 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast and Convergent Proximal Algorithm for Regularized Nonconvex and Nonsmooth Bi-level Optimization
Mar 30, 2022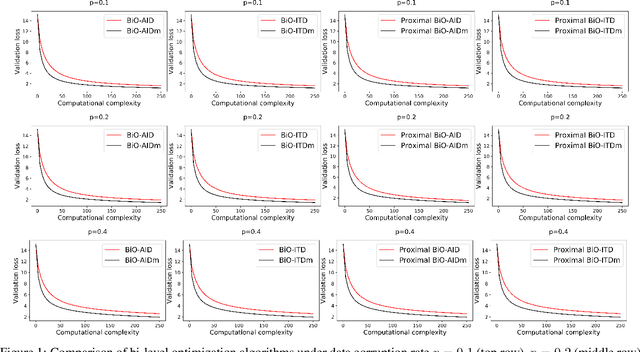
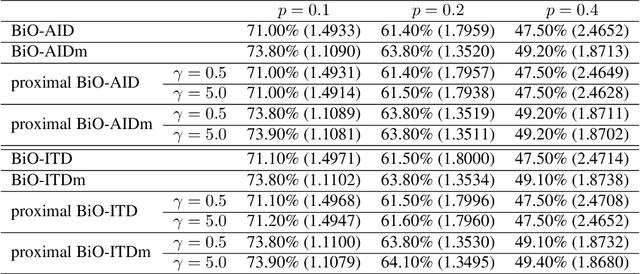
Many important machine learning applications involve regularized nonconvex bi-level optimization. However, the existing gradient-based bi-level optimization algorithms cannot handle nonconvex or nonsmooth regularizers, and they suffer from a high computation complexity in nonconvex bi-level optimization. In this work, we study a proximal gradient-type algorithm that adopts the approximate implicit differentiation (AID) scheme for nonconvex bi-level optimization with possibly nonconvex and nonsmooth regularizers. In particular, the algorithm applies the Nesterov's momentum to accelerate the computation of the implicit gradient involved in AID. We provide a comprehensive analysis of the global convergence properties of this algorithm through identifying its intrinsic potential function. In particular, we formally establish the convergence of the model parameters to a critical point of the bi-level problem, and obtain an improved computation complexity $\mathcal{O}(\kappa^{3.5}\epsilon^{-2})$ over the state-of-the-art result. Moreover, we analyze the asymptotic convergence rates of this algorithm under a class of local nonconvex geometries characterized by a {\L}ojasiewicz-type gradient inequality. Experiment on hyper-parameter optimization demonstrates the effectiveness of our algorithm.
Benchmarking Test-Time Unsupervised Deep Neural Network Adaptation on Edge Devices
Mar 21, 2022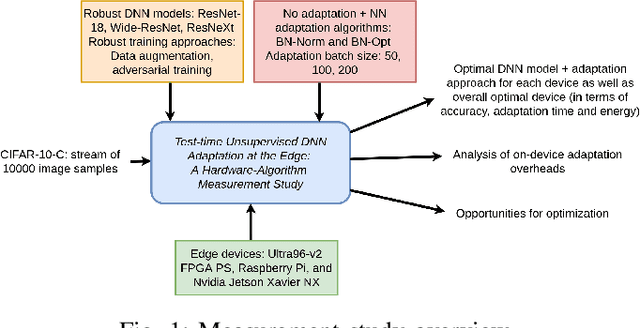
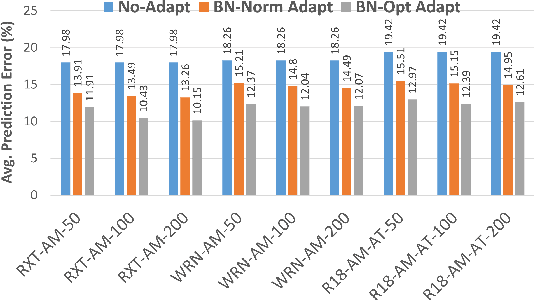
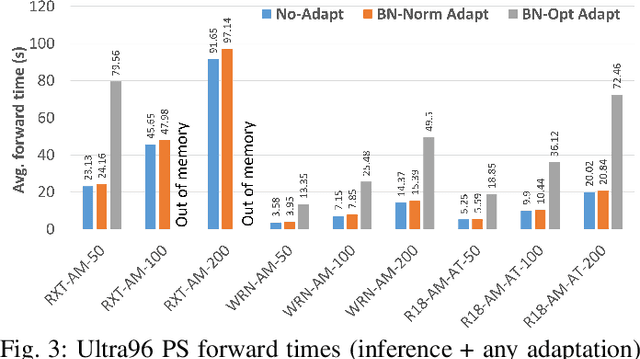
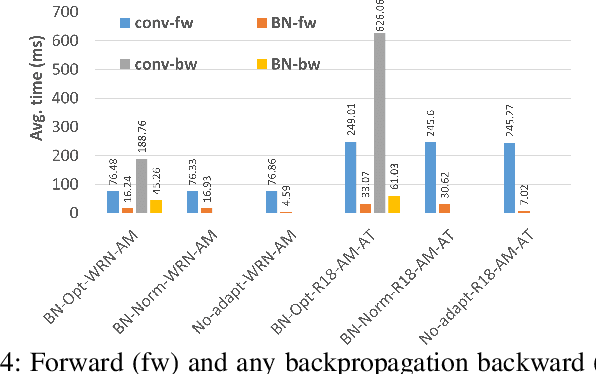
The prediction accuracy of the deep neural networks (DNNs) after deployment at the edge can suffer with time due to shifts in the distribution of the new data. To improve robustness of DNNs, they must be able to update themselves to enhance their prediction accuracy. This adaptation at the resource-constrained edge is challenging as: (i) new labeled data may not be present; (ii) adaptation needs to be on device as connections to cloud may not be available; and (iii) the process must not only be fast but also memory- and energy-efficient. Recently, lightweight prediction-time unsupervised DNN adaptation techniques have been introduced that improve prediction accuracy of the models for noisy data by re-tuning the batch normalization (BN) parameters. This paper, for the first time, performs a comprehensive measurement study of such techniques to quantify their performance and energy on various edge devices as well as find bottlenecks and propose optimization opportunities. In particular, this study considers CIFAR-10-C image classification dataset with corruptions, three robust DNNs (ResNeXt, Wide-ResNet, ResNet-18), two BN adaptation algorithms (one that updates normalization statistics and the other that also optimizes transformation parameters), and three edge devices (FPGA, Raspberry-Pi, and Nvidia Xavier NX). We find that the approach that only updates the normalization parameters with Wide-ResNet, running on Xavier GPU, to be overall effective in terms of balancing multiple cost metrics. However, the adaptation overhead can still be significant (around 213 ms). The results strongly motivate the need for algorithm-hardware co-design for efficient on-device DNN adaptation.
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
Mar 16, 2022
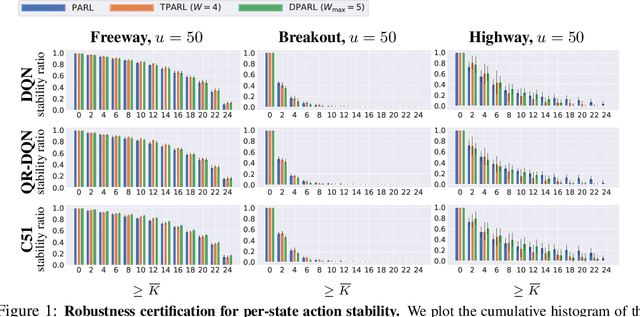
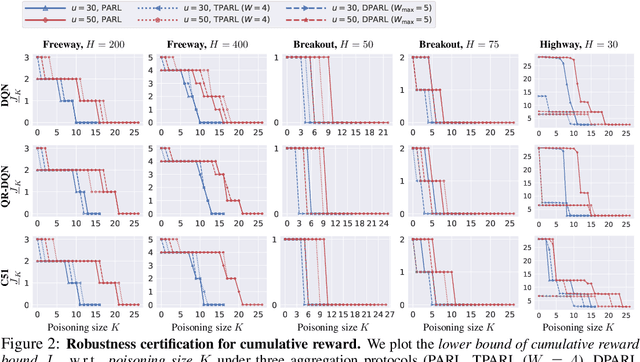
As reinforcement learning (RL) has achieved near human-level performance in a variety of tasks, its robustness has raised great attention. While a vast body of research has explored test-time (evasion) attacks in RL and corresponding defenses, its robustness against training-time (poisoning) attacks remains largely unanswered. In this work, we focus on certifying the robustness of offline RL in the presence of poisoning attacks, where a subset of training trajectories could be arbitrarily manipulated. We propose the first certification framework, COPA, to certify the number of poisoning trajectories that can be tolerated regarding different certification criteria. Given the complex structure of RL, we propose two certification criteria: per-state action stability and cumulative reward bound. To further improve the certification, we propose new partition and aggregation protocols to train robust policies. We further prove that some of the proposed certification methods are theoretically tight and some are NP-Complete problems. We leverage COPA to certify three RL environments trained with different algorithms and conclude: (1) The proposed robust aggregation protocols such as temporal aggregation can significantly improve the certifications; (2) Our certification for both per-state action stability and cumulative reward bound are efficient and tight; (3) The certification for different training algorithms and environments are different, implying their intrinsic robustness properties. All experimental results are available at https://copa-leaderboard.github.io.
Benchmarking Robustness of 3D Point Cloud Recognition Against Common Corruptions
Jan 28, 2022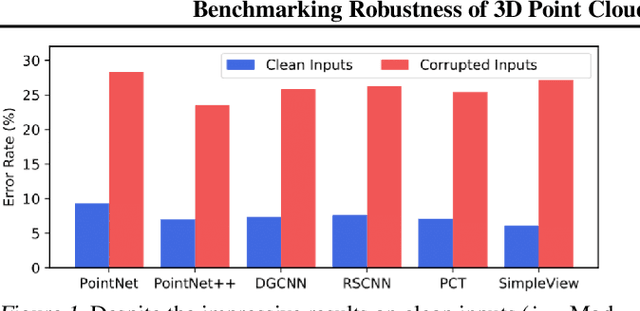
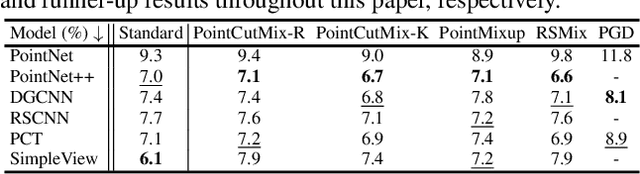
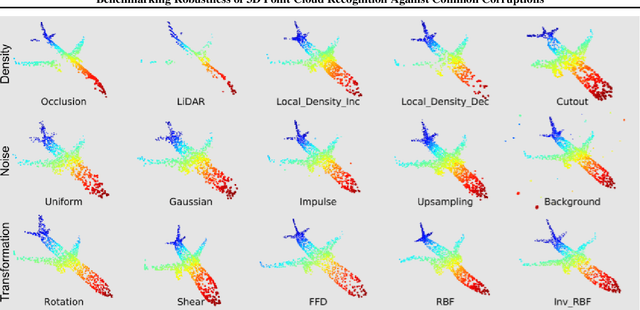

Deep neural networks on 3D point cloud data have been widely used in the real world, especially in safety-critical applications. However, their robustness against corruptions is less studied. In this paper, we present ModelNet40-C, the first comprehensive benchmark on 3D point cloud corruption robustness, consisting of 15 common and realistic corruptions. Our evaluation shows a significant gap between the performances on ModelNet40 and ModelNet40-C for state-of-the-art (SOTA) models. To reduce the gap, we propose a simple but effective method by combining PointCutMix-R and TENT after evaluating a wide range of augmentation and test-time adaptation strategies. We identify a number of critical insights for future studies on corruption robustness in point cloud recognition. For instance, we unveil that Transformer-based architectures with proper training recipes achieve the strongest robustness. We hope our in-depth analysis will motivate the development of robust training strategies or architecture designs in the 3D point cloud domain. Our codebase and dataset are included in https://github.com/jiachens/ModelNet40-C
Certified Adversarial Defenses Meet Out-of-Distribution Corruptions: Benchmarking Robustness and Simple Baselines
Dec 01, 2021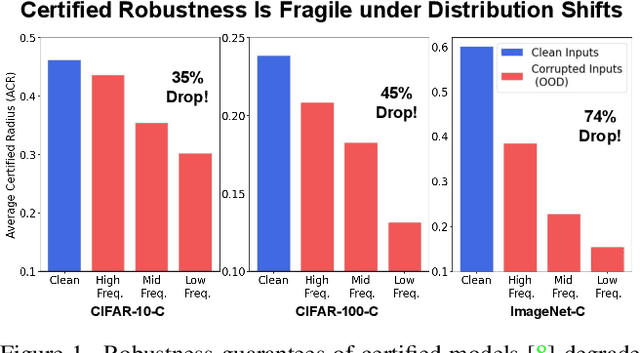
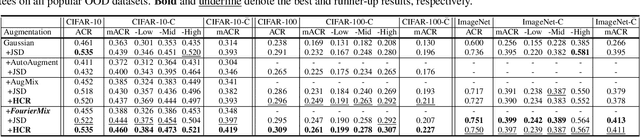
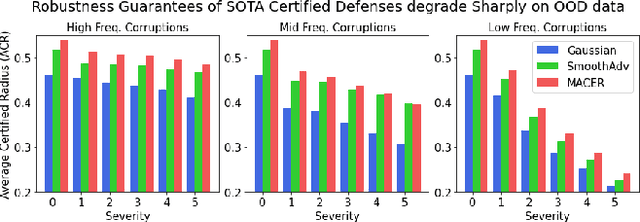
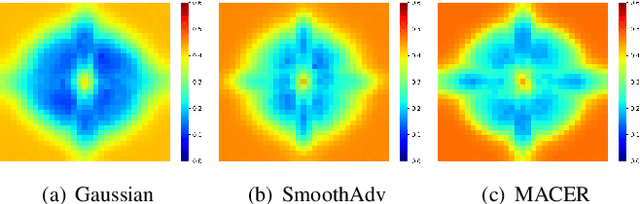
Certified robustness guarantee gauges a model's robustness to test-time attacks and can assess the model's readiness for deployment in the real world. In this work, we critically examine how the adversarial robustness guarantees from randomized smoothing-based certification methods change when state-of-the-art certifiably robust models encounter out-of-distribution (OOD) data. Our analysis demonstrates a previously unknown vulnerability of these models to low-frequency OOD data such as weather-related corruptions, rendering these models unfit for deployment in the wild. To alleviate this issue, we propose a novel data augmentation scheme, FourierMix, that produces augmentations to improve the spectral coverage of the training data. Furthermore, we propose a new regularizer that encourages consistent predictions on noise perturbations of the augmented data to improve the quality of the smoothed models. We find that FourierMix augmentations help eliminate the spectral bias of certifiably robust models enabling them to achieve significantly better robustness guarantees on a range of OOD benchmarks. Our evaluation also uncovers the inability of current OOD benchmarks at highlighting the spectral biases of the models. To this end, we propose a comprehensive benchmarking suite that contains corruptions from different regions in the spectral domain. Evaluation of models trained with popular augmentation methods on the proposed suite highlights their spectral biases and establishes the superiority of FourierMix trained models at achieving better-certified robustness guarantees under OOD shifts over the entire frequency spectrum.
On the Certified Robustness for Ensemble Models and Beyond
Jul 22, 2021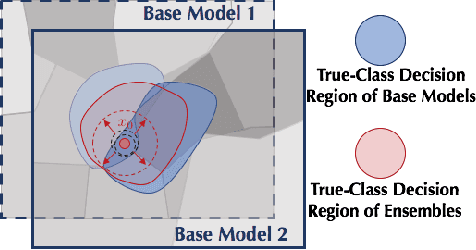
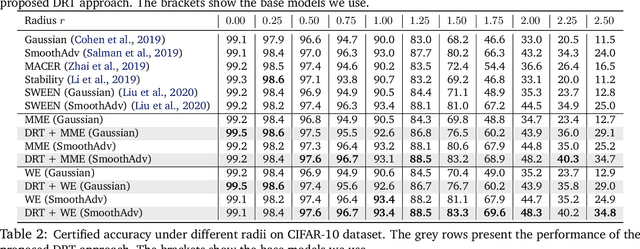
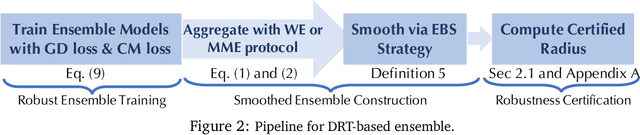
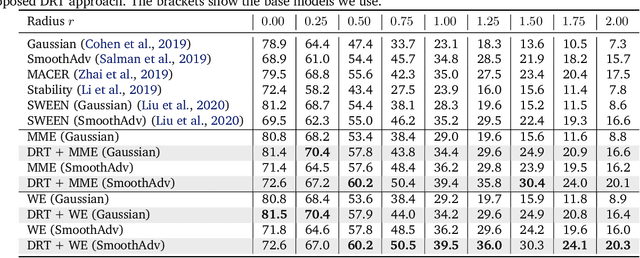
Recent studies show that deep neural networks (DNN) are vulnerable to adversarial examples, which aim to mislead DNNs by adding perturbations with small magnitude. To defend against such attacks, both empirical and theoretical defense approaches have been extensively studied for a single ML model. In this work, we aim to analyze and provide the certified robustness for ensemble ML models, together with the sufficient and necessary conditions of robustness for different ensemble protocols. Although ensemble models are shown more robust than a single model empirically; surprisingly, we find that in terms of the certified robustness the standard ensemble models only achieve marginal improvement compared to a single model. Thus, to explore the conditions that guarantee to provide certifiably robust ensemble ML models, we first prove that diversified gradient and large confidence margin are sufficient and necessary conditions for certifiably robust ensemble models under the model-smoothness assumption. We then provide the bounded model-smoothness analysis based on the proposed Ensemble-before-Smoothing strategy. We also prove that an ensemble model can always achieve higher certified robustness than a single base model under mild conditions. Inspired by the theoretical findings, we propose the lightweight Diversity Regularized Training (DRT) to train certifiably robust ensemble ML models. Extensive experiments show that our DRT enhanced ensembles can consistently achieve higher certified robustness than existing single and ensemble ML models, demonstrating the state-of-the-art certified L2-robustness on MNIST, CIFAR-10, and ImageNet datasets.
Understanding the Limits of Unsupervised Domain Adaptation via Data Poisoning
Jul 08, 2021
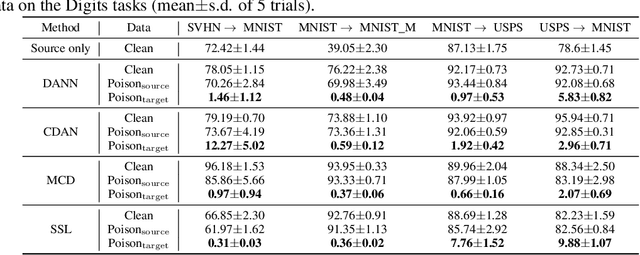
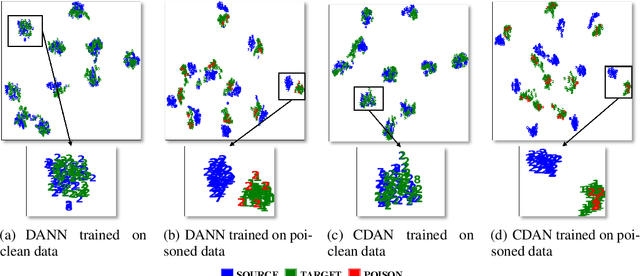
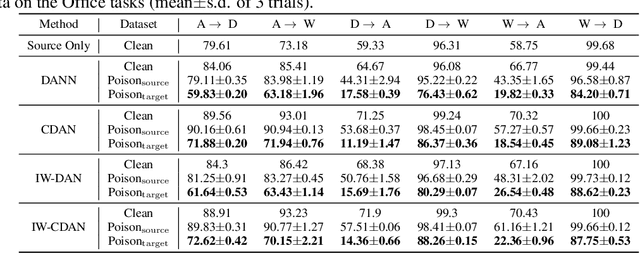
Unsupervised domain adaptation (UDA) enables cross-domain learning without target domain labels by transferring knowledge from a labeled source domain whose distribution differs from the target. However, UDA is not always successful and several accounts of "negative transfer" have been reported in the literature. In this work, we prove a simple lower bound on the target domain error that complements the existing upper bound. Our bound shows the insufficiency of minimizing source domain error and marginal distribution mismatch for a guaranteed reduction in the target domain error, due to the possible increase of induced labeling function mismatch. This insufficiency is further illustrated through simple distributions for which the same UDA approach succeeds, fails, and may succeed or fail with an equal chance. Motivated from this, we propose novel data poisoning attacks to fool UDA methods into learning representations that produce large target domain errors. We evaluate the effect of these attacks on popular UDA methods using benchmark datasets where they have been previously shown to be successful. Our results show that poisoning can significantly decrease the target domain accuracy, dropping it to almost 0\% in some cases, with the addition of only 10\% poisoned data in the source domain. The failure of UDA methods demonstrates the limitations of UDA at guaranteeing cross-domain generalization consistent with the lower bound. Thus, evaluation of UDA methods in adversarial settings such as data poisoning can provide a better sense of their robustness in scenarios unfavorable for UDA.
Reliable Graph Neural Network Explanations Through Adversarial Training
Jun 25, 2021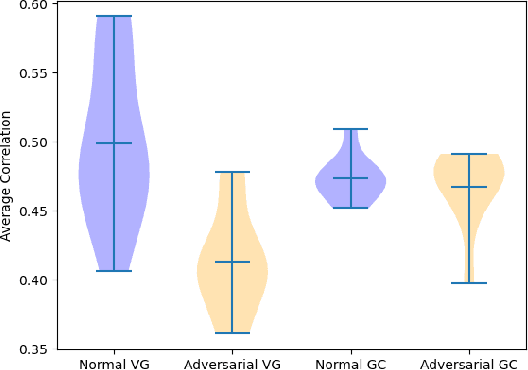
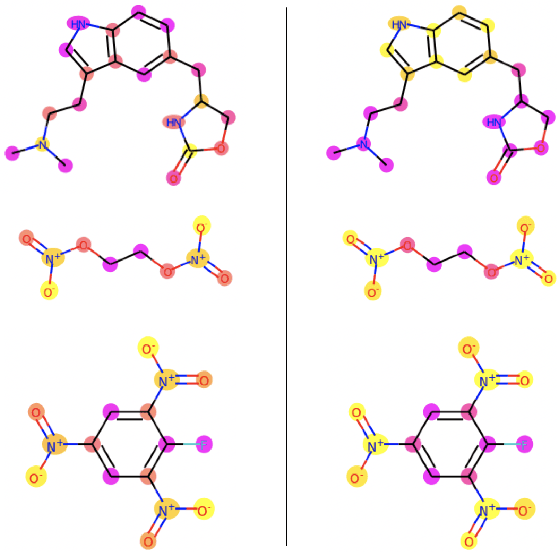
Graph neural network (GNN) explanations have largely been facilitated through post-hoc introspection. While this has been deemed successful, many post-hoc explanation methods have been shown to fail in capturing a model's learned representation. Due to this problem, it is worthwhile to consider how one might train a model so that it is more amenable to post-hoc analysis. Given the success of adversarial training in the computer vision domain to train models with more reliable representations, we propose a similar training paradigm for GNNs and analyze the respective impact on a model's explanations. In instances without ground truth labels, we also determine how well an explanation method is utilizing a model's learned representation through a new metric and demonstrate adversarial training can help better extract domain-relevant insights in chemistry.
A Winning Hand: Compressing Deep Networks Can Improve Out-Of-Distribution Robustness
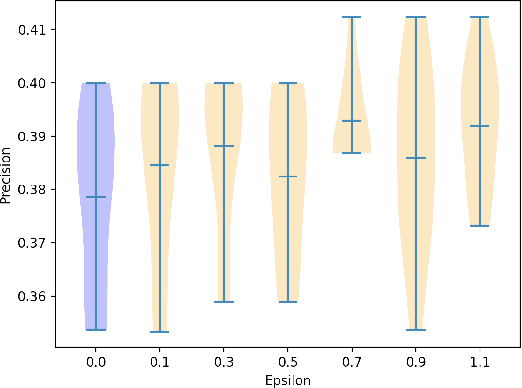
Jun 16, 2021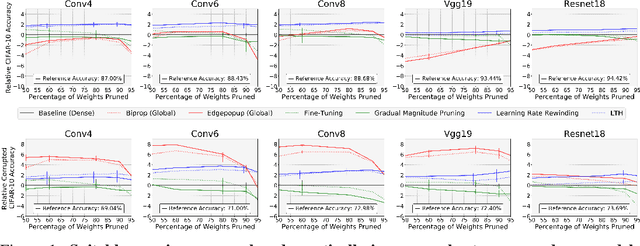
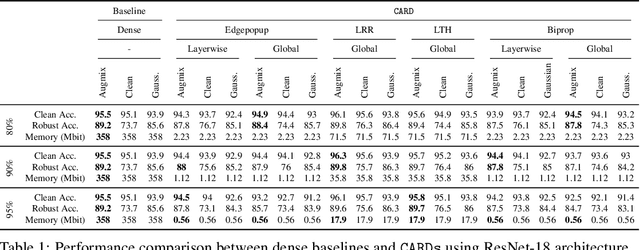
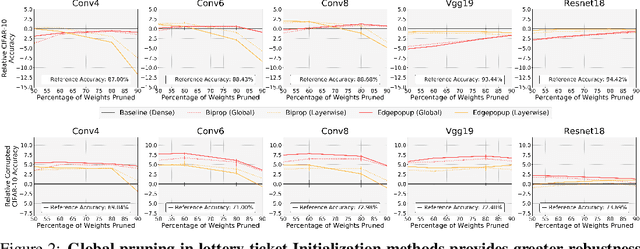
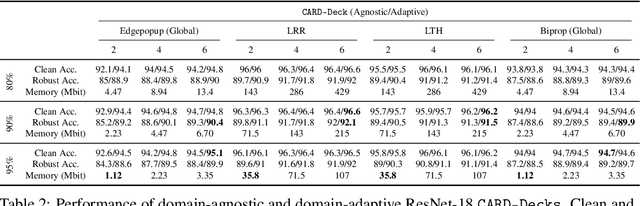
Two crucial requirements for a successful adoption of deep learning (DL) in the wild are: (1) robustness to distributional shifts, and (2) model compactness for achieving efficiency. Unfortunately, efforts towards simultaneously achieving Out-of-Distribution (OOD) robustness and extreme model compactness without sacrificing accuracy have mostly been unsuccessful. This raises an important question: "Is the inability to create compact, accurate, and robust deep neural networks (CARDs) fundamental?" To answer this question, we perform a large-scale analysis for a range of popular model compression techniques which uncovers several intriguing patterns. Notably, in contrast to traditional pruning approaches (e.g., fine tuning and gradual magnitude pruning), we find that "lottery ticket-style" pruning approaches can surprisingly be used to create high performing CARDs. Specifically, we are able to create extremely compact CARDs that are dramatically more robust than their significantly larger and full-precision counterparts while matching (or beating) their test accuracy, simply by pruning and/or quantizing. To better understand these differences, we perform sensitivity analysis in the Fourier domain for CARDs trained using different data augmentation methods. Motivated by our analysis, we develop a simple domain-adaptive test-time ensembling approach (CARD-Deck) that uses a gating module to dynamically select an appropriate CARD from the CARD-Deck based on their spectral-similarity with test samples. By leveraging complementary frequency biases of different compressed models, the proposed approach builds a "winning hand" of CARDs that establishes a new state-of-the-art on CIFAR-10-C accuracies (i.e., 96.8% clean and 92.75% robust) with dramatically better memory usage than their non-compressed counterparts. We also present some theoretical evidences supporting our empirical findings.
Mixture of Robust Experts : A Flexible Defense Against Multiple Perturbations
Apr 21, 2021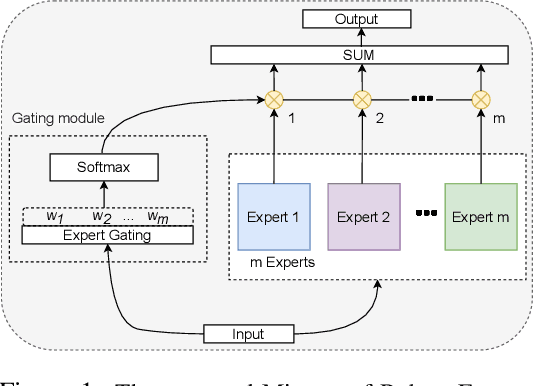
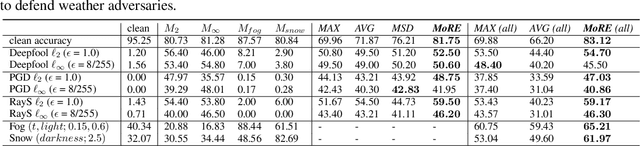
To tackle the susceptibility of deep neural networks to adversarial examples, the adversarial training has been proposed which provides a notion of security through an inner maximization problem presenting the first-order adversaries embedded within the outer minimization of the training loss. To generalize the adversarial robustness over different perturbation types, the adversarial training method has been augmented with the improved inner maximization presenting a union of multiple perturbations e.g., various $\ell_p$ norm-bounded perturbations. However, the improved inner maximization only enjoys limited flexibility in terms of the allowable perturbation types. In this work, through a gating mechanism, we assemble a set of expert networks, each one either adversarially trained to deal with a particular perturbation type or normally trained for boosting accuracy on clean data. The gating module assigns weights dynamically to each expert to achieve superior accuracy under various data types e.g., adversarial examples, adverse weather perturbations, and clean input. In order to deal with the obfuscated gradients issue, the training of the gating module is conducted together with fine-tuning of the last fully connected layers of expert networks through adversarial training approach. Using extensive experiments, we show that our Mixture of Robust Experts (MoRE) approach enables flexible integration of a broad range of robust experts with superior performance.