 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Calibrating Active Binocular Vision via Active Efficient Coding with Deep Autoencoders
Jan 27, 2021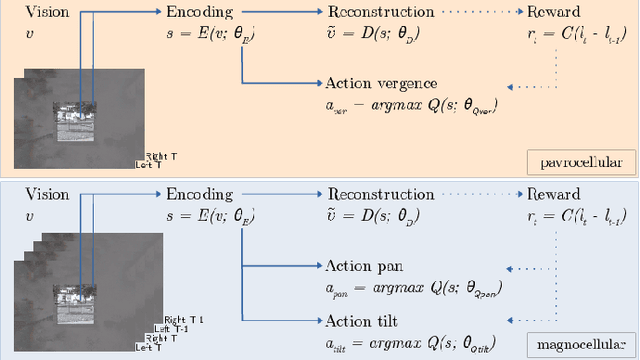
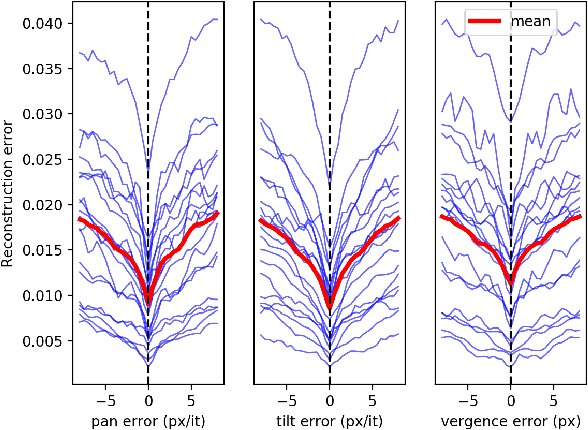
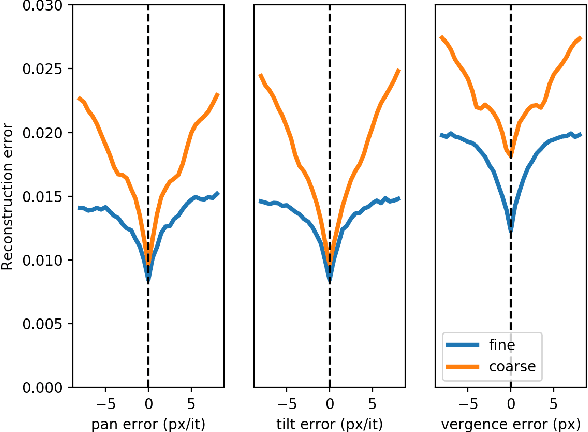
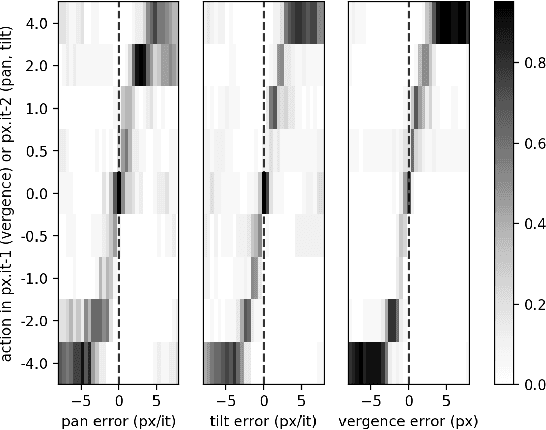
We present a model of the self-calibration of active binocular vision comprising the simultaneous learning of visual representations, vergence, and pursuit eye movements. The model follows the principle of Active Efficient Coding (AEC), a recent extension of the classic Efficient Coding Hypothesis to active perception. In contrast to previous AEC models, the present model uses deep autoencoders to learn sensory representations. We also propose a new formulation of the intrinsic motivation signal that guides the learning of behavior. We demonstrate the performance of the model in simulations.
Learning Abstract Representations through Lossy Compression of Multi-Modal Signals
Jan 27, 2021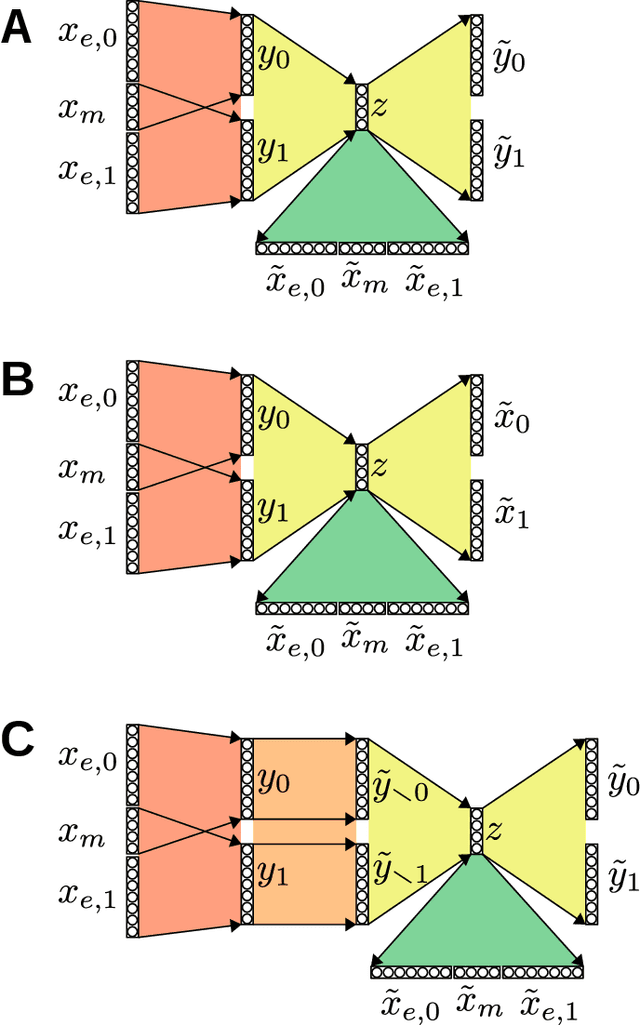
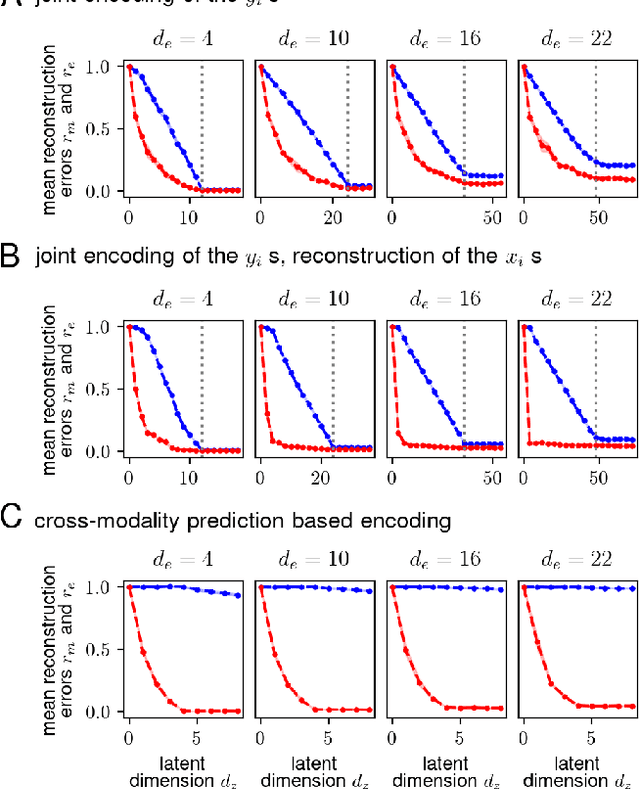
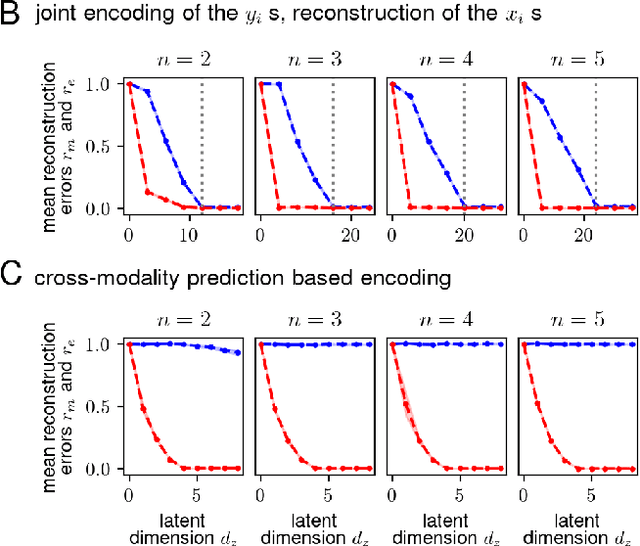
A key competence for open-ended learning is the formation of increasingly abstract representations useful for driving complex behavior. Abstract representations ignore specific details and facilitate generalization. Here we consider the learning of abstract representations in a multi-modal setting with two or more input modalities. We treat the problem as a lossy compression problem and show that generic lossy compression of multimodal sensory input naturally extracts abstract representations that tend to strip away modalitiy specific details and preferentially retain information that is shared across the different modalities. Furthermore, we propose an architecture to learn abstract representations by identifying and retaining only the information that is shared across multiple modalities while discarding any modality specific information.