 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning of Multi-Domain Dialog Policies Via Action Embeddings
Jul 01, 2022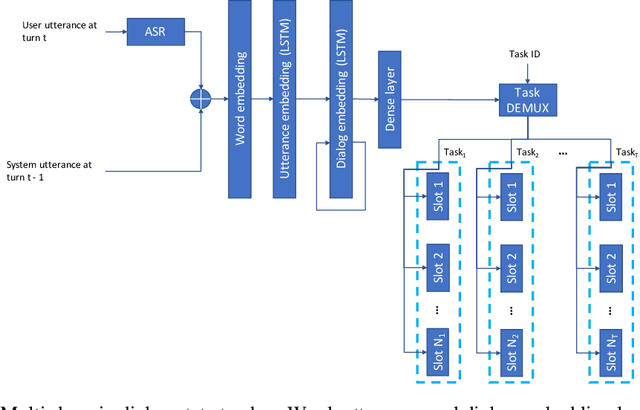
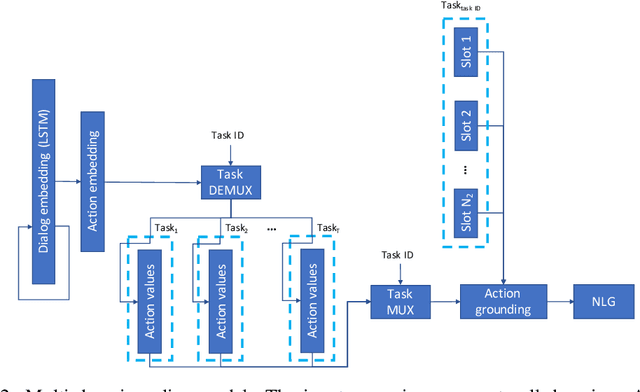
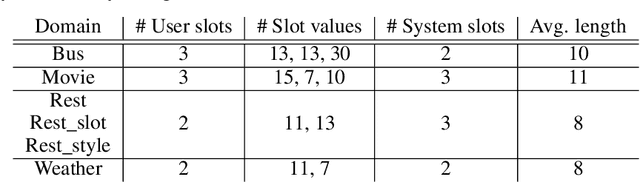
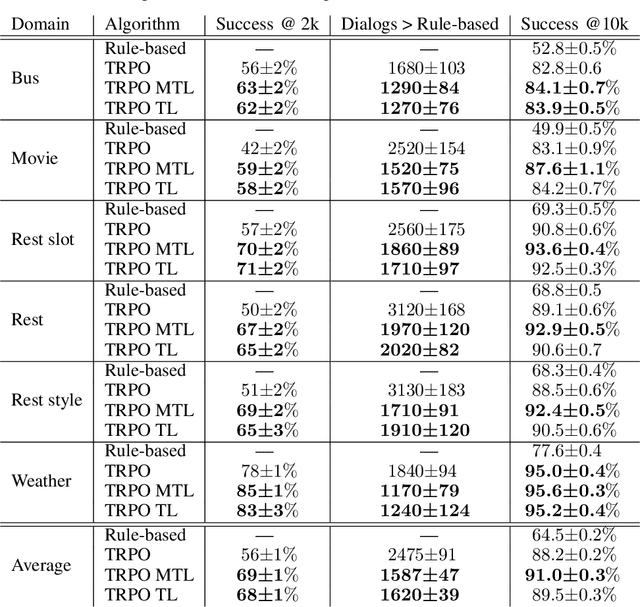
Learning task-oriented dialog policies via reinforcement learning typically requires large amounts of interaction with users, which in practice renders such methods unusable for real-world applications. In order to reduce the data requirements, we propose to leverage data from across different dialog domains, thereby reducing the amount of data required from each given domain. In particular, we propose to learn domain-agnostic action embeddings, which capture general-purpose structure that informs the system how to act given the current dialog context, and are then specialized to a specific domain. We show how this approach is capable of learning with significantly less interaction with users, with a reduction of 35% in the number of dialogs required to learn, and to a higher level of proficiency than training separate policies for each domain on a set of simulated domains.
TextDCT: Arbitrary-Shaped Text Detection via Discrete Cosine Transform Mask
Jun 27, 2022

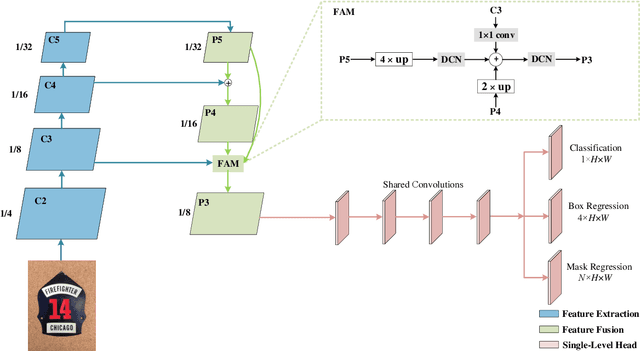
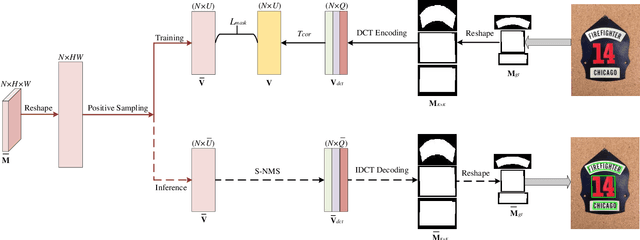
Arbitrary-shaped scene text detection is a challenging task due to the variety of text changes in font, size, color, and orientation. Most existing regression based methods resort to regress the masks or contour points of text regions to model the text instances. However, regressing the complete masks requires high training complexity, and contour points are not sufficient to capture the details of highly curved texts. To tackle the above limitations, we propose a novel light-weight anchor-free text detection framework called TextDCT, which adopts the discrete cosine transform (DCT) to encode the text masks as compact vectors. Further, considering the imbalanced number of training samples among pyramid layers, we only employ a single-level head for top-down prediction. To model the multi-scale texts in a single-level head, we introduce a novel positive sampling strategy by treating the shrunk text region as positive samples, and design a feature awareness module (FAM) for spatial-awareness and scale-awareness by fusing rich contextual information and focusing on more significant features. Moreover, we propose a segmented non-maximum suppression (S-NMS) method that can filter low-quality mask regressions. Extensive experiments are conducted on four challenging datasets, which demonstrate our TextDCT obtains competitive performance on both accuracy and efficiency. Specifically, TextDCT achieves F-measure of 85.1 at 17.2 frames per second (FPS) and F-measure of 84.9 at 15.1 FPS for CTW1500 and Total-Text datasets, respectively.
Beyond Opinion Mining: Summarizing Opinions of Customer Reviews
Jun 03, 2022
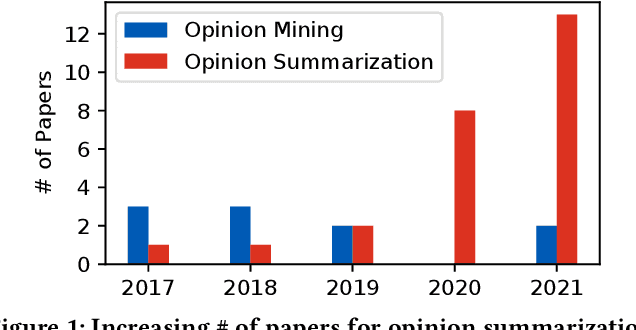
Customer reviews are vital for making purchasing decisions in the Information Age. Such reviews can be automatically summarized to provide the user with an overview of opinions. In this tutorial, we present various aspects of opinion summarization that are useful for researchers and practitioners. First, we will introduce the task and major challenges. Then, we will present existing opinion summarization solutions, both pre-neural and neural. We will discuss how summarizers can be trained in the unsupervised, few-shot, and supervised regimes. Each regime has roots in different machine learning methods, such as auto-encoding, controllable text generation, and variational inference. Finally, we will discuss resources and evaluation methods and conclude with the future directions. This three-hour tutorial will provide a comprehensive overview over major advances in opinion summarization. The listeners will be well-equipped with the knowledge that is both useful for research and practical applications.
KETOD: Knowledge-Enriched Task-Oriented Dialogue
May 11, 2022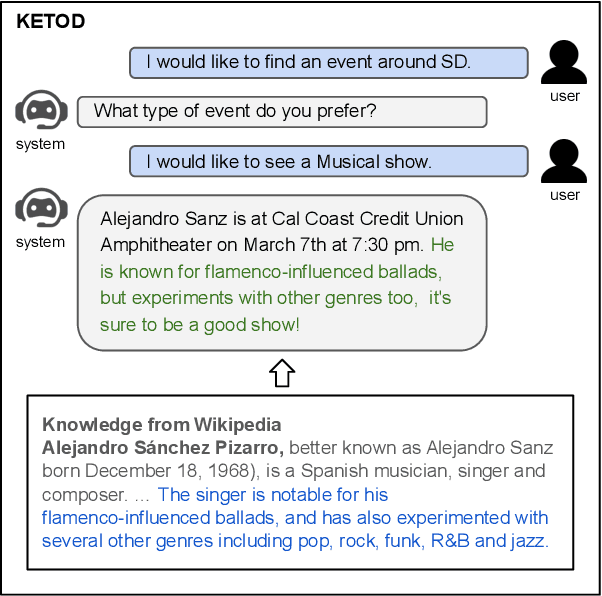

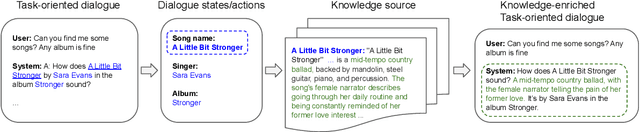
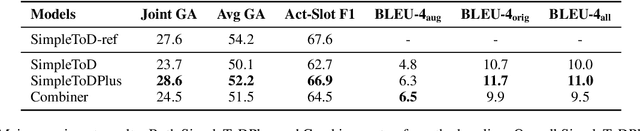
Existing studies in dialogue system research mostly treat task-oriented dialogue and chit-chat as separate domains. Towards building a human-like assistant that can converse naturally and seamlessly with users, it is important to build a dialogue system that conducts both types of conversations effectively. In this work, we investigate how task-oriented dialogue and knowledge-grounded chit-chat can be effectively integrated into a single model. To this end, we create a new dataset, KETOD (Knowledge-Enriched Task-Oriented Dialogue), where we naturally enrich task-oriented dialogues with chit-chat based on relevant entity knowledge. We also propose two new models, SimpleToDPlus and Combiner, for the proposed task. Experimental results on both automatic and human evaluations show that the proposed methods can significantly improve the performance in knowledge-enriched response generation while maintaining a competitive task-oriented dialog performance. We believe our new dataset will be a valuable resource for future studies. Our dataset and code are publicly available at \url{https://github.com/facebookresearch/ketod}.
Open-set Recognition via Augmentation-based Similarity Learning
Mar 24, 2022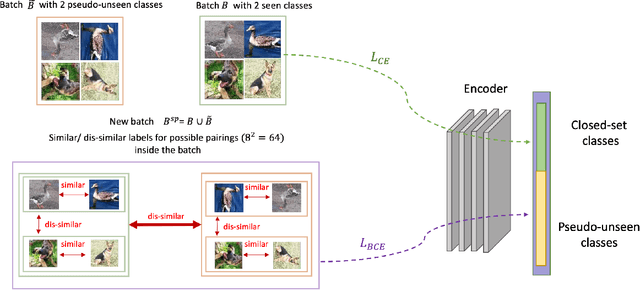
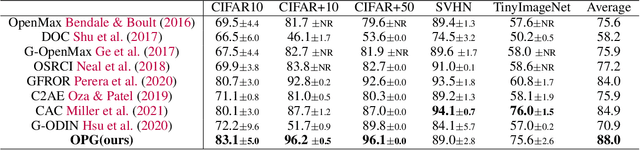
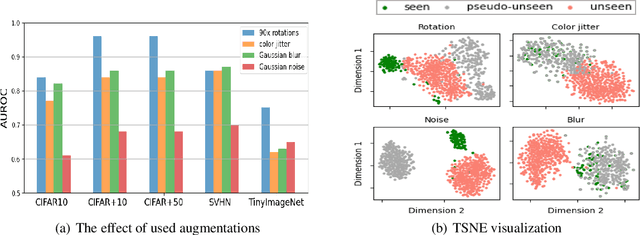
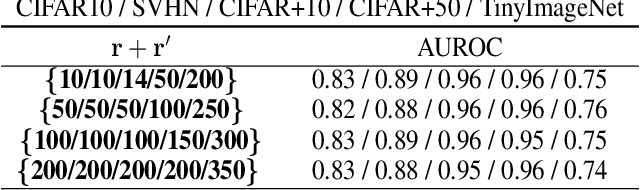
The primary assumption of conventional supervised learning or classification is that the test samples are drawn from the same distribution as the training samples, which is called closed set learning or classification. In many practical scenarios, this is not the case because there are unknowns or unseen class samples in the test data, which is called the open set scenario, and the unknowns need to be detected. This problem is referred to as the open set recognition problem and is important in safety-critical applications. We propose to detect unknowns (or unseen class samples) through learning pairwise similarities. The proposed method works in two steps. It first learns a closed set classifier using the seen classes that have appeared in training and then learns how to compare seen classes with pseudo-unseen (automatically generated unseen class samples). The pseudo-unseen generation is carried out by performing distribution shifting augmentations on the seen or training samples. We call our method OPG (Open set recognition based on Pseudo unseen data Generation). The experimental evaluation shows that the learned similarity-based features can successfully distinguish seen from unseen in benchmark datasets for open set recognition.
AI Autonomy: Self-Initiation, Adaptation and Continual Learning
Mar 19, 2022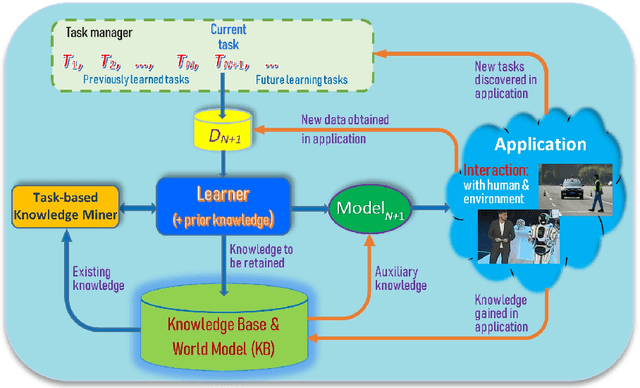
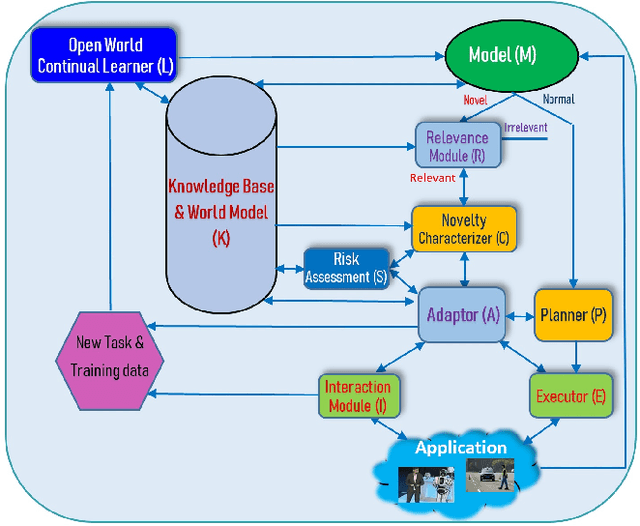
As more and more AI agents are used in practice, it is time to think about how to make these agents fully autonomous so that they can (1) learn by themselves continually in a self-motivated and self-initiated manner rather than being retrained offline periodically on the initiation of human engineers and (2) accommodate or adapt to unexpected or novel circumstances. As the real-world is an open environment that is full of unknowns or novelties, detecting novelties, characterizing them, accommodating or adapting to them, and gathering ground-truth training data and incrementally learning the unknowns/novelties are critical to making the AI agent more and more knowledgeable and powerful over time. The key challenge is how to automate the process so that it is carried out continually on the agent's own initiative and through its own interactions with humans, other agents and the environment just like human on-the-job learning. This paper proposes a framework (called SOLA) for this learning paradigm to promote the research of building autonomous and continual learning enabled AI agents. To show feasibility, an implemented agent is also described.
Continual Learning Based on OOD Detection and Task Masking
Mar 17, 2022



Existing continual learning techniques focus on either task incremental learning (TIL) or class incremental learning (CIL) problem, but not both. CIL and TIL differ mainly in that the task-id is provided for each test sample during testing for TIL, but not provided for CIL. Continual learning methods intended for one problem have limitations on the other problem. This paper proposes a novel unified approach based on out-of-distribution (OOD) detection and task masking, called CLOM, to solve both problems. The key novelty is that each task is trained as an OOD detection model rather than a traditional supervised learning model, and a task mask is trained to protect each task to prevent forgetting. Our evaluation shows that CLOM outperforms existing state-of-the-art baselines by large margins. The average TIL/CIL accuracy of CLOM over six experiments is 87.6/67.9% while that of the best baselines is only 82.4/55.0%.
Ensemble Semi-supervised Entity Alignment via Cycle-teaching
Mar 12, 2022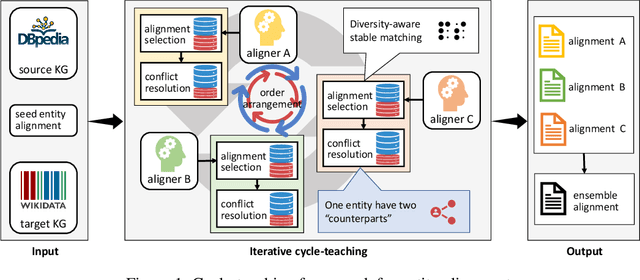
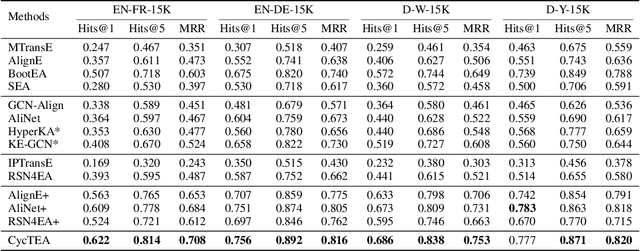
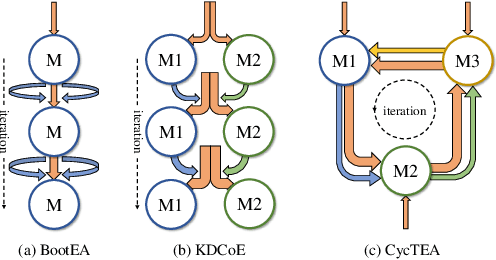
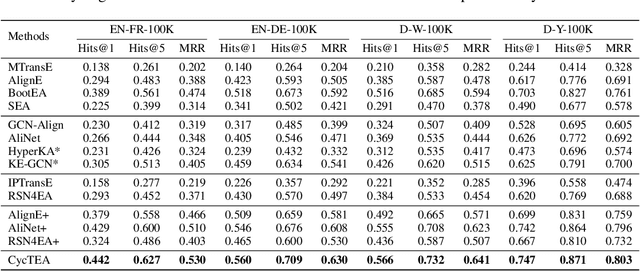
Entity alignment is to find identical entities in different knowledge graphs. Although embedding-based entity alignment has recently achieved remarkable progress, training data insufficiency remains a critical challenge. Conventional semi-supervised methods also suffer from the incorrect entity alignment in newly proposed training data. To resolve these issues, we design an iterative cycle-teaching framework for semi-supervised entity alignment. The key idea is to train multiple entity alignment models (called aligners) simultaneously and let each aligner iteratively teach its successor the proposed new entity alignment. We propose a diversity-aware alignment selection method to choose reliable entity alignment for each aligner. We also design a conflict resolution mechanism to resolve the alignment conflict when combining the new alignment of an aligner and that from its teacher. Besides, considering the influence of cycle-teaching order, we elaborately design a strategy to arrange the optimal order that can maximize the overall performance of multiple aligners. The cycle-teaching process can break the limitations of each model's learning capability and reduce the noise in new training data, leading to improved performance. Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed cycle-teaching framework, which significantly outperforms the state-of-the-art models when the training data is insufficient and the new entity alignment has much noise.
Zero-Shot Aspect-Based Sentiment Analysis
Feb 15, 2022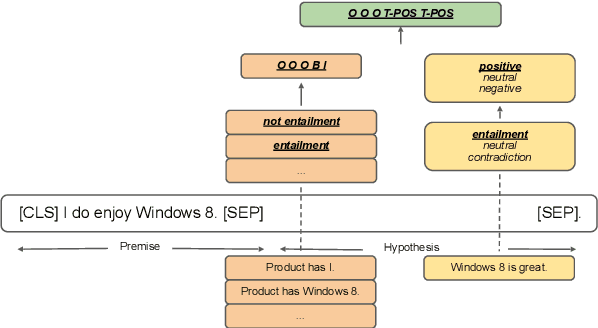


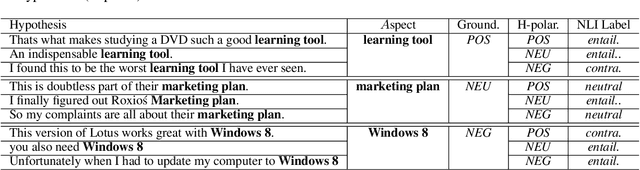
Aspect-based sentiment analysis (ABSA) typically requires in-domain annotated data for supervised training/fine-tuning. It is a big challenge to scale ABSA to a large number of new domains. This paper aims to train a unified model that can perform zero-shot ABSA without using any annotated data for a new domain. We propose a method called contrastive post-training on review Natural Language Inference (CORN). Later ABSA tasks can be cast into NLI for zero-shot transfer. We evaluate CORN on ABSA tasks, ranging from aspect extraction (AE), aspect sentiment classification (ASC), to end-to-end aspect-based sentiment analysis (E2E ABSA), which show ABSA can be conducted without any human annotated ABSA data.
Continual Learning with Knowledge Transfer for Sentiment Classification
Dec 18, 2021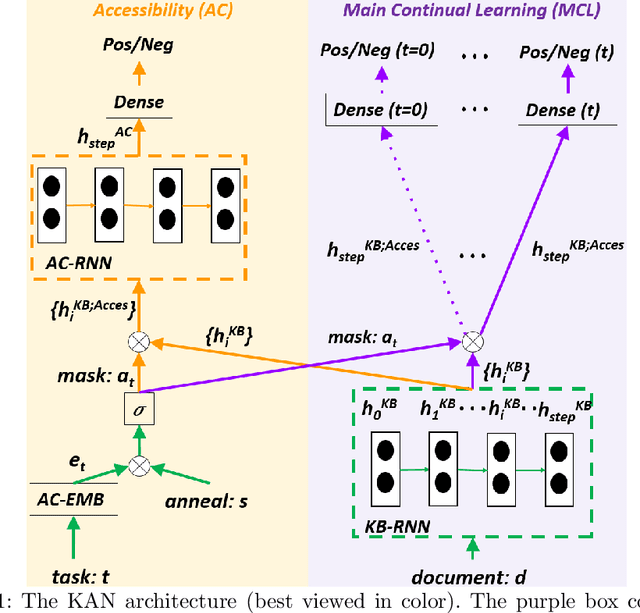
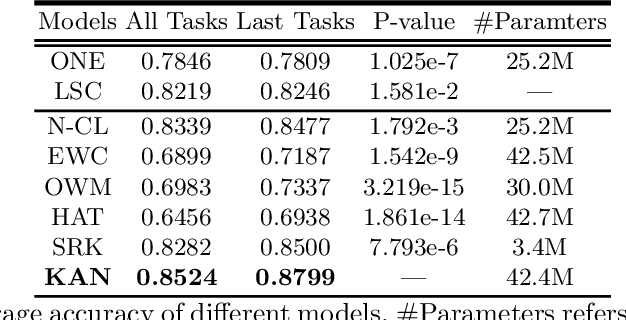
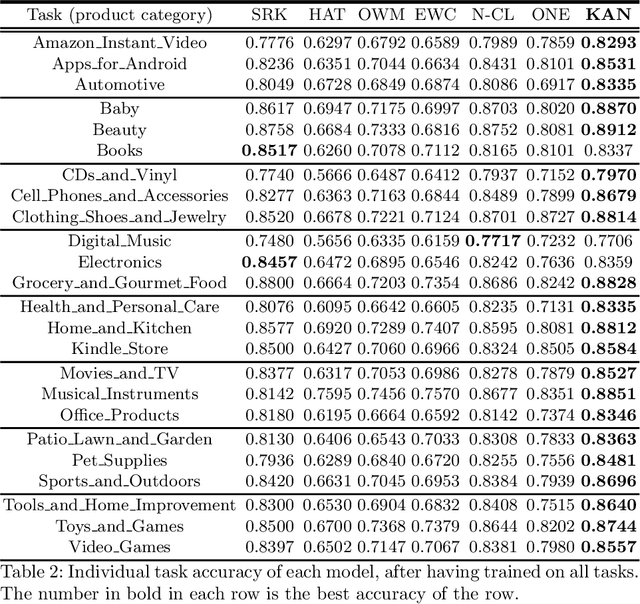
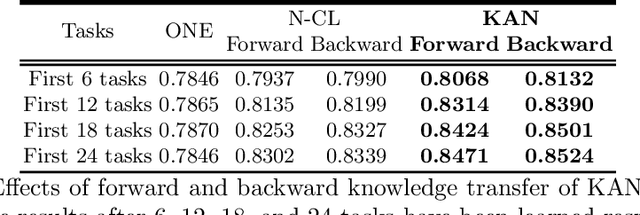
This paper studies continual learning (CL) for sentiment classification (SC). In this setting, the CL system learns a sequence of SC tasks incrementally in a neural network, where each task builds a classifier to classify the sentiment of reviews of a particular product category or domain. Two natural questions are: Can the system transfer the knowledge learned in the past from the previous tasks to the new task to help it learn a better model for the new task? And, can old models for previous tasks be improved in the process as well? This paper proposes a novel technique called KAN to achieve these objectives. KAN can markedly improve the SC accuracy of both the new task and the old tasks via forward and backward knowledge transfer. The effectiveness of KAN is demonstrated through extensive experiments.