 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Graph Learning on Visual and Kinematics Embeddings for Accurate Gesture Recognition in Robotic Surgery
Nov 03, 2020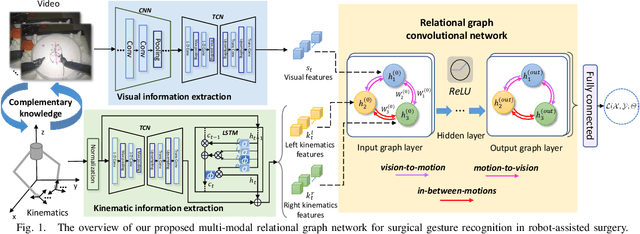
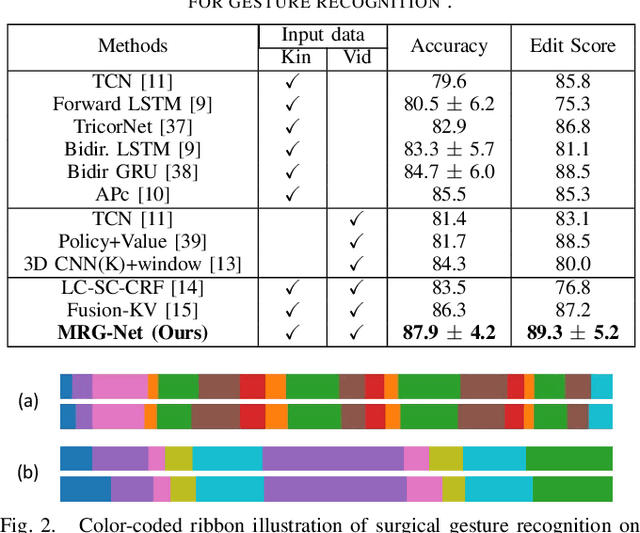
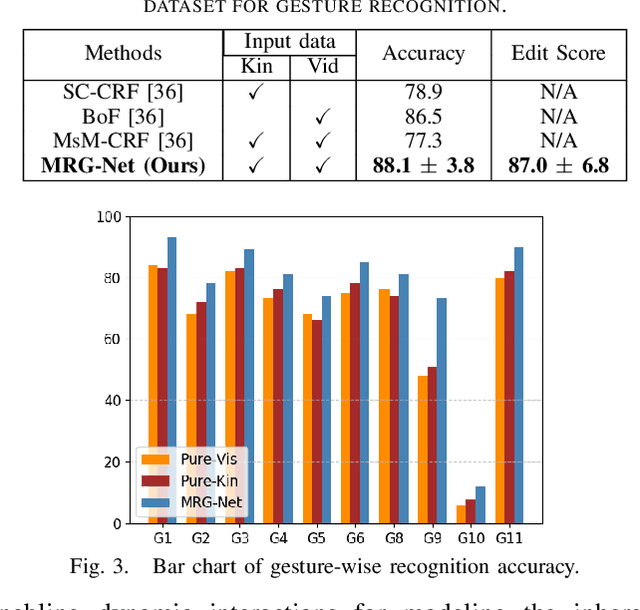

Automatic surgical gesture recognition is fundamentally important to enable intelligent cognitive assistance in robotic surgery. With recent advancement in robot-assisted minimally invasive surgery, rich information including surgical videos and robotic kinematics can be recorded, which provide complementary knowledge for understanding surgical gestures. However, existing methods either solely adopt uni-modal data or directly concatenate multi-modal representations, which can not sufficiently exploit the informative correlations inherent in visual and kinematics data to boost gesture recognition accuracies. In this regard, we propose a novel approach of multimodal relational graph network (i.e., MRG-Net) to dynamically integrate visual and kinematics information through interactive message propagation in the latent feature space. In specific, we first extract embeddings from video and kinematics sequences with temporal convolutional networks and LSTM units. Next, we identify multi-relations in these multi-modal features and model them through a hierarchical relational graph learning module. The effectiveness of our method is demonstrated with state-of-the-art results on the public JIGSAWS dataset, outperforming current uni-modal and multi-modal methods on both suturing and knot typing tasks. Furthermore, we validated our method on in-house visual-kinematics datasets collected with da Vinci Research Kit (dVRK) platforms in two centers, with consistent promising performance achieved.
A Learning-Driven Framework with Spatial Optimization For Surgical Suture Thread Reconstruction and Autonomous Grasping Under Multiple Topologies and Environmental Noises
Jul 02, 2020Surgical knot tying is one of the most fundamental and important procedures in surgery, and a high-quality knot can significantly benefit the postoperative recovery of the patient. However, a longtime operation may easily cause fatigue to surgeons, especially during the tedious wound closure task. In this paper, we present a vision-based method to automate the suture thread grasping, which is a sub-task in surgical knot tying and an intermediate step between the stitching and looping manipulations. To achieve this goal, the acquisition of a suture's three-dimensional (3D) information is critical. Towards this objective, we adopt a transfer-learning strategy first to fine-tune a pre-trained model by learning the information from large legacy surgical data and images obtained by the on-site equipment. Thus, a robust suture segmentation can be achieved regardless of inherent environment noises. We further leverage a searching strategy with termination policies for a suture's sequence inference based on the analysis of multiple topologies. Exact results of the pixel-level sequence along a suture can be obtained, and they can be further applied for a 3D shape reconstruction using our optimized shortest path approach. The grasping point considering the suturing criterion can be ultimately acquired. Experiments regarding the suture 2D segmentation and ordering sequence inference under environmental noises were extensively evaluated. Results related to the automated grasping operation were demonstrated by simulations in V-REP and by robot experiments using Universal Robot (UR) together with the da Vinci Research Kit (dVRK) adopting our learning-driven framework.