 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Optimization of Machine Learning Prediction Queries
May 31, 2022
Prediction queries are widely used across industries to perform advanced analytics and draw insights from data. They include a data processing part (e.g., for joining, filtering, cleaning, featurizing the datasets) and a machine learning (ML) part invoking one or more trained models to perform predictions. These parts have so far been optimized in isolation, leaving significant opportunities for optimization unexplored. We present Raven, a production-ready system for optimizing prediction queries. Raven follows the enterprise architectural trend of collocating data and ML runtimes. It relies on a unified intermediate representation that captures both data and ML operators in a single graph structure to unlock two families of optimizations. First, it employs logical optimizations that pass information between the data part (and the properties of the underlying data) and the ML part to optimize each other. Second, it introduces logical-to-physical transformations that allow operators to be executed on different runtimes (relational, ML, and DNN) and hardware (CPU, GPU). Novel data-driven optimizations determine the runtime to be used for each part of the query to achieve optimal performance. Our evaluation shows that Raven improves performance of prediction queries on Apache Spark and SQL Server by up to 13.1x and 330x, respectively. For complex models where GPU acceleration is beneficial, Raven provides up to 8x speedup compared to state-of-the-art systems.
Query Processing on Tensor Computation Runtimes
Mar 03, 2022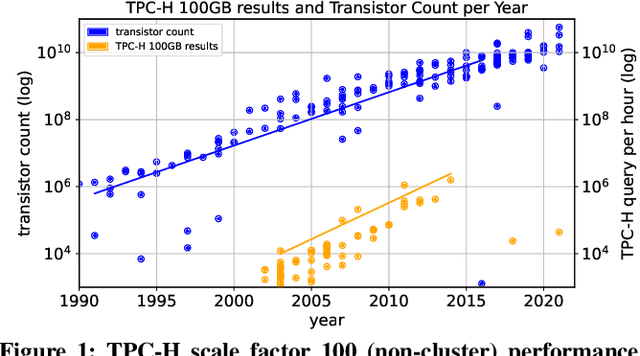

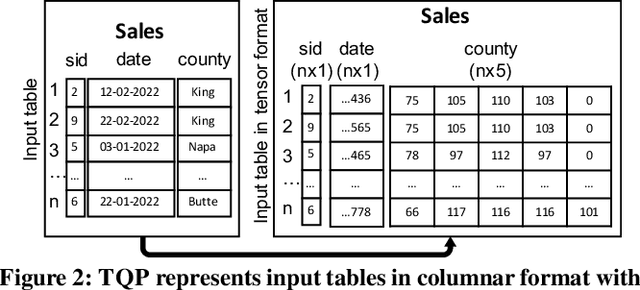
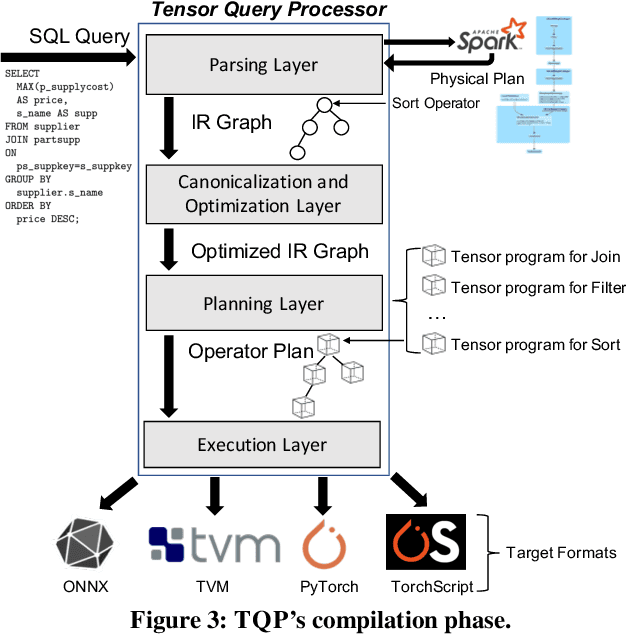
The huge demand for computation in artificial intelligence (AI) is driving unparalleled investments in new hardware and software systems for AI. This leads to an explosion in the number of specialized hardware devices, which are now part of the offerings of major cloud providers. Meanwhile, by hiding the low-level complexity through a tensor-based interface, tensor computation runtimes (TCRs) such as PyTorch allow data scientists to efficiently exploit the exciting capabilities offered by the new hardware. In this paper, we explore how databases can ride the wave of innovation happening in the AI space. Specifically, we present Tensor Query Processor (TQP): a SQL query processor leveraging the tensor interface of TCRs. TQP is able to efficiently run the full TPC-H benchmark by implementing novel algorithms for executing relational operators on the specialized tensor routines provided by TCRs. Meanwhile, TQP can target various hardware while only requiring a fraction of the usual development effort. Experiments show that TQP can improve query execution time by up to 20x over CPU-only systems, and up to 5x over specialized GPU solutions. Finally, TQP can accelerate queries mixing ML predictions and SQL end-to-end, and deliver up to 5x speedup over CPU baselines.
Lights, Camera, Action! A Framework to Improve NLP Accuracy over OCR documents
Aug 06, 2021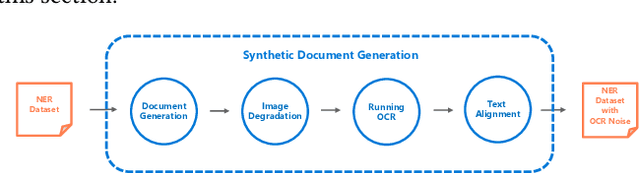
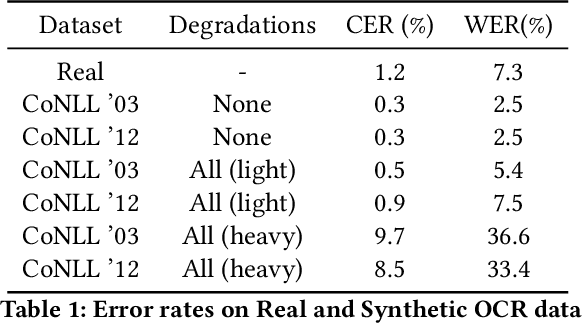
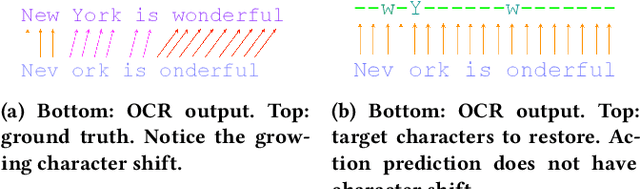

Document digitization is essential for the digital transformation of our societies, yet a crucial step in the process, Optical Character Recognition (OCR), is still not perfect. Even commercial OCR systems can produce questionable output depending on the fidelity of the scanned documents. In this paper, we demonstrate an effective framework for mitigating OCR errors for any downstream NLP task, using Named Entity Recognition (NER) as an example. We first address the data scarcity problem for model training by constructing a document synthesis pipeline, generating realistic but degraded data with NER labels. We measure the NER accuracy drop at various degradation levels and show that a text restoration model, trained on the degraded data, significantly closes the NER accuracy gaps caused by OCR errors, including on an out-of-domain dataset. For the benefit of the community, we have made the document synthesis pipeline available as an open-source project.
Seagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020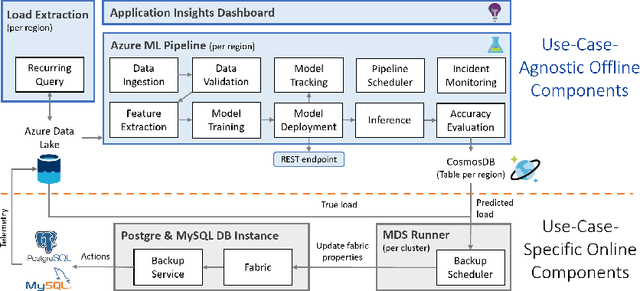
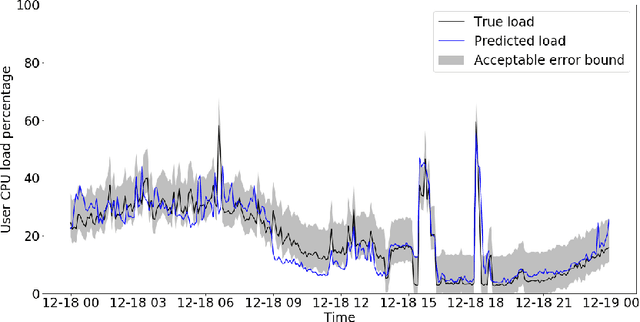
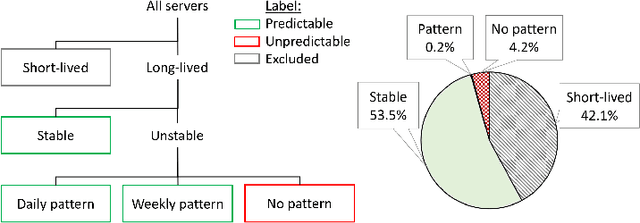
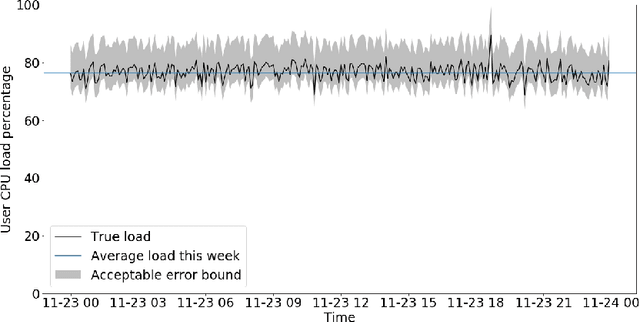
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.
Large-Scale Intelligent Microservices
Sep 17, 2020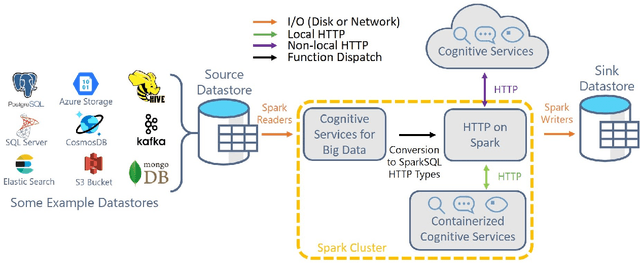
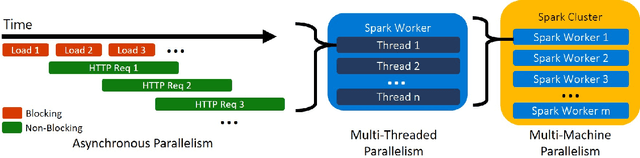
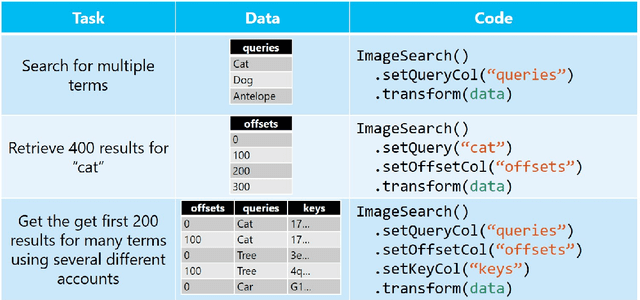
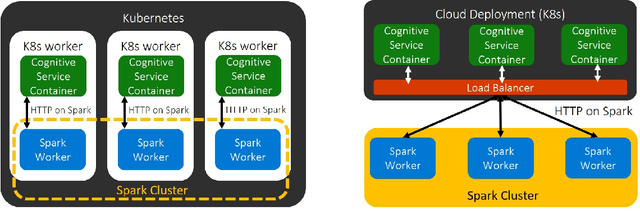
Deploying Machine Learning (ML) algorithms within databases is a challenge due to the varied computational footprints of modern ML algorithms and the myriad of database technologies each with their own restrictive syntax. We introduce an Apache Spark-based micro-service orchestration framework that extends database operations to include web service primitives. Our system can orchestrate web services across hundreds of machines and takes full advantage of cluster, thread, and asynchronous parallelism. Using this framework, we provide large scale clients for intelligent services such as speech, vision, search, anomaly detection, and text analysis. This allows users to integrate ready-to-use intelligence into any datastore with an Apache Spark connector. To eliminate the majority of overhead from network communication, we also introduce a low-latency containerized version of our architecture. Finally, we demonstrate that the services we investigate are competitive on a variety of benchmarks, and present two applications of this framework to create intelligent search engines, and real time auto race analytics systems.