 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenTAD: A Unified Framework and Comprehensive Study of Temporal Action Detection
Feb 27, 2025Temporal action detection (TAD) is a fundamental video understanding task that aims to identify human actions and localize their temporal boundaries in videos. Although this field has achieved remarkable progress in recent years, further progress and real-world applications are impeded by the absence of a standardized framework. Currently, different methods are compared under different implementation settings, evaluation protocols, etc., making it difficult to assess the real effectiveness of a specific technique. To address this issue, we propose \textbf{OpenTAD}, a unified TAD framework consolidating 16 different TAD methods and 9 standard datasets into a modular codebase. In OpenTAD, minimal effort is required to replace one module with a different design, train a feature-based TAD model in end-to-end mode, or switch between the two. OpenTAD also facilitates straightforward benchmarking across various datasets and enables fair and in-depth comparisons among different methods. With OpenTAD, we comprehensively study how innovations in different network components affect detection performance and identify the most effective design choices through extensive experiments. This study has led to a new state-of-the-art TAD method built upon existing techniques for each component. We have made our code and models available at https://github.com/sming256/OpenTAD.
MatchDiffusion: Training-free Generation of Match-cuts
Nov 27, 2024



Match-cuts are powerful cinematic tools that create seamless transitions between scenes, delivering strong visual and metaphorical connections. However, crafting match-cuts is a challenging, resource-intensive process requiring deliberate artistic planning. In MatchDiffusion, we present the first training-free method for match-cut generation using text-to-video diffusion models. MatchDiffusion leverages a key property of diffusion models: early denoising steps define the scene's broad structure, while later steps add details. Guided by this insight, MatchDiffusion employs "Joint Diffusion" to initialize generation for two prompts from shared noise, aligning structure and motion. It then applies "Disjoint Diffusion", allowing the videos to diverge and introduce unique details. This approach produces visually coherent videos suited for match-cuts. User studies and metrics demonstrate MatchDiffusion's effectiveness and potential to democratize match-cut creation.
Generative Timelines for Instructed Visual Assembly
Nov 19, 2024The objective of this work is to manipulate visual timelines (e.g. a video) through natural language instructions, making complex timeline editing tasks accessible to non-expert or potentially even disabled users. We call this task Instructed visual assembly. This task is challenging as it requires (i) identifying relevant visual content in the input timeline as well as retrieving relevant visual content in a given input (video) collection, (ii) understanding the input natural language instruction, and (iii) performing the desired edits of the input visual timeline to produce an output timeline. To address these challenges, we propose the Timeline Assembler, a generative model trained to perform instructed visual assembly tasks. The contributions of this work are three-fold. First, we develop a large multimodal language model, which is designed to process visual content, compactly represent timelines and accurately interpret timeline editing instructions. Second, we introduce a novel method for automatically generating datasets for visual assembly tasks, enabling efficient training of our model without the need for human-labeled data. Third, we validate our approach by creating two novel datasets for image and video assembly, demonstrating that the Timeline Assembler substantially outperforms established baseline models, including the recent GPT-4o, in accurately executing complex assembly instructions across various real-world inspired scenarios.
Compressed-Language Models for Understanding Compressed File Formats: a JPEG Exploration
May 27, 2024This study investigates whether Compressed-Language Models (CLMs), i.e. language models operating on raw byte streams from Compressed File Formats~(CFFs), can understand files compressed by CFFs. We focus on the JPEG format as a representative CFF, given its commonality and its representativeness of key concepts in compression, such as entropy coding and run-length encoding. We test if CLMs understand the JPEG format by probing their capabilities to perform along three axes: recognition of inherent file properties, handling of files with anomalies, and generation of new files. Our findings demonstrate that CLMs can effectively perform these tasks. These results suggest that CLMs can understand the semantics of compressed data when directly operating on the byte streams of files produced by CFFs. The possibility to directly operate on raw compressed files offers the promise to leverage some of their remarkable characteristics, such as their ubiquity, compactness, multi-modality and segment-nature.
Combating Missing Modalities in Egocentric Videos at Test Time
Apr 23, 2024



Understanding videos that contain multiple modalities is crucial, especially in egocentric videos, where combining various sensory inputs significantly improves tasks like action recognition and moment localization. However, real-world applications often face challenges with incomplete modalities due to privacy concerns, efficiency needs, or hardware issues. Current methods, while effective, often necessitate retraining the model entirely to handle missing modalities, making them computationally intensive, particularly with large training datasets. In this study, we propose a novel approach to address this issue at test time without requiring retraining. We frame the problem as a test-time adaptation task, where the model adjusts to the available unlabeled data at test time. Our method, MiDl~(Mutual information with self-Distillation), encourages the model to be insensitive to the specific modality source present during testing by minimizing the mutual information between the prediction and the available modality. Additionally, we incorporate self-distillation to maintain the model's original performance when both modalities are available. MiDl represents the first self-supervised, online solution for handling missing modalities exclusively at test time. Through experiments with various pretrained models and datasets, MiDl demonstrates substantial performance improvement without the need for retraining.
Towards Automated Movie Trailer Generation
Apr 04, 2024



Movie trailers are an essential tool for promoting films and attracting audiences. However, the process of creating trailers can be time-consuming and expensive. To streamline this process, we propose an automatic trailer generation framework that generates plausible trailers from a full movie by automating shot selection and composition. Our approach draws inspiration from machine translation techniques and models the movies and trailers as sequences of shots, thus formulating the trailer generation problem as a sequence-to-sequence task. We introduce Trailer Generation Transformer (TGT), a deep-learning framework utilizing an encoder-decoder architecture. TGT movie encoder is tasked with contextualizing each movie shot representation via self-attention, while the autoregressive trailer decoder predicts the feature representation of the next trailer shot, accounting for the relevance of shots' temporal order in trailers. Our TGT significantly outperforms previous methods on a comprehensive suite of metrics.
Exploring Missing Modality in Multimodal Egocentric Datasets
Jan 21, 2024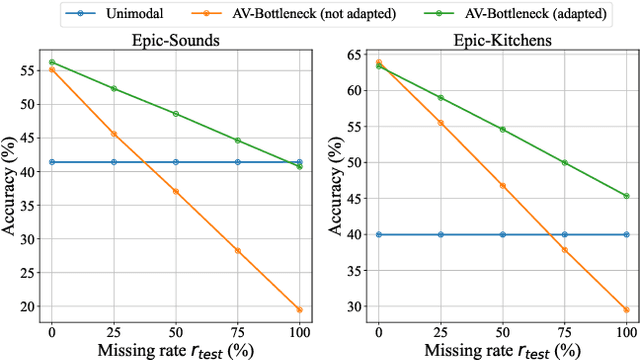
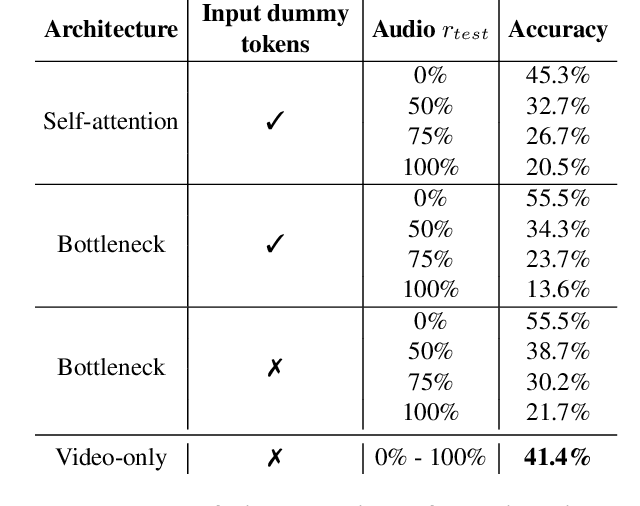
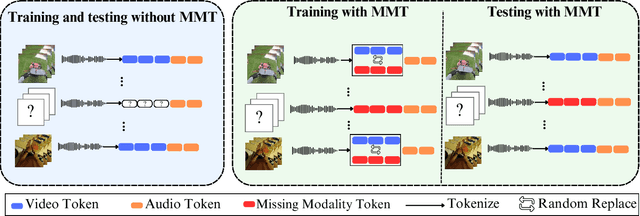
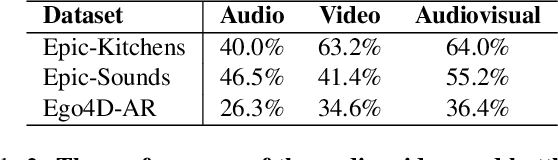
Multimodal video understanding is crucial for analyzing egocentric videos, where integrating multiple sensory signals significantly enhances action recognition and moment localization. However, practical applications often grapple with incomplete modalities due to factors like privacy concerns, efficiency demands, or hardware malfunctions. Addressing this, our study delves into the impact of missing modalities on egocentric action recognition, particularly within transformer-based models. We introduce a novel concept -Missing Modality Token (MMT)-to maintain performance even when modalities are absent, a strategy that proves effective in the Ego4D, Epic-Kitchens, and Epic-Sounds datasets. Our method mitigates the performance loss, reducing it from its original $\sim 30\%$ drop to only $\sim 10\%$ when half of the test set is modal-incomplete. Through extensive experimentation, we demonstrate the adaptability of MMT to different training scenarios and its superiority in handling missing modalities compared to current methods. Our research contributes a comprehensive analysis and an innovative approach, opening avenues for more resilient multimodal systems in real-world settings.
Revisiting Test Time Adaptation under Online Evaluation
Apr 10, 2023



This paper proposes a novel online evaluation protocol for Test Time Adaptation (TTA) methods, which penalizes slower methods by providing them with fewer samples for adaptation. TTA methods leverage unlabeled data at test time to adapt to distribution shifts. Though many effective methods have been proposed, their impressive performance usually comes at the cost of significantly increased computation budgets. Current evaluation protocols overlook the effect of this extra computation cost, affecting their real-world applicability. To address this issue, we propose a more realistic evaluation protocol for TTA methods, where data is received in an online fashion from a constant-speed data stream, thereby accounting for the method's adaptation speed. We apply our proposed protocol to benchmark several TTA methods on multiple datasets and scenarios. Extensive experiments shows that, when accounting for inference speed, simple and fast approaches can outperform more sophisticated but slower methods. For example, SHOT from 2020 outperforms the state-of-the-art method SAR from 2023 under our online setting. Our online evaluation protocol emphasizes the need for developing TTA methods that are efficient and applicable in realistic settings.
MAD: A Scalable Dataset for Language Grounding in Videos from Movie Audio Descriptions
Dec 01, 2021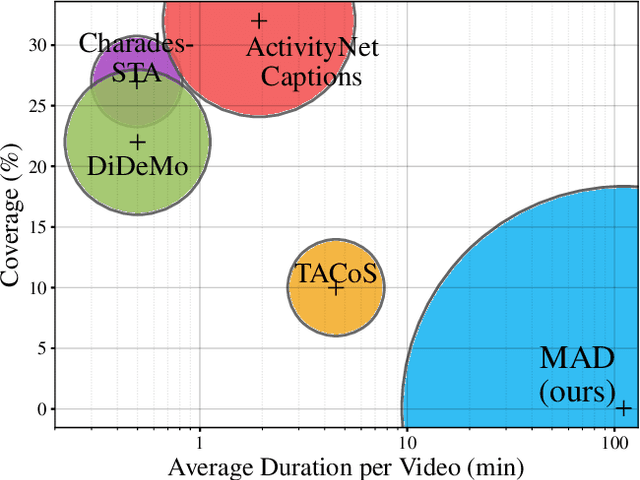
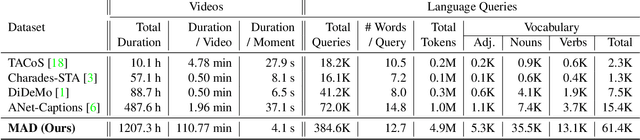


The recent and increasing interest in video-language research has driven the development of large-scale datasets that enable data-intensive machine learning techniques. In comparison, limited effort has been made at assessing the fitness of these datasets for the video-language grounding task. Recent works have begun to discover significant limitations in these datasets, suggesting that state-of-the-art techniques commonly overfit to hidden dataset biases. In this work, we present MAD (Movie Audio Descriptions), a novel benchmark that departs from the paradigm of augmenting existing video datasets with text annotations and focuses on crawling and aligning available audio descriptions of mainstream movies. MAD contains over 384,000 natural language sentences grounded in over 1,200 hours of video and exhibits a significant reduction in the currently diagnosed biases for video-language grounding datasets. MAD's collection strategy enables a novel and more challenging version of video-language grounding, where short temporal moments (typically seconds long) must be accurately grounded in diverse long-form videos that can last up to three hours.
MovieCuts: A New Dataset and Benchmark for Cut Type Recognition
Sep 19, 2021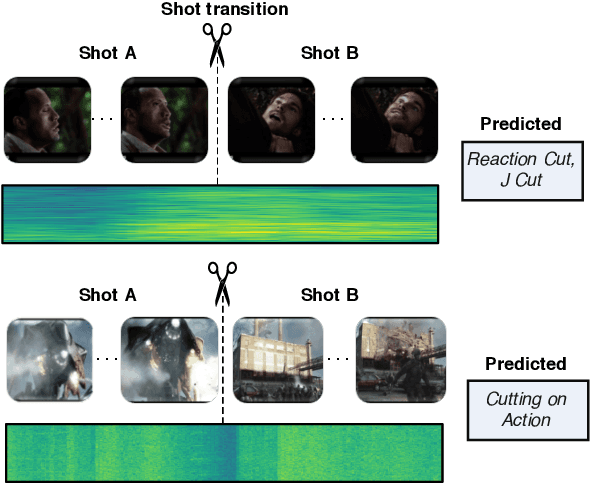
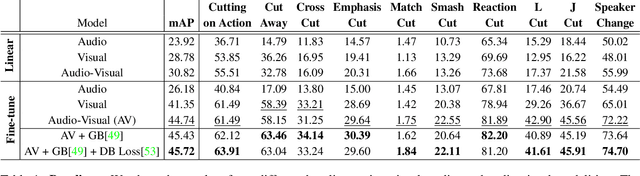
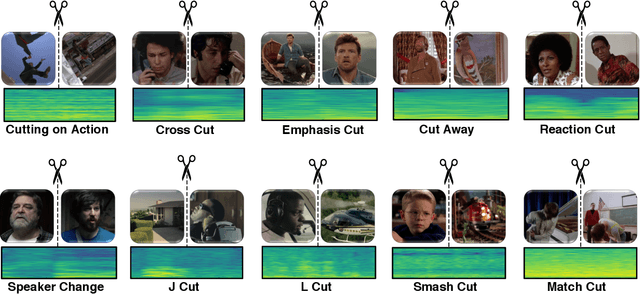
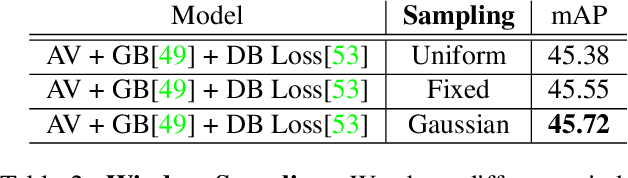
Understanding movies and their structural patterns is a crucial task to decode the craft of video editing. While previous works have developed tools for general analysis such as detecting characters or recognizing cinematography properties at the shot level, less effort has been devoted to understanding the most basic video edit, the Cut. This paper introduces the cut type recognition task, which requires modeling of multi-modal information. To ignite research in the new task, we construct a large-scale dataset called MovieCuts, which contains more than 170K videoclips labeled among ten cut types. We benchmark a series of audio-visual approaches, including some that deal with the problem's multi-modal and multi-label nature. Our best model achieves 45.7% mAP, which suggests that the task is challenging and that attaining highly accurate cut type recognition is an open research problem.