 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelfIE: Self-Interpretation of Large Language Model Embeddings
Mar 26, 2024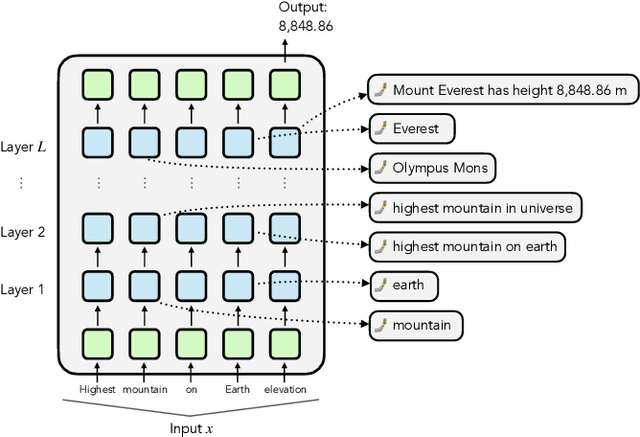
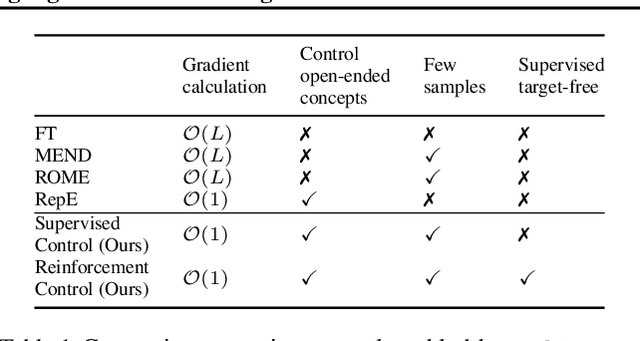
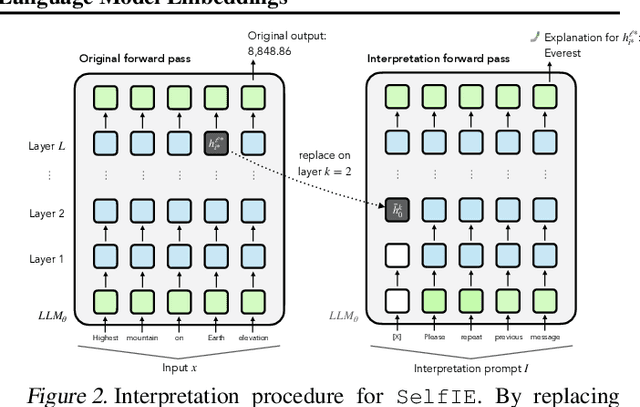
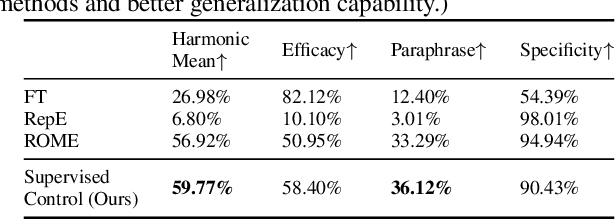
How do large language models (LLMs) obtain their answers? The ability to explain and control an LLM's reasoning process is key for reliability, transparency, and future model developments. We propose SelfIE (Self-Interpretation of Embeddings), a framework that enables LLMs to interpret their own embeddings in natural language by leveraging their ability to respond to inquiries about a given passage. Capable of interpreting open-world concepts in the hidden embeddings, SelfIE reveals LLM internal reasoning in cases such as making ethical decisions, internalizing prompt injection, and recalling harmful knowledge. SelfIE's text descriptions on hidden embeddings also open up new avenues to control LLM reasoning. We propose Supervised Control, which allows editing open-ended concepts while only requiring gradient computation of individual layer. We extend RLHF to hidden embeddings and propose Reinforcement Control that erases harmful knowledge in LLM without supervision targets.
PaperBot: Learning to Design Real-World Tools Using Paper
Mar 14, 2024



Paper is a cheap, recyclable, and clean material that is often used to make practical tools. Traditional tool design either relies on simulation or physical analysis, which is often inaccurate and time-consuming. In this paper, we propose PaperBot, an approach that directly learns to design and use a tool in the real world using paper without human intervention. We demonstrated the effectiveness and efficiency of PaperBot on two tool design tasks: 1. learning to fold and throw paper airplanes for maximum travel distance 2. learning to cut paper into grippers that exert maximum gripping force. We present a self-supervised learning framework that learns to perform a sequence of folding, cutting, and dynamic manipulation actions in order to optimize the design and use of a tool. We deploy our system to a real-world two-arm robotic system to solve challenging design tasks that involve aerodynamics (paper airplane) and friction (paper gripper) that are impossible to simulate accurately.
GES: Generalized Exponential Splatting for Efficient Radiance Field Rendering
Feb 15, 2024



Advancements in 3D Gaussian Splatting have significantly accelerated 3D reconstruction and generation. However, it may require a large number of Gaussians, which creates a substantial memory footprint. This paper introduces GES (Generalized Exponential Splatting), a novel representation that employs Generalized Exponential Function (GEF) to model 3D scenes, requiring far fewer particles to represent a scene and thus significantly outperforming Gaussian Splatting methods in efficiency with a plug-and-play replacement ability for Gaussian-based utilities. GES is validated theoretically and empirically in both principled 1D setup and realistic 3D scenes. It is shown to represent signals with sharp edges more accurately, which are typically challenging for Gaussians due to their inherent low-pass characteristics. Our empirical analysis demonstrates that GEF outperforms Gaussians in fitting natural-occurring signals (e.g. squares, triangles, and parabolic signals), thereby reducing the need for extensive splitting operations that increase the memory footprint of Gaussian Splatting. With the aid of a frequency-modulated loss, GES achieves competitive performance in novel-view synthesis benchmarks while requiring less than half the memory storage of Gaussian Splatting and increasing the rendering speed by up to 39%. The code is available on the project website https://abdullahamdi.com/ges .
pix2gestalt: Amodal Segmentation by Synthesizing Wholes
Jan 25, 2024



We introduce pix2gestalt, a framework for zero-shot amodal segmentation, which learns to estimate the shape and appearance of whole objects that are only partially visible behind occlusions. By capitalizing on large-scale diffusion models and transferring their representations to this task, we learn a conditional diffusion model for reconstructing whole objects in challenging zero-shot cases, including examples that break natural and physical priors, such as art. As training data, we use a synthetically curated dataset containing occluded objects paired with their whole counterparts. Experiments show that our approach outperforms supervised baselines on established benchmarks. Our model can furthermore be used to significantly improve the performance of existing object recognition and 3D reconstruction methods in the presence of occlusions.
Raidar: geneRative AI Detection viA Rewriting
Jan 23, 2024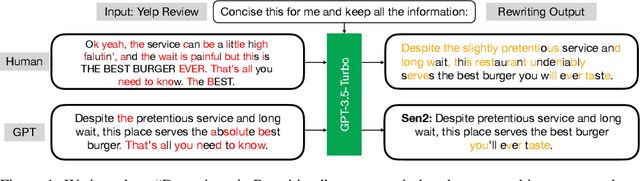
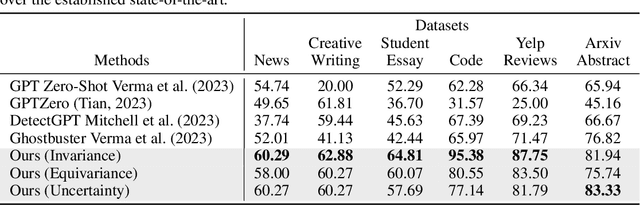
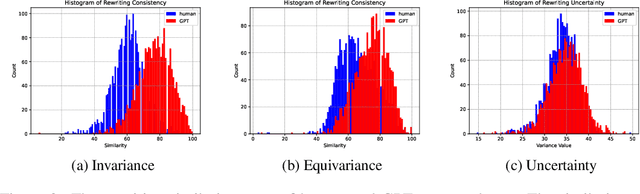
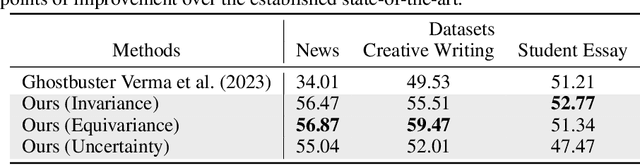
We find that large language models (LLMs) are more likely to modify human-written text than AI-generated text when tasked with rewriting. This tendency arises because LLMs often perceive AI-generated text as high-quality, leading to fewer modifications. We introduce a method to detect AI-generated content by prompting LLMs to rewrite text and calculating the editing distance of the output. We dubbed our geneRative AI Detection viA Rewriting method Raidar. Raidar significantly improves the F1 detection scores of existing AI content detection models -- both academic and commercial -- across various domains, including News, creative writing, student essays, code, Yelp reviews, and arXiv papers, with gains of up to 29 points. Operating solely on word symbols without high-dimensional features, our method is compatible with black box LLMs, and is inherently robust on new content. Our results illustrate the unique imprint of machine-generated text through the lens of the machines themselves.
Remote Sensing Vision-Language Foundation Models without Annotations via Ground Remote Alignment
Dec 12, 2023We introduce a method to train vision-language models for remote-sensing images without using any textual annotations. Our key insight is to use co-located internet imagery taken on the ground as an intermediary for connecting remote-sensing images and language. Specifically, we train an image encoder for remote sensing images to align with the image encoder of CLIP using a large amount of paired internet and satellite images. Our unsupervised approach enables the training of a first-of-its-kind large-scale vision language model (VLM) for remote sensing images at two different resolutions. We show that these VLMs enable zero-shot, open-vocabulary image classification, retrieval, segmentation and visual question answering for satellite images. On each of these tasks, our VLM trained without textual annotations outperforms existing VLMs trained with supervision, with gains of up to 20% for classification and 80% for segmentation.
Interpreting and Controlling Vision Foundation Models via Text Explanations
Oct 16, 2023Large-scale pre-trained vision foundation models, such as CLIP, have become de facto backbones for various vision tasks. However, due to their black-box nature, understanding the underlying rules behind these models' predictions and controlling model behaviors have remained open challenges. We present a framework for interpreting vision transformer's latent tokens with natural language. Given a latent token, our framework retains its semantic information to the final layer using transformer's local operations and retrieves the closest text for explanation. Our approach enables understanding of model visual reasoning procedure without needing additional model training or data collection. Based on the obtained interpretations, our framework allows for model editing that controls model reasoning behaviors and improves model robustness against biases and spurious correlations.
SHIFT3D: Synthesizing Hard Inputs For Tricking 3D Detectors
Sep 11, 2023



We present SHIFT3D, a differentiable pipeline for generating 3D shapes that are structurally plausible yet challenging to 3D object detectors. In safety-critical applications like autonomous driving, discovering such novel challenging objects can offer insight into unknown vulnerabilities of 3D detectors. By representing objects with a signed distanced function (SDF), we show that gradient error signals allow us to smoothly deform the shape or pose of a 3D object in order to confuse a downstream 3D detector. Importantly, the objects generated by SHIFT3D physically differ from the baseline object yet retain a semantically recognizable shape. Our approach provides interpretable failure modes for modern 3D object detectors, and can aid in preemptive discovery of potential safety risks within 3D perception systems before these risks become critical failures.
Objaverse-XL: A Universe of 10M+ 3D Objects
Jul 11, 2023Natural language processing and 2D vision models have attained remarkable proficiency on many tasks primarily by escalating the scale of training data. However, 3D vision tasks have not seen the same progress, in part due to the challenges of acquiring high-quality 3D data. In this work, we present Objaverse-XL, a dataset of over 10 million 3D objects. Our dataset comprises deduplicated 3D objects from a diverse set of sources, including manually designed objects, photogrammetry scans of landmarks and everyday items, and professional scans of historic and antique artifacts. Representing the largest scale and diversity in the realm of 3D datasets, Objaverse-XL enables significant new possibilities for 3D vision. Our experiments demonstrate the improvements enabled with the scale provided by Objaverse-XL. We show that by training Zero123 on novel view synthesis, utilizing over 100 million multi-view rendered images, we achieve strong zero-shot generalization abilities. We hope that releasing Objaverse-XL will enable further innovations in the field of 3D vision at scale.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.