 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Free 3D Shape Control of Deformable Objects Using Novel Features Based on Modal Analysis
Jul 04, 2022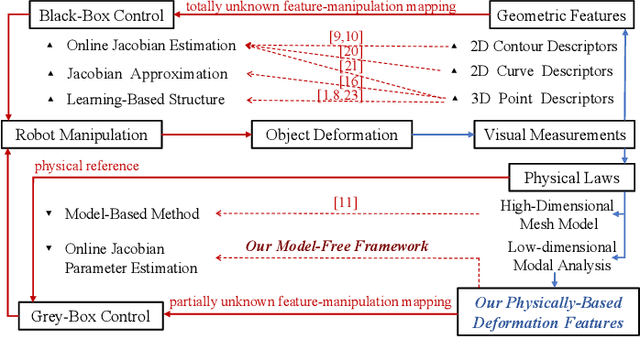
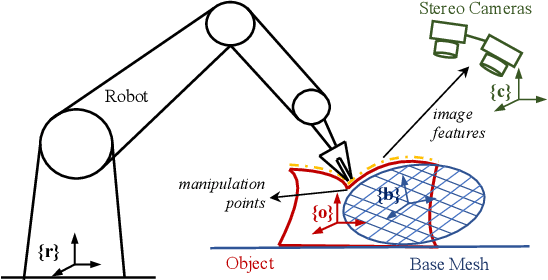
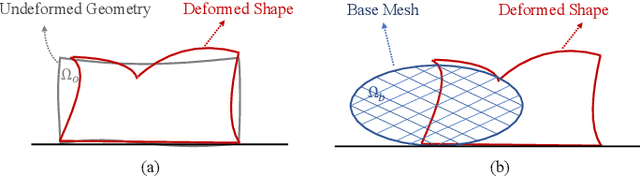

Shape control of deformable objects is a challenging and important robotic problem. This paper proposes a model-free controller using novel 3D global deformation features based on modal analysis. Unlike most existing controllers using geometric features, our controller employs a physically-based deformation feature by decoupling 3D global deformation into low-frequency mode shapes. Although modal analysis is widely adopted in computer vision and simulation, it has not been used in robotic deformation control. We develop a new model-free framework for modal-based deformation control under robot manipulation. Physical interpretation of mode shapes enables us to formulate an analytical deformation Jacobian matrix mapping the robot manipulation onto changes of the modal features. In the Jacobian matrix, unknown geometry and physical properties of the object are treated as low-dimensional modal parameters which can be used to linearly parameterize the closed-loop system. Thus, an adaptive controller with proven stability can be designed to deform the object while online estimating the modal parameters. Simulations and experiments are conducted using linear, planar, and solid objects under different settings. The results not only confirm the superior performance of our controller but also demonstrate its advantages over the baseline method.
3D Perception based Imitation Learning under Limited Demonstration for Laparoscope Control in Robotic Surgery
Apr 07, 2022
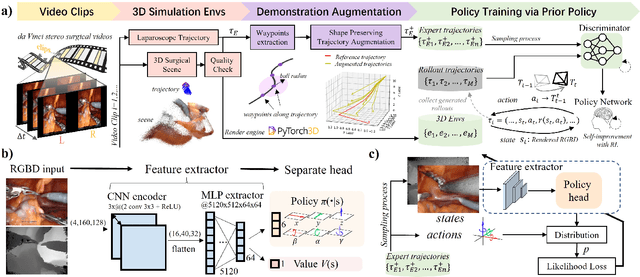
Automatic laparoscope motion control is fundamentally important for surgeons to efficiently perform operations. However, its traditional control methods based on tool tracking without considering information hidden in surgical scenes are not intelligent enough, while the latest supervised imitation learning (IL)-based methods require expensive sensor data and suffer from distribution mismatch issues caused by limited demonstrations. In this paper, we propose a novel Imitation Learning framework for Laparoscope Control (ILLC) with reinforcement learning (RL), which can efficiently learn the control policy from limited surgical video clips. Specially, we first extract surgical laparoscope trajectories from unlabeled videos as the demonstrations and reconstruct the corresponding surgical scenes. To fully learn from limited motion trajectory demonstrations, we propose Shape Preserving Trajectory Augmentation (SPTA) to augment these data, and build a simulation environment that supports parallel RGB-D rendering to reinforce the RL policy for interacting with the environment efficiently. With adversarial training for IL, we obtain the laparoscope control policy based on the generated rollouts and surgical demonstrations. Extensive experiments are conducted in unseen reconstructed surgical scenes, and our method outperforms the previous IL methods, which proves the feasibility of our unified learning-based framework for laparoscope control.
Stereo Dense Scene Reconstruction and Accurate Laparoscope Localization for Learning-Based Navigation in Robot-Assisted Surgery
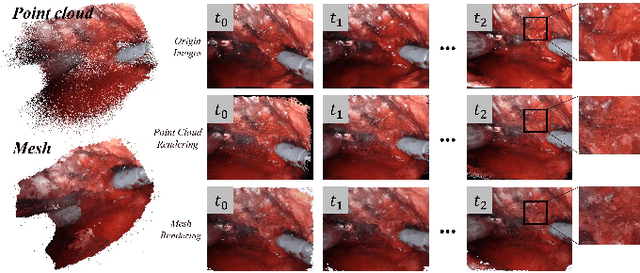
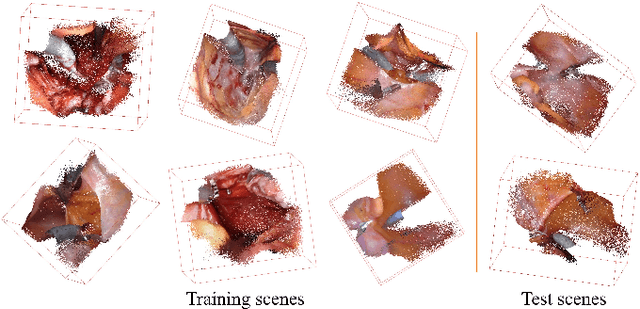
Oct 08, 2021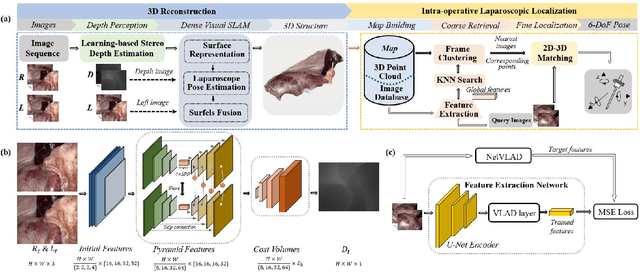
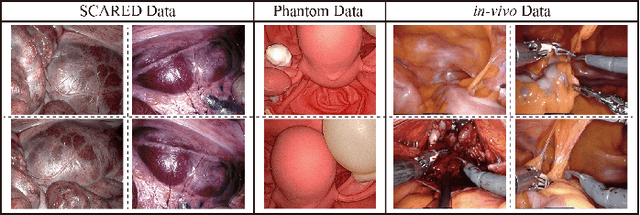
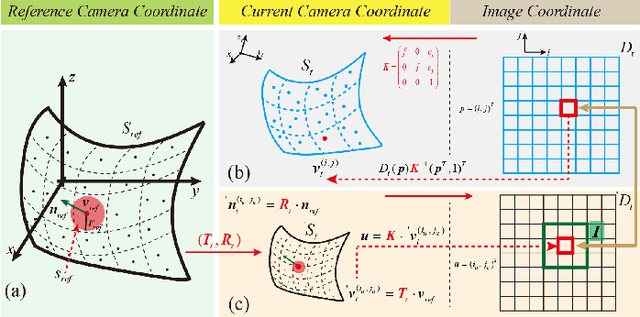
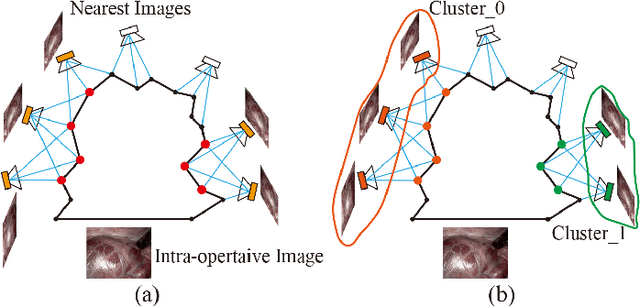
The computation of anatomical information and laparoscope position is a fundamental block of robot-assisted surgical navigation in Minimally Invasive Surgery (MIS). Recovering a dense 3D structure of surgical scene using visual cues remains a challenge, and the online laparoscopic tracking mostly relies on external sensors, which increases system complexity. In this paper, we propose a learning-driven framework, in which an image-guided laparoscopic localization with 3D reconstructions of complex anatomical structures is hereby achieved. To reconstruct the 3D structure of the whole surgical environment, we first fine-tune a learning-based stereoscopic depth perception method, which is robust to the texture-less and variant soft tissues, for depth estimation. Then, we develop a dense visual reconstruction algorithm to represent the scene by surfels, estimate the laparoscope pose and fuse the depth data into a unified reference coordinate for tissue reconstruction. To estimate poses of new laparoscope views, we realize a coarse-to-fine localization method, which incorporates our reconstructed 3D model. We evaluate the reconstruction method and the localization module on three datasets, namely, the stereo correspondence and reconstruction of endoscopic data (SCARED), the ex-vivo phantom and tissue data collected with Universal Robot (UR) and Karl Storz Laparoscope, and the in-vivo DaVinci robotic surgery dataset. Extensive experiments have been conducted to prove the superior performance of our method in 3D anatomy reconstruction and laparoscopic localization, which demonstrates its potential implementation to surgical navigation system.
PlaTe: Visually-Grounded Planning with Transformers in Procedural Tasks
Sep 10, 2021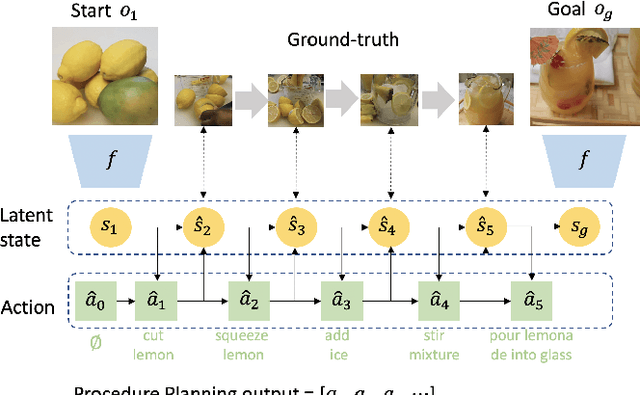
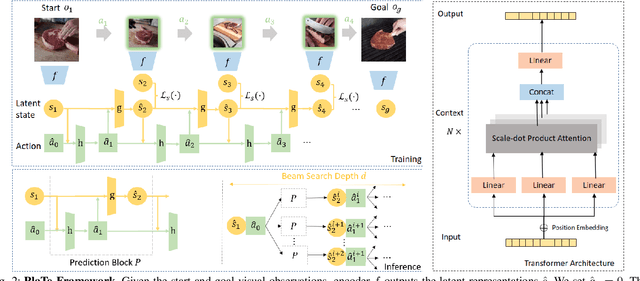
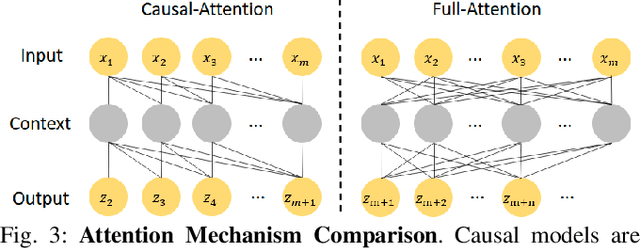

In this work, we study the problem of how to leverage instructional videos to facilitate the understanding of human decision-making processes, focusing on training a model with the ability to plan a goal-directed procedure from real-world videos. Learning structured and plannable state and action spaces directly from unstructured videos is the key technical challenge of our task. There are two problems: first, the appearance gap between the training and validation datasets could be large for unstructured videos; second, these gaps lead to decision errors that compound over the steps. We address these limitations with Planning Transformer (PlaTe), which has the advantage of circumventing the compounding prediction errors that occur with single-step models during long model-based rollouts. Our method simultaneously learns the latent state and action information of assigned tasks and the representations of the decision-making process from human demonstrations. Experiments conducted on real-world instructional videos and an interactive environment show that our method can achieve a better performance in reaching the indicated goal than previous algorithms. We also validated the possibility of applying procedural tasks on a UR-5 platform.
SurRoL: An Open-source Reinforcement Learning Centered and dVRK Compatible Platform for Surgical Robot Learning
Aug 30, 2021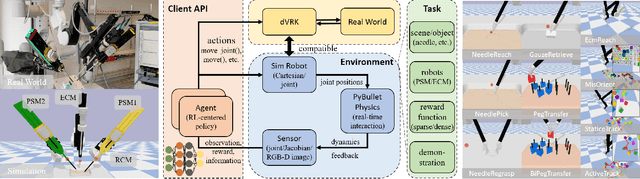
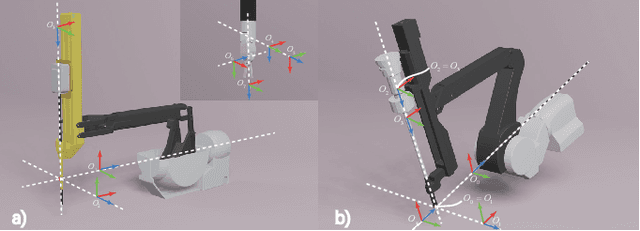
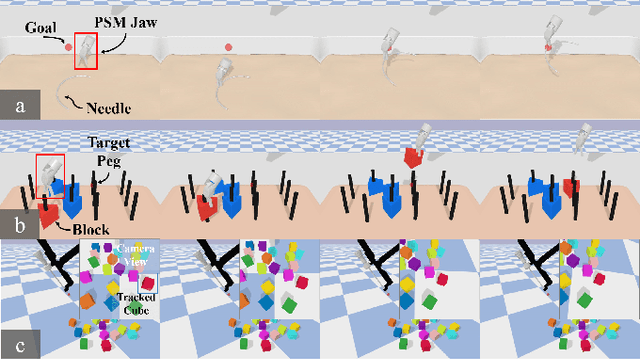
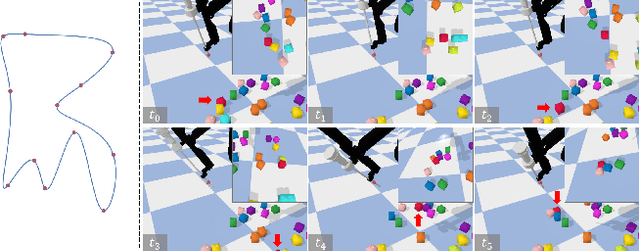
Autonomous surgical execution relieves tedious routines and surgeon's fatigue. Recent learning-based methods, especially reinforcement learning (RL) based methods, achieve promising performance for dexterous manipulation, which usually requires the simulation to collect data efficiently and reduce the hardware cost. The existing learning-based simulation platforms for medical robots suffer from limited scenarios and simplified physical interactions, which degrades the real-world performance of learned policies. In this work, we designed SurRoL, an RL-centered simulation platform for surgical robot learning compatible with the da Vinci Research Kit (dVRK). The designed SurRoL integrates a user-friendly RL library for algorithm development and a real-time physics engine, which is able to support more PSM/ECM scenarios and more realistic physical interactions. Ten learning-based surgical tasks are built in the platform, which are common in the real autonomous surgical execution. We evaluate SurRoL using RL algorithms in simulation, provide in-depth analysis, deploy the trained policies on the real dVRK, and show that our SurRoL achieves better transferability in the real world.
Constrained Motion Planning of A Cable-Driven Soft Robot With Compressible Curvature Modeling
Jun 15, 2021



A cable-driven soft-bodied robot with redundancy can conduct the trajectory tracking task and in the meanwhile fulfill some extra constraints, such as tracking through an end-effector in designated orientation, or get rid of the evitable manipulator-obstacle collision. Those constraints require rational planning of the robot motion. In this work, we derived the compressible curvature kinematics of a cable-driven soft robot which takes the compressible soft segment into account. The motion planning of the soft robot for a trajectory tracking task in constrained conditions, including fixed orientation end-effector and manipulator-obstacle collision avoidance, has been investigated. The inverse solution of cable actuation was formulated as a damped least-square optimization problem and iteratively computed off-line. The performance of trajectory tracking and the obedience to constraints were evaluated via the simulation we made open-source, as well as the prototype experiments. The method can be generalized to the similar multisegment cable-driven soft robotic systems by customizing the robot parameters for the prior motion planning of the manipulator.
One to Many: Adaptive Instrument Segmentation via Meta Learning and Dynamic Online Adaptation in Robotic Surgical Video
Mar 24, 2021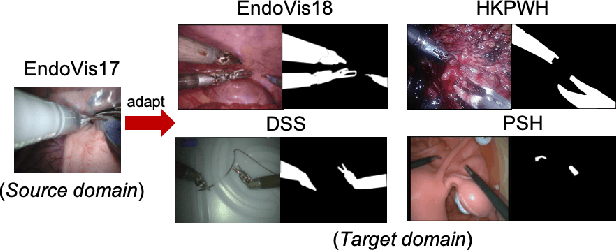
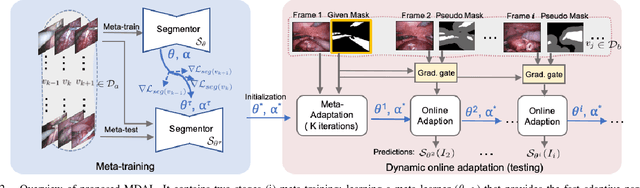

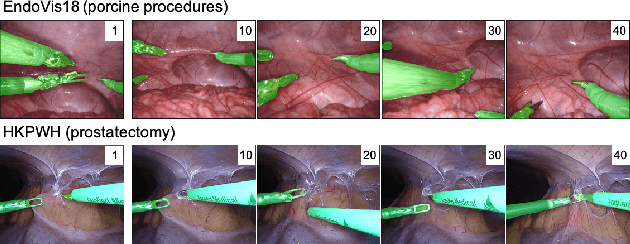
Surgical instrument segmentation in robot-assisted surgery (RAS) - especially that using learning-based models - relies on the assumption that training and testing videos are sampled from the same domain. However, it is impractical and expensive to collect and annotate sufficient data from every new domain. To greatly increase the label efficiency, we explore a new problem, i.e., adaptive instrument segmentation, which is to effectively adapt one source model to new robotic surgical videos from multiple target domains, only given the annotated instruments in the first frame. We propose MDAL, a meta-learning based dynamic online adaptive learning scheme with a two-stage framework to fast adapt the model parameters on the first frame and partial subsequent frames while predicting the results. MDAL learns the general knowledge of instruments and the fast adaptation ability through the video-specific meta-learning paradigm. The added gradient gate excludes the noisy supervision from pseudo masks for dynamic online adaptation on target videos. We demonstrate empirically that MDAL outperforms other state-of-the-art methods on two datasets (including a real-world RAS dataset). The promising performance on ex-vivo scenes also benefits the downstream tasks such as robot-assisted suturing and camera control.
Data-driven Holistic Framework for Automated Laparoscope Optimal View Control with Learning-based Depth Perception
Nov 23, 2020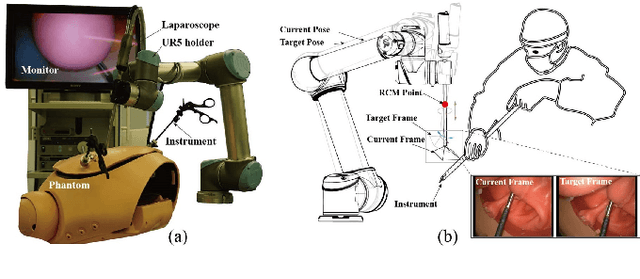
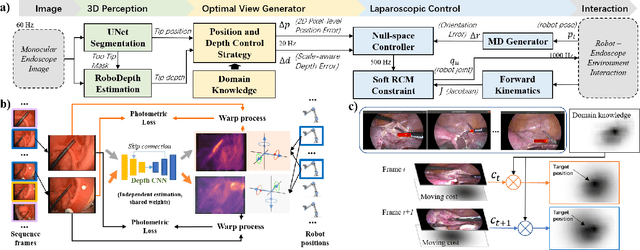
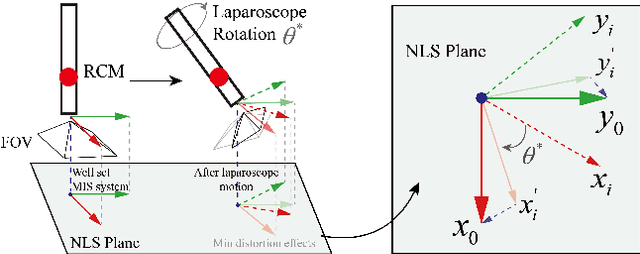
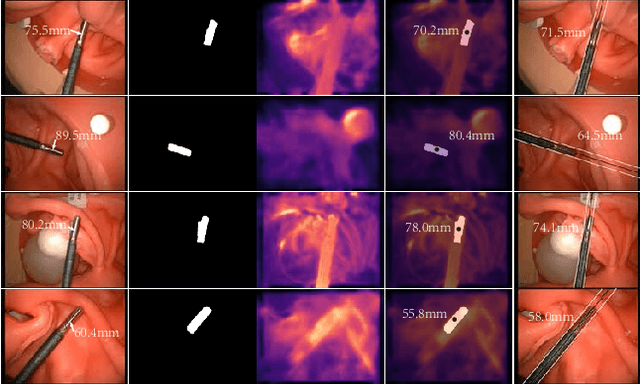
Laparoscopic Field of View (FOV) control is one of the most fundamental and important components in Minimally Invasive Surgery (MIS), nevertheless, the traditional manual holding paradigm may easily bring fatigue to surgical assistants, and misunderstanding between surgeons also hinders assistants to provide a high-quality FOV. Targeting this problem, we here present a data-driven framework to realize an automated laparoscopic optimal FOV control. To achieve this goal, we offline learn a motion strategy of laparoscope relative to the surgeon's hand-held surgical tool from our in-house surgical videos, developing our control domain knowledge and an optimal view generator. To adjust the laparoscope online, we first adopt a learning-based method to segment the two-dimensional (2D) position of the surgical tool, and further leverage this outcome to obtain its scale-aware depth from dense depth estimation results calculated by our novel unsupervised RoboDepth model only with the monocular camera feedback, hence in return fusing the above real-time 3D position into our control loop. To eliminate the misorientation of FOV caused by Remote Center of Motion (RCM) constraints when moving the laparoscope, we propose a novel distortion constraint using an affine map to minimize the visual warping problem, and a null-space controller is also embedded into the framework to optimize all types of errors in a unified and decoupled manner. Experiments are conducted using Universal Robot (UR) and Karl Storz Laparoscope/Instruments, which prove the feasibility of our domain knowledge and learning enabled framework for automated camera control.
Relational Graph Learning on Visual and Kinematics Embeddings for Accurate Gesture Recognition in Robotic Surgery
Nov 03, 2020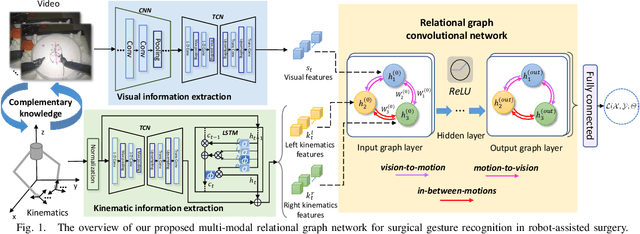
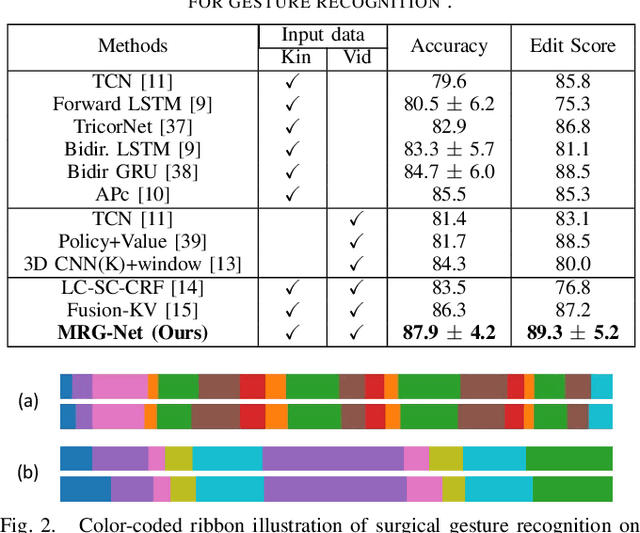
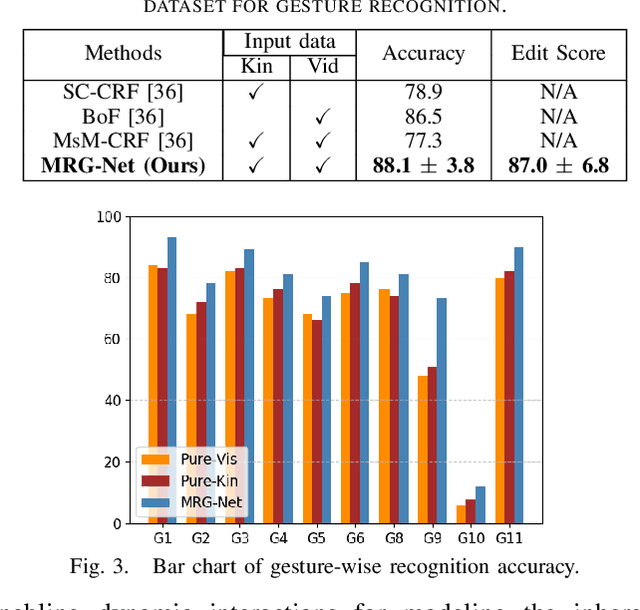

Automatic surgical gesture recognition is fundamentally important to enable intelligent cognitive assistance in robotic surgery. With recent advancement in robot-assisted minimally invasive surgery, rich information including surgical videos and robotic kinematics can be recorded, which provide complementary knowledge for understanding surgical gestures. However, existing methods either solely adopt uni-modal data or directly concatenate multi-modal representations, which can not sufficiently exploit the informative correlations inherent in visual and kinematics data to boost gesture recognition accuracies. In this regard, we propose a novel approach of multimodal relational graph network (i.e., MRG-Net) to dynamically integrate visual and kinematics information through interactive message propagation in the latent feature space. In specific, we first extract embeddings from video and kinematics sequences with temporal convolutional networks and LSTM units. Next, we identify multi-relations in these multi-modal features and model them through a hierarchical relational graph learning module. The effectiveness of our method is demonstrated with state-of-the-art results on the public JIGSAWS dataset, outperforming current uni-modal and multi-modal methods on both suturing and knot typing tasks. Furthermore, we validated our method on in-house visual-kinematics datasets collected with da Vinci Research Kit (dVRK) platforms in two centers, with consistent promising performance achieved.
A Learning-Driven Framework with Spatial Optimization For Surgical Suture Thread Reconstruction and Autonomous Grasping Under Multiple Topologies and Environmental Noises
Jul 02, 2020Surgical knot tying is one of the most fundamental and important procedures in surgery, and a high-quality knot can significantly benefit the postoperative recovery of the patient. However, a longtime operation may easily cause fatigue to surgeons, especially during the tedious wound closure task. In this paper, we present a vision-based method to automate the suture thread grasping, which is a sub-task in surgical knot tying and an intermediate step between the stitching and looping manipulations. To achieve this goal, the acquisition of a suture's three-dimensional (3D) information is critical. Towards this objective, we adopt a transfer-learning strategy first to fine-tune a pre-trained model by learning the information from large legacy surgical data and images obtained by the on-site equipment. Thus, a robust suture segmentation can be achieved regardless of inherent environment noises. We further leverage a searching strategy with termination policies for a suture's sequence inference based on the analysis of multiple topologies. Exact results of the pixel-level sequence along a suture can be obtained, and they can be further applied for a 3D shape reconstruction using our optimized shortest path approach. The grasping point considering the suturing criterion can be ultimately acquired. Experiments regarding the suture 2D segmentation and ordering sequence inference under environmental noises were extensively evaluated. Results related to the automated grasping operation were demonstrated by simulations in V-REP and by robot experiments using Universal Robot (UR) together with the da Vinci Research Kit (dVRK) adopting our learning-driven framework.