesigned multi-agent particle and StarCraft II micromanagement environments with diverse unknown agents of different behaviors/rewards. Empirical results demonstrate that our framework significantly advances the teaming performance of AI and unknown agents in a wide range of collaborative scenarios.
Real-time Network Intrusion Detection via Decision Transformers
Dec 17, 2023Many cybersecurity problems that require real-time decision-making based on temporal observations can be abstracted as a sequence modeling problem, e.g., network intrusion detection from a sequence of arriving packets. Existing approaches like reinforcement learning may not be suitable for such cybersecurity decision problems, since the Markovian property may not necessarily hold and the underlying network states are often not observable. In this paper, we cast the problem of real-time network intrusion detection as casual sequence modeling and draw upon the power of the transformer architecture for real-time decision-making. By conditioning a causal decision transformer on past trajectories, consisting of the rewards, network packets, and detection decisions, our proposed framework will generate future detection decisions to achieve the desired return. It enables decision transformers to be applied to real-time network intrusion detection, as well as a novel tradeoff between the accuracy and timeliness of detection. The proposed solution is evaluated on public network intrusion detection datasets and outperforms several baseline algorithms using reinforcement learning and sequence modeling, in terms of detection accuracy and timeliness.
Every Parameter Matters: Ensuring the Convergence of Federated Learning with Dynamic Heterogeneous Models Reduction
Oct 26, 2023Cross-device Federated Learning (FL) faces significant challenges where low-end clients that could potentially make unique contributions are excluded from training large models due to their resource bottlenecks. Recent research efforts have focused on model-heterogeneous FL, by extracting reduced-size models from the global model and applying them to local clients accordingly. Despite the empirical success, general theoretical guarantees of convergence on this method remain an open question. This paper presents a unifying framework for heterogeneous FL algorithms with online model extraction and provides a general convergence analysis for the first time. In particular, we prove that under certain sufficient conditions and for both IID and non-IID data, these algorithms converge to a stationary point of standard FL for general smooth cost functions. Moreover, we introduce the concept of minimum coverage index, together with model reduction noise, which will determine the convergence of heterogeneous federated learning, and therefore we advocate for a holistic approach that considers both factors to enhance the efficiency of heterogeneous federated learning.
Statistically Efficient Variance Reduction with Double Policy Estimation for Off-Policy Evaluation in Sequence-Modeled Reinforcement Learning
Aug 28, 2023Offline reinforcement learning aims to utilize datasets of previously gathered environment-action interaction records to learn a policy without access to the real environment. Recent work has shown that offline reinforcement learning can be formulated as a sequence modeling problem and solved via supervised learning with approaches such as decision transformer. While these sequence-based methods achieve competitive results over return-to-go methods, especially on tasks that require longer episodes or with scarce rewards, importance sampling is not considered to correct the policy bias when dealing with off-policy data, mainly due to the absence of behavior policy and the use of deterministic evaluation policies. To this end, we propose DPE: an RL algorithm that blends offline sequence modeling and offline reinforcement learning with Double Policy Estimation (DPE) in a unified framework with statistically proven properties on variance reduction. We validate our method in multiple tasks of OpenAI Gym with D4RL benchmarks. Our method brings a performance improvements on selected methods which outperforms SOTA baselines in several tasks, demonstrating the advantages of enabling double policy estimation for sequence-modeled reinforcement learning.
MAC-PO: Multi-Agent Experience Replay via Collective Priority Optimization
Feb 28, 2023Experience replay is crucial for off-policy reinforcement learning (RL) methods. By remembering and reusing the experiences from past different policies, experience replay significantly improves the training efficiency and stability of RL algorithms. Many decision-making problems in practice naturally involve multiple agents and require multi-agent reinforcement learning (MARL) under centralized training decentralized execution paradigm. Nevertheless, existing MARL algorithms often adopt standard experience replay where the transitions are uniformly sampled regardless of their importance. Finding prioritized sampling weights that are optimized for MARL experience replay has yet to be explored. To this end, we propose MAC-PO, which formulates optimal prioritized experience replay for multi-agent problems as a regret minimization over the sampling weights of transitions. Such optimization is relaxed and solved using the Lagrangian multiplier approach to obtain the close-form optimal sampling weights. By minimizing the resulting policy regret, we can narrow the gap between the current policy and a nominal optimal policy, thus acquiring an improved prioritization scheme for multi-agent tasks. Our experimental results on Predator-Prey and StarCraft Multi-Agent Challenge environments demonstrate the effectiveness of our method, having a better ability to replay important transitions and outperforming other state-of-the-art baselines.
ReMIX: Regret Minimization for Monotonic Value Function Factorization in Multiagent Reinforcement Learning
Feb 11, 2023



Value function factorization methods have become a dominant approach for cooperative multiagent reinforcement learning under a centralized training and decentralized execution paradigm. By factorizing the optimal joint action-value function using a monotonic mixing function of agents' utilities, these algorithms ensure the consistency between joint and local action selections for decentralized decision-making. Nevertheless, the use of monotonic mixing functions also induces representational limitations. Finding the optimal projection of an unrestricted mixing function onto monotonic function classes is still an open problem. To this end, we propose ReMIX, formulating this optimal projection problem for value function factorization as a regret minimization over the projection weights of different state-action values. Such an optimization problem can be relaxed and solved using the Lagrangian multiplier method to obtain the close-form optimal projection weights. By minimizing the resulting policy regret, we can narrow the gap between the optimal and the restricted monotonic mixing functions, thus obtaining an improved monotonic value function factorization. Our experimental results on Predator-Prey and StarCraft Multiagent Challenge environments demonstrate the effectiveness of our method, indicating the better capabilities of handling environments with non-monotonic value functions.
PAC: Assisted Value Factorisation with Counterfactual Predictions in Multi-Agent Reinforcement Learning
Jun 22, 2022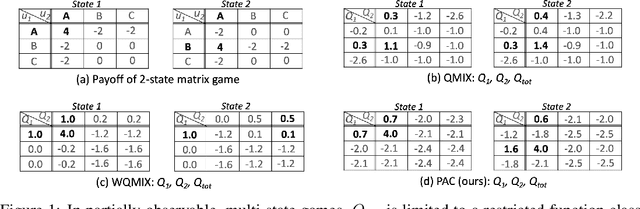
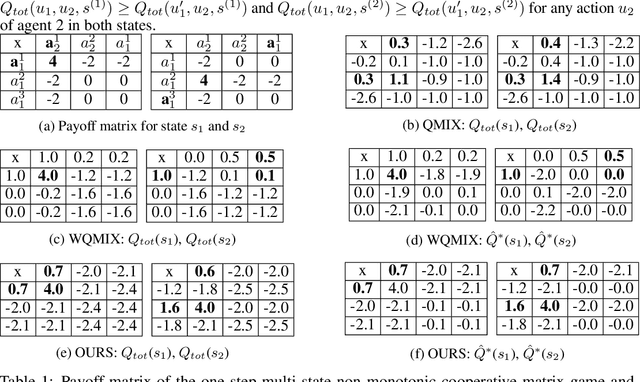
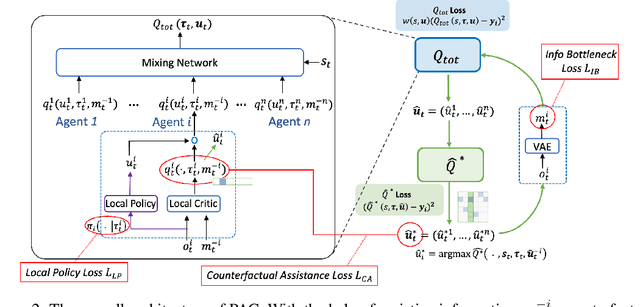

Multi-agent reinforcement learning (MARL) has witnessed significant progress with the development of value function factorization methods. It allows optimizing a joint action-value function through the maximization of factorized per-agent utilities due to monotonicity. In this paper, we show that in partially observable MARL problems, an agent's ordering over its own actions could impose concurrent constraints (across different states) on the representable function class, causing significant estimation error during training. We tackle this limitation and propose PAC, a new framework leveraging Assistive information generated from Counterfactual Predictions of optimal joint action selection, which enable explicit assistance to value function factorization through a novel counterfactual loss. A variational inference-based information encoding method is developed to collect and encode the counterfactual predictions from an estimated baseline. To enable decentralized execution, we also derive factorized per-agent policies inspired by a maximum-entropy MARL framework. We evaluate the proposed PAC on multi-agent predator-prey and a set of StarCraft II micromanagement tasks. Empirical results demonstrate improved results of PAC over state-of-the-art value-based and policy-based multi-agent reinforcement learning algorithms on all benchmarks.