 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDE: Collocation for Demonstration Encoding
May 07, 2021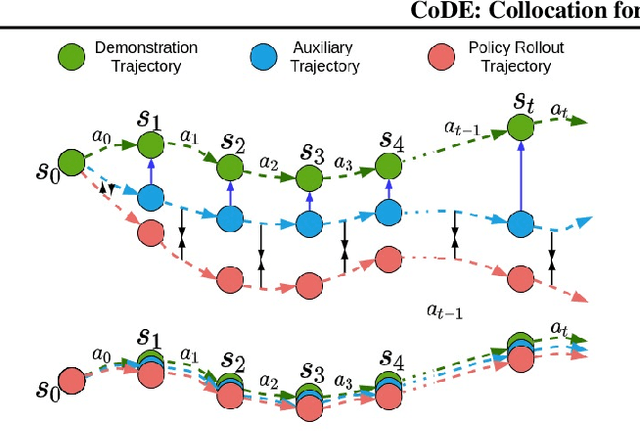
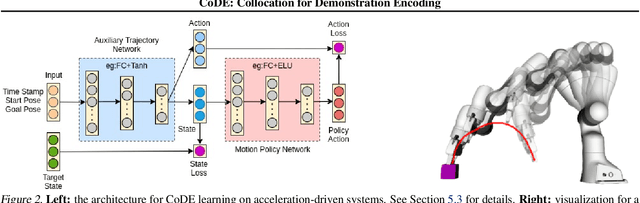
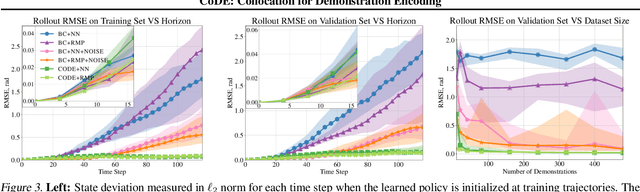
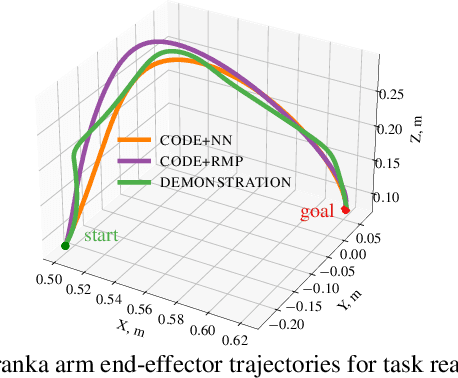
Roboticists frequently turn to Imitation learning (IL) for data efficient policy learning. Many IL methods, canonicalized by the seminal work on Dataset Aggregation (DAgger), combat distributional shift issues with older Behavior Cloning (BC) methods by introducing oracle experts. Unfortunately, access to oracle experts is often unrealistic in practice; data frequently comes from manual offline methods such as lead-through or teleoperation. We present a data-efficient imitation learning technique called Collocation for Demonstration Encoding (CoDE) that operates on only a fixed set of trajectory demonstrations by modeling learning as empirical risk minimization. We circumvent problematic back-propagation through time problems by introducing an auxiliary trajectory network taking inspiration from collocation techniques in optimal control. Our method generalizes well and is much more data efficient than standard BC methods. We present experiments on a 7-degree-of-freedom (DoF) robotic manipulator learning behavior shaping policies for efficient tabletop operation.
Fast Joint Space Model-Predictive Control for Reactive Manipulation
Apr 28, 2021
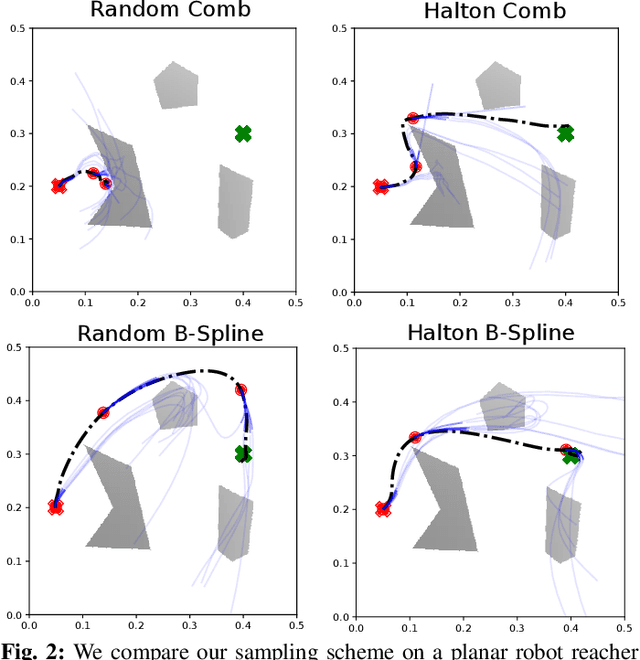
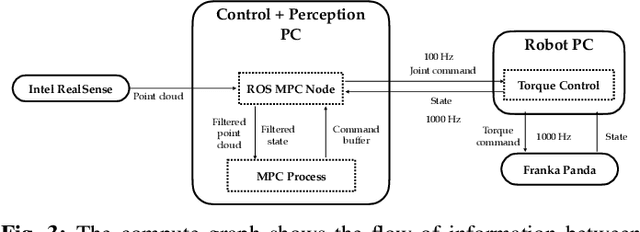
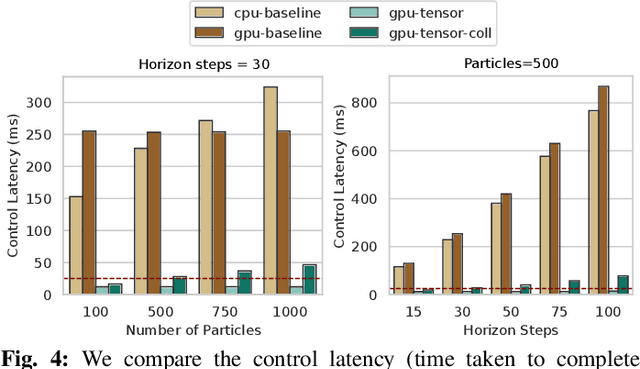
Sampling-based model predictive control (MPC) is a promising tool for feedback control of robots with complex and non-smooth dynamics and cost functions. The computationally demanding nature of sampling-based MPC algorithms is a key bottleneck in their application to high-dimensional robotic manipulation problems. Previous methods have addressed this issue by running MPC in the task space while relying on a low-level operational space controller for joint control. However, by not using the joint space of the robot in the MPC formulation, existing methods cannot directly account for non-task space related constraints such as avoiding joint limits, singular configurations, and link collisions. In this paper, we develop a joint space sampling-based MPC for manipulators that can be efficiently parallelized using GPUs. Our approach can handle task and joint space constraints while taking less than 0.02 seconds (50Hz) to compute the next control command. Further, our method can integrate perception into the control problem by utilizing learned cost functions from raw sensor data. We validate our approach by deploying it on a Franka Panda robot for a variety of common manipulation tasks. We study the effect of different cost formulations and MPC parameters on the synthesized behavior and provide key insights that pave the way for the application of sampling-based MPC for manipulators in a principled manner. Videos of experiments can be found at: https://sites.google.com/view/manipulation-mppi.
Fast and Efficient Locomotion via Learned Gait Transitions
Apr 09, 2021
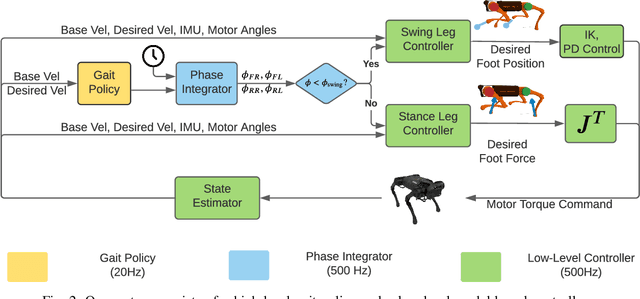

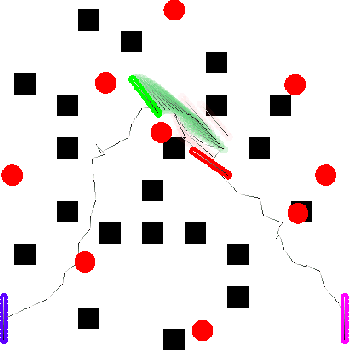
We focus on the problem of developing efficient controllers for quadrupedal robots. Animals can actively switch gaits at different speeds to lower their energy consumption. In this paper, we devise a hierarchical learning framework, in which distinctive locomotion gaits and natural gait transitions emerge automatically with a simple reward of energy minimization. We use reinforcement learning to train a high-level gait policy that specifies the contact schedules of each foot, while the low-level Model Predictive Controller (MPC) optimizes the motor torques so that the robot can walk at a desired velocity using that gait pattern. We test our learning framework on a quadruped robot and demonstrate automatic gait transitions, from walking to trotting and to fly-trotting, as the robot increases its speed up to 2.5m/s (5 body lengths/s). We show that the learned hierarchical controller consumes much less energy across a wide range of locomotion speed than baseline controllers.
The Value of Planning for Infinite-Horizon Model Predictive Control
Apr 07, 2021


Model Predictive Control (MPC) is a classic tool for optimal control of complex, real-world systems. Although it has been successfully applied to a wide range of challenging tasks in robotics, it is fundamentally limited by the prediction horizon, which, if too short, will result in myopic decisions. Recently, several papers have suggested using a learned value function as the terminal cost for MPC. If the value function is accurate, it effectively allows MPC to reason over an infinite horizon. Unfortunately, Reinforcement Learning (RL) solutions to value function approximation can be difficult to realize for robotics tasks. In this paper, we suggest a more efficient method for value function approximation that applies to goal-directed problems, like reaching and navigation. In these problems, MPC is often formulated to track a path or trajectory returned by a planner. However, this strategy is brittle in that unexpected perturbations to the robot will require replanning, which can be costly at runtime. Instead, we show how the intermediate data structures used by modern planners can be interpreted as an approximate value function. We show that that this value function can be used by MPC directly, resulting in more efficient and resilient behavior at runtime.
Few-shot Weakly-Supervised Object Detection via Directional Statistics
Mar 25, 2021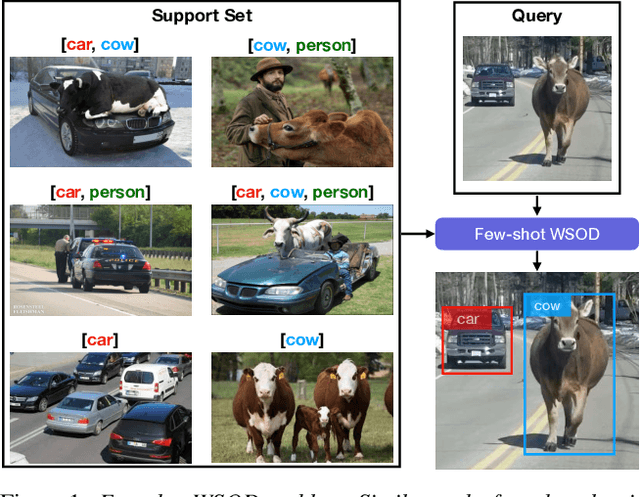
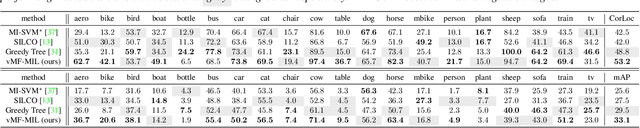
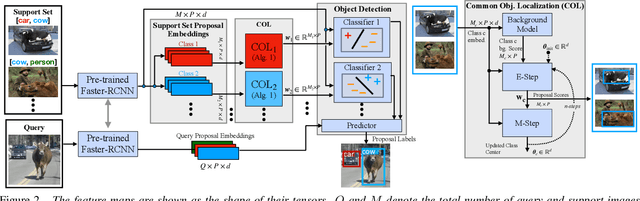

Detecting novel objects from few examples has become an emerging topic in computer vision recently. However, these methods need fully annotated training images to learn new object categories which limits their applicability in real world scenarios such as field robotics. In this work, we propose a probabilistic multiple instance learning approach for few-shot Common Object Localization (COL) and few-shot Weakly Supervised Object Detection (WSOD). In these tasks, only image-level labels, which are much cheaper to acquire, are available. We find that operating on features extracted from the last layer of a pre-trained Faster-RCNN is more effective compared to previous episodic learning based few-shot COL methods. Our model simultaneously learns the distribution of the novel objects and localizes them via expectation-maximization steps. As a probabilistic model, we employ von Mises-Fisher (vMF) distribution which captures the semantic information better than Gaussian distribution when applied to the pre-trained embedding space. When the novel objects are localized, we utilize them to learn a linear appearance model to detect novel classes in new images. Our extensive experiments show that the proposed method, despite being simple, outperforms strong baselines in few-shot COL and WSOD, as well as large-scale WSOD tasks.
Dual Online Stein Variational Inference for Control and Dynamics
Mar 23, 2021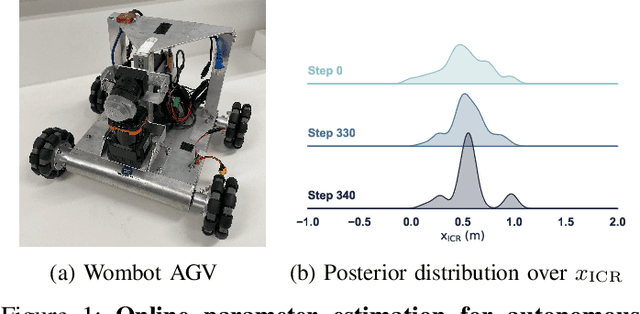
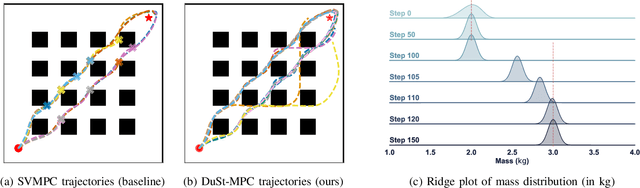
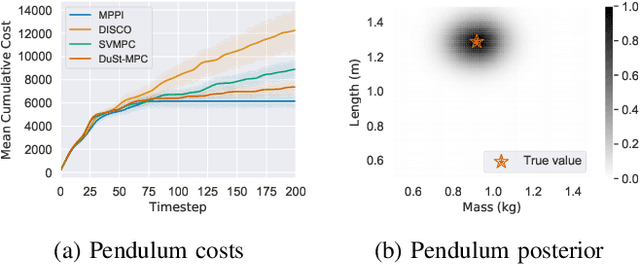
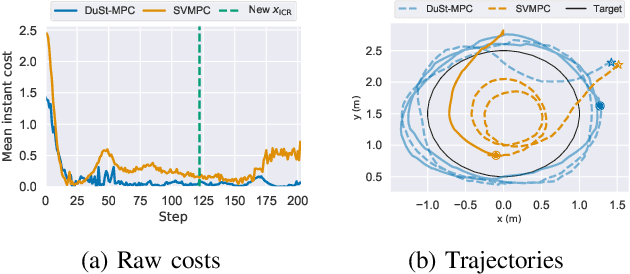
Model predictive control (MPC) schemes have a proven track record for delivering aggressive and robust performance in many challenging control tasks, coping with nonlinear system dynamics, constraints, and observational noise. Despite their success, these methods often rely on simple control distributions, which can limit their performance in highly uncertain and complex environments. MPC frameworks must be able to accommodate changing distributions over system parameters, based on the most recent measurements. In this paper, we devise an implicit variational inference algorithm able to estimate distributions over model parameters and control inputs on-the-fly. The method incorporates Stein Variational gradient descent to approximate the target distributions as a collection of particles, and performs updates based on a Bayesian formulation. This enables the approximation of complex multi-modal posterior distributions, typically occurring in challenging and realistic robot navigation tasks. We demonstrate our approach on both simulated and real-world experiments requiring real-time execution in the face of dynamically changing environments.
RMP2: A Structured Composable Policy Class for Robot Learning
Mar 10, 2021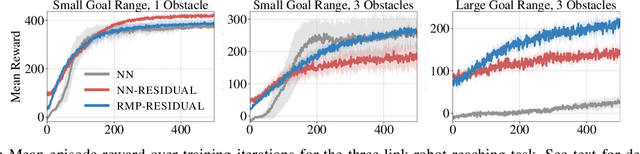
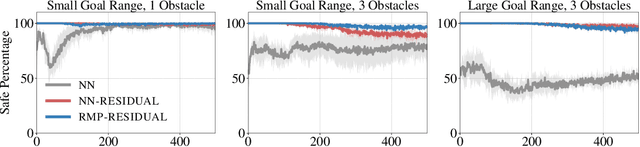
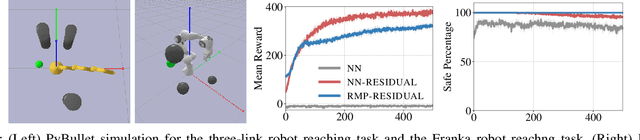
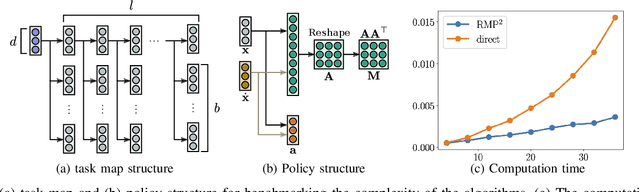
We consider the problem of learning motion policies for acceleration-based robotics systems with a structured policy class specified by RMPflow. RMPflow is a multi-task control framework that has been successfully applied in many robotics problems. Using RMPflow as a structured policy class in learning has several benefits, such as sufficient expressiveness, the flexibility to inject different levels of prior knowledge as well as the ability to transfer policies between robots. However, implementing a system for end-to-end learning RMPflow policies faces several computational challenges. In this work, we re-examine the message passing algorithm of RMPflow and propose a more efficient alternate algorithm, called RMP2, that uses modern automatic differentiation tools (such as TensorFlow and PyTorch) to compute RMPflow policies. Our new design retains the strengths of RMPflow while bringing in advantages from automatic differentiation, including 1) easy programming interfaces to designing complex transformations; 2) support of general directed acyclic graph (DAG) transformation structures; 3) end-to-end differentiability for policy learning; 4) improved computational efficiency. Because of these features, RMP2 can be treated as a structured policy class for efficient robot learning which is suitable encoding domain knowledge. Our experiments show that using structured policy class given by RMP2 can improve policy performance and safety in reinforcement learning tasks for goal reaching in cluttered space.
Combining pretrained CNN feature extractors to enhance clustering of complex natural images
Jan 07, 2021
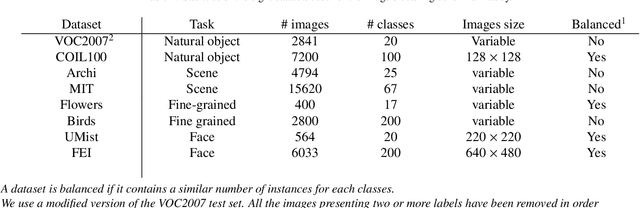
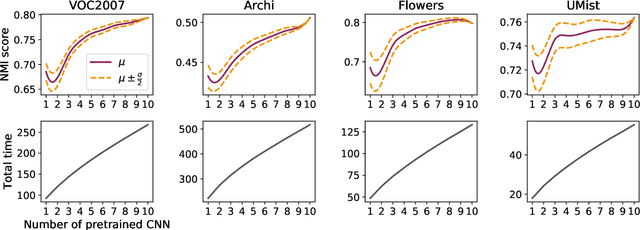
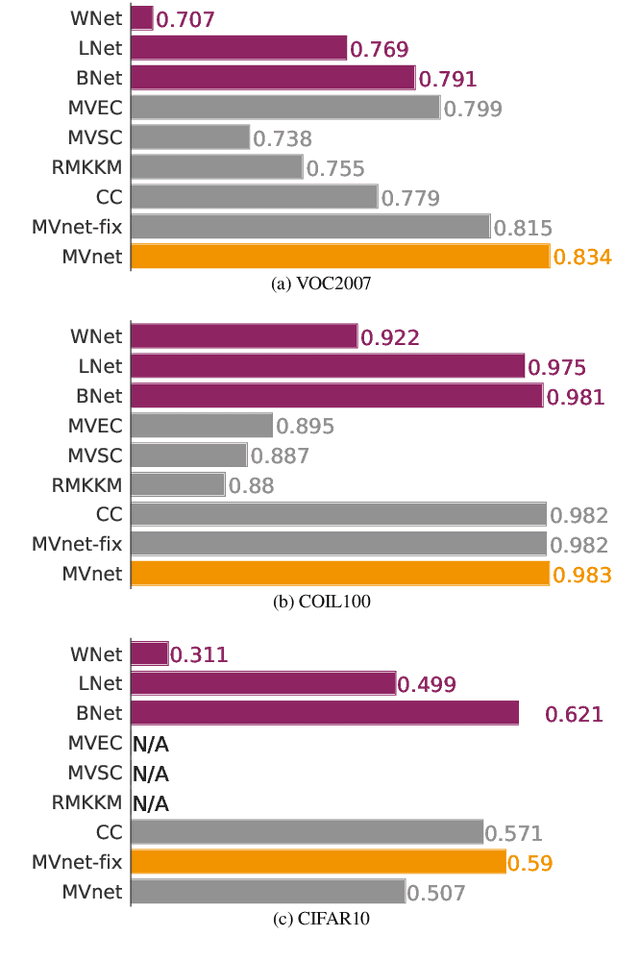
Recently, a common starting point for solving complex unsupervised image classification tasks is to use generic features, extracted with deep Convolutional Neural Networks (CNN) pretrained on a large and versatile dataset (ImageNet). However, in most research, the CNN architecture for feature extraction is chosen arbitrarily, without justification. This paper aims at providing insight on the use of pretrained CNN features for image clustering (IC). First, extensive experiments are conducted and show that, for a given dataset, the choice of the CNN architecture for feature extraction has a huge impact on the final clustering. These experiments also demonstrate that proper extractor selection for a given IC task is difficult. To solve this issue, we propose to rephrase the IC problem as a multi-view clustering (MVC) problem that considers features extracted from different architectures as different "views" of the same data. This approach is based on the assumption that information contained in the different CNN may be complementary, even when pretrained on the same data. We then propose a multi-input neural network architecture that is trained end-to-end to solve the MVC problem effectively. This approach is tested on nine natural image datasets, and produces state-of-the-art results for IC.
* 21 pages, 16 figures, 10 tables, preprint of our paper published in Neurocomputing
Towards Coordinated Robot Motions: End-to-End Learning of Motion Policies on Transform Trees
Dec 24, 2020
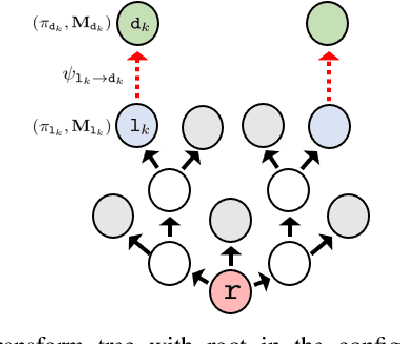
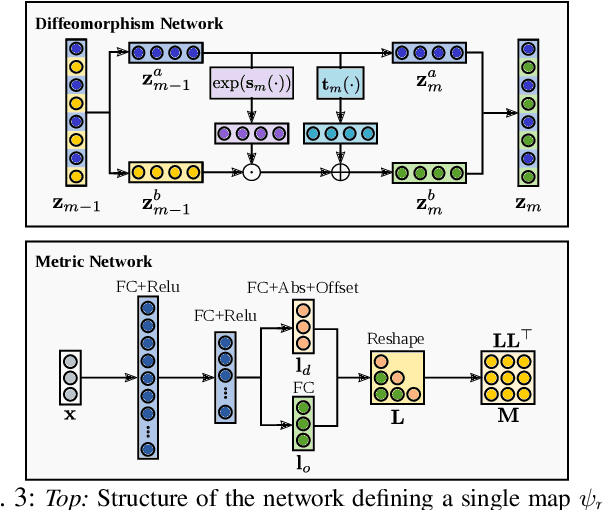
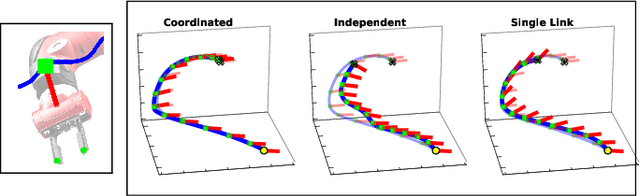
Robotic tasks often require generation of motions that satisfy multiple motion constraints, that may live on different parts of a robot's body. In this paper, we address the challenge of learning motion policies to generate motions for execution of such tasks. Additionally, to encode multiple motion constraints and their synergies, we enforce structure in our motion policy. Specifically, the structure results from decomposing a motion policy into multiple subtask policies, whereby each subtask policy dictates a particular subtask behavior. By learning the subtask policies together in an end-to-end fashion, our formulation not only learns coordination between subtask behaviors, but also learns how to trade them off against default behaviors that may exist. Furthermore, due to our choice of parameterization for the constituting subtask policies, our overall structured motion policy is guaranteed to generate stable motions. To corroborate our theory, we also present qualitative and quantitative evaluations on multiple robotic tasks.
Blending MPC & Value Function Approximation for Efficient Reinforcement Learning
Dec 10, 2020
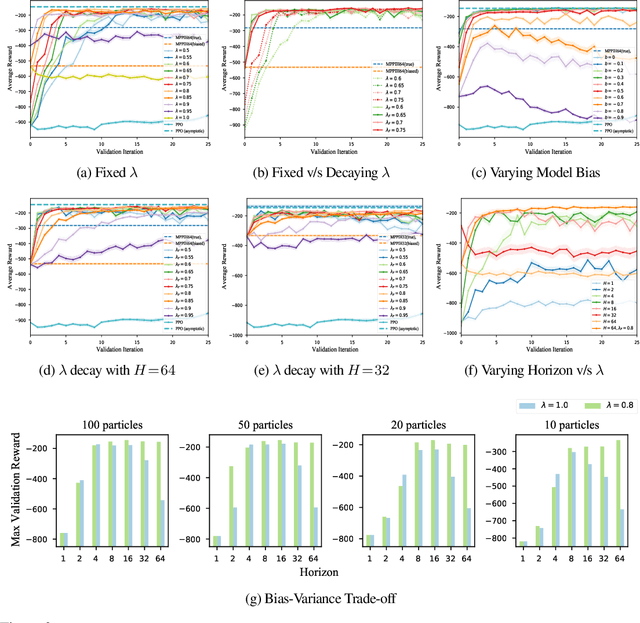
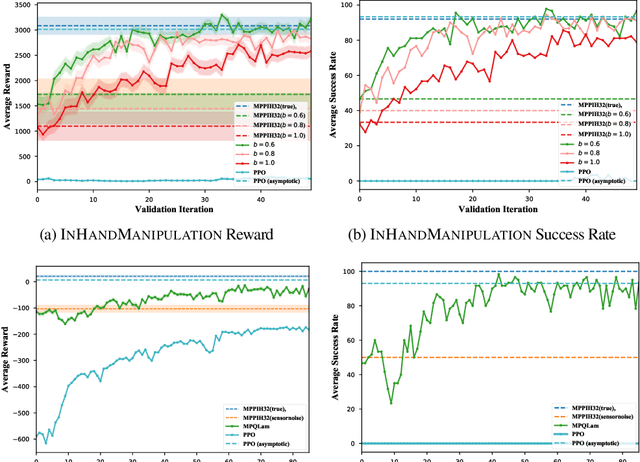
Model-Predictive Control (MPC) is a powerful tool for controlling complex, real-world systems that uses a model to make predictions about future behavior. For each state encountered, MPC solves an online optimization problem to choose a control action that will minimize future cost. This is a surprisingly effective strategy, but real-time performance requirements warrant the use of simple models. If the model is not sufficiently accurate, then the resulting controller can be biased, limiting performance. We present a framework for improving on MPC with model-free reinforcement learning (RL). The key insight is to view MPC as constructing a series of local Q-function approximations. We show that by using a parameter $\lambda$, similar to the trace decay parameter in TD($\lambda$), we can systematically trade-off learned value estimates against the local Q-function approximations. We present a theoretical analysis that shows how error from inaccurate models in MPC and value function estimation in RL can be balanced. We further propose an algorithm that changes $\lambda$ over time to reduce the dependence on MPC as our estimates of the value function improve, and test the efficacy our approach on challenging high-dimensional manipulation tasks with biased models in simulation. We demonstrate that our approach can obtain performance comparable with MPC with access to true dynamics even under severe model bias and is more sample efficient as compared to model-free RL.