 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling graph dynamics in fraud detection with "Attention"
Apr 22, 2022At online retail platforms, detecting fraudulent accounts and transactions is crucial to improve customer experience, minimize loss, and avoid unauthorized transactions. Despite the variety of different models for deep learning on graphs, few approaches have been proposed for dealing with graphs that are both heterogeneous and dynamic. In this paper, we propose DyHGN (Dynamic Heterogeneous Graph Neural Network) and its variants to capture both temporal and heterogeneous information. We first construct dynamic heterogeneous graphs from registration and transaction data from eBay. Then, we build models with diachronic entity embedding and heterogeneous graph transformer. We also use model explainability techniques to understand the behaviors of DyHGN-* models. Our findings reveal that modelling graph dynamics with heterogeneous inputs need to be conducted with "attention" depending on the data structure, distribution, and computation cost.
X-CAR: An Experimental Vehicle Platform for Connected Autonomy Research Powered by CARMA
Apr 06, 2022
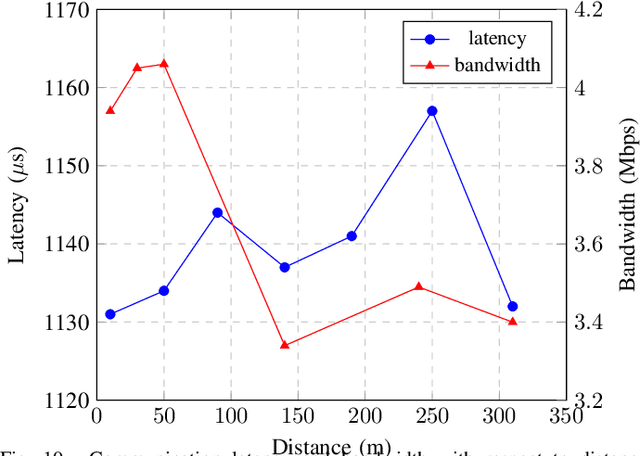
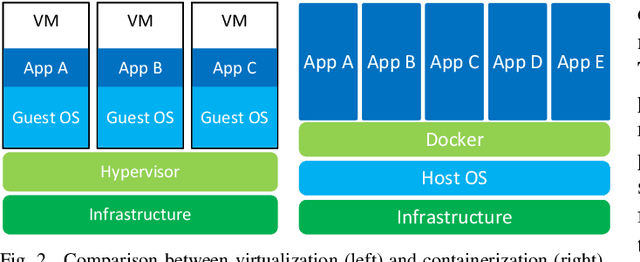
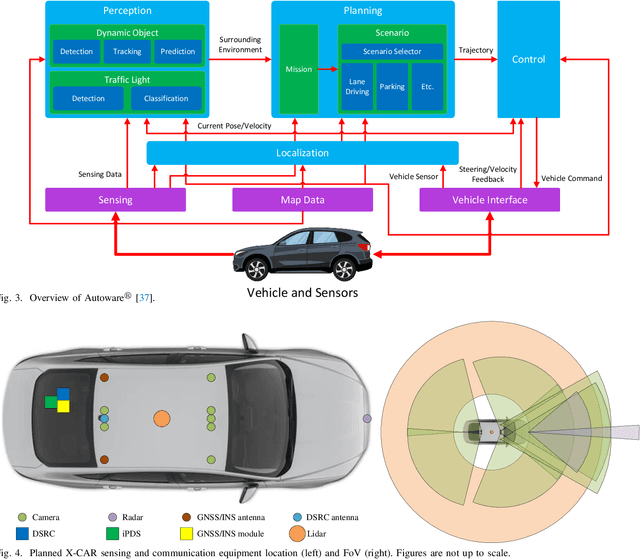
Autonomous vehicles promise a future with a safer, cleaner, more efficient, and more reliable transportation system. However, the current approach to autonomy has focused on building small, disparate intelligences that are closed off to the rest of the world. Vehicle connectivity has been proposed as a solution, relying on a vision of the future where a mix of connected autonomous and human-driven vehicles populate the road. Developed by the U.S. Department of Transportation Federal Highway Administration as a reusable, extensible platform for controlling connected autonomous vehicles, the CARMA Platform is one of the technologies enabling this connected future. Nevertheless, the adoption of the CARMA Platform has been slow, with a contributing factor being the limited, expensive, and somewhat old vehicle configurations that are officially supported. To alleviate this problem, we propose X-CAR (eXperimental vehicle platform for Connected Autonomy Research). By implementing the CARMA Platform on more affordable, high quality hardware, X-CAR aims to increase the versatility of the CARMA Platform and facilitate its adoption for research and development of connected driving automation.
SHiFT: An Efficient, Flexible Search Engine for Transfer Learning
Apr 04, 2022
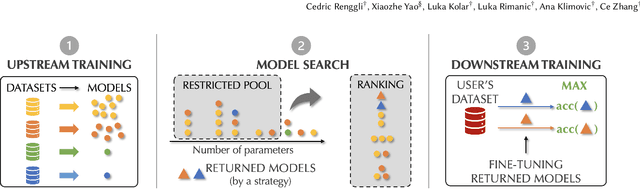
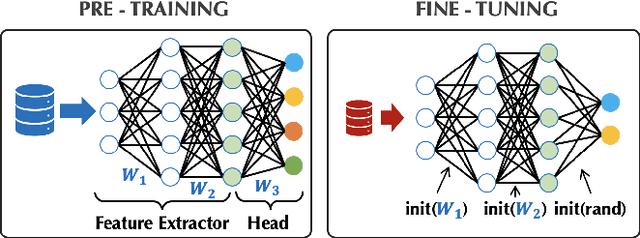
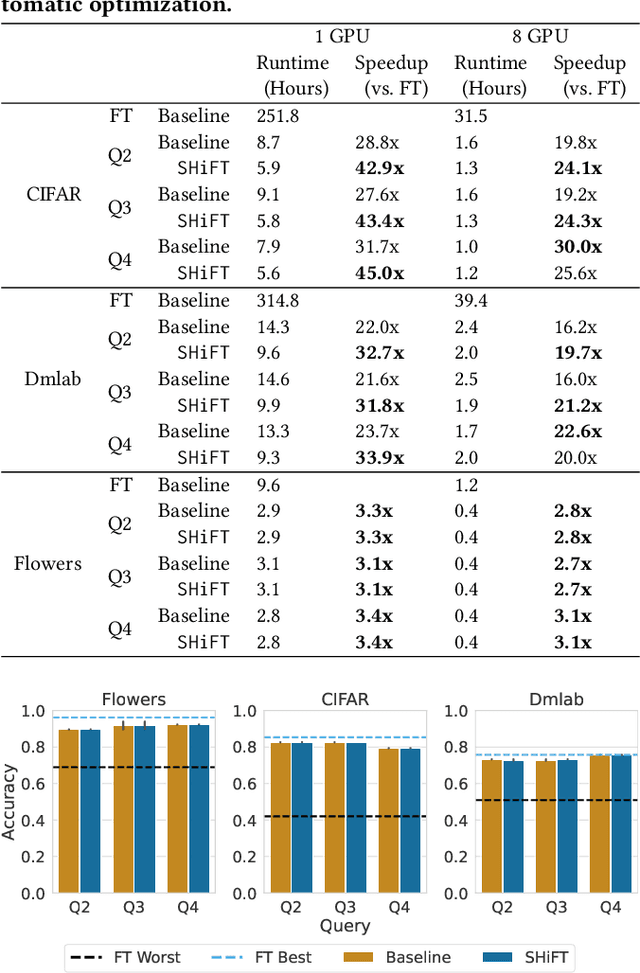
Transfer learning can be seen as a data- and compute-efficient alternative to training models from scratch. The emergence of rich model repositories, such as TensorFlow Hub, enables practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. By carefully comparing various selection and search strategies, we realize that no single method outperforms the others, and hybrid or mixed strategies can be beneficial. Therefore, we propose SHiFT, the first downstream task-aware, flexible, and efficient model search engine for transfer learning. These properties are enabled by a custom query language SHiFT-QL together with a cost-based decision maker, which we empirically validate. Motivated by the iterative nature of machine learning development, we further support efficient incremental executions of our queries, which requires a careful implementation when jointly used with our optimizations.
A Quality Index Metric and Method for Online Self-Assessment of Autonomous Vehicles Sensory Perception
Mar 04, 2022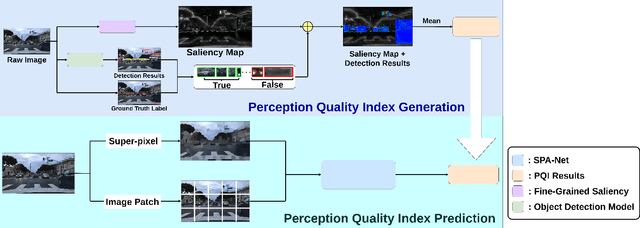

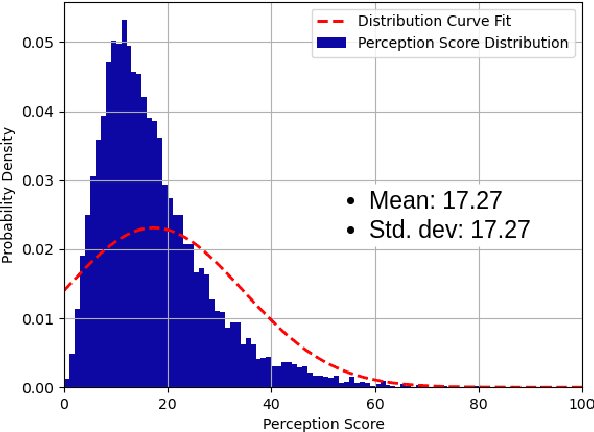
Perception is critical to autonomous driving safety. Camera-based object detection is one of the most important methods for autonomous vehicle perception. Current camera-based object detection solutions for autonomous driving cannot provide feedback on the detection performance for each frame. We propose an evaluation metric, namely the perception quality index (PQI), to assess the camera-based object detection algorithm performance and provide the perception quality feedback frame by frame. The method of the PQI generation is by combining the fine-grained saliency map intensity with the object detection algorithm's output results. Furthermore, we developed a superpixel-based attention network (SPA-NET) to predict the proposed PQI evaluation metric by using raw image pixels and superpixels as input. The proposed evaluation metric and prediction network are tested on three open-source datasets. The proposed evaluation metric can correctly assess the camera-based perception quality under the autonomous driving environment according to the experiment results. The network regression R-square values determine the comparison among models. It is shown that a Perception Quality Index is useful in self-evaluating a cameras visual scene perception.
Certifying Out-of-Domain Generalization for Blackbox Functions
Feb 03, 2022
Certifying the robustness of model performance under bounded data distribution shifts has recently attracted intensive interests under the umbrella of distributional robustness. However, existing techniques either make strong assumptions on the model class and loss functions that can be certified, such as smoothness expressed via Lipschitz continuity of gradients, or require to solve complex optimization problems. As a result, the wider application of these techniques is currently limited by its scalability and flexibility -- these techniques often do not scale to large-scale datasets with modern deep neural networks or cannot handle loss functions which may be non-smooth, such as the 0-1 loss. In this paper, we focus on the problem of certifying distributional robustness for black box models and bounded losses, without other assumptions. We propose a novel certification framework given bounded distance of mean and variance of two distributions. Our certification technique scales to ImageNet-scale datasets, complex models, and a diverse range of loss functions. We then focus on one specific application enabled by such scalability and flexibility, i.e., certifying out-of-domain generalization for large neural networks and loss functions such as accuracy and AUC. We experimentally validate our certification method on a number of datasets, ranging from ImageNet, where we provide the first non-vacuous certified out-of-domain generalization, to smaller classification tasks where we are able to compare with the state-of-the-art and show that our method performs considerably better.
ReforesTree: A Dataset for Estimating Tropical Forest Carbon Stock with Deep Learning and Aerial Imagery
Jan 26, 2022
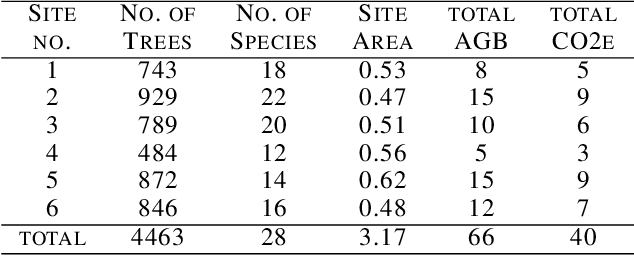
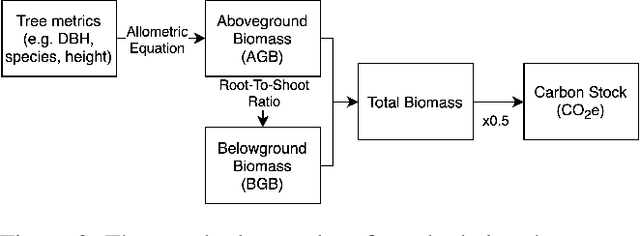
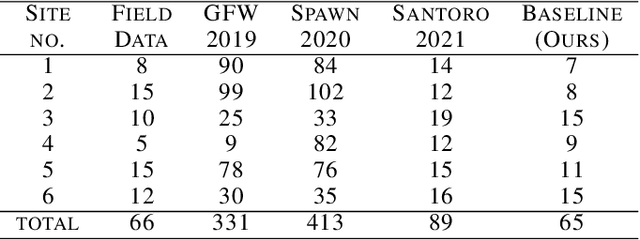
Forest biomass is a key influence for future climate, and the world urgently needs highly scalable financing schemes, such as carbon offsetting certifications, to protect and restore forests. Current manual forest carbon stock inventory methods of measuring single trees by hand are time, labour, and cost-intensive and have been shown to be subjective. They can lead to substantial overestimation of the carbon stock and ultimately distrust in forest financing. The potential for impact and scale of leveraging advancements in machine learning and remote sensing technologies is promising but needs to be of high quality in order to replace the current forest stock protocols for certifications. In this paper, we present ReforesTree, a benchmark dataset of forest carbon stock in six agro-forestry carbon offsetting sites in Ecuador. Furthermore, we show that a deep learning-based end-to-end model using individual tree detection from low cost RGB-only drone imagery is accurately estimating forest carbon stock within official carbon offsetting certification standards. Additionally, our baseline CNN model outperforms state-of-the-art satellite-based forest biomass and carbon stock estimates for this type of small-scale, tropical agro-forestry sites. We present this dataset to encourage machine learning research in this area to increase accountability and transparency of monitoring, verification and reporting (MVR) in carbon offsetting projects, as well as scaling global reforestation financing through accurate remote sensing.
Hyper-Tune: Towards Efficient Hyper-parameter Tuning at Scale
Jan 18, 2022

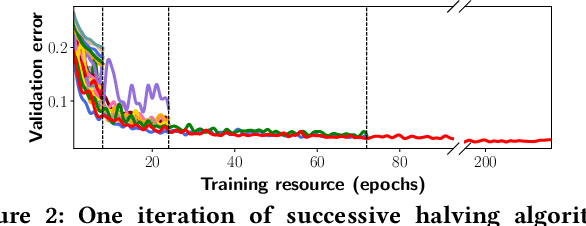
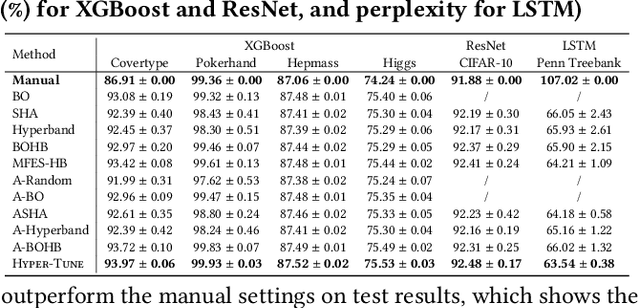
The ever-growing demand and complexity of machine learning are putting pressure on hyper-parameter tuning systems: while the evaluation cost of models continues to increase, the scalability of state-of-the-arts starts to become a crucial bottleneck. In this paper, inspired by our experience when deploying hyper-parameter tuning in a real-world application in production and the limitations of existing systems, we propose Hyper-Tune, an efficient and robust distributed hyper-parameter tuning framework. Compared with existing systems, Hyper-Tune highlights multiple system optimizations, including (1) automatic resource allocation, (2) asynchronous scheduling, and (3) multi-fidelity optimizer. We conduct extensive evaluations on benchmark datasets and a large-scale real-world dataset in production. Empirically, with the aid of these optimizations, Hyper-Tune outperforms competitive hyper-parameter tuning systems on a wide range of scenarios, including XGBoost, CNN, RNN, and some architectural hyper-parameters for neural networks. Compared with the state-of-the-art BOHB and A-BOHB, Hyper-Tune achieves up to 11.2x and 5.1x speedups, respectively.
TableParser: Automatic Table Parsing with Weak Supervision from Spreadsheets
Jan 05, 2022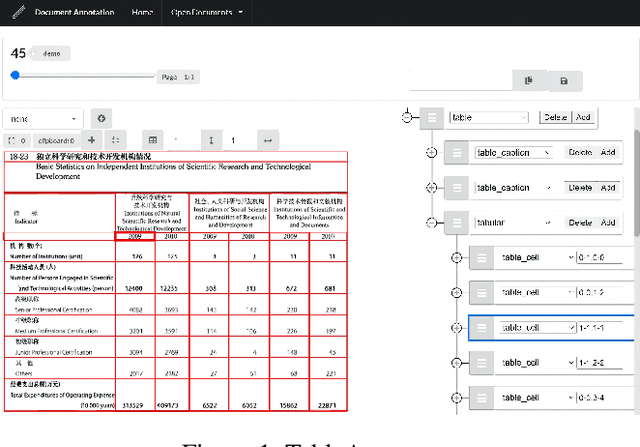
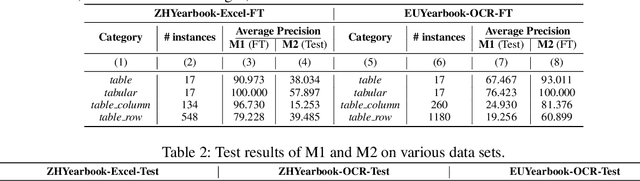
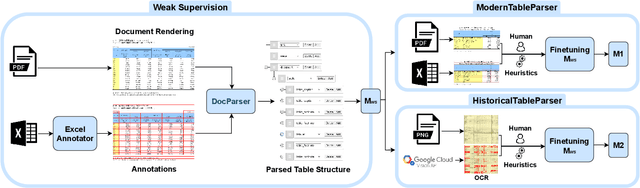

Tables have been an ever-existing structure to store data. There exist now different approaches to store tabular data physically. PDFs, images, spreadsheets, and CSVs are leading examples. Being able to parse table structures and extract content bounded by these structures is of high importance in many applications. In this paper, we devise TableParser, a system capable of parsing tables in both native PDFs and scanned images with high precision. We have conducted extensive experiments to show the efficacy of domain adaptation in developing such a tool. Moreover, we create TableAnnotator and ExcelAnnotator, which constitute a spreadsheet-based weak supervision mechanism and a pipeline to enable table parsing. We share these resources with the research community to facilitate further research in this interesting direction.
Super-resolution reconstruction of cytoskeleton image based on A-net deep learning network
Dec 17, 2021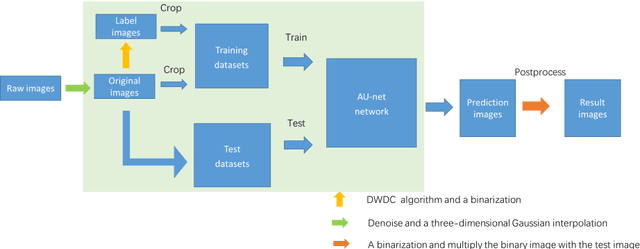
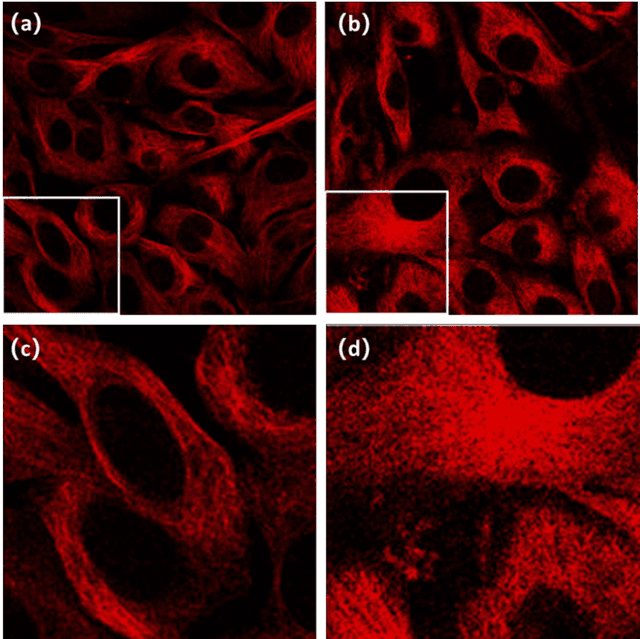
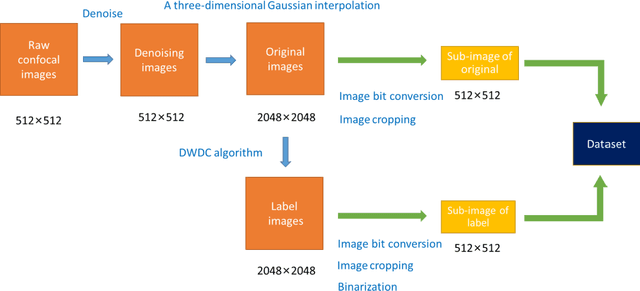
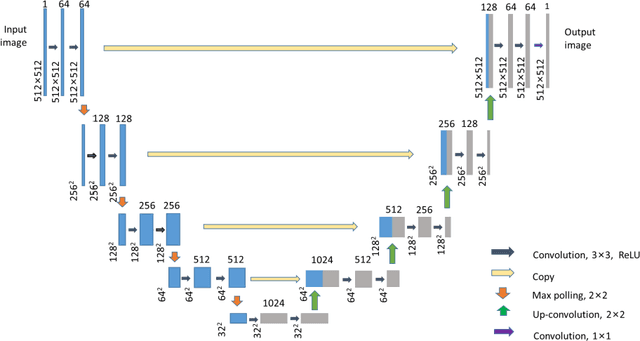
To date, live-cell imaging at the nanometer scale remains challenging. Even though super-resolution microscopy methods have enabled visualization of subcellular structures below the optical resolution limit, the spatial resolution is still far from enough for the structural reconstruction of biomolecules in vivo (i.e. ~24 nm thickness of microtubule fiber). In this study, we proposed an A-net network and showed that the resolution of cytoskeleton images captured by a confocal microscope can be significantly improved by combining the A-net deep learning network with the DWDC algorithm based on degradation model. Utilizing the DWDC algorithm to construct new datasets and taking advantage of A-net neural network's features (i.e., considerably fewer layers), we successfully removed the noise and flocculent structures, which originally interfere with the cellular structure in the raw image, and improved the spatial resolution by 10 times using relatively small dataset. We, therefore, conclude that the proposed algorithm that combines A-net neural network with the DWDC method is a suitable and universal approach for exacting structural details of biomolecules, cells and organs from low-resolution images.
Dynamic Human Evaluation for Relative Model Comparisons
Dec 15, 2021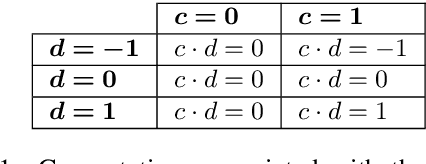
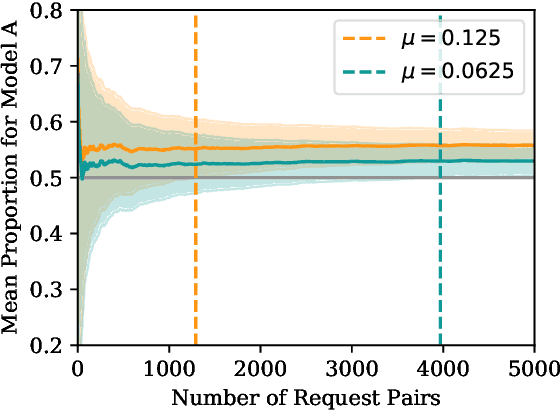
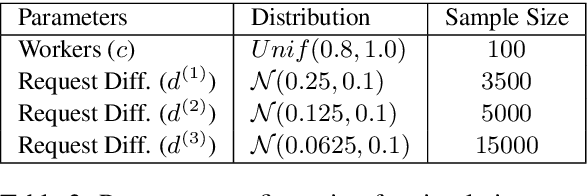
Collecting human judgements is currently the most reliable evaluation method for natural language generation systems. Automatic metrics have reported flaws when applied to measure quality aspects of generated text and have been shown to correlate poorly with human judgements. However, human evaluation is time and cost-intensive, and we lack consensus on designing and conducting human evaluation experiments. Thus there is a need for streamlined approaches for efficient collection of human judgements when evaluating natural language generation systems. Therefore, we present a dynamic approach to measure the required number of human annotations when evaluating generated outputs in relative comparison settings. We propose an agent-based framework of human evaluation to assess multiple labelling strategies and methods to decide the better model in a simulation and a crowdsourcing case study. The main results indicate that a decision about the superior model can be made with high probability across different labelling strategies, where assigning a single random worker per task requires the least overall labelling effort and thus the least cost.