 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Principled Learning for Re-ranking in Recommender Systems
Apr 05, 2025



As the final stage of recommender systems, re-ranking presents ordered item lists to users that best match their interests. It plays such a critical role and has become a trending research topic with much attention from both academia and industry. Recent advances of re-ranking are focused on attentive listwise modeling of interactions and mutual influences among items to be re-ranked. However, principles to guide the learning process of a re-ranker, and to measure the quality of the output of the re-ranker, have been always missing. In this paper, we study such principles to learn a good re-ranker. Two principles are proposed, including convergence consistency and adversarial consistency. These two principles can be applied in the learning of a generic re-ranker and improve its performance. We validate such a finding by various baseline methods over different datasets.
Towards Efficient Replay in Federated Incremental Learning
Mar 09, 2024



In Federated Learning (FL), the data in each client is typically assumed fixed or static. However, data often comes in an incremental manner in real-world applications, where the data domain may increase dynamically. In this work, we study catastrophic forgetting with data heterogeneity in Federated Incremental Learning (FIL) scenarios where edge clients may lack enough storage space to retain full data. We propose to employ a simple, generic framework for FIL named Re-Fed, which can coordinate each client to cache important samples for replay. More specifically, when a new task arrives, each client first caches selected previous samples based on their global and local importance. Then, the client trains the local model with both the cached samples and the samples from the new task. Theoretically, we analyze the ability of Re-Fed to discover important samples for replay thus alleviating the catastrophic forgetting problem. Moreover, we empirically show that Re-Fed achieves competitive performance compared to state-of-the-art methods.
Denoising Time Cycle Modeling for Recommendation
Feb 05, 2024



Recently, modeling temporal patterns of user-item interactions have attracted much attention in recommender systems. We argue that existing methods ignore the variety of temporal patterns of user behaviors. We define the subset of user behaviors that are irrelevant to the target item as noises, which limits the performance of target-related time cycle modeling and affect the recommendation performance. In this paper, we propose Denoising Time Cycle Modeling (DiCycle), a novel approach to denoise user behaviors and select the subset of user behaviors that are highly related to the target item. DiCycle is able to explicitly model diverse time cycle patterns for recommendation. Extensive experiments are conducted on both public benchmarks and a real-world dataset, demonstrating the superior performance of DiCycle over the state-of-the-art recommendation methods.
Edge-cloud Collaborative Learning with Federated and Centralized Features
Apr 12, 2023Federated learning (FL) is a popular way of edge computing that doesn't compromise users' privacy. Current FL paradigms assume that data only resides on the edge, while cloud servers only perform model averaging. However, in real-life situations such as recommender systems, the cloud server has the ability to store historical and interactive features. In this paper, our proposed Edge-Cloud Collaborative Knowledge Transfer Framework (ECCT) bridges the gap between the edge and cloud, enabling bi-directional knowledge transfer between both, sharing feature embeddings and prediction logits. ECCT consolidates various benefits, including enhancing personalization, enabling model heterogeneity, tolerating training asynchronization, and relieving communication burdens. Extensive experiments on public and industrial datasets demonstrate ECCT's effectiveness and potential for use in academia and industry.
Prototypical Contrastive Learning and Adaptive Interest Selection for Candidate Generation in Recommendations
Nov 23, 2022



Deep Candidate Generation plays an important role in large-scale recommender systems. It takes user history behaviors as inputs and learns user and item latent embeddings for candidate generation. In the literature, conventional methods suffer from two problems. First, a user has multiple embeddings to reflect various interests, and such number is fixed. However, taking into account different levels of user activeness, a fixed number of interest embeddings is sub-optimal. For example, for less active users, they may need fewer embeddings to represent their interests compared to active users. Second, the negative samples are often generated by strategies with unobserved supervision, and similar items could have different labels. Such a problem is termed as class collision. In this paper, we aim to advance the typical two-tower DNN candidate generation model. Specifically, an Adaptive Interest Selection Layer is designed to learn the number of user embeddings adaptively in an end-to-end way, according to the level of their activeness. Furthermore, we propose a Prototypical Contrastive Learning Module to tackle the class collision problem introduced by negative sampling. Extensive experimental evaluations show that the proposed scheme remarkably outperforms competitive baselines on multiple benchmarks.
Quickest Change Detection in Anonymous Heterogeneous Sensor Networks
Feb 26, 2022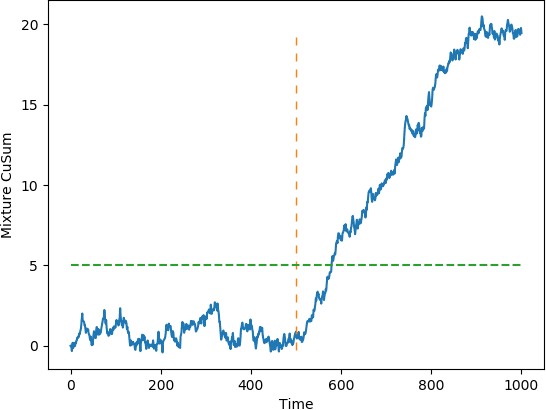
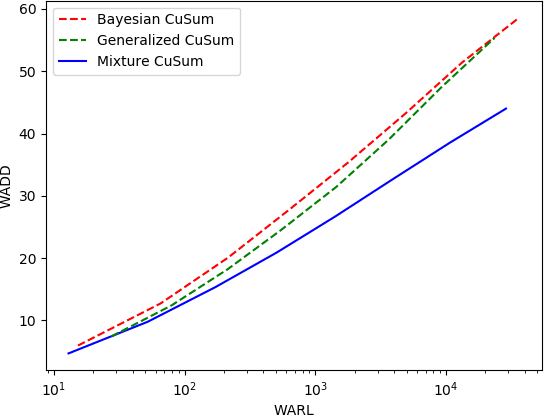
The problem of quickest change detection (QCD) in anonymous heterogeneous sensor networks is studied. There are $n$ heterogeneous sensors and a fusion center. The sensors are clustered into $K$ groups, and different groups follow different data-generating distributions. At some unknown time, an event occurs in the network and changes the data-generating distribution of the sensors. The goal is to detect the change as quickly as possible, subject to false alarm constraints. The anonymous setting is studied, where at each time step, the fusion center receives $n$ unordered samples, and the fusion center does not know which sensor each sample comes from, and thus does not know its exact distribution. A simple optimality proof is first derived for the mixture likelihood ratio test, which was constructed and proved to be optimal for the non-sequential anonymous setting in (Chen and Wang, 2019). For the QCD problem, a mixture CuSum algorithm is further constructed, and is further shown to be optimal under Lorden's criterion. For large networks, a computationally efficient test is proposed and a novel theoretical characterization of its false alarm rate is developed. Numerical results are provided to validate the theoretical results.
Escaping Saddle Points in Nonconvex Minimax Optimization via Cubic-Regularized Gradient Descent-Ascent
Oct 15, 2021
The gradient descent-ascent (GDA) algorithm has been widely applied to solve nonconvex minimax optimization problems. However, the existing GDA-type algorithms can only find first-order stationary points of the envelope function of nonconvex minimax optimization problems, which does not rule out the possibility to get stuck at suboptimal saddle points. In this paper, we develop Cubic-GDA -- the first GDA-type algorithm for escaping strict saddle points in nonconvex-strongly-concave minimax optimization. Specifically, the algorithm uses gradient ascent to estimate the second-order information of the minimax objective function, and it leverages the cubic regularization technique to efficiently escape the strict saddle points. Under standard smoothness assumptions on the objective function, we show that Cubic-GDA admits an intrinsic potential function whose value monotonically decreases in the minimax optimization process. Such a property leads to a desired global convergence of Cubic-GDA to a second-order stationary point at a sublinear rate. Moreover, we analyze the convergence rate of Cubic-GDA in the full spectrum of a gradient dominant-type nonconvex geometry. Our result shows that Cubic-GDA achieves an orderwise faster convergence rate than the standard GDA for a wide spectrum of gradient dominant geometry. Our study bridges minimax optimization with second-order optimization and may inspire new developments along this direction.
Learning Graph Neural Networks with Approximate Gradient Descent
Dec 07, 2020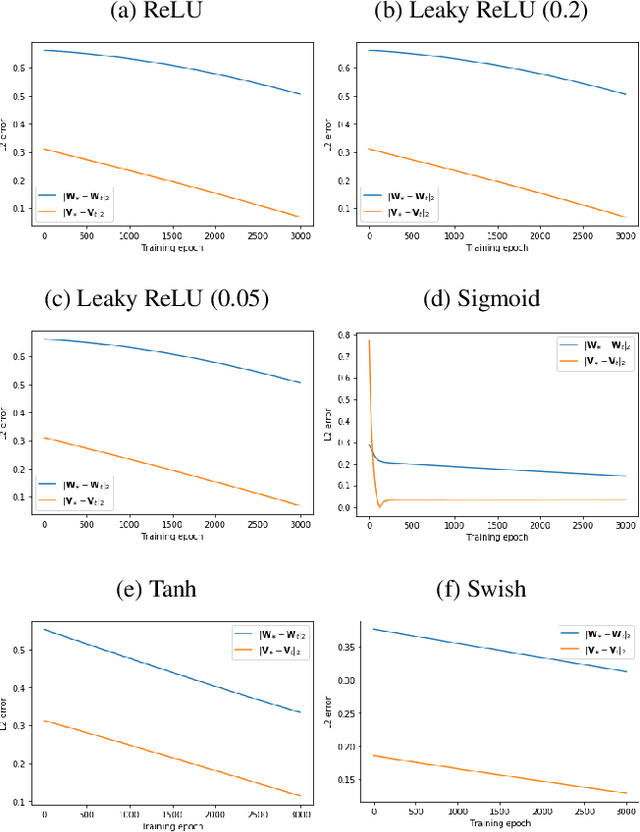
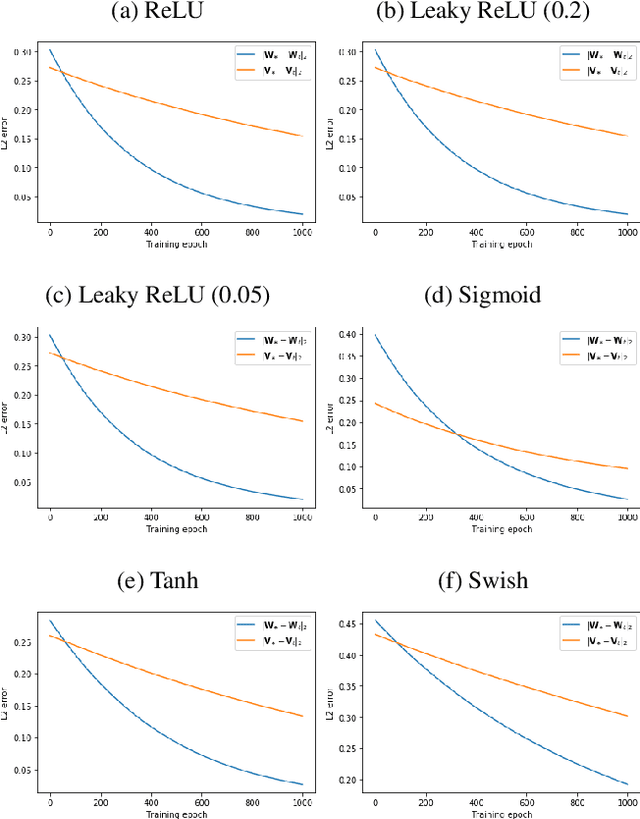
The first provably efficient algorithm for learning graph neural networks (GNNs) with one hidden layer for node information convolution is provided in this paper. Two types of GNNs are investigated, depending on whether labels are attached to nodes or graphs. A comprehensive framework for designing and analyzing convergence of GNN training algorithms is developed. The algorithm proposed is applicable to a wide range of activation functions including ReLU, Leaky ReLU, Sigmod, Softplus and Swish. It is shown that the proposed algorithm guarantees a linear convergence rate to the underlying true parameters of GNNs. For both types of GNNs, sample complexity in terms of the number of nodes or the number of graphs is characterized. The impact of feature dimension and GNN structure on the convergence rate is also theoretically characterized. Numerical experiments are further provided to validate our theoretical analysis.
Prospect Theory Based Crowdsourcing for Classification in the Presence of Spammers
Sep 03, 2019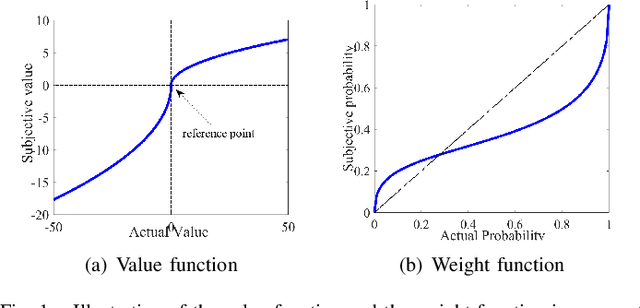
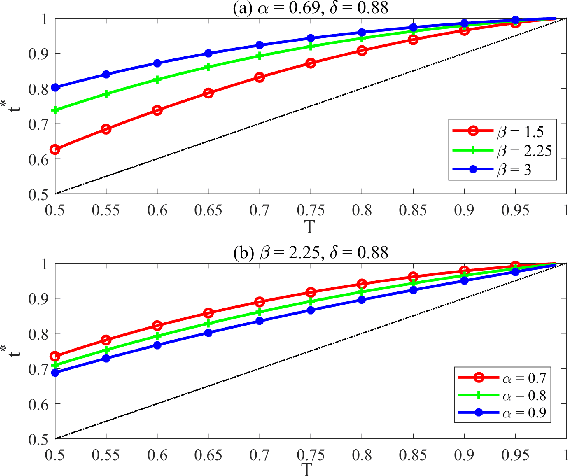
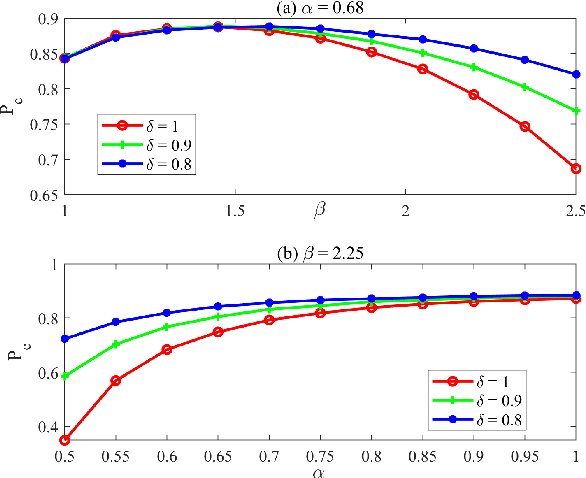
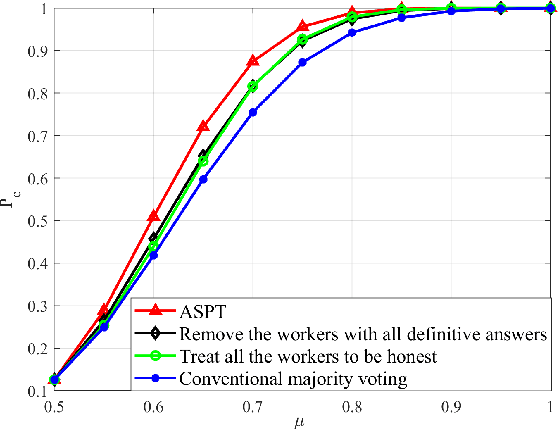
We consider the $M$-ary classification problem via crowdsourcing, where crowd workers respond to simple binary questions and the answers are aggregated via decision fusion. The workers have a reject option to skip answering a question when they do not have the expertise, or when the confidence of answering that question correctly is low. We further consider that there are spammers in the crowd who respond to the questions with random guesses. Under the payment mechanism that encourages the reject option, we study the behavior of honest workers and spammers, whose objectives are to maximize their monetary rewards. To accurately characterize human behavioral aspects, we employ prospect theory to model the rationality of the crowd workers, whose perception of costs and probabilities are distorted based on some value and weight functions, respectively. Moreover, we estimate the number of spammers and employ a weighted majority voting decision rule, where we assign an optimal weight for every worker to maximize the system performance. The probability of correct classification and asymptotic system performance are derived. We also provide simulation results to demonstrate the effectiveness of our approach.
A Look at the Effect of Sample Design on Generalization through the Lens of Spectral Analysis
Jun 08, 2019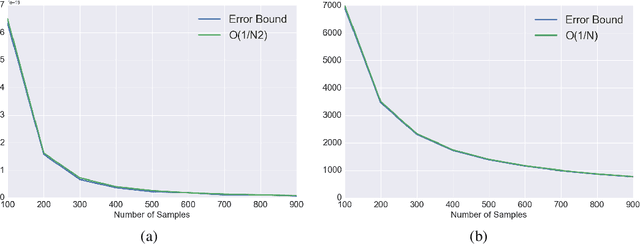
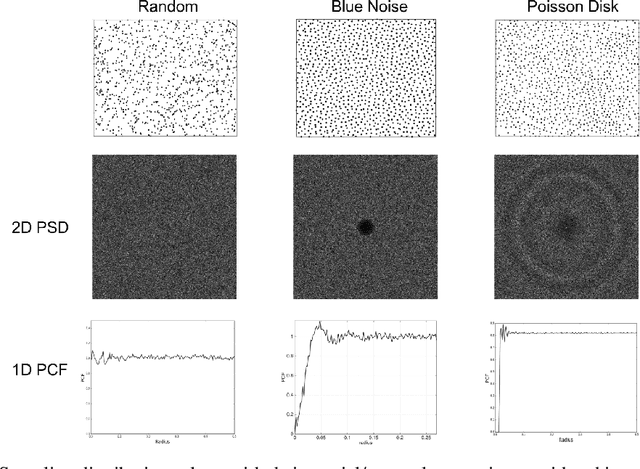
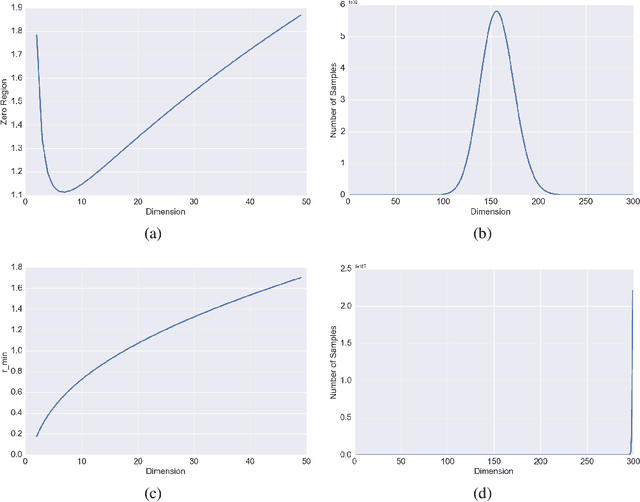
This paper provides a general framework to study the effect of sampling properties of training data on the generalization error of the learned machine learning (ML) models. Specifically, we propose a new spectral analysis of the generalization error, expressed in terms of the power spectra of the sampling pattern and the function involved. The framework is build in the Euclidean space using Fourier analysis and establishes a connection between some high dimensional geometric objects and optimal spectral form of different state-of-the-art sampling patterns. Subsequently, we estimate the expected error bounds and convergence rate of different state-of-the-art sampling patterns, as the number of samples and dimensions increase. We make several observations about generalization error which are valid irrespective of the approximation scheme (or learning architecture) and training (or optimization) algorithms. Our result also sheds light on ways to formulate design principles for constructing optimal sampling methods for particular problems.