 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix3D: Out-of-Context Data Augmentation for 3D Scenes
Oct 05, 2021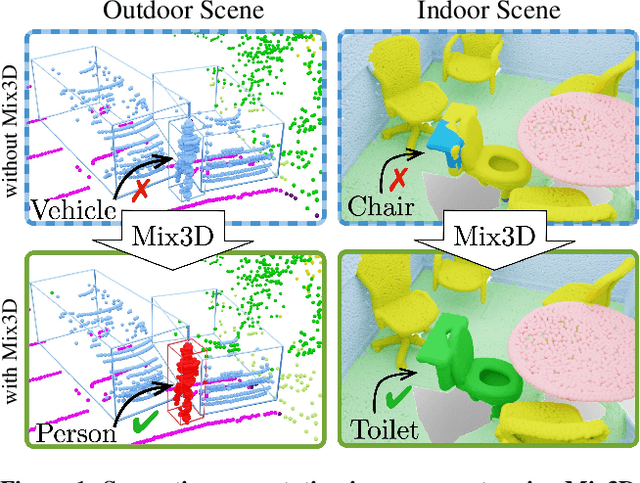
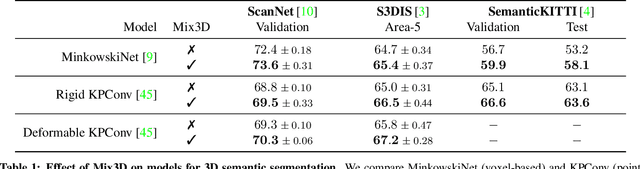


We present Mix3D, a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well. We perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU. Code is available at: https://nekrasov.dev/mix3d/
Person-MinkUNet: 3D Person Detection with LiDAR Point Cloud
Jul 03, 2021In this preliminary work we attempt to apply submanifold sparse convolution to the task of 3D person detection. In particular, we present Person-MinkUNet, a single-stage 3D person detection network based on Minkowski Engine with U-Net architecture. The network achieves a 76.4% average precision (AP) on the JRDB 3D detection benchmark.
Domain and Modality Gaps for LiDAR-based Person Detection on Mobile Robots
Jun 21, 2021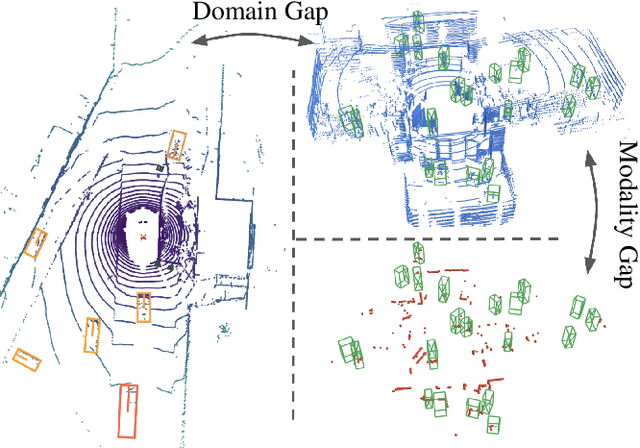
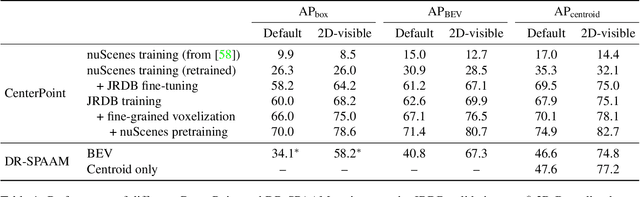
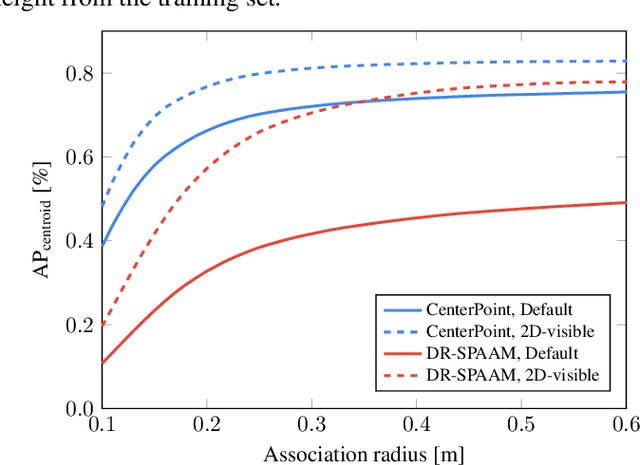

Person detection is a crucial task for mobile robots navigating in human-populated environments and LiDAR sensors are promising for this task, given their accurate depth measurements and large field of view. This paper studies existing LiDAR-based person detectors with a particular focus on mobile robot scenarios (e.g. service robot or social robot), where persons are observed more frequently and in much closer ranges, compared to the driving scenarios. We conduct a series of experiments, using the recently released JackRabbot dataset and the state-of-the-art detectors based on 3D or 2D LiDAR sensors (CenterPoint and DR-SPAAM respectively). These experiments revolve around the domain gap between driving and mobile robot scenarios, as well as the modality gap between 3D and 2D LiDAR sensors. For the domain gap, we aim to understand if detectors pretrained on driving datasets can achieve good performance on the mobile robot scenarios, for which there are currently no trained models readily available. For the modality gap, we compare detectors that use 3D or 2D LiDAR, from various aspects, including performance, runtime, localization accuracy, robustness to range and crowdedness. The results from our experiments provide practical insights into LiDAR-based person detection and facilitate informed decisions for relevant mobile robot designs and applications.
Opening up Open-World Tracking
Apr 22, 2021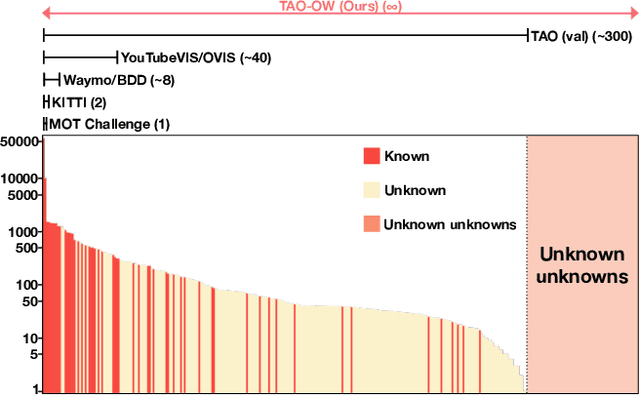


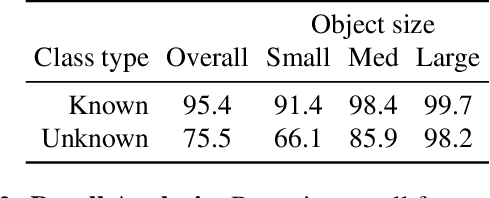
In this paper, we propose and study Open-World Tracking (OWT). Open-world tracking goes beyond current multi-object tracking benchmarks and methods which focus on tracking object classes that belong to a predefined closed-set of frequently observed object classes. In OWT, we relax this assumption: we may encounter objects at inference time that were not labeled for training. The main contribution of this paper is the formalization of the OWT task, along with an evaluation protocol and metric (Open-World Tracking Accuracy, OWTA), which decomposes into two intuitive terms, one for measuring recall, and another for measuring track association accuracy. This allows us to perform a rigorous evaluation of several different baselines that follow design patterns proposed in the multi-object tracking community. Further we show that our Open-World Tracking Baseline, while performing well in the OWT setting, also achieves near state-of-the-art results on traditional closed-world benchmarks, without any adjustments or tuning. We believe that this paper is an initial step towards studying multi-object tracking in the open world, a task of crucial importance for future intelligent agents that will need to understand, react to, and learn from, an infinite variety of objects that can appear in an open world.
STEP: Segmenting and Tracking Every Pixel
Feb 23, 2021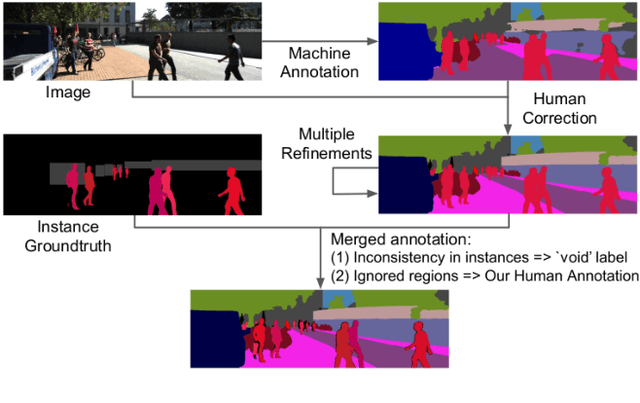
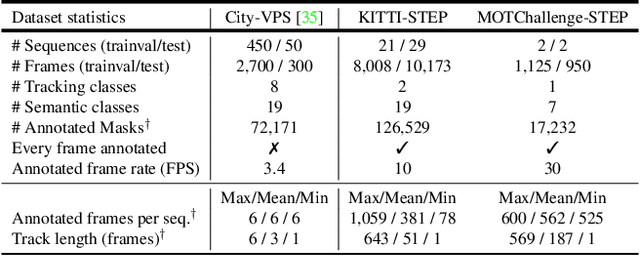


In this paper, we tackle video panoptic segmentation, a task that requires assigning semantic classes and track identities to all pixels in a video. To study this important problem in a setting that requires a continuous interpretation of sensory data, we present a new benchmark: Segmenting and Tracking Every Pixel (STEP), encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP together with a new evaluation metric. Our work is the first that targets this task in a real-world setting that requires dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. By contrast, our datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking. For measuring the performance, we propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is suitable for evaluating sequences of arbitrary length. We will make our datasets, metric, and baselines publicly available.
From Points to Multi-Object 3D Reconstruction
Dec 21, 2020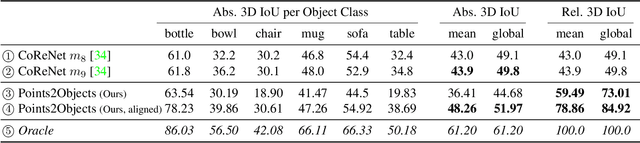
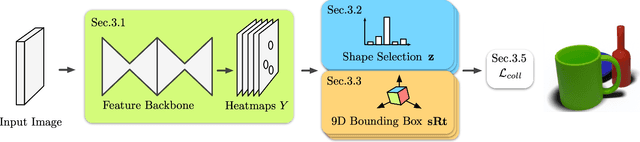

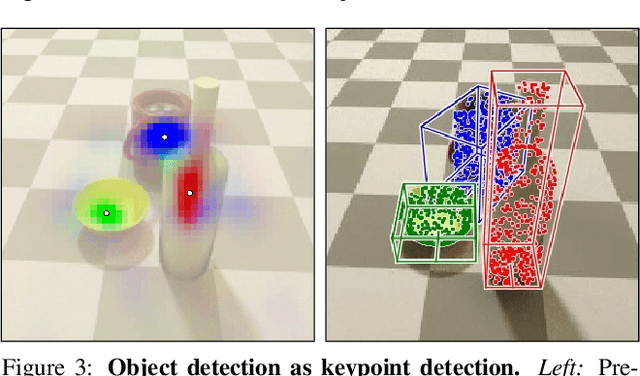
We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
Self-Supervised Person Detection in 2D Range Data using a Calibrated Camera
Dec 16, 2020

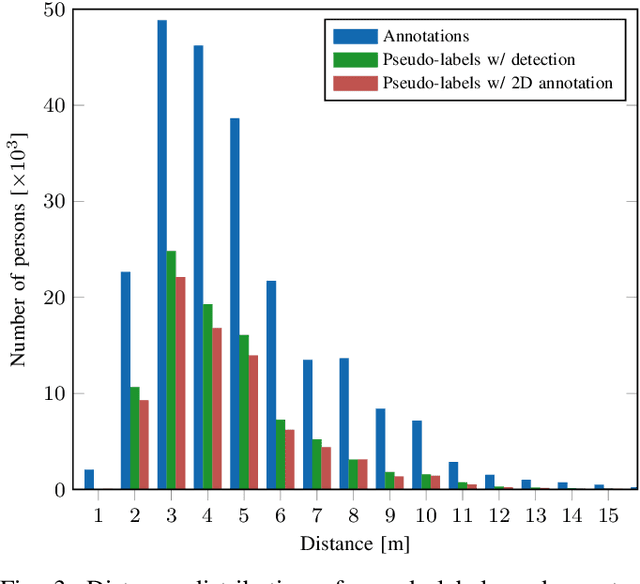
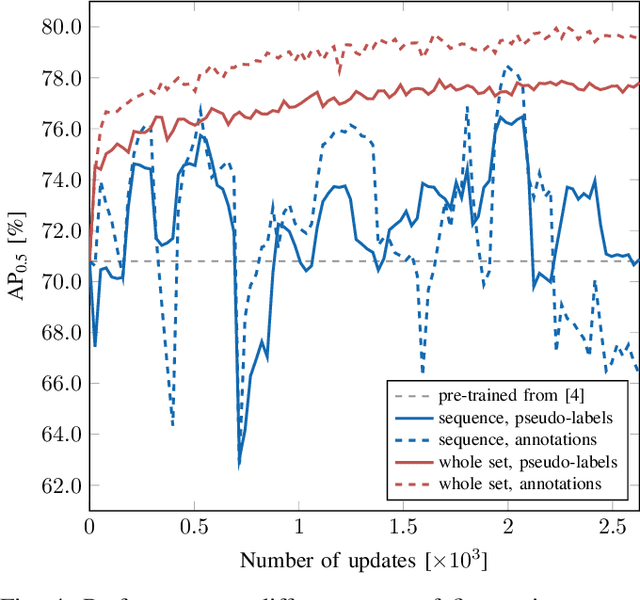
Deep learning is the essential building block of state-of-the-art person detectors in 2D range data. However, only a few annotated datasets are available for training and testing these deep networks, potentially limiting their performance when deployed in new environments or with different LiDAR models. We propose a method, which uses bounding boxes from an image-based detector (e.g. Faster R-CNN) on a calibrated camera to automatically generate training labels (called pseudo-labels) for 2D LiDAR-based person detectors. Through experiments on the JackRabbot dataset with two detector models, DROW3 and DR-SPAAM, we show that self-supervised detectors, trained or fine-tuned with pseudo-labels, outperform detectors trained using manual annotations from a different dataset. Combined with robust training techniques, the self-supervised detectors reach a performance close to the ones trained using manual annotations. Our method is an effective way to improve person detectors during deployment without any additional labeling effort, and we release our source code to support relevant robotic applications.
Reducing the Annotation Effort for Video Object Segmentation Datasets
Nov 02, 2020
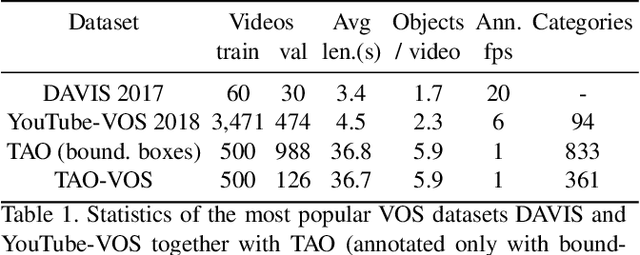

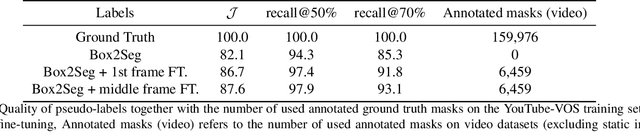
For further progress in video object segmentation (VOS), larger, more diverse, and more challenging datasets will be necessary. However, densely labeling every frame with pixel masks does not scale to large datasets. We use a deep convolutional network to automatically create pseudo-labels on a pixel level from much cheaper bounding box annotations and investigate how far such pseudo-labels can carry us for training state-of-the-art VOS approaches. A very encouraging result of our study is that adding a manually annotated mask in only a single video frame for each object is sufficient to generate pseudo-labels which can be used to train a VOS method to reach almost the same performance level as when training with fully segmented videos. We use this workflow to create pixel pseudo-labels for the training set of the challenging tracking dataset TAO, and we manually annotate a subset of the validation set. Together, we obtain the new TAO-VOS benchmark, which we make publicly available at www.vision.rwth-aachen.de/page/taovos. While the performance of state-of-the-art methods on existing datasets starts to saturate, TAO-VOS remains very challenging for current algorithms and reveals their shortcomings.
HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
Sep 29, 2020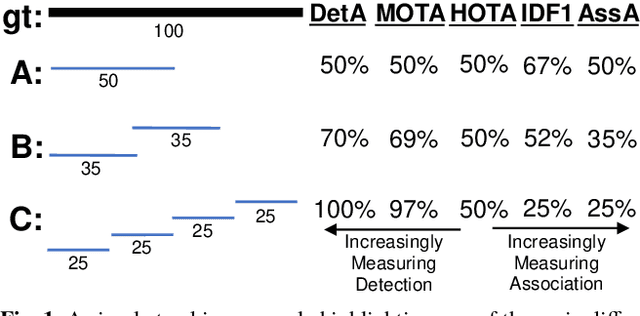
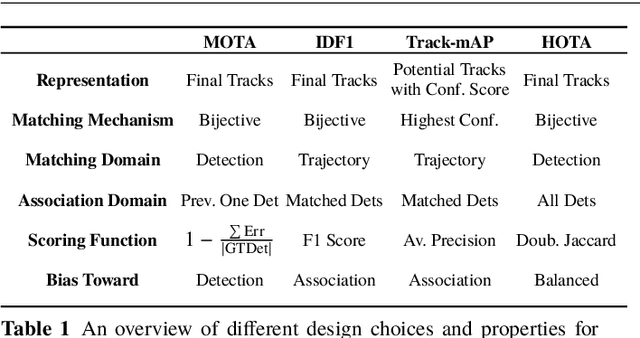
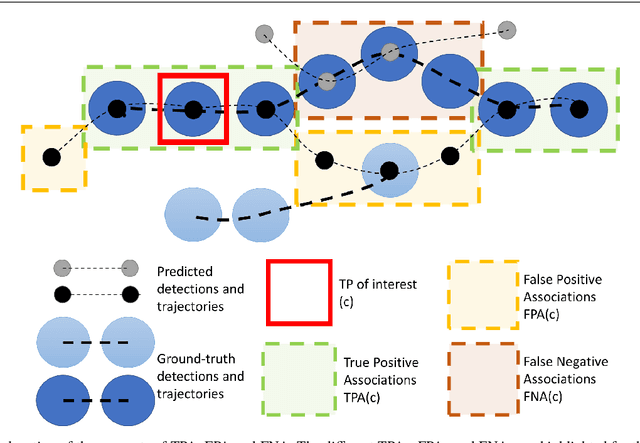
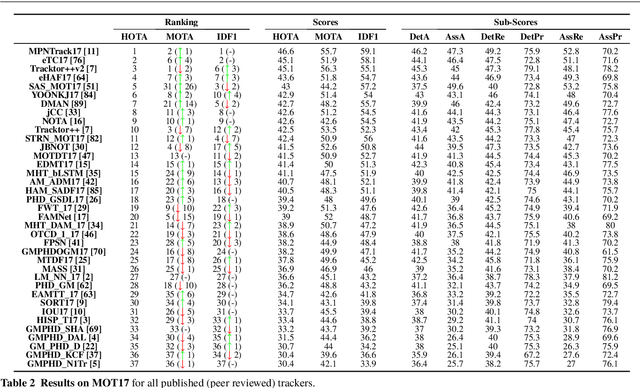
Multi-Object Tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, HOTA (Higher Order Tracking Accuracy), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
Making a Case for 3D Convolutions for Object Segmentation in Videos
Aug 26, 2020
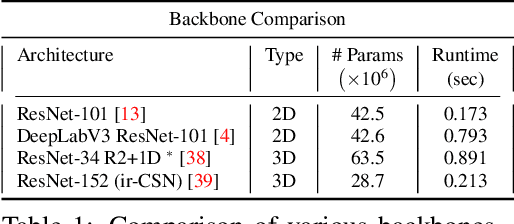
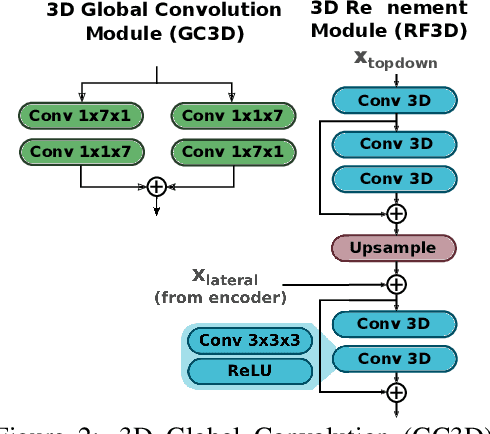
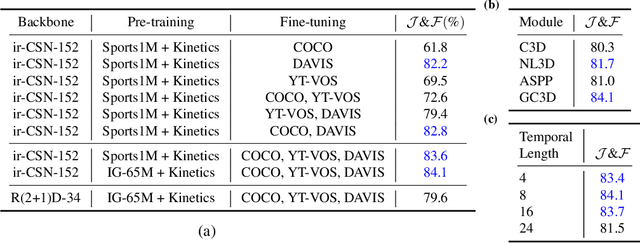
The task of object segmentation in videos is usually accomplished by processing appearance and motion information separately using standard 2D convolutional networks, followed by a learned fusion of the two sources of information. On the other hand, 3D convolutional networks have been successfully applied for video classification tasks, but have not been leveraged as effectively to problems involving dense per-pixel interpretation of videos compared to their 2D convolutional counterparts and lag behind the aforementioned networks in terms of performance. In this work, we show that 3D CNNs can be effectively applied to dense video prediction tasks such as salient object segmentation. We propose a simple yet effective encoder-decoder network architecture consisting entirely of 3D convolutions that can be trained end-to-end using a standard cross-entropy loss. To this end, we leverage an efficient 3D encoder, and propose a 3D decoder architecture, that comprises novel 3D Global Convolution layers and 3D Refinement modules. Our approach outperforms existing state-of-the-arts by a large margin on the DAVIS'16 Unsupervised, FBMS and ViSal dataset benchmarks in addition to being faster, thus showing that our architecture can efficiently learn expressive spatio-temporal features and produce high quality video segmentation masks. Our code and models will be made publicly available.