 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBastian Leibe
Global Hierarchical Attention for 3D Point Cloud Analysis
Aug 07, 2022
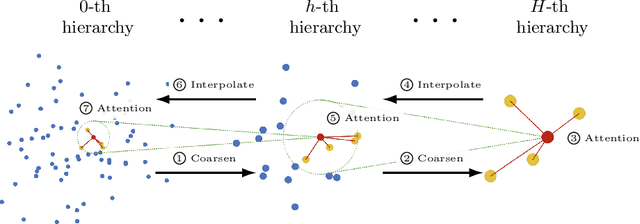
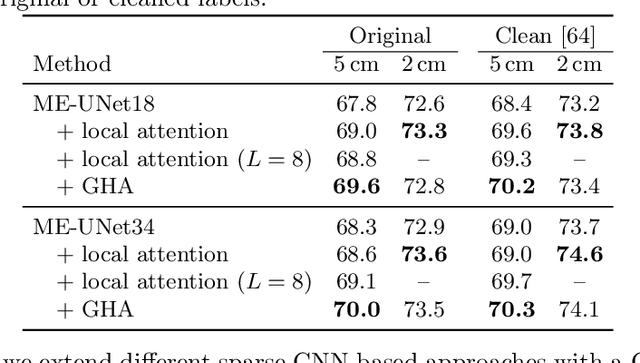
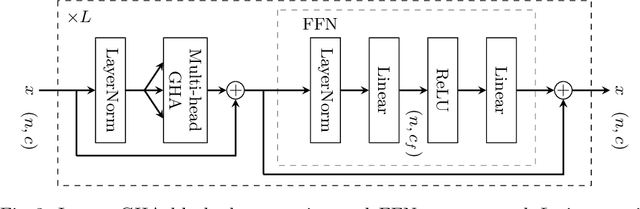
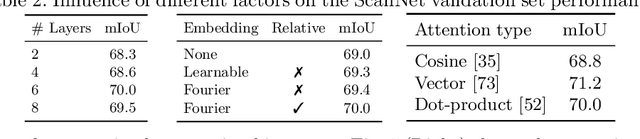
We propose a new attention mechanism, called Global Hierarchical Attention (GHA), for 3D point cloud analysis. GHA approximates the regular global dot-product attention via a series of coarsening and interpolation operations over multiple hierarchy levels. The advantage of GHA is two-fold. First, it has linear complexity with respect to the number of points, enabling the processing of large point clouds. Second, GHA inherently possesses the inductive bias to focus on spatially close points, while retaining the global connectivity among all points. Combined with a feedforward network, GHA can be inserted into many existing network architectures. We experiment with multiple baseline networks and show that adding GHA consistently improves performance across different tasks and datasets. For the task of semantic segmentation, GHA gives a +1.7% mIoU increase to the MinkowskiEngine baseline on ScanNet. For the 3D object detection task, GHA improves the CenterPoint baseline by +0.5% mAP on the nuScenes dataset, and the 3DETR baseline by +2.1% mAP25 and +1.5% mAP50 on ScanNet.
Pedestrian-Robot Interactions on Autonomous Crowd Navigation: Reactive Control Methods and Evaluation Metrics
Aug 03, 2022
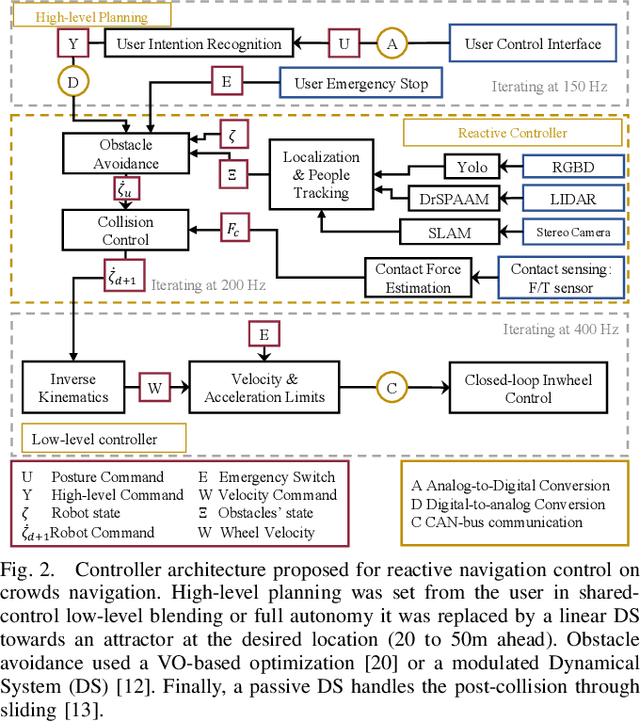
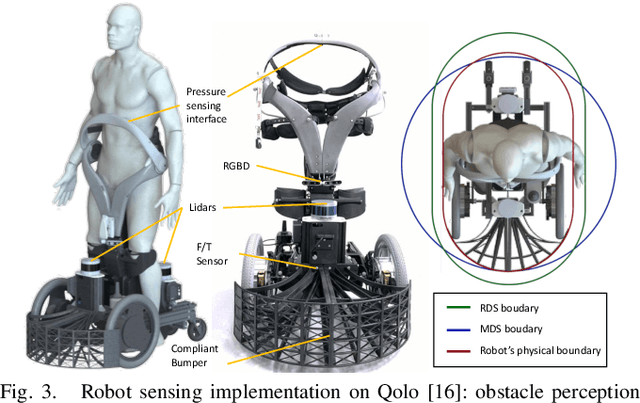
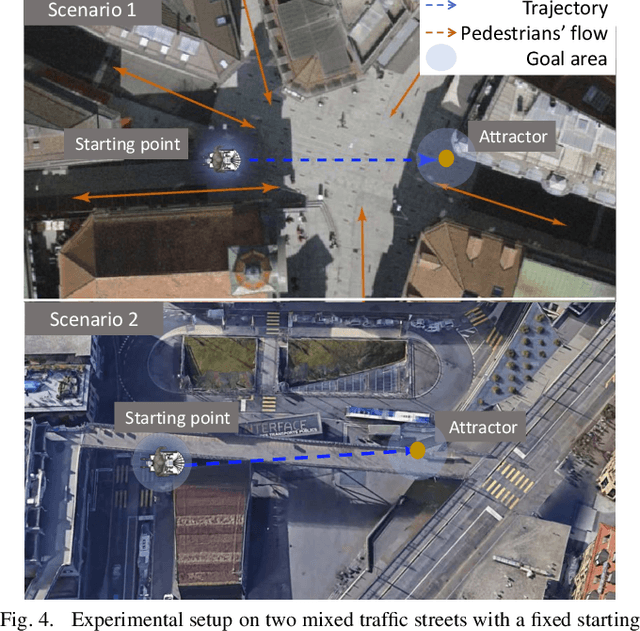
Autonomous navigation in highly populated areas remains a challenging task for robots because of the difficulty in guaranteeing safe interactions with pedestrians in unstructured situations. In this work, we present a crowd navigation control framework that delivers continuous obstacle avoidance and post-contact control evaluated on an autonomous personal mobility vehicle. We propose evaluation metrics for accounting efficiency, controller response and crowd interactions in natural crowds. We report the results of over 110 trials in different crowd types: sparse, flows, and mixed traffic, with low- (< 0.15 ppsm), mid- (< 0.65 ppsm), and high- (< 1 ppsm) pedestrian densities. We present comparative results between two low-level obstacle avoidance methods and a baseline of shared control. Results show a 10% drop in relative time to goal on the highest density tests, and no other efficiency metric decrease. Moreover, autonomous navigation showed to be comparable to shared-control navigation with a lower relative jerk and significantly higher fluency in commands indicating high compatibility with the crowd. We conclude that the reactive controller fulfils a necessary task of fast and continuous adaptation to crowd navigation, and it should be coupled with high-level planners for environmental and situational awareness.
* \c{opyright}IEEE All rights reserved. IEEE-IROS-2022, Oct.23-27. Kyoto, Japan
Differentiable Soft-Masked Attention
Jun 01, 2022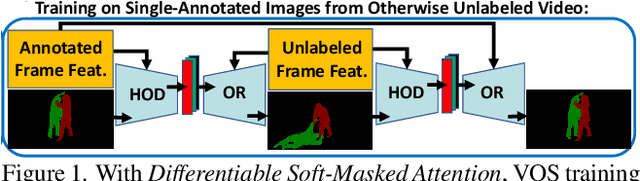

Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the 'cross-attention' operation, which allows a vector representation (e.g. of an object in an image) to be learned by attending to an arbitrarily sized set of input features. Recently, "Masked Attention" was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over `soft-masks' (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our "Differentiable Soft-Masked Attention" for the task of Weakly-Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.
HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
Dec 16, 2021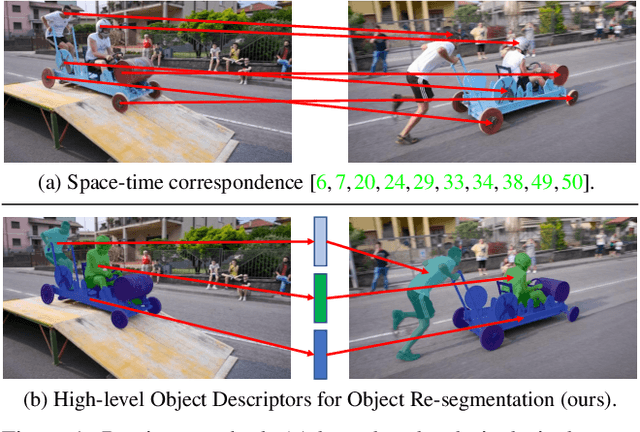
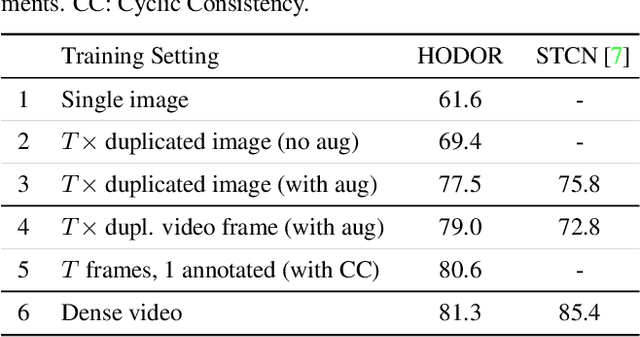

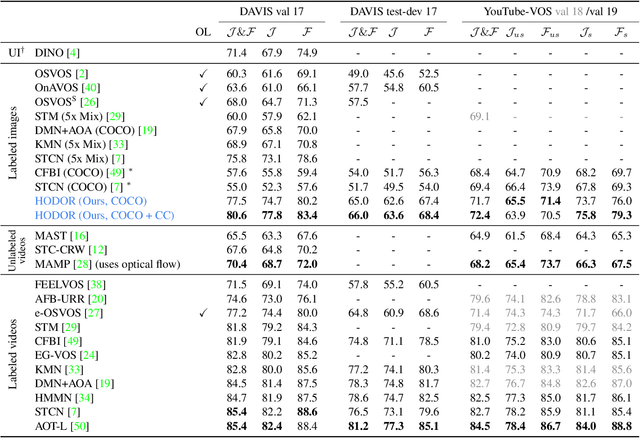
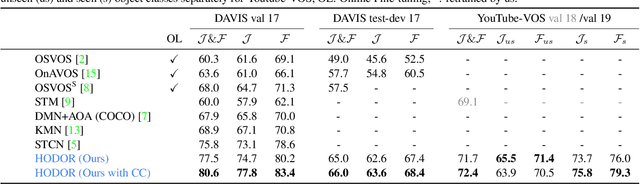
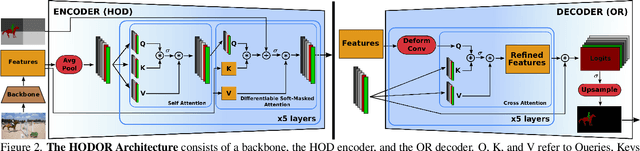
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.
D^2Conv3D: Dynamic Dilated Convolutions for Object Segmentation in Videos
Nov 15, 2021
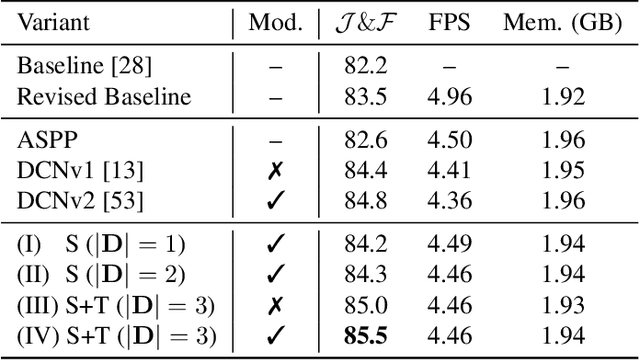

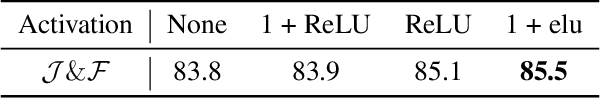
Despite receiving significant attention from the research community, the task of segmenting and tracking objects in monocular videos still has much room for improvement. Existing works have simultaneously justified the efficacy of dilated and deformable convolutions for various image-level segmentation tasks. This gives reason to believe that 3D extensions of such convolutions should also yield performance improvements for video-level segmentation tasks. However, this aspect has not yet been explored thoroughly in existing literature. In this paper, we propose Dynamic Dilated Convolutions (D^2Conv3D): a novel type of convolution which draws inspiration from dilated and deformable convolutions and extends them to the 3D (spatio-temporal) domain. We experimentally show that D^2Conv3D can be used to improve the performance of multiple 3D CNN architectures across multiple video segmentation related benchmarks by simply employing D^2Conv3D as a drop-in replacement for standard convolutions. We further show that D^2Conv3D out-performs trivial extensions of existing dilated and deformable convolutions to 3D. Lastly, we set a new state-of-the-art on the DAVIS 2016 Unsupervised Video Object Segmentation benchmark. Code is made publicly available at https://github.com/Schmiddo/d2conv3d .
Mix3D: Out-of-Context Data Augmentation for 3D Scenes
Oct 05, 2021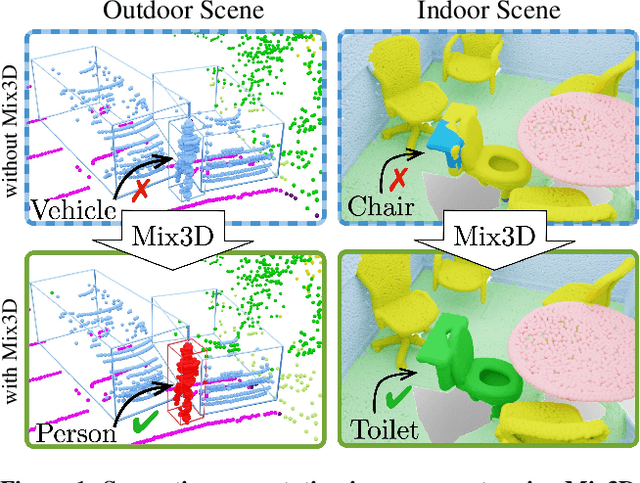
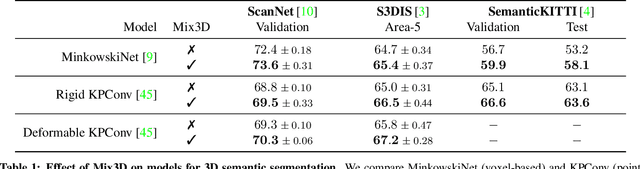


We present Mix3D, a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well. We perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU. Code is available at: https://nekrasov.dev/mix3d/
Person-MinkUNet: 3D Person Detection with LiDAR Point Cloud
Jul 03, 2021In this preliminary work we attempt to apply submanifold sparse convolution to the task of 3D person detection. In particular, we present Person-MinkUNet, a single-stage 3D person detection network based on Minkowski Engine with U-Net architecture. The network achieves a 76.4% average precision (AP) on the JRDB 3D detection benchmark.
Domain and Modality Gaps for LiDAR-based Person Detection on Mobile Robots
Jun 21, 2021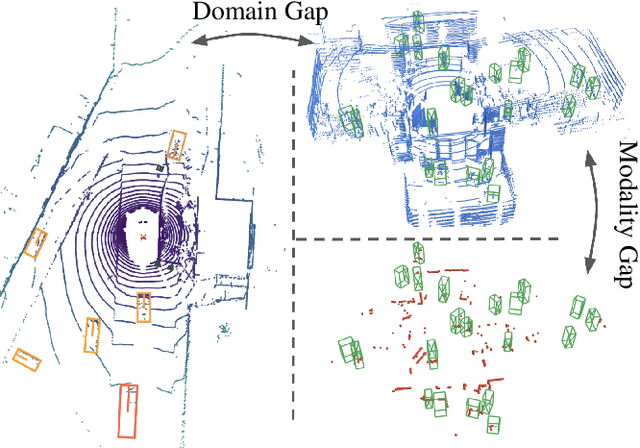
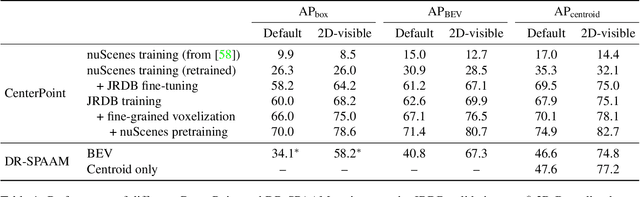
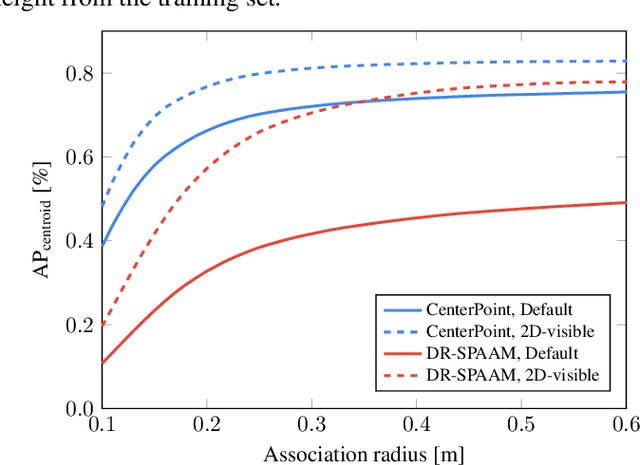

Person detection is a crucial task for mobile robots navigating in human-populated environments and LiDAR sensors are promising for this task, given their accurate depth measurements and large field of view. This paper studies existing LiDAR-based person detectors with a particular focus on mobile robot scenarios (e.g. service robot or social robot), where persons are observed more frequently and in much closer ranges, compared to the driving scenarios. We conduct a series of experiments, using the recently released JackRabbot dataset and the state-of-the-art detectors based on 3D or 2D LiDAR sensors (CenterPoint and DR-SPAAM respectively). These experiments revolve around the domain gap between driving and mobile robot scenarios, as well as the modality gap between 3D and 2D LiDAR sensors. For the domain gap, we aim to understand if detectors pretrained on driving datasets can achieve good performance on the mobile robot scenarios, for which there are currently no trained models readily available. For the modality gap, we compare detectors that use 3D or 2D LiDAR, from various aspects, including performance, runtime, localization accuracy, robustness to range and crowdedness. The results from our experiments provide practical insights into LiDAR-based person detection and facilitate informed decisions for relevant mobile robot designs and applications.
Opening up Open-World Tracking
Apr 22, 2021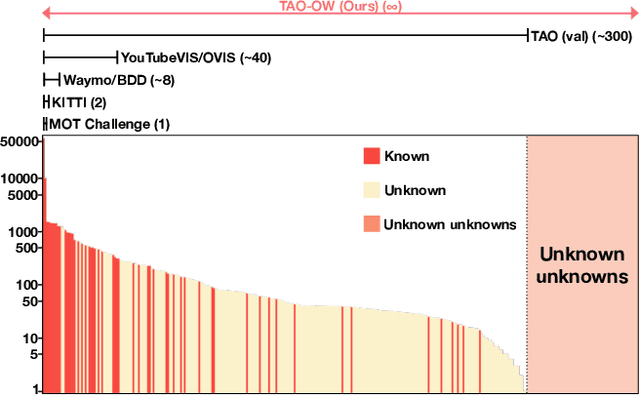


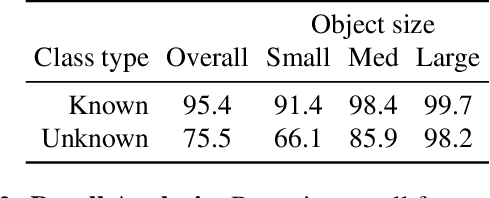
In this paper, we propose and study Open-World Tracking (OWT). Open-world tracking goes beyond current multi-object tracking benchmarks and methods which focus on tracking object classes that belong to a predefined closed-set of frequently observed object classes. In OWT, we relax this assumption: we may encounter objects at inference time that were not labeled for training. The main contribution of this paper is the formalization of the OWT task, along with an evaluation protocol and metric (Open-World Tracking Accuracy, OWTA), which decomposes into two intuitive terms, one for measuring recall, and another for measuring track association accuracy. This allows us to perform a rigorous evaluation of several different baselines that follow design patterns proposed in the multi-object tracking community. Further we show that our Open-World Tracking Baseline, while performing well in the OWT setting, also achieves near state-of-the-art results on traditional closed-world benchmarks, without any adjustments or tuning. We believe that this paper is an initial step towards studying multi-object tracking in the open world, a task of crucial importance for future intelligent agents that will need to understand, react to, and learn from, an infinite variety of objects that can appear in an open world.
STEP: Segmenting and Tracking Every Pixel
Feb 23, 2021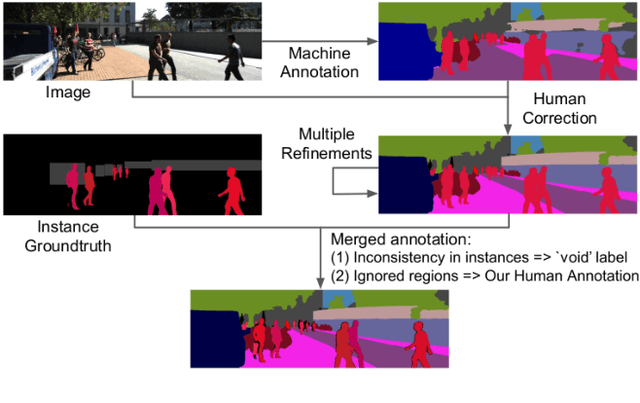
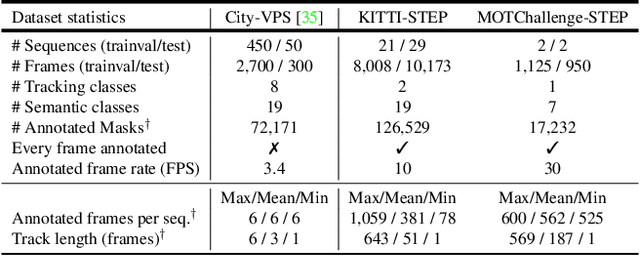


In this paper, we tackle video panoptic segmentation, a task that requires assigning semantic classes and track identities to all pixels in a video. To study this important problem in a setting that requires a continuous interpretation of sensory data, we present a new benchmark: Segmenting and Tracking Every Pixel (STEP), encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP together with a new evaluation metric. Our work is the first that targets this task in a real-world setting that requires dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. By contrast, our datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking. For measuring the performance, we propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is suitable for evaluating sequences of arbitrary length. We will make our datasets, metric, and baselines publicly available.