 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Guided RANSAC: Learning Where to Sample Model Hypotheses
May 10, 2019
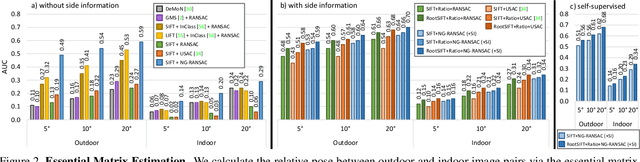

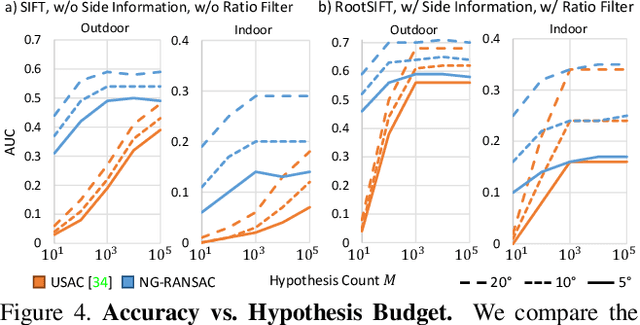
We present Neural-Guided RANSAC (NG-RANSAC), an extension to the classic RANSAC algorithm from robust optimization. NG-RANSAC uses prior information to improve model hypothesis search, increasing the chance of finding outlier-free minimal sets. Previous works use heuristic side-information like hand-crafted descriptor distance to guide hypothesis search. In contrast, we learn hypothesis search in a principled fashion that lets us optimize an arbitrary task loss during training, leading to large improvements on classic computer vision tasks. We present two further extensions to NG-RANSAC. Firstly, using the inlier count itself as training signal allows us to train neural guidance in a self-supervised fashion. Secondly, we combine neural guidance with differentiable RANSAC to build neural networks which focus on certain parts of the input data and make the output predictions as good as possible. We evaluate NG-RANSAC on a wide array of computer vision tasks, namely estimation of epipolar geometry, horizon line estimation and camera re-localization. We achieve superior or competitive results compared to state-of-the-art robust estimators, including very recent, learned ones.
Uncertainty-aware performance assessment of optical imaging modalities with invertible neural networks
Mar 08, 2019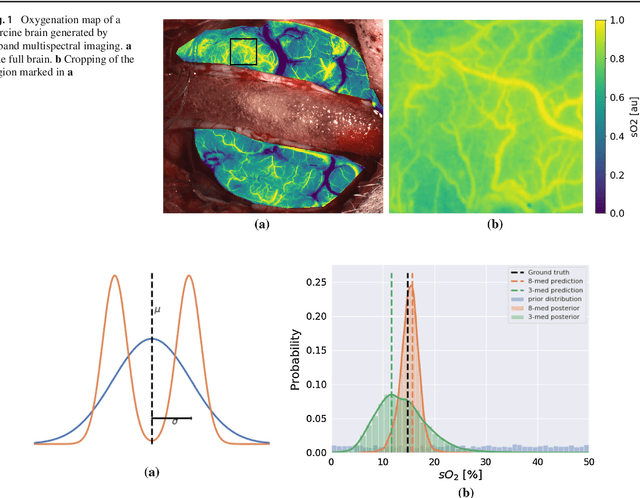

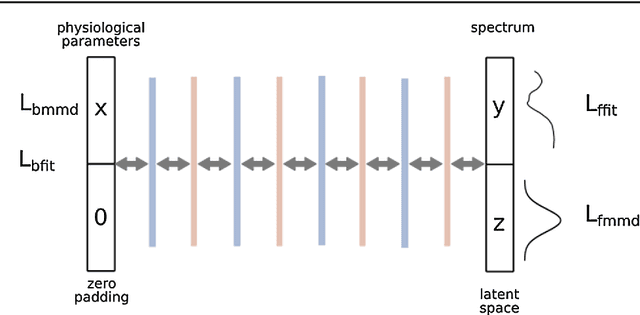
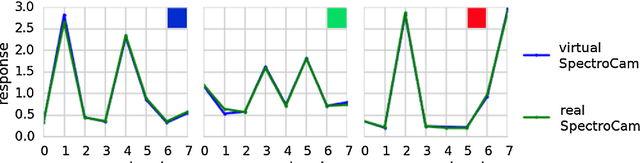
Purpose: Optical imaging is evolving as a key technique for advanced sensing in the operating room. Recent research has shown that machine learning algorithms can be used to address the inverse problem of converting pixel-wise multispectral reflectance measurements to underlying tissue parameters, such as oxygenation. Assessment of the specific hardware used in conjunction with such algorithms, however, has not properly addressed the possibility that the problem may be ill-posed. Methods: We present a novel approach to the assessment of optical imaging modalities, which is sensitive to the different types of uncertainties that may occur when inferring tissue parameters. Based on the concept of invertible neural networks, our framework goes beyond point estimates and maps each multispectral measurement to a full posterior probability distribution which is capable of representing ambiguity in the solution via multiple modes. Performance metrics for a hardware setup can then be computed from the characteristics of the posteriors. Results: Application of the assessment framework to the specific use case of camera selection for physiological parameter estimation yields the following insights: (1) Estimation of tissue oxygenation from multispectral images is a well-posed problem, while (2) blood volume fraction may not be recovered without ambiguity. (3) In general, ambiguity may be reduced by increasing the number of spectral bands in the camera. Conclusion: Our method could help to optimize optical camera design in an application-specific manner.
CEREALS - Cost-Effective REgion-based Active Learning for Semantic Segmentation
Oct 23, 2018

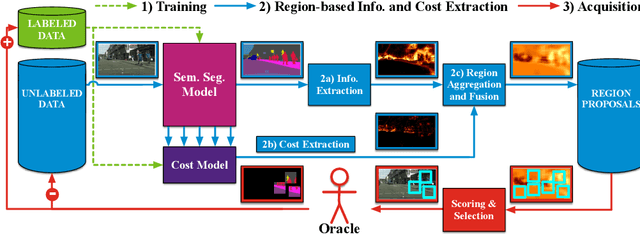
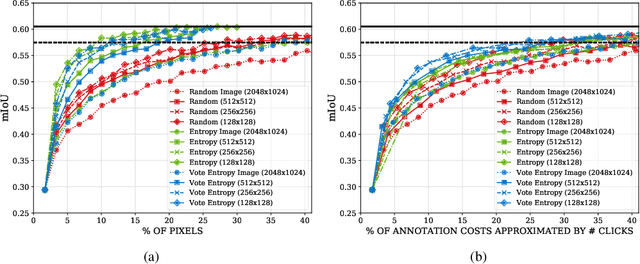
State of the art methods for semantic image segmentation are trained in a supervised fashion using a large corpus of fully labeled training images. However, gathering such a corpus is expensive, due to human annotation effort, in contrast to gathering unlabeled data. We propose an active learning-based strategy, called CEREALS, in which a human only has to hand-label a few, automatically selected, regions within an unlabeled image corpus. This minimizes human annotation effort while maximizing the performance of a semantic image segmentation method. The automatic selection procedure is achieved by: a) using a suitable information measure combined with an estimate about human annotation effort, which is inferred from a learned cost model, and b) exploiting the spatial coherency of an image. The performance of CEREALS is demonstrated on Cityscapes, where we are able to reduce the annotation effort to 17%, while keeping 95% of the mean Intersection over Union (mIoU) of a model that was trained with the fully annotated training set of Cityscapes.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
Oct 09, 2018
This document summarizes the 4th International Workshop on Recovering 6D Object Pose which was organized in conjunction with ECCV 2018 in Munich. The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation. The workshop was attended by 100+ people working on relevant topics in both academia and industry who shared up-to-date advances and discussed open problems.
Geometric Image Synthesis
Sep 12, 2018
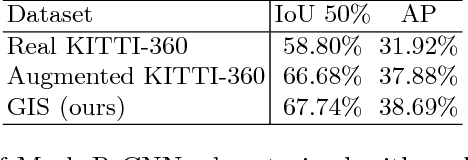
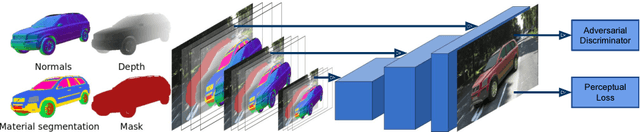

The task of generating natural images from 3D scenes has been a long standing goal in computer graphics. On the other hand, recent developments in deep neural networks allow for trainable models that can produce natural-looking images with little or no knowledge about the scene structure. While the generated images often consist of realistic looking local patterns, the overall structure of the generated images is often inconsistent. In this work we propose a trainable, geometry-aware image generation method that leverages various types of scene information, including geometry and segmentation, to create realistic looking natural images that match the desired scene structure. Our geometrically-consistent image synthesis method is a deep neural network, called Geometry to Image Synthesis (GIS) framework, which retains the advantages of a trainable method, e.g., differentiability and adaptiveness, but, at the same time, makes a step towards the generalizability, control and quality output of modern graphics rendering engines. We utilize the GIS framework to insert vehicles in outdoor driving scenes, as well as to generate novel views of objects from the Linemod dataset. We qualitatively show that our network is able to generalize beyond the training set to novel scene geometries, object shapes and segmentations. Furthermore, we quantitatively show that the GIS framework can be used to synthesize large amounts of training data which proves beneficial for training instance segmentation models.
Analyzing Inverse Problems with Invertible Neural Networks
Sep 10, 2018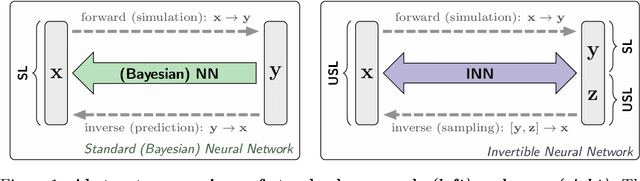
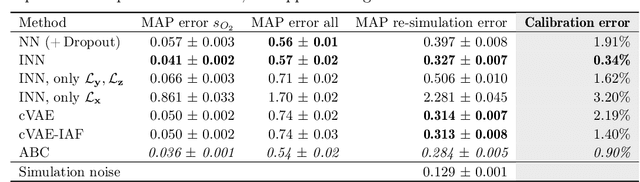
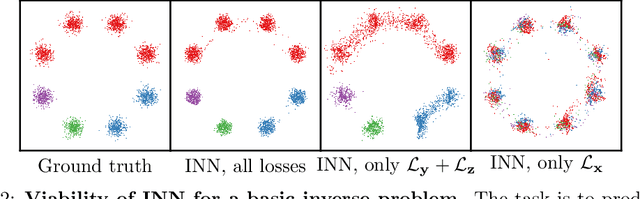
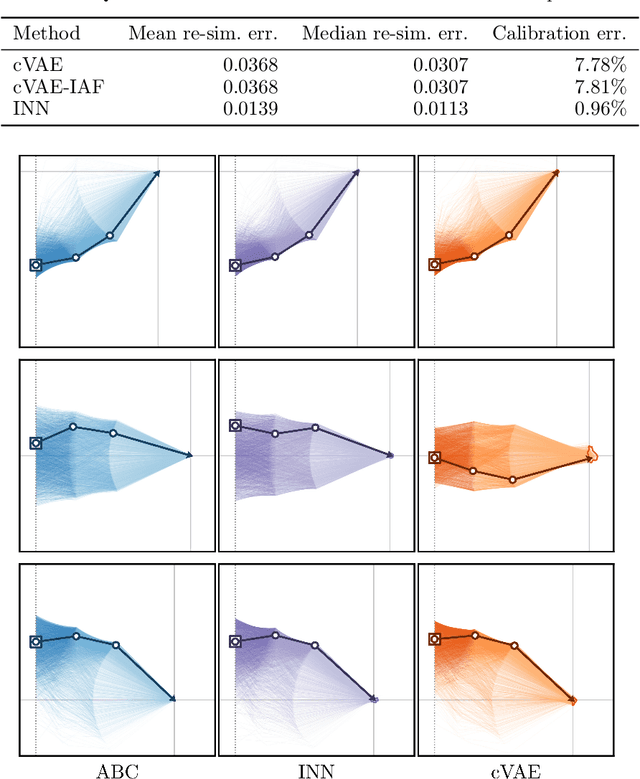
In many tasks, in particular in natural science, the goal is to determine hidden system parameters from a set of measurements. Often, the forward process from parameter- to measurement-space is a well-defined function, whereas the inverse problem is ambiguous: one measurement may map to multiple different sets of parameters. In this setting, the posterior parameter distribution, conditioned on an input measurement, has to be determined. We argue that a particular class of neural networks is well suited for this task -- so-called Invertible Neural Networks (INNs). Although INNs are not new, they have, so far, received little attention in literature. While classical neural networks attempt to solve the ambiguous inverse problem directly, INNs are able to learn it jointly with the well-defined forward process, using additional latent output variables to capture the information otherwise lost. Given a specific measurement and sampled latent variables, the inverse pass of the INN provides a full distribution over parameter space. We verify experimentally, on artificial data and real-world problems from astrophysics and medicine, that INNs are a powerful analysis tool to find multi-modalities in parameter space, to uncover parameter correlations, and to identify unrecoverable parameters.
BOP: Benchmark for 6D Object Pose Estimation
Aug 24, 2018
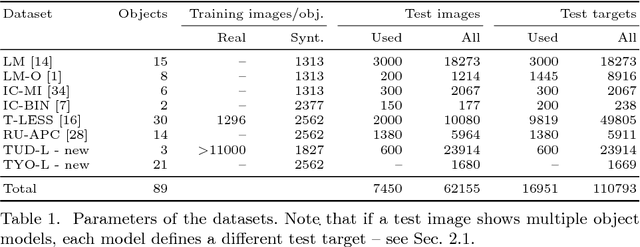

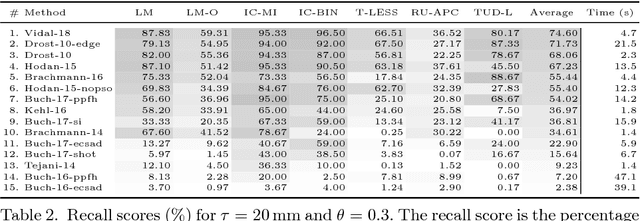
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image. The training data consists of a texture-mapped 3D object model or images of the object in known 6D poses. The benchmark comprises of: i) eight datasets in a unified format that cover different practical scenarios, including two new datasets focusing on varying lighting conditions, ii) an evaluation methodology with a pose-error function that deals with pose ambiguities, iii) a comprehensive evaluation of 15 diverse recent methods that captures the status quo of the field, and iv) an online evaluation system that is open for continuous submission of new results. The evaluation shows that methods based on point-pair features currently perform best, outperforming template matching methods, learning-based methods and methods based on 3D local features. The project website is available at bop.felk.cvut.cz.
Mapping Auto-context Decision Forests to Deep ConvNets for Semantic Segmentation
Aug 13, 2018

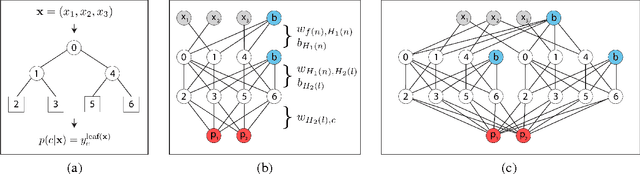
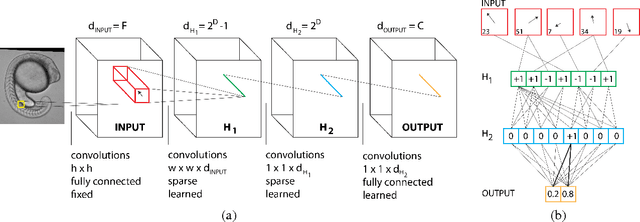
We consider the task of pixel-wise semantic segmentation given a small set of labeled training images. Among two of the most popular techniques to address this task are Decision Forests (DF) and Neural Networks (NN). In this work, we explore the relationship between two special forms of these techniques: stacked DFs (namely Auto-context) and deep Convolutional Neural Networks (ConvNet). Our main contribution is to show that Auto-context can be mapped to a deep ConvNet with novel architecture, and thereby trained end-to-end. This mapping can be used as an initialization of a deep ConvNet, enabling training even in the face of very limited amounts of training data. We also demonstrate an approximate mapping back from the refined ConvNet to a second stacked DF, with improved performance over the original. We experimentally verify that these mappings outperform stacked DFs for two different applications in computer vision and biology: Kinect-based body part labeling from depth images, and somite segmentation in microscopy images of developing zebrafish. Finally, we revisit the core mapping from a Decision Tree (DT) to a NN, and show that it is also possible to map a fuzzy DT, with sigmoidal split decisions, to a NN. This addresses multiple limitations of the previous mapping, and yields new insights into the popular Rectified Linear Unit (ReLU), and more recently proposed concatenated ReLU (CReLU), activation functions.
iPose: Instance-Aware 6D Pose Estimation of Partly Occluded Objects
Jun 18, 2018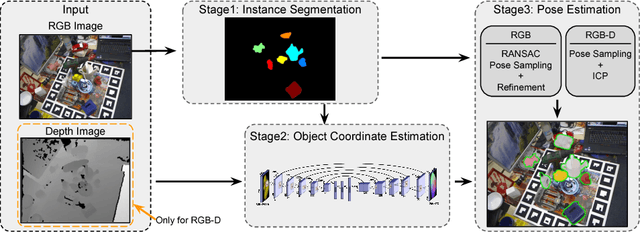
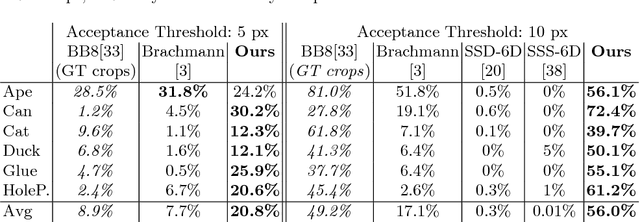

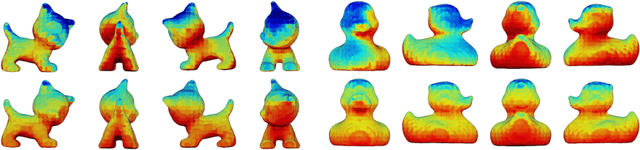
We address the task of 6D pose estimation of known rigid objects from single input images in scenarios where the objects are partly occluded. Recent RGB-D-based methods are robust to moderate degrees of occlusion. For RGB inputs, no previous method works well for partly occluded objects. Our main contribution is to present the first deep learning-based system that estimates accurate poses for partly occluded objects from RGB-D and RGB input. We achieve this with a new instance-aware pipeline that decomposes 6D object pose estimation into a sequence of simpler steps, where each step removes specific aspects of the problem. The first step localizes all known objects in the image using an instance segmentation network, and hence eliminates surrounding clutter and occluders. The second step densely maps pixels to 3D object surface positions, so called object coordinates, using an encoder-decoder network, and hence eliminates object appearance. The third, and final, step predicts the 6D pose using geometric optimization. We demonstrate that we significantly outperform the state-of-the-art for pose estimation of partly occluded objects for both RGB and RGB-D input.
Deep Object Co-Segmentation
Apr 17, 2018



This work presents a deep object co-segmentation (DOCS) approach for segmenting common objects of the same class within a pair of images. This means that the method learns to ignore common, or uncommon, background stuff and focuses on objects. If multiple object classes are presented in the image pair, they are jointly extracted as foreground. To address this task, we propose a CNN-based Siamese encoder-decoder architecture. The encoder extracts high-level semantic features of the foreground objects, a mutual correlation layer detects the common objects, and finally, the decoder generates the output foreground masks for each image. To train our model, we compile a large object co-segmentation dataset consisting of image pairs from the PASCAL VOC dataset with common objects masks. We evaluate our approach on commonly used datasets for co-segmentation tasks and observe that our approach consistently outperforms competing methods, for both seen and unseen object classes.