 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecord-Remix-Replay: Hierarchical GPU Kernel Optimization using Evolutionary Search
Apr 13, 2026As high-performance computing and AI workloads become increasingly dependent on GPUs, maintaining high performance across rapidly evolving hardware generations has become a major challenge. Developers often spend months tuning scientific applications to fully exploit new architectures, navigating a complex optimization space that spans algorithm design, source implementation, compiler flags and pass sequences, and kernel launch parameters. Existing approaches can effectively search parts of this space in isolation, such as launch configurations or compiler settings, but optimizing across the full space still requires substantial human expertise and iterative manual effort. In this paper, we present Record-Remix-Replay (R^3), a hierarchical optimization framework that combines LLM-driven evolutionary search, Bayesian optimization, and record-replay compilation techniques to efficiently explore GPU kernel optimizations from source-level implementation choices down to compiler pass ordering and runtime configuration. By making candidate evaluation fast and scalable, our approach enables practical end-to-end search over optimization dimensions that are typically treated separately. We show that Record-Remix-Replay can optimize full scientific applications better than traditional approaches over kernel parameters and compiler flags, while also being nearly an order of magnitude faster than modern evolutionary search approaches.
Modeling Code: Is Text All You Need?
Jul 15, 2025Code LLMs have become extremely popular recently for modeling source code across a variety of tasks, such as generation, translation, and summarization. However, transformer-based models are limited in their capabilities to reason through structured, analytical properties of code, such as control and data flow. Previous work has explored the modeling of these properties with structured data and graph neural networks. However, these approaches lack the generative capabilities and scale of modern LLMs. In this work, we introduce a novel approach to combine the strengths of modeling both code as text and more structured forms.
Leveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
Can Large Language Models Predict Parallel Code Performance?
May 06, 2025Accurate determination of the performance of parallel GPU code typically requires execution-time profiling on target hardware -- an increasingly prohibitive step due to limited access to high-end GPUs. This paper explores whether Large Language Models (LLMs) can offer an alternative approach for GPU performance prediction without relying on hardware. We frame the problem as a roofline classification task: given the source code of a GPU kernel and the hardware specifications of a target GPU, can an LLM predict whether the GPU kernel is compute-bound or bandwidth-bound? For this study, we build a balanced dataset of 340 GPU kernels, obtained from HeCBench benchmark and written in CUDA and OpenMP, along with their ground-truth labels obtained via empirical GPU profiling. We evaluate LLMs across four scenarios: (1) with access to profiling data of the kernel source, (2) zero-shot with source code only, (3) few-shot with code and label pairs, and (4) fine-tuned on a small custom dataset. Our results show that state-of-the-art LLMs have a strong understanding of the Roofline model, achieving 100% classification accuracy when provided with explicit profiling data. We also find that reasoning-capable LLMs significantly outperform standard LLMs in zero- and few-shot settings, achieving up to 64% accuracy on GPU source codes, without profiling information. Lastly, we find that LLM fine-tuning will require much more data than what we currently have available. This work is among the first to use LLMs for source-level roofline performance prediction via classification, and illustrates their potential to guide optimization efforts when runtime profiling is infeasible. Our findings suggest that with better datasets and prompt strategies, LLMs could become practical tools for HPC performance analysis and performance portability.
Machine Learning-Driven Adaptive OpenMP For Portable Performance on Heterogeneous Systems
Mar 15, 2023



Heterogeneity has become a mainstream architecture design choice for building High Performance Computing systems. However, heterogeneity poses significant challenges for achieving performance portability of execution. Adapting a program to a new heterogeneous platform is laborious and requires developers to manually explore a vast space of execution parameters. To address those challenges, this paper proposes new extensions to OpenMP for autonomous, machine learning-driven adaptation. Our solution includes a set of novel language constructs, compiler transformations, and runtime support. We propose a producer-consumer pattern to flexibly define multiple, different variants of OpenMP code regions to enable adaptation. Those regions are transparently profiled at runtime to autonomously learn optimizing machine learning models that dynamically select the fastest variant. Our approach significantly reduces users' efforts of programming adaptive applications on heterogeneous architectures by leveraging machine learning techniques and code generation capabilities of OpenMP compilation. Using a complete reference implementation in Clang/LLVM we evaluate three use-cases of adaptive CPU-GPU execution. Experiments with HPC proxy applications and benchmarks demonstrate that the proposed adaptive OpenMP extensions automatically choose the best performing code variants for various adaptation possibilities, in several different heterogeneous platforms of CPUs and GPUs.
A Case Study of LLVM-Based Analysis for Optimizing SIMD Code Generation
Jun 27, 2021
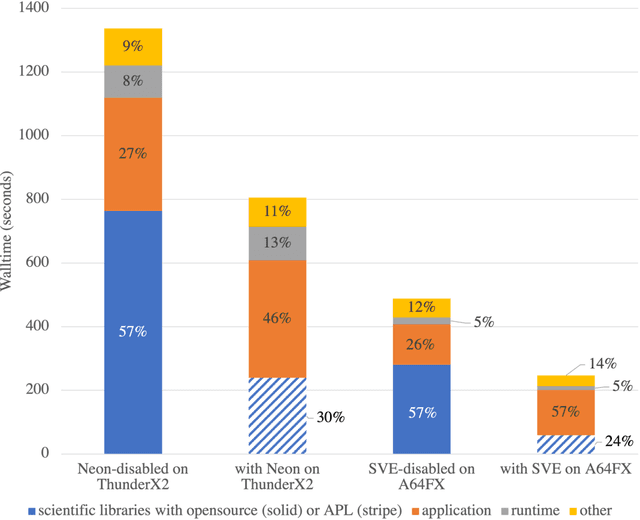
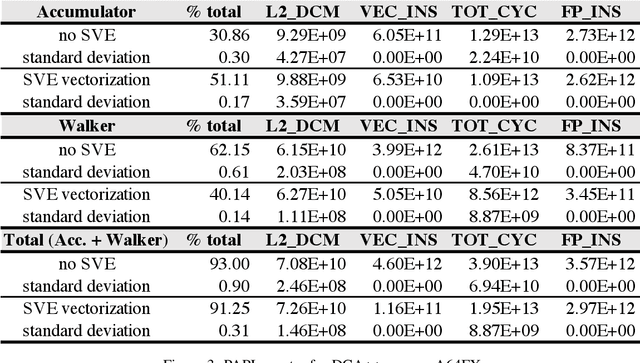

This paper presents a methodology for using LLVM-based tools to tune the DCA++ (dynamical clusterapproximation) application that targets the new ARM A64FX processor. The goal is to describethe changes required for the new architecture and generate efficient single instruction/multiple data(SIMD) instructions that target the new Scalable Vector Extension instruction set. During manualtuning, the authors used the LLVM tools to improve code parallelization by using OpenMP SIMD,refactored the code and applied transformation that enabled SIMD optimizations, and ensured thatthe correct libraries were used to achieve optimal performance. By applying these code changes, codespeed was increased by 1.98X and 78 GFlops were achieved on the A64FX processor. The authorsaim to automatize parts of the efforts in the OpenMP Advisor tool, which is built on top of existingand newly introduced LLVM tooling.