 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022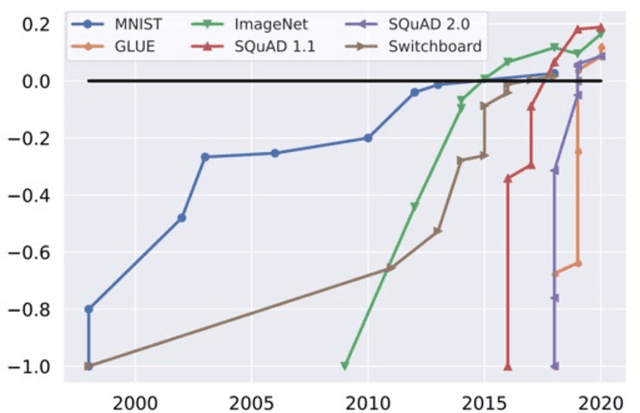
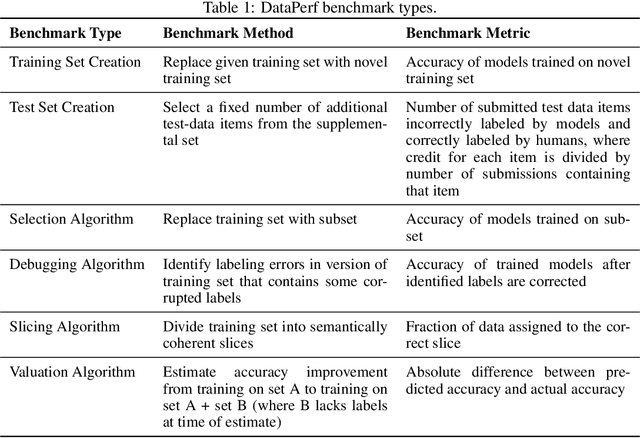
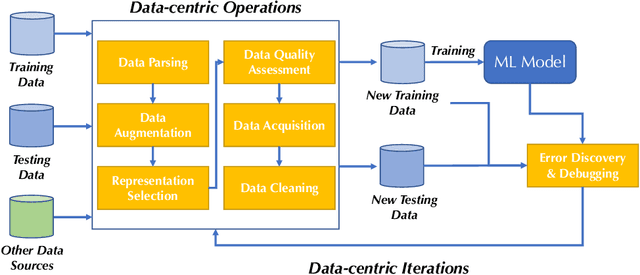
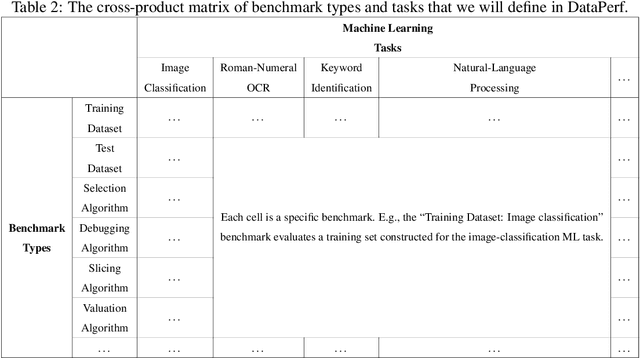
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
FEL: High Capacity Learning for Recommendation and Ranking via Federated Ensemble Learning
Jun 07, 2022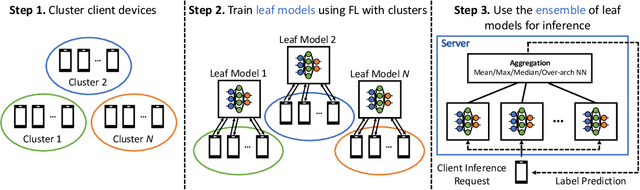
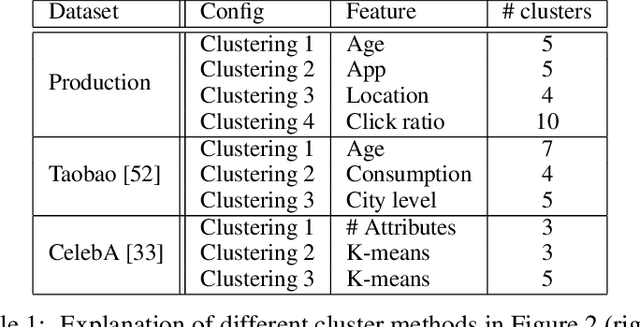
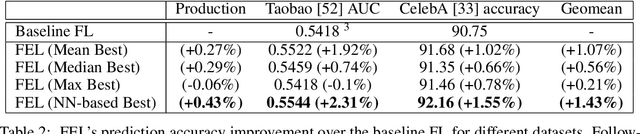
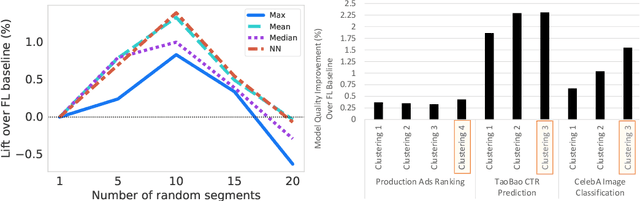
Federated learning (FL) has emerged as an effective approach to address consumer privacy needs. FL has been successfully applied to certain machine learning tasks, such as training smart keyboard models and keyword spotting. Despite FL's initial success, many important deep learning use cases, such as ranking and recommendation tasks, have been limited from on-device learning. One of the key challenges faced by practical FL adoption for DL-based ranking and recommendation is the prohibitive resource requirements that cannot be satisfied by modern mobile systems. We propose Federated Ensemble Learning (FEL) as a solution to tackle the large memory requirement of deep learning ranking and recommendation tasks. FEL enables large-scale ranking and recommendation model training on-device by simultaneously training multiple model versions on disjoint clusters of client devices. FEL integrates the trained sub-models via an over-arch layer into an ensemble model that is hosted on the server. Our experiments demonstrate that FEL leads to 0.43-2.31% model quality improvement over traditional on-device federated learning - a significant improvement for ranking and recommendation system use cases.
Infinite Recommendation Networks: A Data-Centric Approach
Jun 03, 2022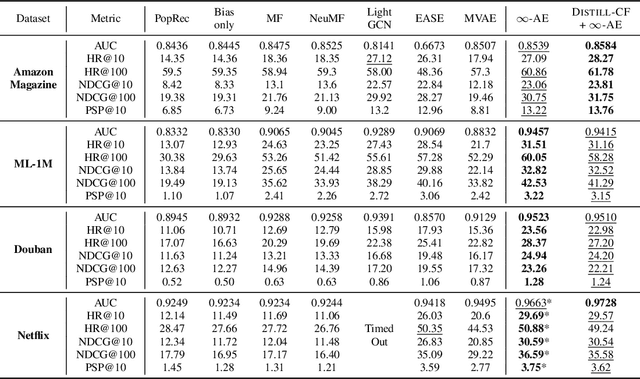
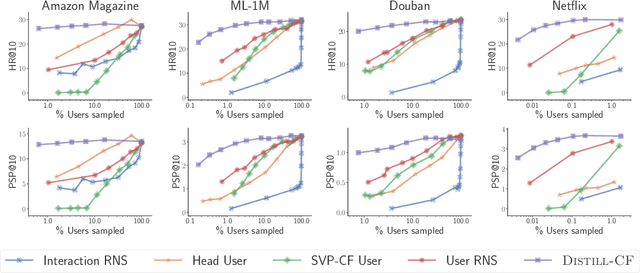
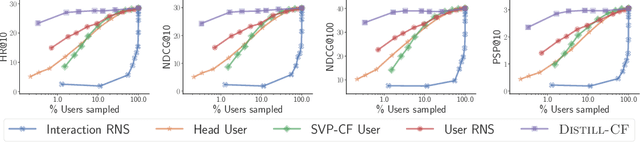
We leverage the Neural Tangent Kernel and its equivalence to training infinitely-wide neural networks to devise $\infty$-AE: an autoencoder with infinitely-wide bottleneck layers. The outcome is a highly expressive yet simplistic recommendation model with a single hyper-parameter and a closed-form solution. Leveraging $\infty$-AE's simplicity, we also develop Distill-CF for synthesizing tiny, high-fidelity data summaries which distill the most important knowledge from the extremely large and sparse user-item interaction matrix for efficient and accurate subsequent data-usage like model training, inference, architecture search, etc. This takes a data-centric approach to recommendation, where we aim to improve the quality of logged user-feedback data for subsequent modeling, independent of the learning algorithm. We particularly utilize the concept of differentiable Gumbel-sampling to handle the inherent data heterogeneity, sparsity, and semi-structuredness, while being scalable to datasets with hundreds of millions of user-item interactions. Both of our proposed approaches significantly outperform their respective state-of-the-art and when used together, we observe 96-105% of $\infty$-AE's performance on the full dataset with as little as 0.1% of the original dataset size, leading us to explore the counter-intuitive question: Is more data what you need for better recommendation?
Towards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity
May 30, 2022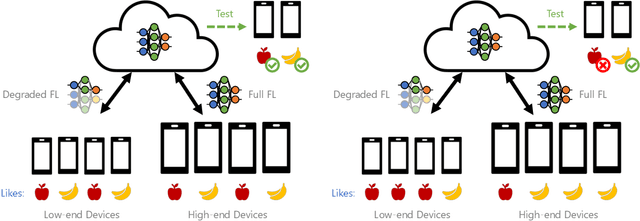
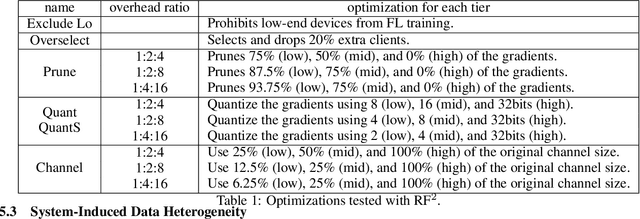
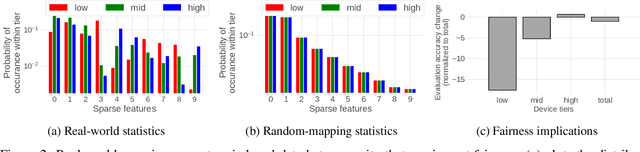
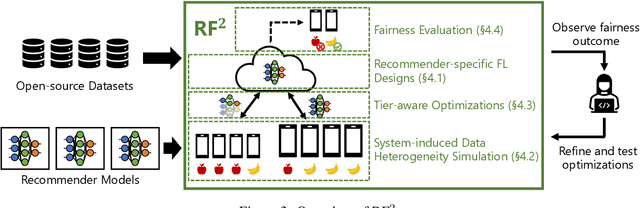
Federated learning (FL) is an effective mechanism for data privacy in recommender systems by running machine learning model training on-device. While prior FL optimizations tackled the data and system heterogeneity challenges faced by FL, they assume the two are independent of each other. This fundamental assumption is not reflective of real-world, large-scale recommender systems -- data and system heterogeneity are tightly intertwined. This paper takes a data-driven approach to show the inter-dependence of data and system heterogeneity in real-world data and quantifies its impact on the overall model quality and fairness. We design a framework, RF^2, to model the inter-dependence and evaluate its impact on state-of-the-art model optimization techniques for federated recommendation tasks. We demonstrate that the impact on fairness can be severe under realistic heterogeneity scenarios, by up to 15.8--41x compared to a simple setup assumed in most (if not all) prior work. It means when realistic system-induced data heterogeneity is not properly modeled, the fairness impact of an optimization can be downplayed by up to 41x. The result shows that modeling realistic system-induced data heterogeneity is essential to achieving fair federated recommendation learning. We plan to open-source RF^2 to enable future design and evaluation of FL innovations.
RecShard: Statistical Feature-Based Memory Optimization for Industry-Scale Neural Recommendation
Jan 25, 2022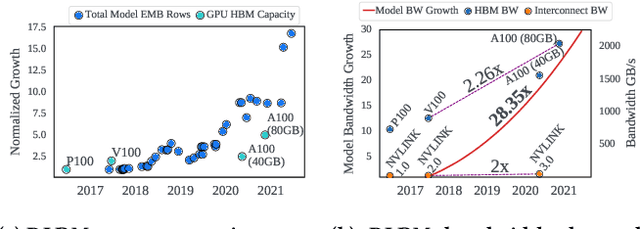
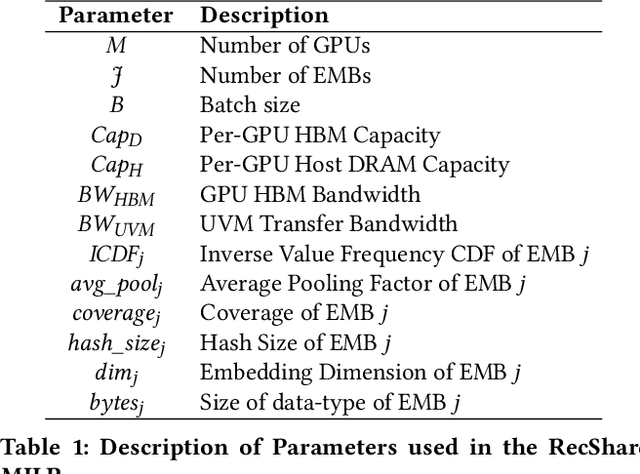
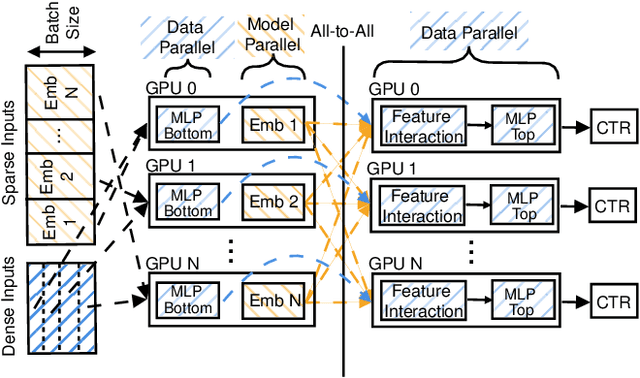
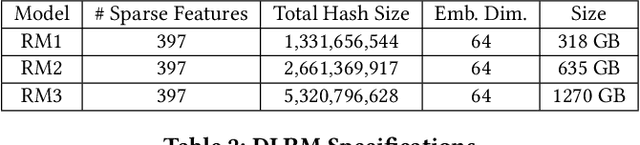
We propose RecShard, a fine-grained embedding table (EMB) partitioning and placement technique for deep learning recommendation models (DLRMs). RecShard is designed based on two key observations. First, not all EMBs are equal, nor all rows within an EMB are equal in terms of access patterns. EMBs exhibit distinct memory characteristics, providing performance optimization opportunities for intelligent EMB partitioning and placement across a tiered memory hierarchy. Second, in modern DLRMs, EMBs function as hash tables. As a result, EMBs display interesting phenomena, such as the birthday paradox, leaving EMBs severely under-utilized. RecShard determines an optimal EMB sharding strategy for a set of EMBs based on training data distributions and model characteristics, along with the bandwidth characteristics of the underlying tiered memory hierarchy. In doing so, RecShard achieves over 6 times higher EMB training throughput on average for capacity constrained DLRMs. The throughput increase comes from improved EMB load balance by over 12 times and from the reduced access to the slower memory by over 87 times.
On Sampling Collaborative Filtering Datasets
Jan 13, 2022
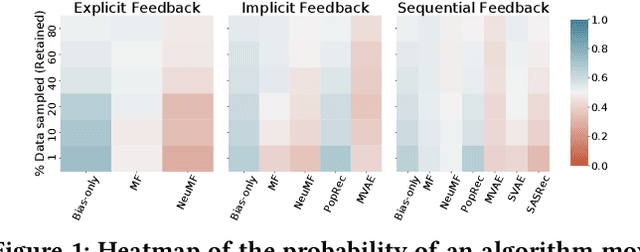
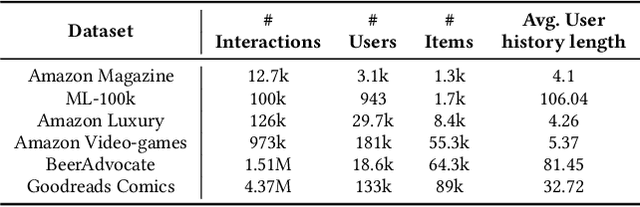
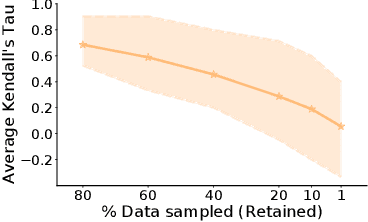
We study the practical consequences of dataset sampling strategies on the ranking performance of recommendation algorithms. Recommender systems are generally trained and evaluated on samples of larger datasets. Samples are often taken in a naive or ad-hoc fashion: e.g. by sampling a dataset randomly or by selecting users or items with many interactions. As we demonstrate, commonly-used data sampling schemes can have significant consequences on algorithm performance. Following this observation, this paper makes three main contributions: (1) characterizing the effect of sampling on algorithm performance, in terms of algorithm and dataset characteristics (e.g. sparsity characteristics, sequential dynamics, etc.); (2) designing SVP-CF, which is a data-specific sampling strategy, that aims to preserve the relative performance of models after sampling, and is especially suited to long-tailed interaction data; and (3) developing an oracle, Data-Genie, which can suggest the sampling scheme that is most likely to preserve model performance for a given dataset. The main benefit of Data-Genie is that it will allow recommender system practitioners to quickly prototype and compare various approaches, while remaining confident that algorithm performance will be preserved, once the algorithm is retrained and deployed on the complete data. Detailed experiments show that using Data-Genie, we can discard upto 5x more data than any sampling strategy with the same level of performance.
Papaya: Practical, Private, and Scalable Federated Learning
Nov 08, 2021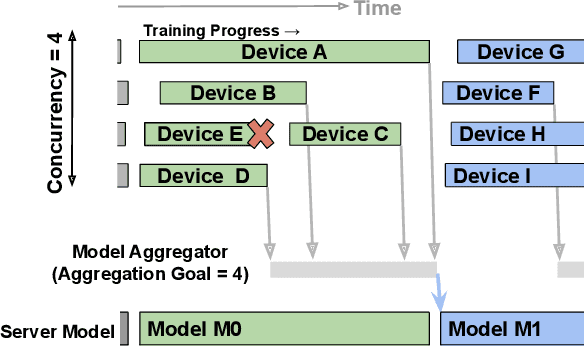
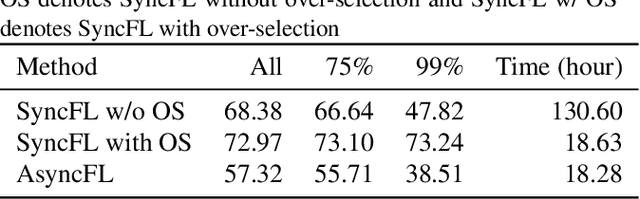
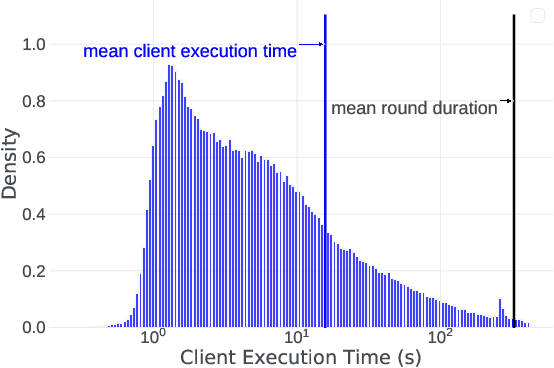
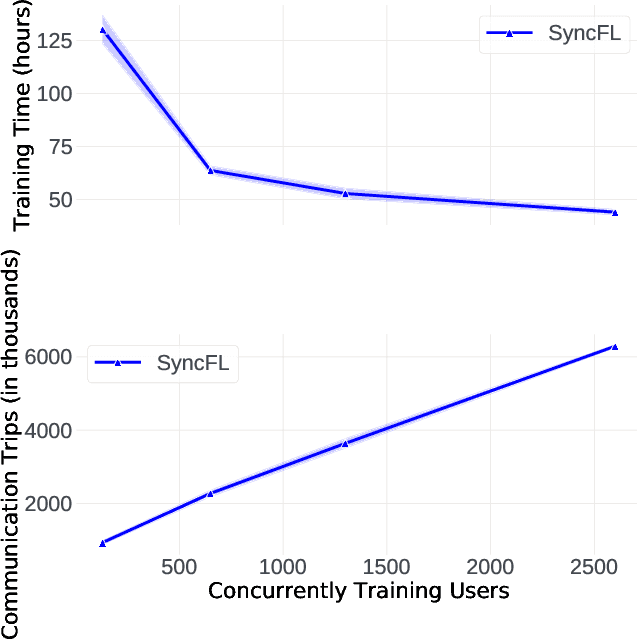
Cross-device Federated Learning (FL) is a distributed learning paradigm with several challenges that differentiate it from traditional distributed learning, variability in the system characteristics on each device, and millions of clients coordinating with a central server being primary ones. Most FL systems described in the literature are synchronous - they perform a synchronized aggregation of model updates from individual clients. Scaling synchronous FL is challenging since increasing the number of clients training in parallel leads to diminishing returns in training speed, analogous to large-batch training. Moreover, stragglers hinder synchronous FL training. In this work, we outline a production asynchronous FL system design. Our work tackles the aforementioned issues, sketches of some of the system design challenges and their solutions, and touches upon principles that emerged from building a production FL system for millions of clients. Empirically, we demonstrate that asynchronous FL converges faster than synchronous FL when training across nearly one hundred million devices. In particular, in high concurrency settings, asynchronous FL is 5x faster and has nearly 8x less communication overhead than synchronous FL.
Sustainable AI: Environmental Implications, Challenges and Opportunities
Oct 30, 2021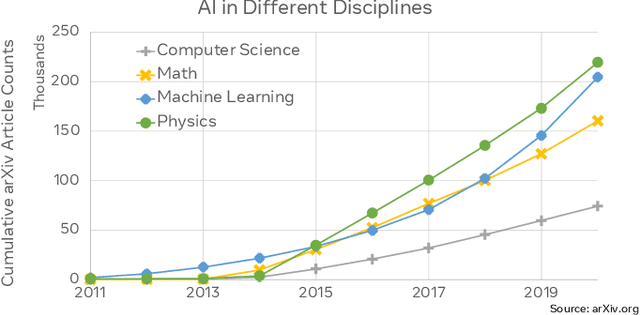
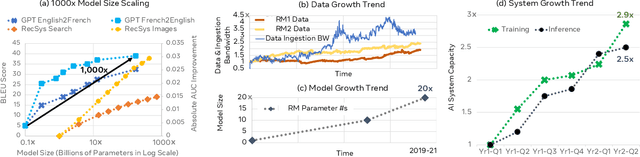
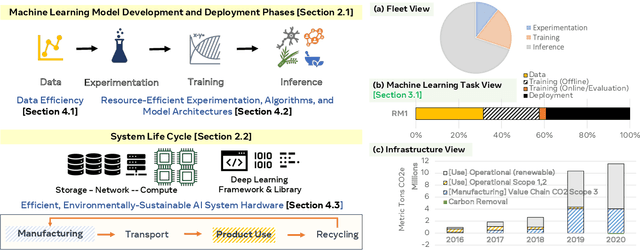
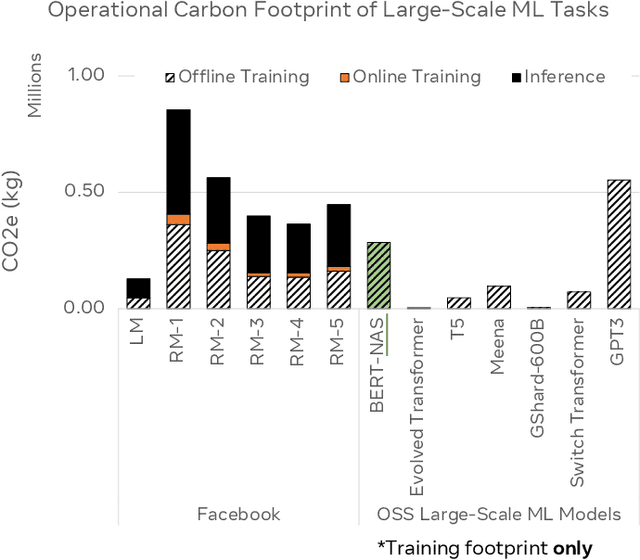
This paper explores the environmental impact of the super-linear growth trends for AI from a holistic perspective, spanning Data, Algorithms, and System Hardware. We characterize the carbon footprint of AI computing by examining the model development cycle across industry-scale machine learning use cases and, at the same time, considering the life cycle of system hardware. Taking a step further, we capture the operational and manufacturing carbon footprint of AI computing and present an end-to-end analysis for what and how hardware-software design and at-scale optimization can help reduce the overall carbon footprint of AI. Based on the industry experience and lessons learned, we share the key challenges and chart out important development directions across the many dimensions of AI. We hope the key messages and insights presented in this paper can inspire the community to advance the field of AI in an environmentally-responsible manner.
Understanding and Co-designing the Data Ingestion Pipeline for Industry-Scale RecSys Training
Aug 20, 2021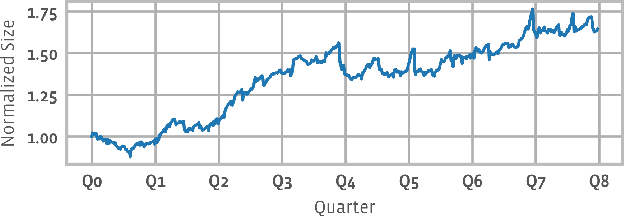
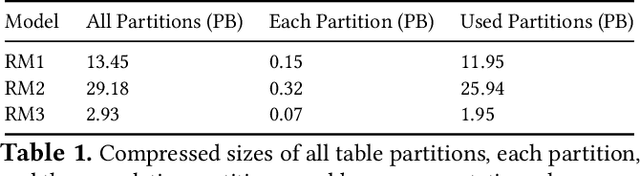
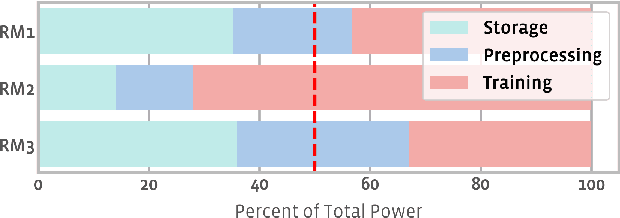

The data ingestion pipeline, responsible for storing and preprocessing training data, is an important component of any machine learning training job. At Facebook, we use recommendation models extensively across our services. The data ingestion requirements to train these models are substantial. In this paper, we present an extensive characterization of the data ingestion challenges for industry-scale recommendation model training. First, dataset storage requirements are massive and variable; exceeding local storage capacities. Secondly, reading and preprocessing data is computationally expensive, requiring substantially more compute, memory, and network resources than are available on trainers themselves. These demands result in drastically reduced training throughput, and thus wasted GPU resources, when current on-trainer preprocessing solutions are used. To address these challenges, we present a disaggregated data ingestion pipeline. It includes a central data warehouse built on distributed storage nodes. We introduce Data PreProcessing Service (DPP), a fully disaggregated preprocessing service that scales to hundreds of nodes, eliminating data stalls that can reduce training throughput by 56%. We implement important optimizations across storage and DPP, increasing storage and preprocessing throughput by 1.9x and 2.3x, respectively, addressing the substantial power requirements of data ingestion. We close with lessons learned and cover the important remaining challenges and opportunities surrounding data ingestion at scale.
AutoFL: Enabling Heterogeneity-Aware Energy Efficient Federated Learning
Jul 16, 2021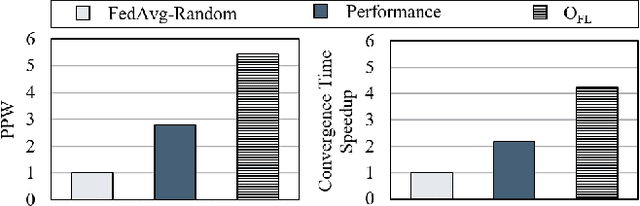

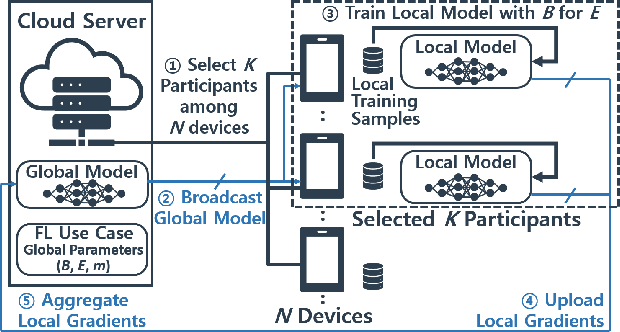
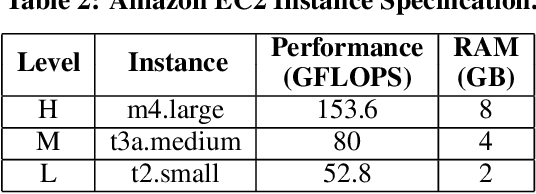
Federated learning enables a cluster of decentralized mobile devices at the edge to collaboratively train a shared machine learning model, while keeping all the raw training samples on device. This decentralized training approach is demonstrated as a practical solution to mitigate the risk of privacy leakage. However, enabling efficient FL deployment at the edge is challenging because of non-IID training data distribution, wide system heterogeneity and stochastic-varying runtime effects in the field. This paper jointly optimizes time-to-convergence and energy efficiency of state-of-the-art FL use cases by taking into account the stochastic nature of edge execution. We propose AutoFL by tailor-designing a reinforcement learning algorithm that learns and determines which K participant devices and per-device execution targets for each FL model aggregation round in the presence of stochastic runtime variance, system and data heterogeneity. By considering the unique characteristics of FL edge deployment judiciously, AutoFL achieves 3.6 times faster model convergence time and 4.7 and 5.2 times higher energy efficiency for local clients and globally over the cluster of K participants, respectively.