 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Retrieval Heads See Images? Multimodal Retrieval Heads in Long-Context Vision-Language Models
May 26, 2026Large vision-language models increasingly rely on long-context modeling to reason over documents, hour-level videos, and long-horizon agent trajectories, requiring them to locate relevant evidence across interleaved text and images. Prior work has studied this behavior using retrieval heads in large language models, but its copy-based criterion does not directly apply when evidence appears in images. We introduce a multimodal retrieval head detection method that scores attention from question tokens to textual or visual evidence. With this method, we show that multimodal retrieval heads are sparse, intrinsic, and causally important: only 4.4-10.2% of attention heads account for 50% of the positive retrieval-score mass, and masking the top-5% selected heads drops MMLongBench-Doc from 48.2% to 5.7% and SlideVQA from 71.2% to 8.9%, while random-head masking is far less damaging. Further analysis shows that these heads are partly shared across modalities yet remain dynamic within each modality, with image retrieval heads changing more than text retrieval heads as context length and haystack modality change. Without further training, we find that these heads can also be used directly to rank visually rich documents: on MMDocIR, Qwen3-VL-8B selected-head scoring improves Recall@1 by 7.7/7.4 macro/micro points for page retrieval and 6.3/6.8 points for layout retrieval over the strongest reported baseline.
Training Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
May 13, 2026Long-context modeling is becoming a core capability of modern large vision-language models (LVLMs), enabling sustained context management across long-document understanding, video analysis, and multi-turn tool use in agentic workflows. Yet practical training recipes remain insufficiently explored, particularly for designing and balancing long-context data mixtures. In this work, we present a systematic study of long-context continued pre-training for LVLMs, extending a 7B model from 32K to 128K context with extensive ablations on long-document data. We first show that long-document VQA is substantially more effective than OCR transcription. Building on this observation, our ablations further yield three key findings: i) for sequence-length distribution, balanced data outperforms target-length-focused data (e.g., 128K), suggesting that long-context ability requires generalizable key-information retrieval across various lengths and positions; ii) retrieval remains the primary bottleneck, favoring retrieval-heavy mixtures with modest reasoning data for task diversity; and iii) pure long-document VQA largely preserves short-context capabilities, suggesting that instruction-formatted long data reduces the need for short-data mixing. Based on these findings, we introduce MMProLong, obtained by long-context continued pre-training from Qwen2.5-VL-7B with only a 5B-token budget. MMProLong improves long-document VQA scores by 7.1% and maintains strong performance at 256K and 512K contexts beyond its 128K training window, without additional training. It further generalizes to webpage-based multimodal needle retrieval, long-context vision-text compression, and long-video understanding without task-specific supervision. Overall, our study establishes a practical LongPT recipe and an empirical foundation for advancing long-context vision-language models.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Reducing the Annotation Effort for Video Object Segmentation Datasets
Nov 02, 2020
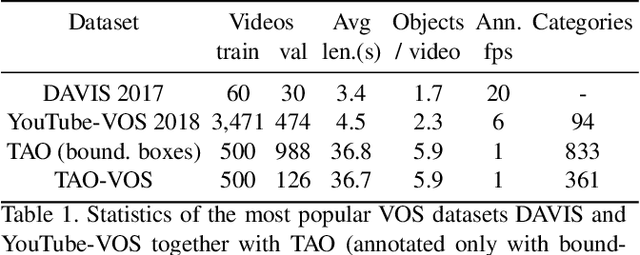

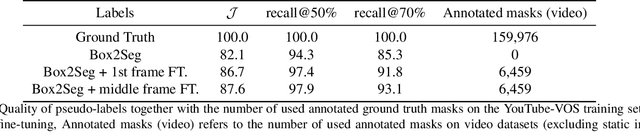
For further progress in video object segmentation (VOS), larger, more diverse, and more challenging datasets will be necessary. However, densely labeling every frame with pixel masks does not scale to large datasets. We use a deep convolutional network to automatically create pseudo-labels on a pixel level from much cheaper bounding box annotations and investigate how far such pseudo-labels can carry us for training state-of-the-art VOS approaches. A very encouraging result of our study is that adding a manually annotated mask in only a single video frame for each object is sufficient to generate pseudo-labels which can be used to train a VOS method to reach almost the same performance level as when training with fully segmented videos. We use this workflow to create pixel pseudo-labels for the training set of the challenging tracking dataset TAO, and we manually annotate a subset of the validation set. Together, we obtain the new TAO-VOS benchmark, which we make publicly available at www.vision.rwth-aachen.de/page/taovos. While the performance of state-of-the-art methods on existing datasets starts to saturate, TAO-VOS remains very challenging for current algorithms and reveals their shortcomings.