 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Representation Learning by Discovering Reliable Image Relations
Nov 18, 2019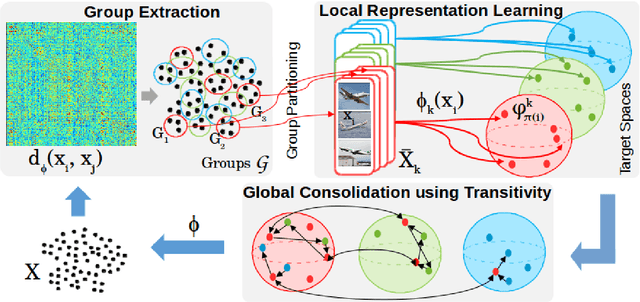
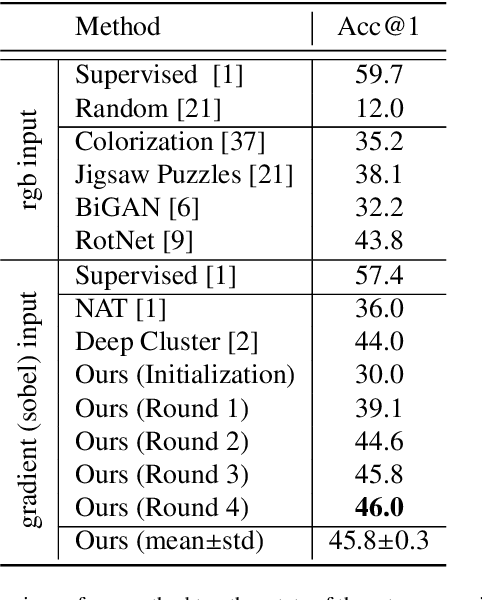
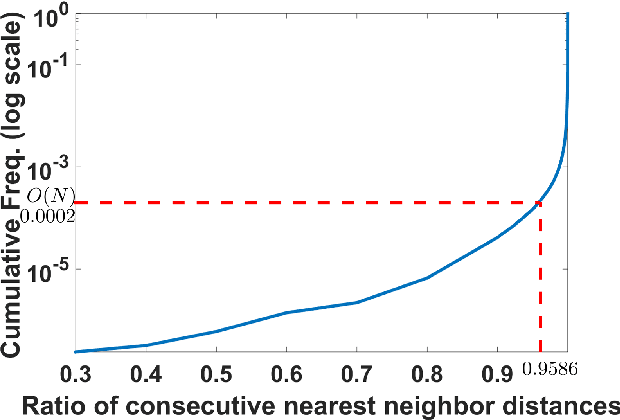
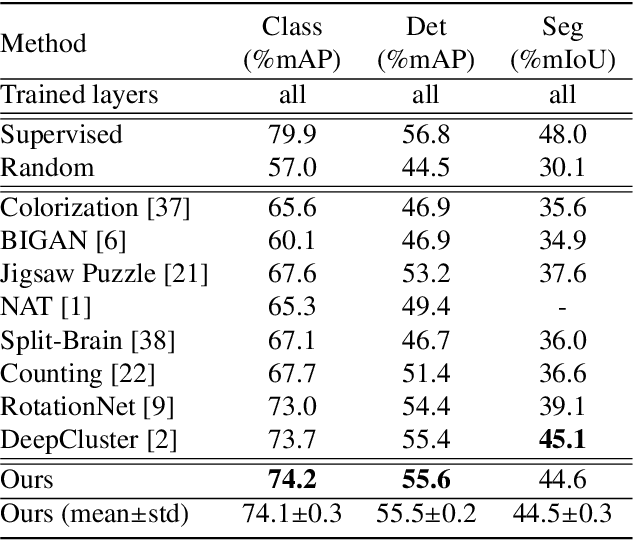
Learning robust representations that allow to reliably establish relations between images is of paramount importance for virtually all of computer vision. Annotating the quadratic number of pairwise relations between training images is simply not feasible, while unsupervised inference is prone to noise, thus leaving the vast majority of these relations to be unreliable. To nevertheless find those relations which can be reliably utilized for learning, we follow a divide-and-conquer strategy: We find reliable similarities by extracting compact groups of images and reliable dissimilarities by partitioning these groups into subsets, converting the complicated overall problem into few reliable local subproblems. For each of the subsets we obtain a representation by learning a mapping to a target feature space so that their reliable relations are kept. Transitivity relations between the subsets are then exploited to consolidate the local solutions into a concerted global representation. While iterating between grouping, partitioning, and learning, we can successively use more and more reliable relations which, in turn, improves our image representation. In experiments, our approach shows state-of-the-art performance on unsupervised classification on ImageNet with 46.0% and competes favorably on different transfer learning tasks on PASCAL VOC.
CEREALS - Cost-Effective REgion-based Active Learning for Semantic Segmentation
Oct 23, 2018

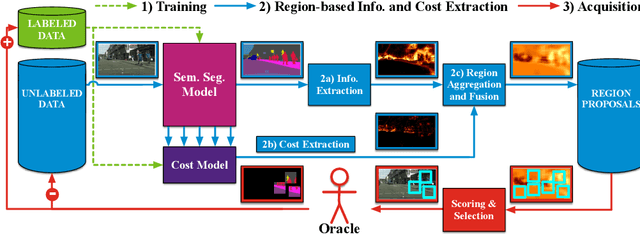
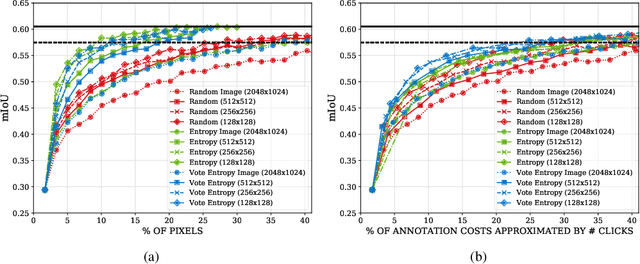
State of the art methods for semantic image segmentation are trained in a supervised fashion using a large corpus of fully labeled training images. However, gathering such a corpus is expensive, due to human annotation effort, in contrast to gathering unlabeled data. We propose an active learning-based strategy, called CEREALS, in which a human only has to hand-label a few, automatically selected, regions within an unlabeled image corpus. This minimizes human annotation effort while maximizing the performance of a semantic image segmentation method. The automatic selection procedure is achieved by: a) using a suitable information measure combined with an estimate about human annotation effort, which is inferred from a learned cost model, and b) exploiting the spatial coherency of an image. The performance of CEREALS is demonstrated on Cityscapes, where we are able to reduce the annotation effort to 17%, while keeping 95% of the mean Intersection over Union (mIoU) of a model that was trained with the fully annotated training set of Cityscapes.