 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCauTraj: A Causal-Knowledge-Guided Framework for Lane-Changing Trajectory Planning of Autonomous Vehicles
Dec 21, 2025



Enhancing the performance of trajectory planners for lane - changing vehicles is one of the key challenges in autonomous driving within human - machine mixed traffic. Most existing studies have not incorporated human drivers' prior knowledge when designing trajectory planning models. To address this issue, this study proposes a novel trajectory planning framework that integrates causal prior knowledge into the control process. Both longitudinal and lateral microscopic behaviors of vehicles are modeled to quantify interaction risk, and a staged causal graph is constructed to capture causal dependencies in lane-changing scenarios. Causal effects between the lane-changing vehicle and surrounding vehicles are then estimated using causal inference, including average causal effects (ATE) and conditional average treatment effects (CATE). These causal priors are embedded into a model predictive control (MPC) framework to enhance trajectory planning. The proposed approach is validated on naturalistic vehicle trajectory datasets. Experimental results show that: (1) causal inference provides interpretable and stable quantification of vehicle interactions; (2) individual causal effects reveal driver heterogeneity; and (3) compared with the baseline MPC, the proposed method achieves a closer alignment with human driving behaviors, reducing maximum trajectory deviation from 1.2 m to 0.2 m, lateral velocity fluctuation by 60%, and yaw angle variability by 50%. These findings provide methodological support for human-like trajectory planning and practical value for improving safety, stability, and realism in autonomous vehicle testing and traffic simulation platforms.
An Automated Reinforcement Learning Reward Design Framework with Large Language Model for Cooperative Platoon Coordination
Apr 28, 2025



Reinforcement Learning (RL) has demonstrated excellent decision-making potential in platoon coordination problems. However, due to the variability of coordination goals, the complexity of the decision problem, and the time-consumption of trial-and-error in manual design, finding a well performance reward function to guide RL training to solve complex platoon coordination problems remains challenging. In this paper, we formally define the Platoon Coordination Reward Design Problem (PCRDP), extending the RL-based cooperative platoon coordination problem to incorporate automated reward function generation. To address PCRDP, we propose a Large Language Model (LLM)-based Platoon coordination Reward Design (PCRD) framework, which systematically automates reward function discovery through LLM-driven initialization and iterative optimization. In this method, LLM first initializes reward functions based on environment code and task requirements with an Analysis and Initial Reward (AIR) module, and then iteratively optimizes them based on training feedback with an evolutionary module. The AIR module guides LLM to deepen their understanding of code and tasks through a chain of thought, effectively mitigating hallucination risks in code generation. The evolutionary module fine-tunes and reconstructs the reward function, achieving a balance between exploration diversity and convergence stability for training. To validate our approach, we establish six challenging coordination scenarios with varying complexity levels within the Yangtze River Delta transportation network simulation. Comparative experimental results demonstrate that RL agents utilizing PCRD-generated reward functions consistently outperform human-engineered reward functions, achieving an average of 10\% higher performance metrics in all scenarios.
STGAN: Spatial-temporal Graph Autoregression Network for Pavement Distress Deterioration Prediction
Mar 03, 2025Pavement distress significantly compromises road integrity and poses risks to drivers. Accurate prediction of pavement distress deterioration is essential for effective road management, cost reduction in maintenance, and improvement of traffic safety. However, real-world data on pavement distress is usually collected irregularly, resulting in uneven, asynchronous, and sparse spatial-temporal datasets. This hinders the application of existing spatial-temporal models, such as DCRNN, since they are only applicable to regularly and synchronously collected data. To overcome these challenges, we propose the Spatial-Temporal Graph Autoregression Network (STGAN), a novel graph neural network model designed for accurately predicting irregular pavement distress deterioration using complex spatial-temporal data. Specifically, STGAN integrates the temporal domain into the spatial domain, creating a larger graph where nodes are represented by spatial-temporal tuples and edges are formed based on a similarity-based connection mechanism. Furthermore, based on the constructed spatiotemporal graph, we formulate pavement distress deterioration prediction as a graph autoregression task, i.e., the graph size increases incrementally and the prediction is performed sequentially. This is accomplished by a novel spatial-temporal attention mechanism deployed by STGAN. Utilizing the ConTrack dataset, which contains pavement distress records collected from different locations in Shanghai, we demonstrate the superior performance of STGAN in capturing spatial-temporal correlations and addressing the aforementioned challenges. Experimental results further show that STGAN outperforms baseline models, and ablation studies confirm the effectiveness of its novel modules. Our findings contribute to promoting proactive road maintenance decision-making and ultimately enhancing road safety and resilience.
Human-Vehicle Cooperative Visual Perception for Shared Autonomous Driving
Dec 17, 2021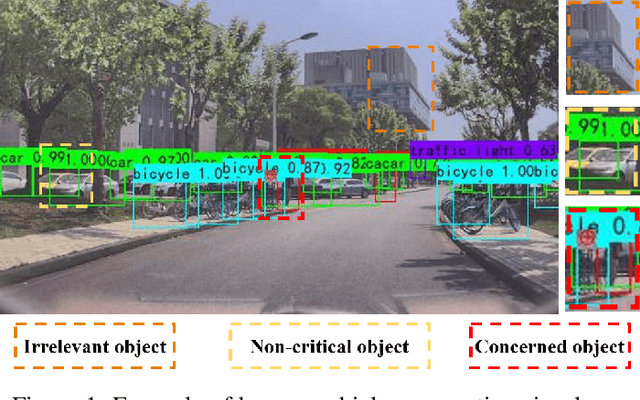
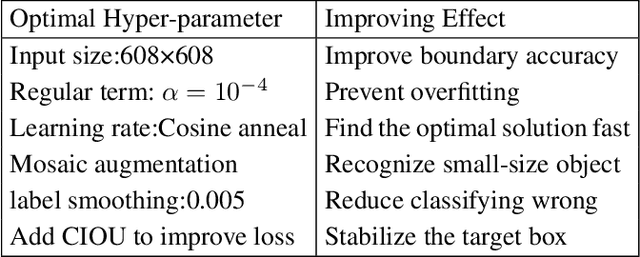
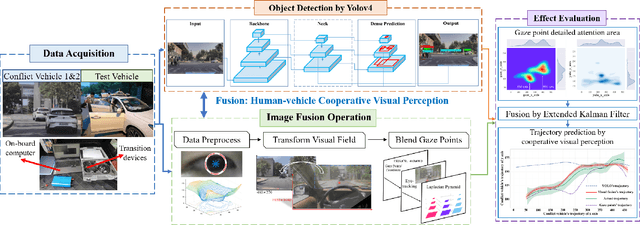

With the development of key technologies like environment perception, the automation level of autonomous vehicles has been increasing. However, before reaching highly autonomous driving, manual driving still needs to participate in the driving process to ensure the safety of human-vehicle shared driving. The existing human-vehicle cooperative driving focuses on auto engineering and drivers' behaviors, with few research studies in the field of visual perception. Due to the bad performance in the complex road traffic conflict scenarios, cooperative visual perception needs to be studied further. In addition, the autonomous driving perception system cannot correctly understand the characteristics of manual driving. Based on the background above, this paper directly proposes a human-vehicle cooperative visual perception method to enhance the visual perception ability of shared autonomous driving based on the transfer learning method and the image fusion algorithm for the complex road traffic scenarios. Based on transfer learning, the mAP of object detection reaches 75.52% and lays a solid foundation for visual fusion. And the fusion experiment further reveals that human-vehicle cooperative visual perception reflects the riskiest zone and predicts the conflict object's trajectory more precisely. This study pioneers a cooperative visual perception solution for shared autonomous driving and experiments in real-world complex traffic conflict scenarios, which can better support the following planning and controlling and improve the safety of autonomous vehicles.
A Deep Reinforcement Learning Approach for Ramp Metering Based on Traffic Video Data
Dec 09, 2020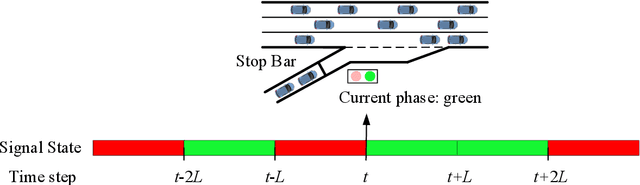

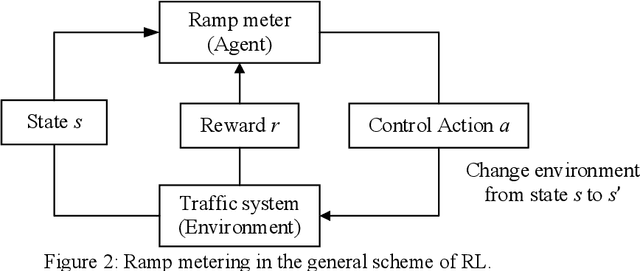
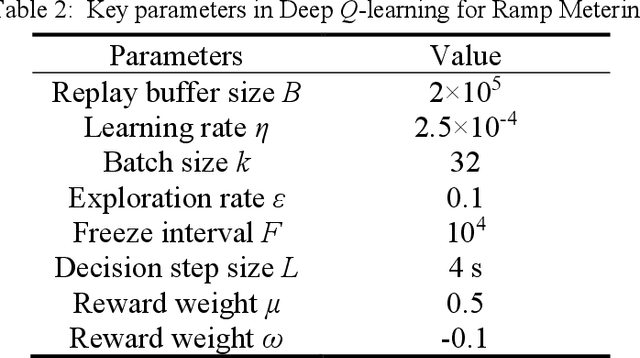
Ramp metering that uses traffic signals to regulate vehicle flows from the on-ramps has been widely implemented to improve vehicle mobility of the freeway. Previous studies generally update signal timings in real-time based on predefined traffic measures collected by point detectors, such as traffic volumes and occupancies. Comparing with point detectors, traffic cameras-which have been increasingly deployed on road networks-could cover larger areas and provide more detailed traffic information. In this work, we propose a deep reinforcement learning (DRL) method to explore the potential of traffic video data in improving the efficiency of ramp metering. The proposed method uses traffic video frames as inputs and learns the optimal control strategies directly from the high-dimensional visual inputs. A real-world case study demonstrates that, in comparison with a state-of-the-practice method, the proposed DRL method results in 1) lower travel times in the mainline, 2) shorter vehicle queues at the on-ramp, and 3) higher traffic flows downstream of the merging area. The results suggest that the proposed method is able to extract useful information from the video data for better ramp metering controls.