 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
Mar 31, 2024



Neural Text-to-Speech (TTS) systems find broad applications in voice assistants, e-learning, and audiobook creation. The pursuit of modern models, like Diffusion Models (DMs), holds promise for achieving high-fidelity, real-time speech synthesis. Yet, the efficiency of multi-step sampling in Diffusion Models presents challenges. Efforts have been made to integrate GANs with DMs, speeding up inference by approximating denoising distributions, but this introduces issues with model convergence due to adversarial training. To overcome this, we introduce CM-TTS, a novel architecture grounded in consistency models (CMs). Drawing inspiration from continuous-time diffusion models, CM-TTS achieves top-quality speech synthesis in fewer steps without adversarial training or pre-trained model dependencies. We further design weighted samplers to incorporate different sampling positions into model training with dynamic probabilities, ensuring unbiased learning throughout the entire training process. We present a real-time mel-spectrogram generation consistency model, validated through comprehensive evaluations. Experimental results underscore CM-TTS's superiority over existing single-step speech synthesis systems, representing a significant advancement in the field.
From Flies to Robots: Inverted Landing in Small Quadcopters with Dynamic Perching
Feb 29, 2024



Inverted landing is a routine behavior among a number of animal fliers. However, mastering this feat poses a considerable challenge for robotic fliers, especially to perform dynamic perching with rapid body rotations (or flips) and landing against gravity. Inverted landing in flies have suggested that optical flow senses are closely linked to the precise triggering and control of body flips that lead to a variety of successful landing behaviors. Building upon this knowledge, we aimed to replicate the flies' landing behaviors in small quadcopters by developing a control policy general to arbitrary ceiling-approach conditions. First, we employed reinforcement learning in simulation to optimize discrete sensory-motor pairs across a broad spectrum of ceiling-approach velocities and directions. Next, we converted the sensory-motor pairs to a two-stage control policy in a continuous augmented-optical flow space. The control policy consists of a first-stage Flip-Trigger Policy, which employs a one-class support vector machine, and a second-stage Flip-Action Policy, implemented as a feed-forward neural network. To transfer the inverted-landing policy to physical systems, we utilized domain randomization and system identification techniques for a zero-shot sim-to-real transfer. As a result, we successfully achieved a range of robust inverted-landing behaviors in small quadcopters, emulating those observed in flies.
Making Pre-trained Language Models Better Continual Few-Shot Relation Extractors
Feb 24, 2024



Continual Few-shot Relation Extraction (CFRE) is a practical problem that requires the model to continuously learn novel relations while avoiding forgetting old ones with few labeled training data. The primary challenges are catastrophic forgetting and overfitting. This paper harnesses prompt learning to explore the implicit capabilities of pre-trained language models to address the above two challenges, thereby making language models better continual few-shot relation extractors. Specifically, we propose a Contrastive Prompt Learning framework, which designs prompt representation to acquire more generalized knowledge that can be easily adapted to old and new categories, and margin-based contrastive learning to focus more on hard samples, therefore alleviating catastrophic forgetting and overfitting issues. To further remedy overfitting in low-resource scenarios, we introduce an effective memory augmentation strategy that employs well-crafted prompts to guide ChatGPT in generating diverse samples. Extensive experiments demonstrate that our method outperforms state-of-the-art methods by a large margin and significantly mitigates catastrophic forgetting and overfitting in low-resource scenarios.
Focus on Local Regions for Query-based Object Detection
Oct 10, 2023



Query-based methods have garnered significant attention in object detection since the advent of DETR, the pioneering end-to-end query-based detector. However, these methods face challenges like slow convergence and suboptimal performance. Notably, self-attention in object detection often hampers convergence due to its global focus. To address these issues, we propose FoLR, a transformer-like architecture with only decoders. We enhance the self-attention mechanism by isolating connections between irrelevant objects that makes it focus on local regions but not global regions. We also design the adaptive sampling method to extract effective features based on queries' local regions from feature maps. Additionally, we employ a look-back strategy for decoders to retain prior information, followed by the Feature Mixer module to fuse features and queries. Experimental results demonstrate FoLR's state-of-the-art performance in query-based detectors, excelling in convergence speed and computational efficiency.
Robot motor learning shows emergence of frequency-modulated, robust swimming with an invariant Strouhal-number
Jul 17, 2023Fish locomotion emerges from a diversity of interactions among deformable structures, surrounding fluids and neuromuscular activations, i.e., fluid-structure interactions (FSI) controlled by fish's motor systems. Previous studies suggested that such motor-controlled FSI may possess embodied traits. However, their implications in motor learning, neuromuscular control, gait generation, and swimming performance remain to be uncovered. Using robot models, we studied how swimming behaviours emerged from the FSI and the embodied traits. We developed modular robots with various designs and used Central Pattern Generators (CPGs) to control the torque acting on robot body. We used reinforcement learning to learn CPG parameters to maximize the swimming speed. The results showed that motor frequency converged faster than other parameters, and the emergent swimming gaits were robust against disruptions applied to motor control. For all robots and frequencies tested, swimming speed was proportional to the mean undulation velocity of body and caudal-fin combined, yielding an invariant, undulation-based Strouhal number. The Strouhal number also revealed two fundamental classes of undulatory swimming in both biological and robotic fishes. The robot actuators also demonstrated diverse functions as motors, virtual springs, and virtual masses. These results provide novel insights into the embodied traits of motor-controlled FSI for fish-inspired locomotion.
Inverted Landing in a Small Aerial Robot via Deep Reinforcement Learning for Triggering and Control of Rotational Maneuvers
Sep 22, 2022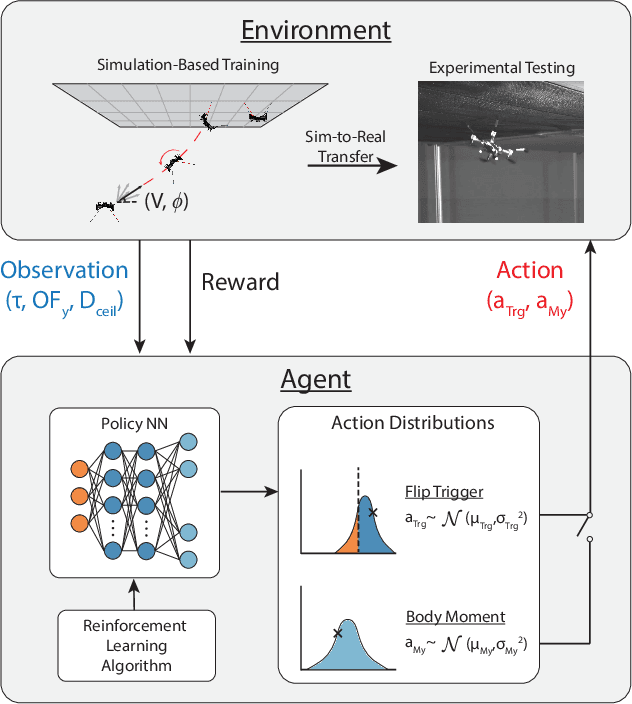
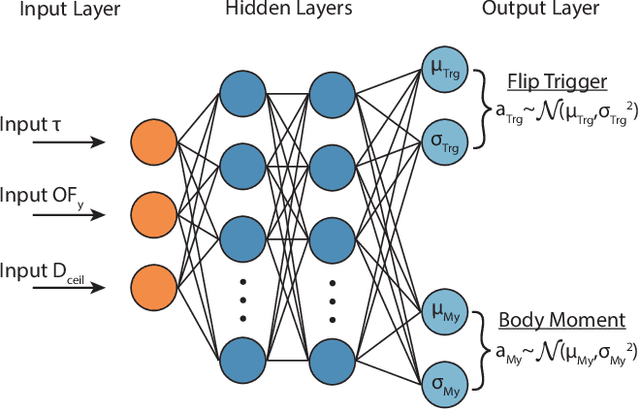
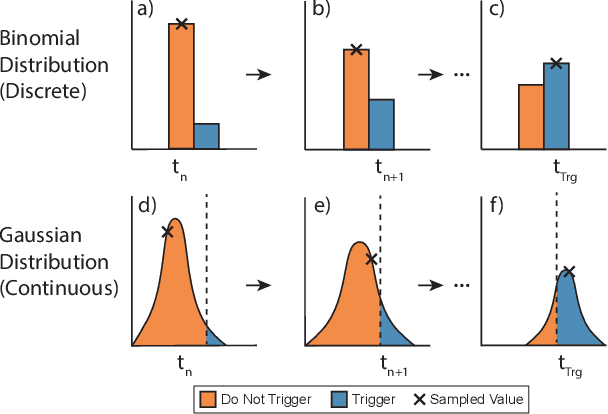
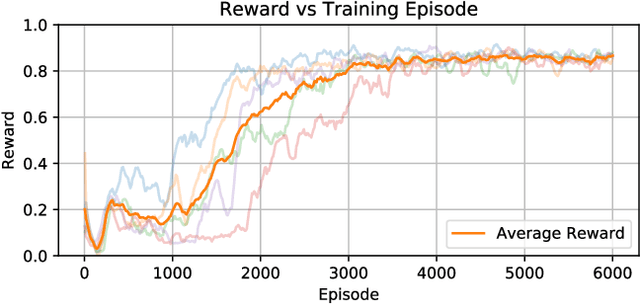
Inverted landing in a rapid and robust manner is a challenging feat for aerial robots, especially while depending entirely on onboard sensing and computation. In spite of this, this feat is routinely performed by biological fliers such as bats, flies, and bees. Our previous work has identified a direct causal connection between a series of onboard visual cues and kinematic actions that allow for reliable execution of this challenging aerobatic maneuver in small aerial robots. In this work, we first utilized Deep Reinforcement Learning and a physics-based simulation to obtain a general, optimal control policy for robust inverted landing starting from any arbitrary approach condition. This optimized control policy provides a computationally-efficient mapping from the system's observational space to its motor command action space, including both triggering and control of rotational maneuvers. This was done by training the system over a large range of approach flight velocities that varied with magnitude and direction. Next, we performed a sim-to-real transfer and experimental validation of the learned policy via domain randomization, by varying the robot's inertial parameters in the simulation. Through experimental trials, we identified several dominant factors which greatly improved landing robustness and the primary mechanisms that determined inverted landing success. We expect the learning framework developed in this study can be generalized to solve more challenging tasks, such as utilizing noisy onboard sensory data, landing on surfaces of various orientations, or landing on dynamically-moving surfaces.
Analyzing Modality Robustness in Multimodal Sentiment Analysis
May 30, 2022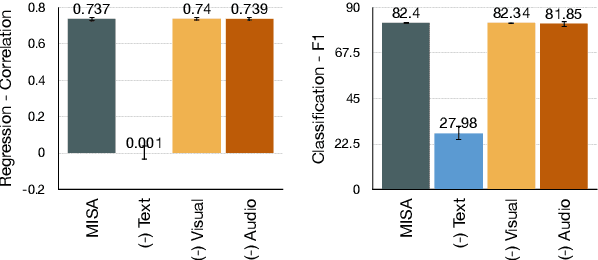
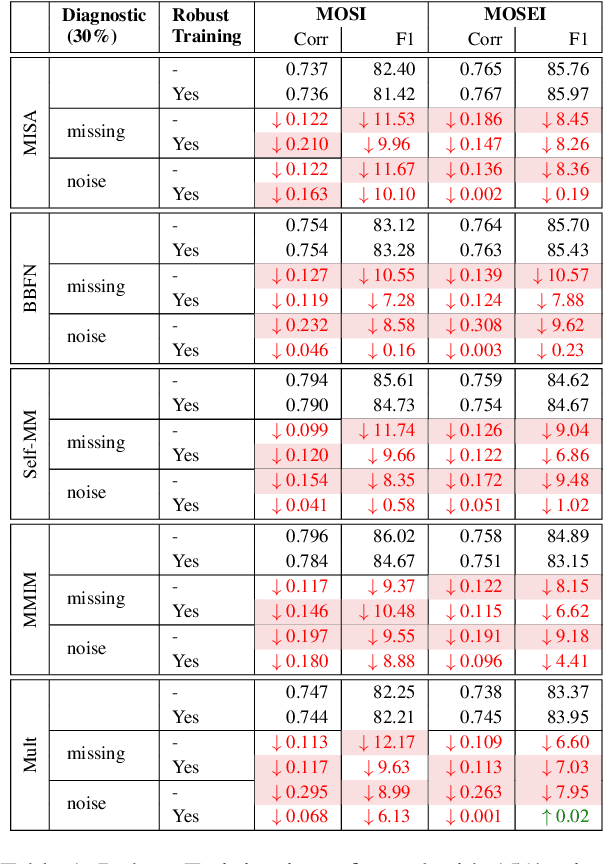
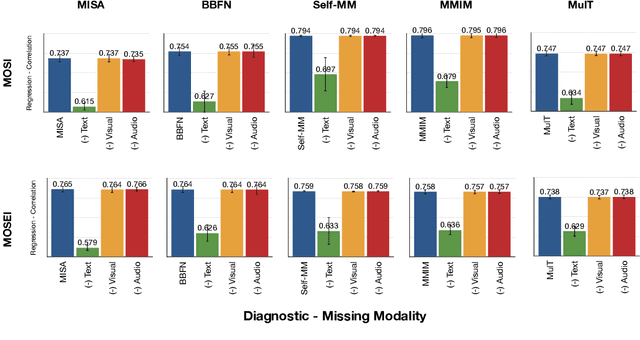
Building robust multimodal models are crucial for achieving reliable deployment in the wild. Despite its importance, less attention has been paid to identifying and improving the robustness of Multimodal Sentiment Analysis (MSA) models. In this work, we hope to address that by (i) Proposing simple diagnostic checks for modality robustness in a trained multimodal model. Using these checks, we find MSA models to be highly sensitive to a single modality, which creates issues in their robustness; (ii) We analyze well-known robust training strategies to alleviate the issues. Critically, we observe that robustness can be achieved without compromising on the original performance. We hope our extensive study-performed across five models and two benchmark datasets-and proposed procedures would make robustness an integral component in MSA research. Our diagnostic checks and robust training solutions are simple to implement and available at https://github. com/declare-lab/MSA-Robustness.
Exploring Entity Interactions for Few-Shot Relation Learning (Student Abstract)
May 04, 2022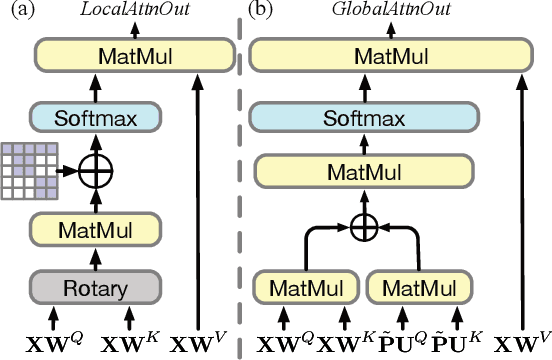
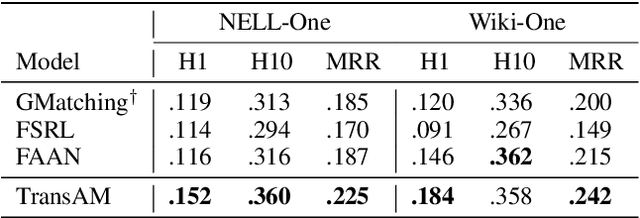
Few-shot relation learning refers to infer facts for relations with a limited number of observed triples. Existing metric-learning methods for this problem mostly neglect entity interactions within and between triples. In this paper, we explore this kind of fine-grained semantic meanings and propose our model TransAM. Specifically, we serialize reference entities and query entities into sequence and apply transformer structure with local-global attention to capture both intra- and inter-triple entity interactions. Experiments on two public benchmark datasets NELL-One and Wiki-One with 1-shot setting prove the effectiveness of TransAM.
Effects of Design and Hydrodynamic Parameters on Optimized Swimming for Simulated, Fish-inspired Robots
Nov 10, 2021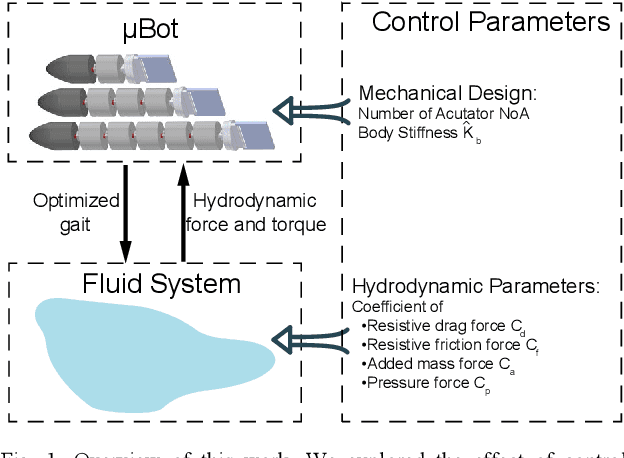
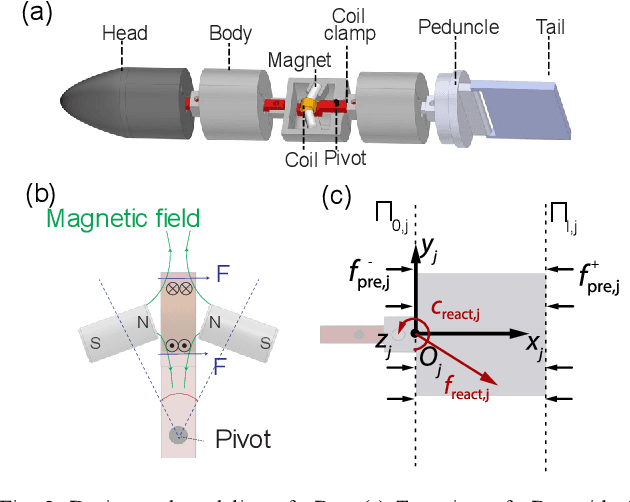
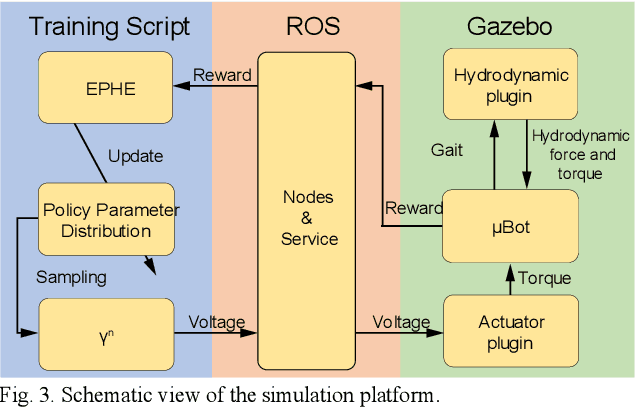

In this work we developed a mathematical model and a simulation platform for a fish-inspired robotic template, namely Magnetic, Modular, Undulatory Robotics ($\mu$Bots). Through this platform, we systematically explored the effects of design and fluid parameters on the swimming performance via reinforcement learning. The mathematical model was composed of two interacting subsystems, the robot dynamics and the hydrodynamics, and the hydrodynamic model consisted of reactive components (added-mass and pressure forces) and resistive components (drag and friction forces), which were then nondimensionalized for deriving key "control parameters" of robot-fluid interaction. The $\mu$Bot was actuated via magnetic actuators controlled with harmonic voltage signals, which were optimized via EM-based Policy Hyper Parameter Exploration (EPHE) to maximize swimming speed. By varying the control parameters, total 36 cases with different robot template variations (Number of Actuation (NoA) and stiffness) and hydrodynamic parameters were simulated and optimized via EPHE. Results showed that wavelength of optimized gaits (i.e., traveling wave along body) was independent of template variations and hydrodynamic parameters. Higher NoA yielded higher speed but lower speed per body length however with diminishing gain and lower speed per body length. Body and caudal-fin gait dynamics were dominated by the interaction among fluid added-mass, spring, and actuation torque, with negligible contribution from fluid resistive drag. In contrast, thrust generation was dominated by pressure force acting on caudal fin, as steady swimming resulted from a balance between resistive force and pressure force, with minor contributions from added-mass and body drag forces. Therefore, added-mass force only indirectly affected the thrust generation and swimming speed via the caudal fin dynamics.
Optimal Inverted Landing in a Small Aerial Robot with Varied Approach Velocities and Landing Gear Designs
Nov 05, 2021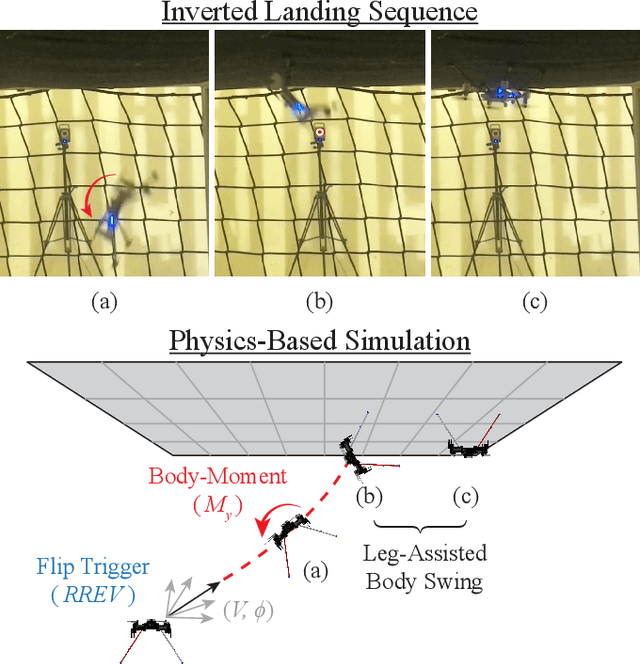
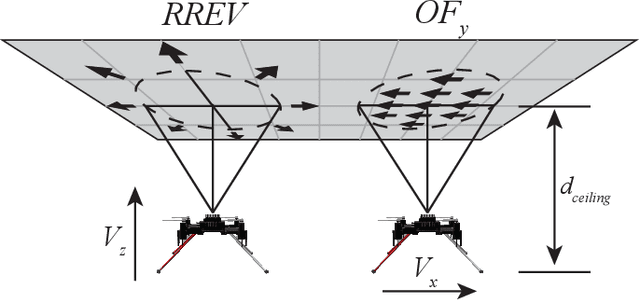
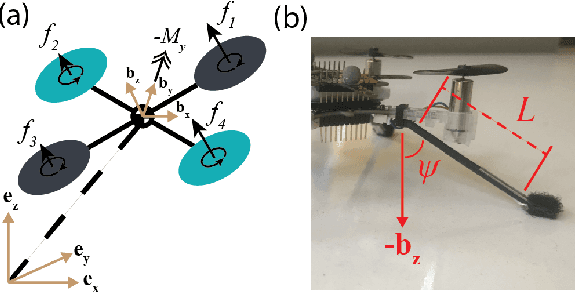
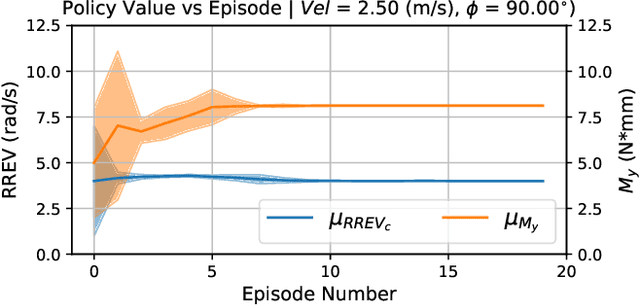
Inverted landing is a challenging feat to perform in aerial robots, especially without external positioning. However, it is routinely performed by biological fliers such as bees, flies, and bats. Our previous observations of landing behaviors in flies suggest an open-loop causal relationship between their putative visual cues and the kinematics of the aerial maneuvers executed. For example, the degree of rotational maneuver (therefore the body inversion prior to touchdown) and the amount of leg-assisted body swing both depend on the flies' initial body states while approaching the ceiling. In this work, by using a physics-based simulation with experimental validation, we systematically investigated how optimized inverted landing maneuvers depend on the initial approach velocities with varied magnitude and direction. This was done by analyzing the putative visual cues (that can be derived from onboard measurements) during optimal maneuvering trajectories. We identified a three-dimensional policy region, from which a mapping to a global inverted landing policy can be developed without the use of external positioning data. In addition, we also investigated the effects of an array of landing gear designs on the optimized landing performance and identified their advantages and disadvantages. The above results have been partially validated using limited experimental testing and will continue to inform and guide our future experiments, for example by applying the calculated global policy.