 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex--Concave Quadratic Spectral Filtering for Graph Neural Networks
Jun 23, 2026Spectral graph neural networks (GNNs) interpret message passing as frequency-selective filtering. While low-order spectral filters are efficient, their limited selectivity often leads to weak attenuation outside the passband, whereas high-order alternatives introduce optimization challenges. We propose DCQ-GNN, a spectral GNN based on a compact bank of adaptive convex--concave quadratic filters. By restricting the filter order to two while explicitly exploiting complementary curvature, DCQ-GNN improves spectral selectivity as quantified by Dirichlet energy and entropy measures without resorting to high-order polynomial expansions. The model fuses filter outputs through a node-adaptive gating mechanism to enable node-wise structure-aware spectral selection. We provide a formal spectral analysis grounded in Dirichlet energy attenuation, von Neumann entropy, and curvature polarity, and derive explicit characterizations of filter behavior across varying levels of homophily and structural perturbations. Extensive benchmarks on 10 datasets show that DCQ-GNN ties for the top average rank (3.0) on heterophilic graphs and obtains the second-best rank (4.2) on homophilic graphs, remaining competitive with representative high-order polynomial spectral filters. Furthermore, under strong structural perturbations, DCQ-GNN exhibits substantially smaller performance degradation compared to both first-order and high-order baselines. These results demonstrate that curvature-aware quadratic banks provide a robust and efficient alternative to high-order spectral models while preserving optimization stability and computational efficiency.
Diffusion Forcing Planner: History-Annealed Planning with Time-Dependent Guidance for Autonomous Driving
Jun 09, 2026Learning-based motion planners, despite recent progress, often suffer from temporal inconsistency. Small perturbations across frames can accumulate into unstable trajectories, degrading comfort and safety in closed-loop driving. Several methods attempt to inject history as a static conditioning signal to stabilize outputs, only to induce the planner to copy historical patterns instead of adapting to environment contexts. To address this limitation, we propose Diffusion Forcing Planner (DFP), a diffusion-based planning framework driven by history-guided control. Specifically, DFP decomposes the full trajectory into history, current and future segments, and assign independent noise levels to each segment. The model jointly denoises the historical and the future segments, enforcing a heterogeneous joint diffusion process. At inference, classifier-free guidance (CFG) is applied to steer future sampling using annealed history in a controllable manner. Closed-loop evaluation and comprehensive ablations on nuPlan show that DFP achieves competitive performance while producing continuous, stable, and controllable motion plans in complex driving scenarios.
DynamicVGGT: Learning Dynamic Point Maps for 4D Scene Reconstruction in Autonomous Driving
Mar 09, 2026Dynamic scene reconstruction in autonomous driving remains a fundamental challenge due to significant temporal variations, moving objects, and complex scene dynamics. Existing feed-forward 3D models have demonstrated strong performance in static reconstruction but still struggle to capture dynamic motion. To address these limitations, we propose DynamicVGGT, a unified feed-forward framework that extends VGGT from static 3D perception to dynamic 4D reconstruction. Our goal is to model point motion within feed-forward 3D models in a dynamic and temporally coherent manner. To this end, we jointly predict the current and future point maps within a shared reference coordinate system, allowing the model to implicitly learn dynamic point representations through temporal correspondence. To efficiently capture temporal dependencies, we introduce a Motion-aware Temporal Attention (MTA) module that learns motion continuity. Furthermore, we design a Dynamic 3D Gaussian Splatting Head that explicitly models point motion by predicting Gaussian velocities using learnable motion tokens under scene flow supervision. It refines dynamic geometry through continuous 3D Gaussian optimization. Extensive experiments on autonomous driving datasets demonstrate that DynamicVGGT significantly outperforms existing methods in reconstruction accuracy, achieving robust feed-forward 4D dynamic scene reconstruction under complex driving scenarios.
Single-Edge Node Injection Threats to GNN-Based Security Monitoring in Industrial Graph Systems
Feb 01, 2026Graph neural networks (GNNs) are increasingly adopted in industrial graph-based monitoring systems (e.g., Industrial internet of things (IIoT) device graphs, power-grid topology models, and manufacturing communication networks) to support anomaly detection, state estimation, and asset classification. In such settings, an adversary that compromises a small number of edge devices may inject counterfeit nodes (e.g., rogue sensors, virtualized endpoints, or spoofed substations) to bias downstream decisions while evading topology- and homophily-based sanitization. This paper formulates deployment-oriented node-injection attacks under constrained resources and proposes the \emph{Single-Edge Graph Injection Attack} (SEGIA), in which each injected node attaches to the operational graph through a single edge. SEGIA integrates a pruned SGC surrogate, multi-hop neighborhood sampling, and reverse graph convolution-based feature synthesis with a similarity-regularized objective to preserve local homophily and survive edge pruning. Theoretical analysis and extensive evaluations across datasets and defenses show at least $25\%$ higher attack success than representative baselines under substantially smaller edge budgets. These results indicate a system-level risk in industrial GNN deployments and motivate lightweight admission validation and neighborhood-consistency monitoring.
DGSNA: prompt-based Dynamic Generative Scene-based Noise Addition method
Nov 19, 2024



This paper addresses the challenges of accurately enumerating and describing scenes and the labor-intensive process required to replicate acoustic environments using non-generative methods. We introduce the prompt-based Dynamic Generative Sce-ne-based Noise Addition method (DGSNA), which innovatively combines the Dynamic Generation of Scene Information (DGSI) with Scene-based Noise Addition for Audio (SNAA). Employing generative chat models structured within the Back-ground-Examples-Task (BET) prompt framework, DGSI com-ponent facilitates the dynamic synthesis of tailored Scene Infor-mation (SI) for specific acoustic environments. Additionally, the SNAA component leverages Room Impulse Response (RIR) fil-ters and Text-To-Audio (TTA) systems to generate realistic, scene-based noise that can be adapted for both indoor and out-door environments. Through comprehensive experiments, the adaptability of DGSNA across different generative chat models was demonstrated. The results, assessed through both objective and subjective evaluations, show that DGSNA provides robust performance in dynamically generating precise SI and effectively enhancing scene-based noise addition capabilities, thus offering significant improvements over traditional methods in acoustic scene simulation. Our implementation and demos are available at https://dgsna.github.io.
Unsupervised Visual Representation Learning by Synchronous Momentum Grouping
Jul 13, 2022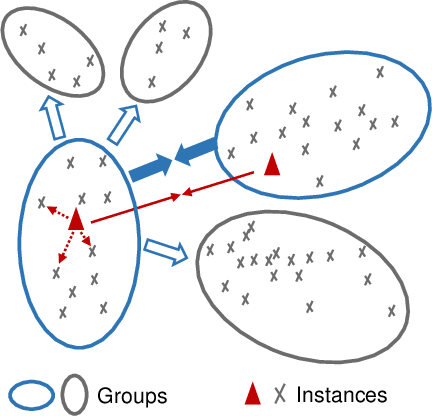
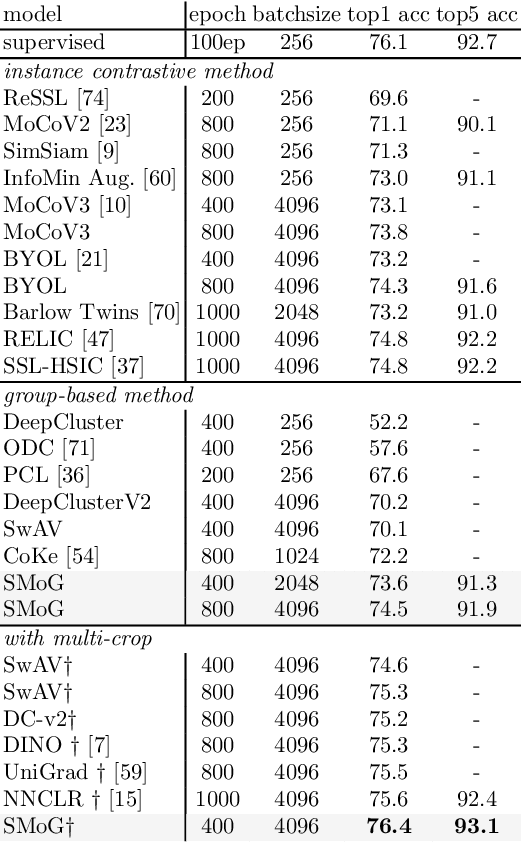

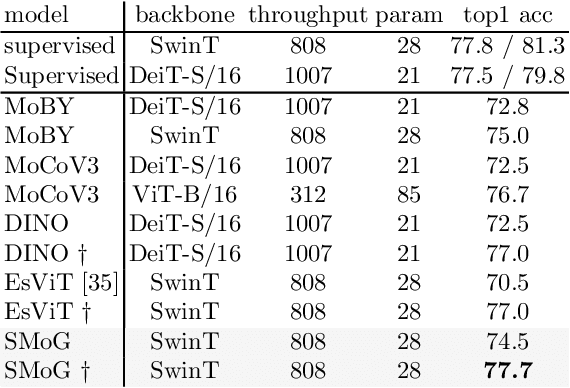
In this paper, we propose a genuine group-level contrastive visual representation learning method whose linear evaluation performance on ImageNet surpasses the vanilla supervised learning. Two mainstream unsupervised learning schemes are the instance-level contrastive framework and clustering-based schemes. The former adopts the extremely fine-grained instance-level discrimination whose supervisory signal is not efficient due to the false negatives. Though the latter solves this, they commonly come with some restrictions affecting the performance. To integrate their advantages, we design the SMoG method. SMoG follows the framework of contrastive learning but replaces the contrastive unit from instance to group, mimicking clustering-based methods. To achieve this, we propose the momentum grouping scheme which synchronously conducts feature grouping with representation learning. In this way, SMoG solves the problem of supervisory signal hysteresis which the clustering-based method usually faces, and reduces the false negatives of instance contrastive methods. We conduct exhaustive experiments to show that SMoG works well on both CNN and Transformer backbones. Results prove that SMoG has surpassed the current SOTA unsupervised representation learning methods. Moreover, its linear evaluation results surpass the performances obtained by vanilla supervised learning and the representation can be well transferred to downstream tasks.
WAD-CMSN: Wasserstein Distance based Cross-Modal Semantic Network for Zero-Shot Sketch-Based Image Retrieval
Feb 11, 2022



Zero-shot sketch-based image retrieval (ZSSBIR), as a popular studied branch of computer vision, attracts wide attention recently. Unlike sketch-based image retrieval (SBIR), the main aim of ZSSBIR is to retrieve natural images given free hand-drawn sketches that may not appear during training. Previous approaches used semantic aligned sketch-image pairs or utilized memory expensive fusion layer for projecting the visual information to a low dimensional subspace, which ignores the significant heterogeneous cross-domain discrepancy between highly abstract sketch and relevant image. This may yield poor performance in the training phase. To tackle this issue and overcome this drawback, we propose a Wasserstein distance based cross-modal semantic network (WAD-CMSN) for ZSSBIR. Specifically, it first projects the visual information of each branch (sketch, image) to a common low dimensional semantic subspace via Wasserstein distance in an adversarial training manner. Furthermore, identity matching loss is employed to select useful features, which can not only capture complete semantic knowledge, but also alleviate the over-fitting phenomenon caused by the WAD-CMSN model. Experimental results on the challenging Sketchy (Extended) and TU-Berlin (Extended) datasets indicate the effectiveness of the proposed WAD-CMSN model over several competitors.
Multi-scale Graph Convolutional Networks with Self-Attention
Dec 04, 2021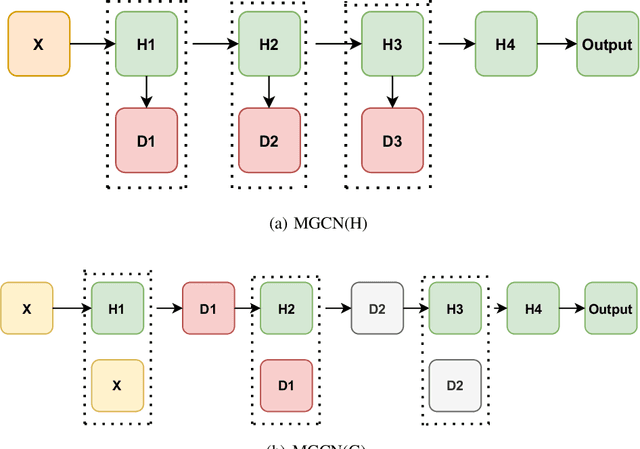
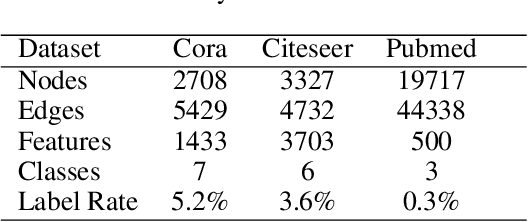

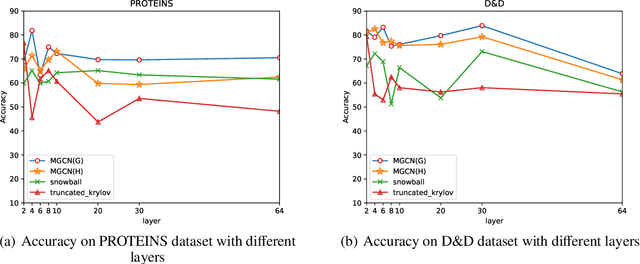
Graph convolutional networks (GCNs) have achieved remarkable learning ability for dealing with various graph structural data recently. In general, deep GCNs do not work well since graph convolution in conventional GCNs is a special form of Laplacian smoothing, which makes the representation of different nodes indistinguishable. In the literature, multi-scale information was employed in GCNs to enhance the expressive power of GCNs. However, over-smoothing phenomenon as a crucial issue of GCNs remains to be solved and investigated. In this paper, we propose two novel multi-scale GCN frameworks by incorporating self-attention mechanism and multi-scale information into the design of GCNs. Our methods greatly improve the computational efficiency and prediction accuracy of the GCNs model. Extensive experiments on both node classification and graph classification demonstrate the effectiveness over several state-of-the-art GCNs. Notably, the proposed two architectures can efficiently mitigate the over-smoothing problem of GCNs, and the layer of our model can even be increased to $64$.
SStaGCN: Simplified stacking based graph convolutional networks
Nov 16, 2021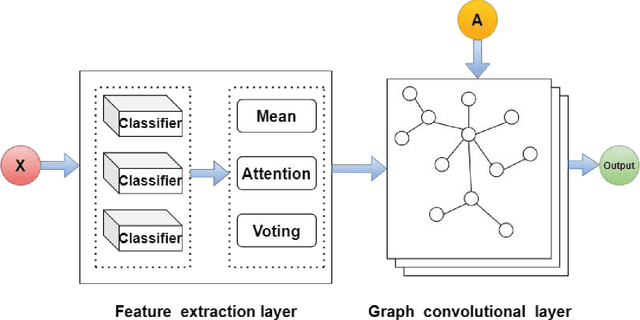
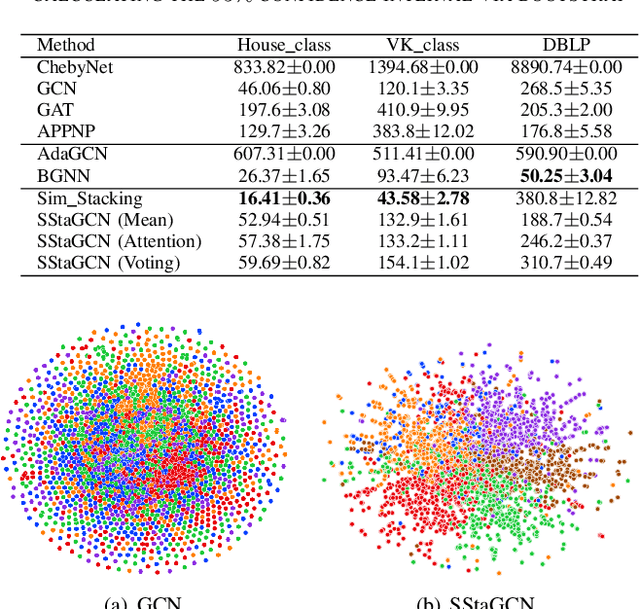


Graph convolutional network (GCN) is a powerful model studied broadly in various graph structural data learning tasks. However, to mitigate the over-smoothing phenomenon, and deal with heterogeneous graph structural data, the design of GCN model remains a crucial issue to be investigated. In this paper, we propose a novel GCN called SStaGCN (Simplified stacking based GCN) by utilizing the ideas of stacking and aggregation, which is an adaptive general framework for tackling heterogeneous graph data. Specifically, we first use the base models of stacking to extract the node features of a graph. Subsequently, aggregation methods such as mean, attention and voting techniques are employed to further enhance the ability of node features extraction. Thereafter, the node features are considered as inputs and fed into vanilla GCN model. Furthermore, theoretical generalization bound analysis of the proposed model is explicitly given. Extensive experiments on $3$ public citation networks and another $3$ heterogeneous tabular data demonstrate the effectiveness and efficiency of the proposed approach over state-of-the-art GCNs. Notably, the proposed SStaGCN can efficiently mitigate the over-smoothing problem of GCN.
Sparse Generalized Canonical Correlation Analysis: Distributed Alternating Iteration based Approach
Apr 23, 2020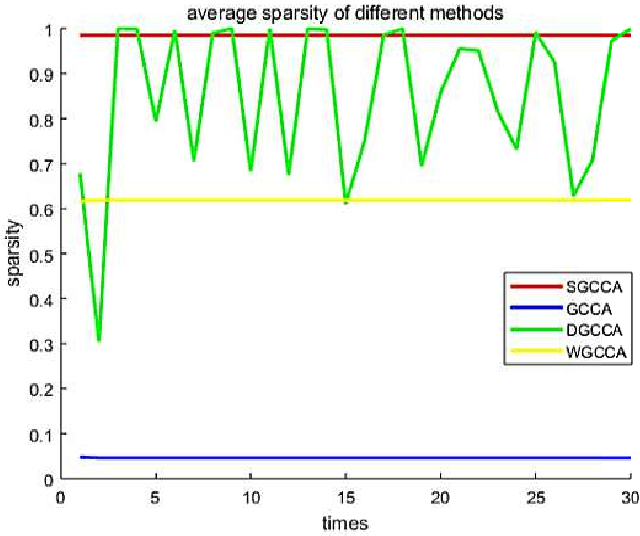
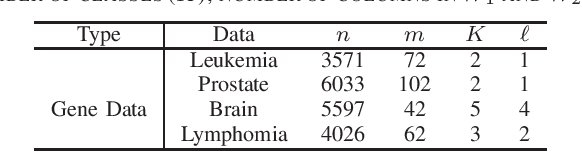
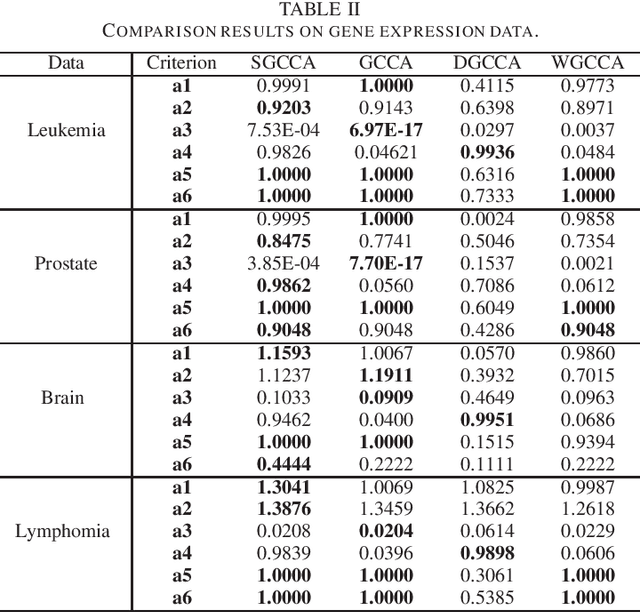
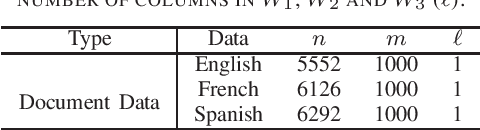
Sparse canonical correlation analysis (CCA) is a useful statistical tool to detect latent information with sparse structures. However, sparse CCA works only for two datasets, i.e., there are only two views or two distinct objects. To overcome this limitation, in this paper, we propose a sparse generalized canonical correlation analysis (GCCA), which could detect the latent relations of multiview data with sparse structures. Moreover, the introduced sparsity could be considered as Laplace prior on the canonical variates. Specifically, we convert the GCCA into a linear system of equations and impose $\ell_1$ minimization penalty for sparsity pursuit. This results in a nonconvex problem on Stiefel manifold, which is difficult to solve. Motivated by Boyd's consensus problem, an algorithm based on distributed alternating iteration approach is developed and theoretical consistency analysis is investigated elaborately under mild conditions. Experiments on several synthetic and real world datasets demonstrate the effectiveness of the proposed algorithm.