 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAT: Neural Acoustic Transfer for Interactive Scenes in Real Time
Jun 06, 2025



Previous acoustic transfer methods rely on extensive precomputation and storage of data to enable real-time interaction and auditory feedback. However, these methods struggle with complex scenes, especially when dynamic changes in object position, material, and size significantly alter sound effects. These continuous variations lead to fluctuating acoustic transfer distributions, making it challenging to represent with basic data structures and render efficiently in real time. To address this challenge, we present Neural Acoustic Transfer, a novel approach that utilizes an implicit neural representation to encode precomputed acoustic transfer and its variations, allowing for real-time prediction of sound fields under varying conditions. To efficiently generate the training data required for the neural acoustic field, we developed a fast Monte-Carlo-based boundary element method (BEM) approximation for general scenarios with smooth Neumann conditions. Additionally, we implemented a GPU-accelerated version of standard BEM for scenarios requiring higher precision. These methods provide the necessary training data, enabling our neural network to accurately model the sound radiation space. We demonstrate our method's numerical accuracy and runtime efficiency (within several milliseconds for 30s audio) through comprehensive validation and comparisons in diverse acoustic transfer scenarios. Our approach allows for efficient and accurate modeling of sound behavior in dynamically changing environments, which can benefit a wide range of interactive applications such as virtual reality, augmented reality, and advanced audio production.
Breaking the Cloak! Unveiling Chinese Cloaked Toxicity with Homophone Graph and Toxic Lexicon
May 28, 2025Social media platforms have experienced a significant rise in toxic content, including abusive language and discriminatory remarks, presenting growing challenges for content moderation. Some users evade censorship by deliberately disguising toxic words through homophonic cloak, which necessitates the task of unveiling cloaked toxicity. Existing methods are mostly designed for English texts, while Chinese cloaked toxicity unveiling has not been solved yet. To tackle the issue, we propose C$^2$TU, a novel training-free and prompt-free method for Chinese cloaked toxic content unveiling. It first employs substring matching to identify candidate toxic words based on Chinese homo-graph and toxic lexicon. Then it filters those candidates that are non-toxic and corrects cloaks to be their corresponding toxicities. Specifically, we develop two model variants for filtering, which are based on BERT and LLMs, respectively. For LLMs, we address the auto-regressive limitation in computing word occurrence probability and utilize the full semantic contexts of a text sequence to reveal cloaked toxic words. Extensive experiments demonstrate that C$^2$TU can achieve superior performance on two Chinese toxic datasets. In particular, our method outperforms the best competitor by up to 71% on the F1 score and 35% on accuracy, respectively.
Temporal Consistency Constrained Transferable Adversarial Attacks with Background Mixup for Action Recognition
May 23, 2025Action recognition models using deep learning are vulnerable to adversarial examples, which are transferable across other models trained on the same data modality. Existing transferable attack methods face two major challenges: 1) they heavily rely on the assumption that the decision boundaries of the surrogate (a.k.a., source) model and the target model are similar, which limits the adversarial transferability; and 2) their decision boundary difference makes the attack direction uncertain, which may result in the gradient oscillation, weakening the adversarial attack. This motivates us to propose a Background Mixup-induced Temporal Consistency (BMTC) attack method for action recognition. From the input transformation perspective, we design a model-agnostic background adversarial mixup module to reduce the surrogate-target model dependency. In particular, we randomly sample one video from each category and make its background frame, while selecting the background frame with the top attack ability for mixup with the clean frame by reinforcement learning. Moreover, to ensure an explicit attack direction, we leverage the background category as guidance for updating the gradient of adversarial example, and design a temporal gradient consistency loss, which strengthens the stability of the attack direction on subsequent frames. Empirical studies on two video datasets, i.e., UCF101 and Kinetics-400, and one image dataset, i.e., ImageNet, demonstrate that our method significantly boosts the transferability of adversarial examples across several action/image recognition models. Our code is available at https://github.com/mlvccn/BMTC_TransferAttackVid.
xGen-small Technical Report
May 10, 2025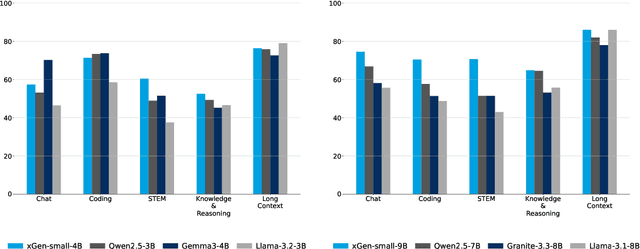
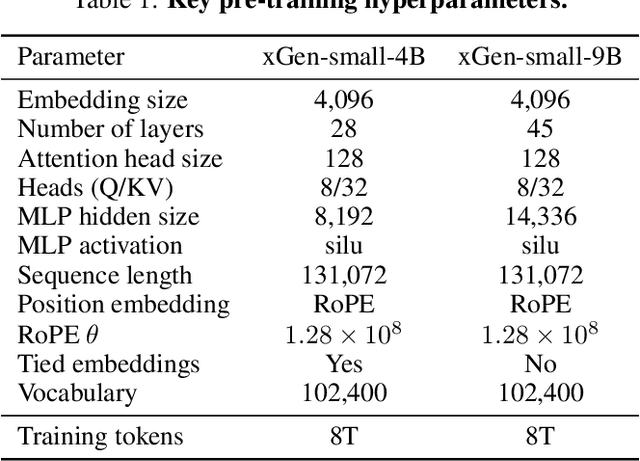
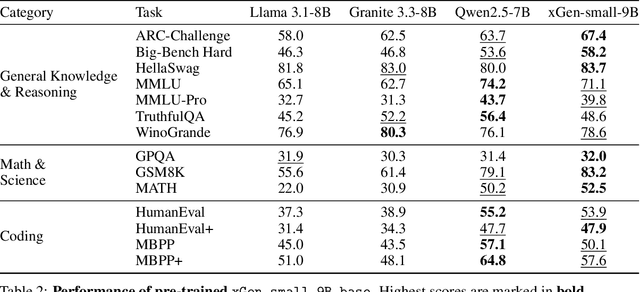
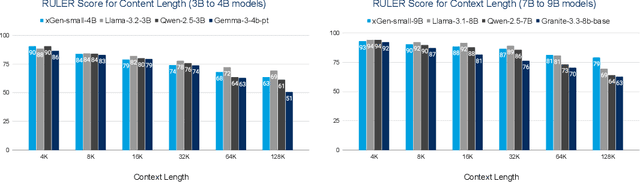
We introduce xGen-small, a family of 4B and 9B Transformer decoder models optimized for long-context applications. Our vertically integrated pipeline unites domain-balanced, frequency-aware data curation; multi-stage pre-training with quality annealing and length extension to 128k tokens; and targeted post-training via supervised fine-tuning, preference learning, and online reinforcement learning. xGen-small delivers strong performance across various tasks, especially in math and coding domains, while excelling at long context benchmarks.
A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
Apr 15, 2025



Reinforcement learning (RL) has become a prevailing approach for fine-tuning large language models (LLMs) on complex reasoning tasks. Among recent methods, GRPO stands out for its empirical success in training models such as DeepSeek-R1, yet the sources of its effectiveness remain poorly understood. In this work, we revisit GRPO from a reinforce-like algorithm perspective and analyze its core components. Surprisingly, we find that a simple rejection sampling baseline, RAFT, which trains only on positively rewarded samples, yields competitive performance than GRPO and PPO. Our ablation studies reveal that GRPO's main advantage arises from discarding prompts with entirely incorrect responses, rather than from its reward normalization. Motivated by this insight, we propose Reinforce-Rej, a minimal extension of policy gradient that filters both entirely incorrect and entirely correct samples. Reinforce-Rej improves KL efficiency and stability, serving as a lightweight yet effective alternative to more complex RL algorithms. We advocate RAFT as a robust and interpretable baseline, and suggest that future advances should focus on more principled designs for incorporating negative samples, rather than relying on them indiscriminately. Our findings provide guidance for future work in reward-based LLM post-training.
CLOVER: A Test Case Generation Benchmark with Coverage, Long-Context, and Verification
Feb 12, 2025Software testing is a critical aspect of software development, yet generating test cases remains a routine task for engineers. This paper presents a benchmark, CLOVER, to evaluate models' capabilities in generating and completing test cases under specific conditions. Spanning from simple assertion completions to writing test cases that cover specific code blocks across multiple files, these tasks are based on 12 python repositories, analyzing 845 problems with context lengths ranging from 4k to 128k tokens. Utilizing code testing frameworks, we propose a method to construct retrieval contexts using coverage information. While models exhibit comparable performance with short contexts, notable differences emerge with 16k contexts. Notably, models like GPT-4o and Claude 3.5 can effectively leverage relevant snippets; however, all models score below 35\% on the complex Task III, even with the oracle context provided, underscoring the benchmark's significance and the potential for model improvement. The benchmark is containerized for code execution across tasks, and we will release the code, data, and construction methodologies.
BOLT: Bootstrap Long Chain-of-Thought in Language Models without Distillation
Feb 06, 2025



Large language models (LLMs), such as o1 from OpenAI, have demonstrated remarkable reasoning capabilities. o1 generates a long chain-of-thought (LongCoT) before answering a question. LongCoT allows LLMs to analyze problems, devise plans, reflect, and backtrack effectively. These actions empower LLM to solve complex problems. After the release of o1, many teams have attempted to replicate its LongCoT and reasoning capabilities. In terms of methods, they primarily rely on knowledge distillation with data from existing models with LongCoT capacities (e.g., OpenAI-o1, Qwen-QwQ, DeepSeek-R1-Preview), leaving significant uncertainties on systematically developing such reasoning abilities. In terms of data domains, these works focus narrowly on math while a few others include coding, limiting their generalizability. This paper introduces a novel approach to enable LLM's LongCoT capacity without distillation from o1-like models or expensive human annotations, where we bootstrap LongCoT (BOLT) from a standard instruct model. BOLT involves three stages: 1) LongCoT data bootstrapping with in-context learning on a standard instruct model; 2) LongCoT supervised finetuning; 3) online training to further refine LongCoT capacities. In BOLT, only a few in-context examples need to be constructed during the bootstrapping stage; in our experiments, we created 10 examples, demonstrating the feasibility of this approach. We use Llama-3.1-70B-Instruct to bootstrap LongCoT and apply our method to various model scales (7B, 8B, 70B). We achieve impressive performance on a variety of benchmarks, Arena-Hard, MT-Bench, WildBench, ZebraLogic, MATH500, which evaluate diverse task-solving and reasoning capabilities.
Scalable Language Models with Posterior Inference of Latent Thought Vectors
Feb 03, 2025



We propose a novel family of language models, Latent-Thought Language Models (LTMs), which incorporate explicit latent thought vectors that follow an explicit prior model in latent space. These latent thought vectors guide the autoregressive generation of ground tokens through a Transformer decoder. Training employs a dual-rate optimization process within the classical variational Bayes framework: fast learning of local variational parameters for the posterior distribution of latent vectors, and slow learning of global decoder parameters. Empirical studies reveal that LTMs possess additional scaling dimensions beyond traditional LLMs, yielding a structured design space. Higher sample efficiency can be achieved by increasing training compute per token, with further gains possible by trading model size for more inference steps. Designed based on these scaling properties, LTMs demonstrate superior sample and parameter efficiency compared to conventional autoregressive models and discrete diffusion models. They significantly outperform these counterparts in validation perplexity and zero-shot language modeling. Additionally, LTMs exhibit emergent few-shot in-context reasoning capabilities that scale with model and latent size, and achieve competitive performance in conditional and unconditional text generation.
GReaTer: Gradients over Reasoning Makes Smaller Language Models Strong Prompt Optimizers
Dec 12, 2024



The effectiveness of large language models (LLMs) is closely tied to the design of prompts, making prompt optimization essential for enhancing their performance across a wide range of tasks. Many existing approaches to automating prompt engineering rely exclusively on textual feedback, refining prompts based solely on inference errors identified by large, computationally expensive LLMs. Unfortunately, smaller models struggle to generate high-quality feedback, resulting in complete dependence on large LLM judgment. Moreover, these methods fail to leverage more direct and finer-grained information, such as gradients, due to operating purely in text space. To this end, we introduce GReaTer, a novel prompt optimization technique that directly incorporates gradient information over task-specific reasoning. By utilizing task loss gradients, GReaTer enables self-optimization of prompts for open-source, lightweight language models without the need for costly closed-source LLMs. This allows high-performance prompt optimization without dependence on massive LLMs, closing the gap between smaller models and the sophisticated reasoning often needed for prompt refinement. Extensive evaluations across diverse reasoning tasks including BBH, GSM8k, and FOLIO demonstrate that GReaTer consistently outperforms previous state-of-the-art prompt optimization methods, even those reliant on powerful LLMs. Additionally, GReaTer-optimized prompts frequently exhibit better transferability and, in some cases, boost task performance to levels comparable to or surpassing those achieved by larger language models, highlighting the effectiveness of prompt optimization guided by gradients over reasoning. Code of GReaTer is available at https://github.com/psunlpgroup/GreaTer.
Fire-Image-DenseNet (FIDN) for predicting wildfire burnt area using remote sensing data
Dec 02, 2024



Predicting the extent of massive wildfires once ignited is essential to reduce the subsequent socioeconomic losses and environmental damage, but challenging because of the complexity of fire behaviour. Existing physics-based models are limited in predicting large or long-duration wildfire events. Here, we develop a deep-learning-based predictive model, Fire-Image-DenseNet (FIDN), that uses spatial features derived from both near real-time and reanalysis data on the environmental and meteorological drivers of wildfire. We trained and tested this model using more than 300 individual wildfires that occurred between 2012 and 2019 in the western US. In contrast to existing models, the performance of FIDN does not degrade with fire size or duration. Furthermore, it predicts final burnt area accurately even in very heterogeneous landscapes in terms of fuel density and flammability. The FIDN model showed higher accuracy, with a mean squared error (MSE) about 82% and 67% lower than those of the predictive models based on cellular automata (CA) and the minimum travel time (MTT) approaches, respectively. Its structural similarity index measure (SSIM) averages 97%, outperforming the CA and FlamMap MTT models by 6% and 2%, respectively. Additionally, FIDN is approximately three orders of magnitude faster than both CA and MTT models. The enhanced computational efficiency and accuracy advancements offer vital insights for strategic planning and resource allocation for firefighting operations.