 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Retrieval Scaling with Hierarchical Indexing for Large Scale Recommendation
Apr 14, 2026The increase in data volume, computational resources, and model parameters during training has led to the development of numerous large-scale industrial retrieval models for recommendation tasks. However, effectively and efficiently deploying these large-scale foundational retrieval models remains a critical challenge that has not been fully addressed. Common quick-win solutions for deploying these massive models include relying on offline computations (such as cached user dictionaries) or distilling large models into smaller ones. Yet, both approaches fall short of fully leveraging the representational and inference capabilities of foundational models. In this paper, we explore whether it is possible to learn a hierarchical organization over the memory of foundational retrieval models. Such a hierarchical structure would enable more efficient search by reducing retrieval costs while preserving exactness. To achieve this, we propose jointly learning a hierarchical index using cross-attention and residual quantization for large-scale retrieval models. We also present its real-world deployment at Meta, supporting daily advertisement recommendations for billions of Facebook and Instagram users. Interestingly, we discovered that the intermediate nodes in the learned index correspond to a small set of high-quality data. Fine-tuning the model on this set further improves inference performance, and concretize the concept of "test-time training" within the recommendation system domain. We demonstrate these findings using both internal and public datasets with strong baseline comparisons and hope they contribute to the community's efforts in developing the next generation of foundational retrieval models.
Towards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity
May 30, 2022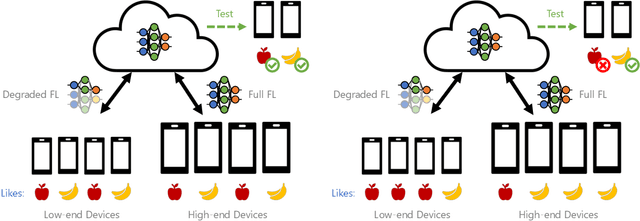
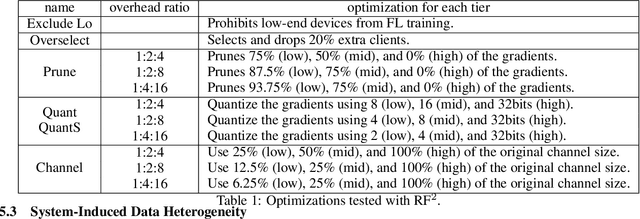
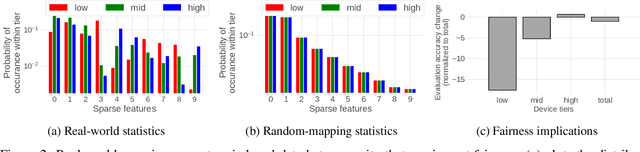
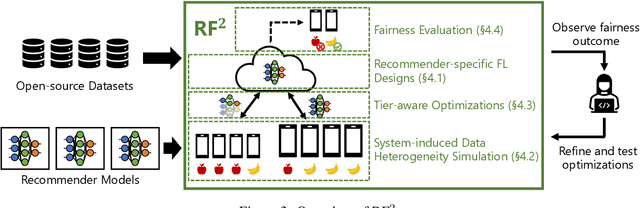
Federated learning (FL) is an effective mechanism for data privacy in recommender systems by running machine learning model training on-device. While prior FL optimizations tackled the data and system heterogeneity challenges faced by FL, they assume the two are independent of each other. This fundamental assumption is not reflective of real-world, large-scale recommender systems -- data and system heterogeneity are tightly intertwined. This paper takes a data-driven approach to show the inter-dependence of data and system heterogeneity in real-world data and quantifies its impact on the overall model quality and fairness. We design a framework, RF^2, to model the inter-dependence and evaluate its impact on state-of-the-art model optimization techniques for federated recommendation tasks. We demonstrate that the impact on fairness can be severe under realistic heterogeneity scenarios, by up to 15.8--41x compared to a simple setup assumed in most (if not all) prior work. It means when realistic system-induced data heterogeneity is not properly modeled, the fairness impact of an optimization can be downplayed by up to 41x. The result shows that modeling realistic system-induced data heterogeneity is essential to achieving fair federated recommendation learning. We plan to open-source RF^2 to enable future design and evaluation of FL innovations.