 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Optimize Permutation Flow Shop Scheduling via Graph-based Imitation Learning
Oct 31, 2022



The permutation flow shop scheduling (PFSS), aiming at finding the optimal permutation of jobs, is widely used in manufacturing systems. When solving the large-scale PFSS problems, traditional optimization algorithms such as heuristics could hardly meet the demands of both solution accuracy and computational efficiency. Thus learning-based methods have recently garnered more attention. Some work attempts to solve the problems by reinforcement learning methods, which suffer from slow convergence issues during training and are still not accurate enough regarding the solutions. To that end, we train the model via expert-driven imitation learning, which accelerates the convergence more stably and accurately. Moreover, in order to extract better feature representations of input jobs, we incorporate the graph structure as the encoder. The extensive experiments reveal that our proposed model obtains significant promotion and presents excellent generalizability in large-scale problems with up to 1000 jobs. Compared to the state-of-the-art reinforcement learning method, our model's network parameters are reduced to only 37\% of theirs, and the solution gap of our model towards the expert solutions decreases from 6.8\% to 1.3\% on average.
Boosting the Transferability of Adversarial Attacks with Reverse Adversarial Perturbation
Oct 12, 2022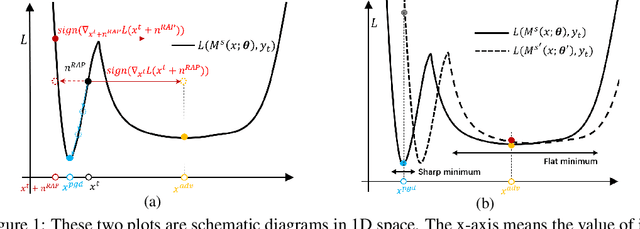
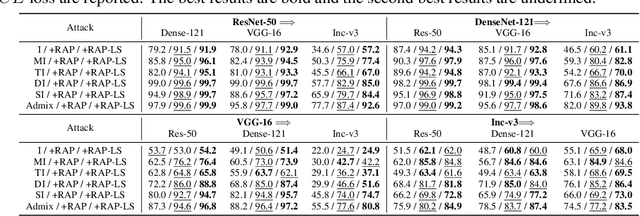
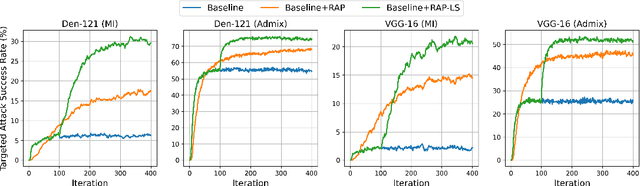
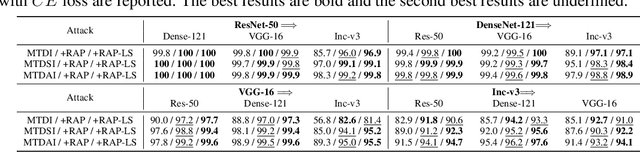
Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples, which can produce erroneous predictions by injecting imperceptible perturbations. In this work, we study the transferability of adversarial examples, which is significant due to its threat to real-world applications where model architecture or parameters are usually unknown. Many existing works reveal that the adversarial examples are likely to overfit the surrogate model that they are generated from, limiting its transfer attack performance against different target models. To mitigate the overfitting of the surrogate model, we propose a novel attack method, dubbed reverse adversarial perturbation (RAP). Specifically, instead of minimizing the loss of a single adversarial point, we advocate seeking adversarial example located at a region with unified low loss value, by injecting the worst-case perturbation (the reverse adversarial perturbation) for each step of the optimization procedure. The adversarial attack with RAP is formulated as a min-max bi-level optimization problem. By integrating RAP into the iterative process for attacks, our method can find more stable adversarial examples which are less sensitive to the changes of decision boundary, mitigating the overfitting of the surrogate model. Comprehensive experimental comparisons demonstrate that RAP can significantly boost adversarial transferability. Furthermore, RAP can be naturally combined with many existing black-box attack techniques, to further boost the transferability. When attacking a real-world image recognition system, Google Cloud Vision API, we obtain 22% performance improvement of targeted attacks over the compared method. Our codes are available at https://github.com/SCLBD/Transfer_attack_RAP.
Adaptive Smoothness-weighted Adversarial Training for Multiple Perturbations with Its Stability Analysis
Oct 02, 2022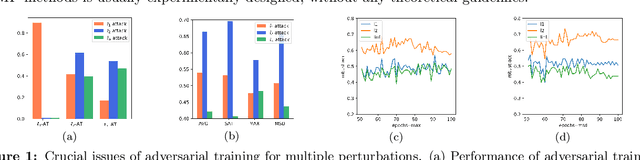
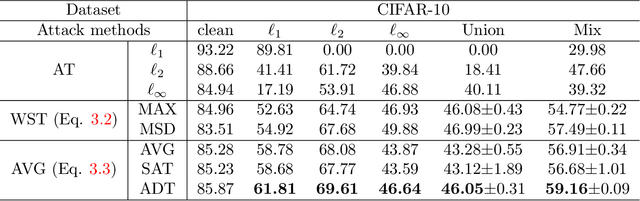
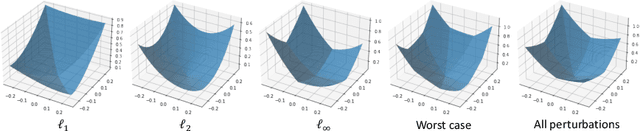
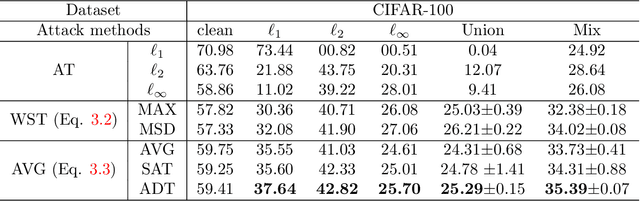
Adversarial Training (AT) has been demonstrated as one of the most effective methods against adversarial examples. While most existing works focus on AT with a single type of perturbation e.g., the $\ell_\infty$ attacks), DNNs are facing threats from different types of adversarial examples. Therefore, adversarial training for multiple perturbations (ATMP) is proposed to generalize the adversarial robustness over different perturbation types (in $\ell_1$, $\ell_2$, and $\ell_\infty$ norm-bounded perturbations). However, the resulting model exhibits trade-off between different attacks. Meanwhile, there is no theoretical analysis of ATMP, limiting its further development. In this paper, we first provide the smoothness analysis of ATMP and show that $\ell_1$, $\ell_2$, and $\ell_\infty$ adversaries give different contributions to the smoothness of the loss function of ATMP. Based on this, we develop the stability-based excess risk bounds and propose adaptive smoothness-weighted adversarial training for multiple perturbations. Theoretically, our algorithm yields better bounds. Empirically, our experiments on CIFAR10 and CIFAR100 achieve the state-of-the-art performance against the mixture of multiple perturbations attacks.
A Large-scale Multiple-objective Method for Black-box Attack against Object Detection
Sep 16, 2022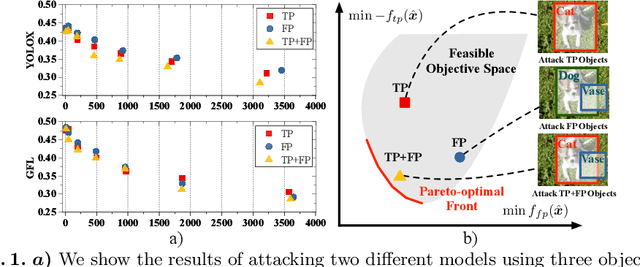
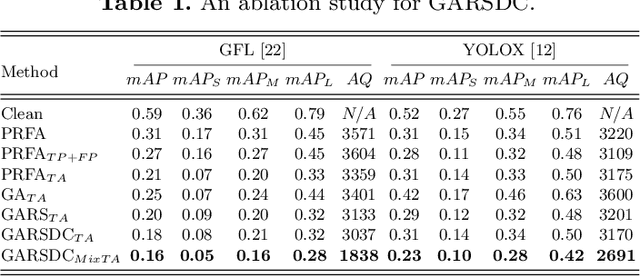
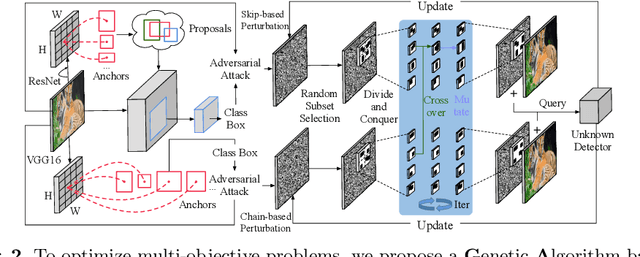
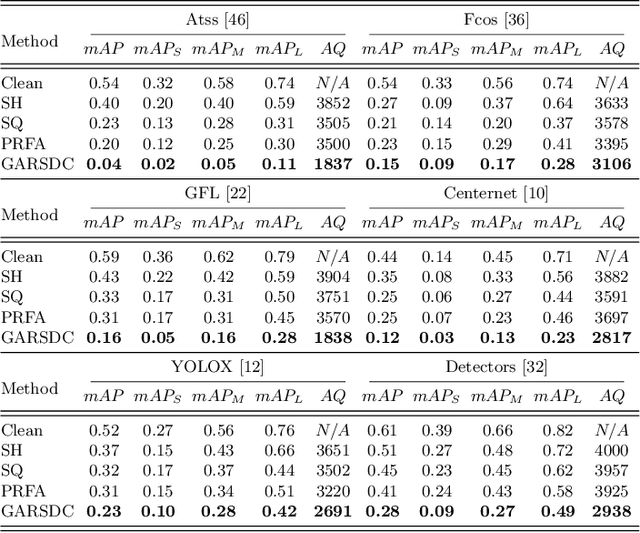
Recent studies have shown that detectors based on deep models are vulnerable to adversarial examples, even in the black-box scenario where the attacker cannot access the model information. Most existing attack methods aim to minimize the true positive rate, which often shows poor attack performance, as another sub-optimal bounding box may be detected around the attacked bounding box to be the new true positive one. To settle this challenge, we propose to minimize the true positive rate and maximize the false positive rate, which can encourage more false positive objects to block the generation of new true positive bounding boxes. It is modeled as a multi-objective optimization (MOP) problem, of which the generic algorithm can search the Pareto-optimal. However, our task has more than two million decision variables, leading to low searching efficiency. Thus, we extend the standard Genetic Algorithm with Random Subset selection and Divide-and-Conquer, called GARSDC, which significantly improves the efficiency. Moreover, to alleviate the sensitivity to population quality in generic algorithms, we generate a gradient-prior initial population, utilizing the transferability between different detectors with similar backbones. Compared with the state-of-art attack methods, GARSDC decreases by an average 12.0 in the mAP and queries by about 1000 times in extensive experiments. Our codes can be found at https://github.com/LiangSiyuan21/ GARSDC.
Imperceptible and Robust Backdoor Attack in 3D Point Cloud
Aug 17, 2022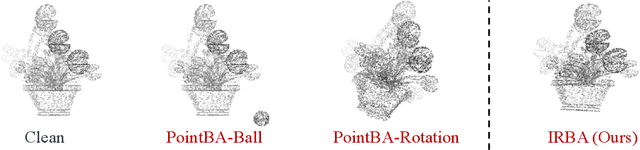
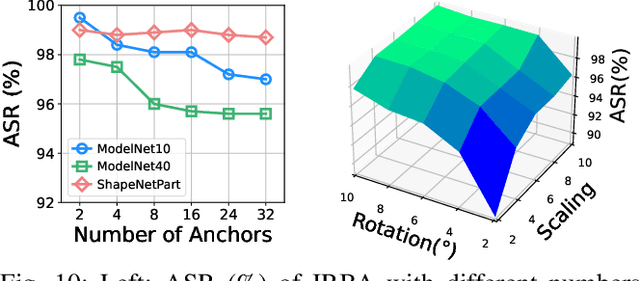
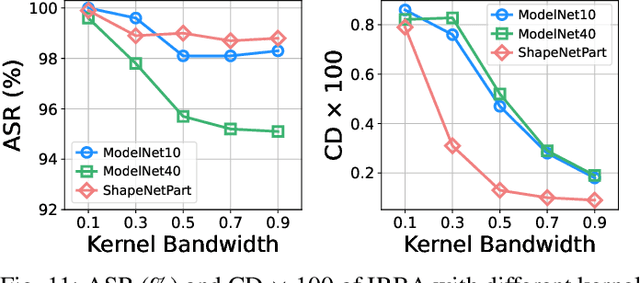
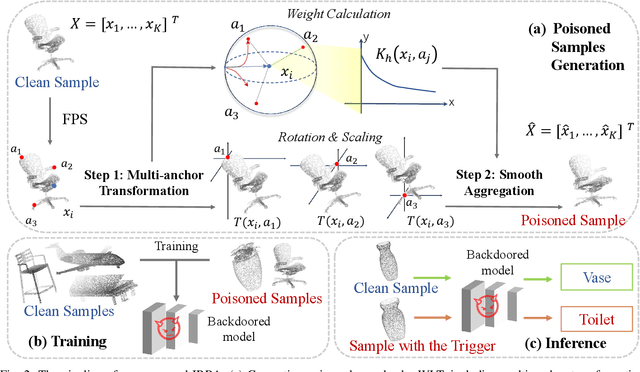
With the thriving of deep learning in processing point cloud data, recent works show that backdoor attacks pose a severe security threat to 3D vision applications. The attacker injects the backdoor into the 3D model by poisoning a few training samples with trigger, such that the backdoored model performs well on clean samples but behaves maliciously when the trigger pattern appears. Existing attacks often insert some additional points into the point cloud as the trigger, or utilize a linear transformation (e.g., rotation) to construct the poisoned point cloud. However, the effects of these poisoned samples are likely to be weakened or even eliminated by some commonly used pre-processing techniques for 3D point cloud, e.g., outlier removal or rotation augmentation. In this paper, we propose a novel imperceptible and robust backdoor attack (IRBA) to tackle this challenge. We utilize a nonlinear and local transformation, called weighted local transformation (WLT), to construct poisoned samples with unique transformations. As there are several hyper-parameters and randomness in WLT, it is difficult to produce two similar transformations. Consequently, poisoned samples with unique transformations are likely to be resistant to aforementioned pre-processing techniques. Besides, as the controllability and smoothness of the distortion caused by a fixed WLT, the generated poisoned samples are also imperceptible to human inspection. Extensive experiments on three benchmark datasets and four models show that IRBA achieves 80%+ ASR in most cases even with pre-processing techniques, which is significantly higher than previous state-of-the-art attacks.
Versatile Weight Attack via Flipping Limited Bits
Jul 25, 2022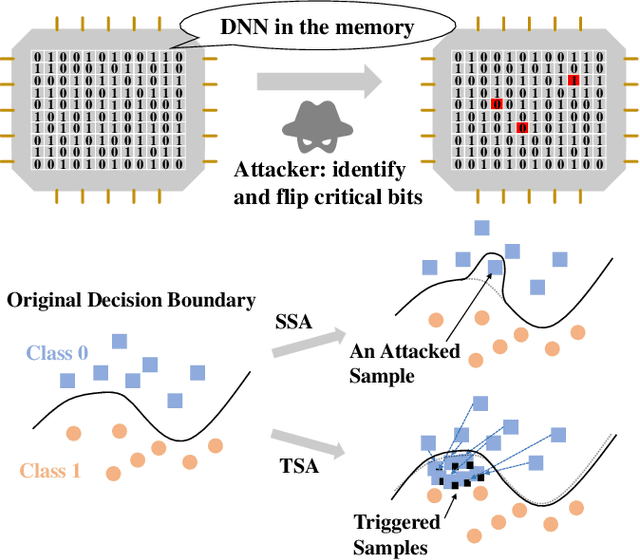
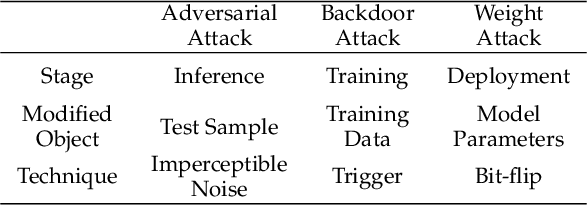
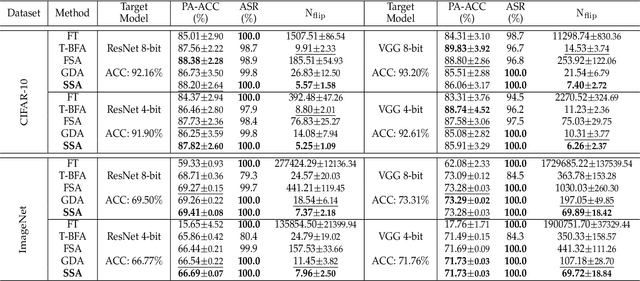
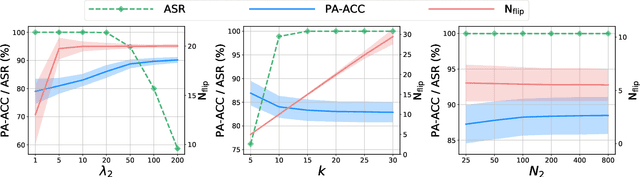
To explore the vulnerability of deep neural networks (DNNs), many attack paradigms have been well studied, such as the poisoning-based backdoor attack in the training stage and the adversarial attack in the inference stage. In this paper, we study a novel attack paradigm, which modifies model parameters in the deployment stage. Considering the effectiveness and stealthiness goals, we provide a general formulation to perform the bit-flip based weight attack, where the effectiveness term could be customized depending on the attacker's purpose. Furthermore, we present two cases of the general formulation with different malicious purposes, i.e., single sample attack (SSA) and triggered samples attack (TSA). To this end, we formulate this problem as a mixed integer programming (MIP) to jointly determine the state of the binary bits (0 or 1) in the memory and learn the sample modification. Utilizing the latest technique in integer programming, we equivalently reformulate this MIP problem as a continuous optimization problem, which can be effectively and efficiently solved using the alternating direction method of multipliers (ADMM) method. Consequently, the flipped critical bits can be easily determined through optimization, rather than using a heuristic strategy. Extensive experiments demonstrate the superiority of SSA and TSA in attacking DNNs.
Prior-Guided Adversarial Initialization for Fast Adversarial Training
Jul 18, 2022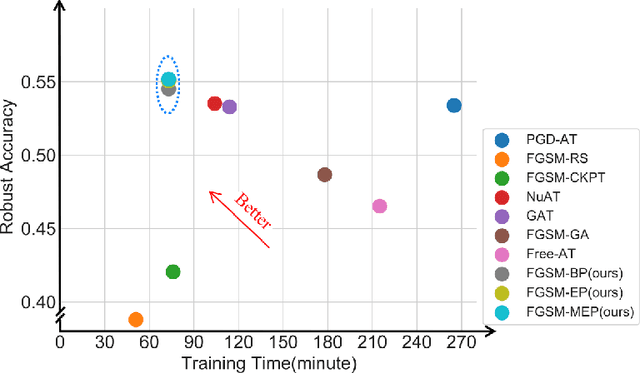
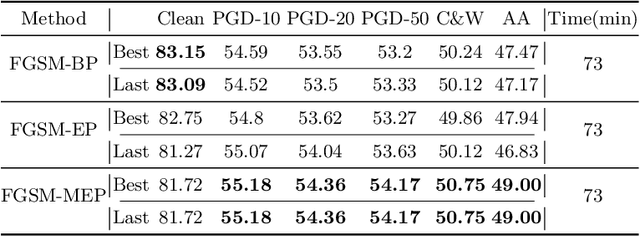
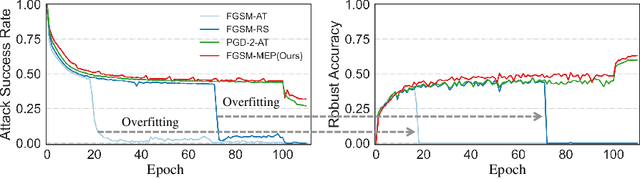
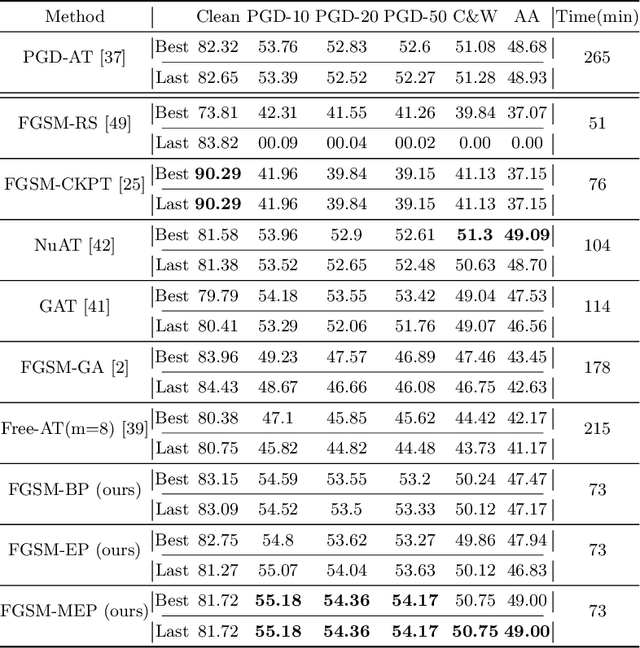
Fast adversarial training (FAT) effectively improves the efficiency of standard adversarial training (SAT). However, initial FAT encounters catastrophic overfitting, i.e.,the robust accuracy against adversarial attacks suddenly and dramatically decreases. Though several FAT variants spare no effort to prevent overfitting, they sacrifice much calculation cost. In this paper, we explore the difference between the training processes of SAT and FAT and observe that the attack success rate of adversarial examples (AEs) of FAT gets worse gradually in the late training stage, resulting in overfitting. The AEs are generated by the fast gradient sign method (FGSM) with a zero or random initialization. Based on the observation, we propose a prior-guided FGSM initialization method to avoid overfitting after investigating several initialization strategies, improving the quality of the AEs during the whole training process. The initialization is formed by leveraging historically generated AEs without additional calculation cost. We further provide a theoretical analysis for the proposed initialization method. We also propose a simple yet effective regularizer based on the prior-guided initialization,i.e., the currently generated perturbation should not deviate too much from the prior-guided initialization. The regularizer adopts both historical and current adversarial perturbations to guide the model learning. Evaluations on four datasets demonstrate that the proposed method can prevent catastrophic overfitting and outperform state-of-the-art FAT methods. The code is released at https://github.com/jiaxiaojunQAQ/FGSM-PGI.
* ECCV 2022
Learning to Accelerate Approximate Methods for Solving Integer Programming via Early Fixing
Jul 05, 2022
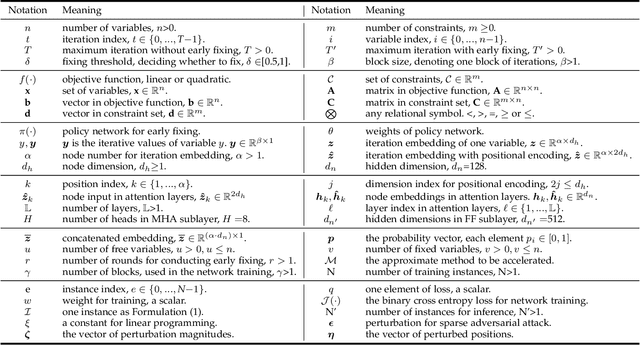
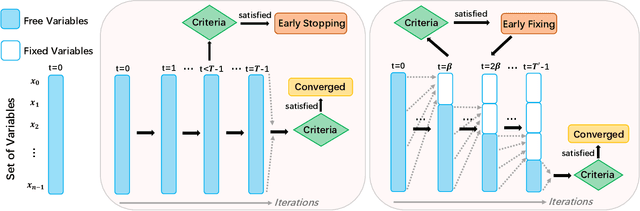

Integer programming (IP) is an important and challenging problem. Approximate methods have shown promising performance on both effectiveness and efficiency for solving the IP problem. However, we observed that a large fraction of variables solved by some iterative approximate methods fluctuate around their final converged discrete states in very long iterations. Inspired by this observation, we aim to accelerate these approximate methods by early fixing these fluctuated variables to their converged states while not significantly harming the solution accuracy. To this end, we propose an early fixing framework along with the approximate method. We formulate the whole early fixing process as a Markov decision process, and train it using imitation learning. A policy network will evaluate the posterior probability of each free variable concerning its discrete candidate states in each block of iterations. Specifically, we adopt the powerful multi-headed attention mechanism in the policy network. Extensive experiments on our proposed early fixing framework are conducted to three different IP applications: constrained linear programming, MRF energy minimization and sparse adversarial attack. The former one is linear IP problem, while the latter two are quadratic IP problems. We extend the problem scale from regular size to significantly large size. The extensive experiments reveal the competitiveness of our early fixing framework: the runtime speeds up significantly, while the solution quality does not degrade much, even in some cases it is available to obtain better solutions. Our proposed early fixing framework can be regarded as an acceleration extension of ADMM methods for solving integer programming. The source codes are available at \url{https://github.com/SCLBD/Accelerated-Lpbox-ADMM}.
BackdoorBench: A Comprehensive Benchmark of Backdoor Learning
Jun 25, 2022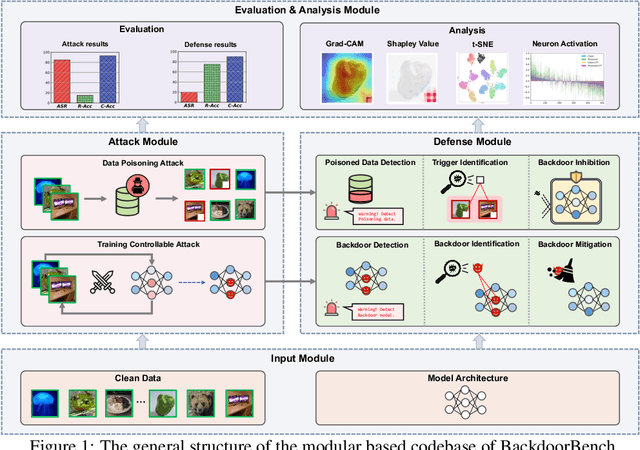
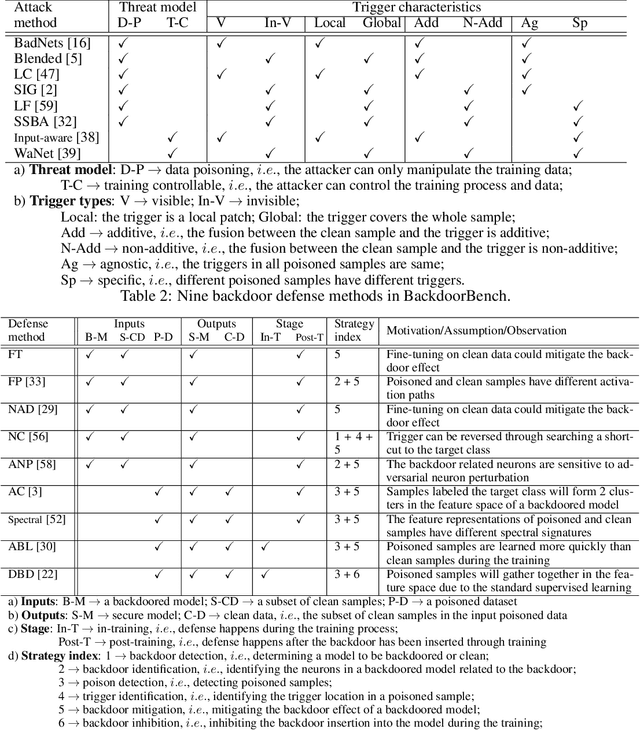
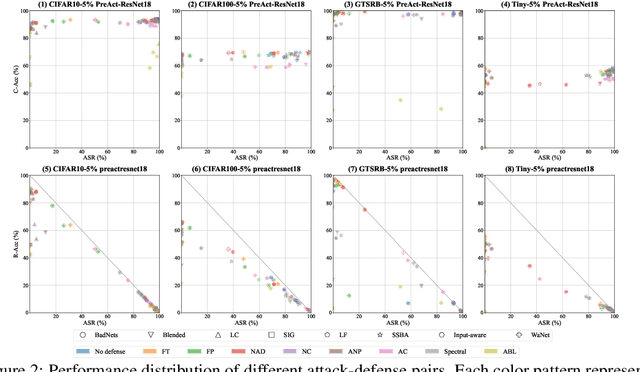

Backdoor learning is an emerging and important topic of studying the vulnerability of deep neural networks (DNNs). Many pioneering backdoor attack and defense methods are being proposed successively or concurrently, in the status of a rapid arms race. However, we find that the evaluations of new methods are often unthorough to verify their claims and real performance, mainly due to the rapid development, diverse settings, as well as the difficulties of implementation and reproducibility. Without thorough evaluations and comparisons, it is difficult to track the current progress and design the future development roadmap of the literature. To alleviate this dilemma, we build a comprehensive benchmark of backdoor learning, called BackdoorBench. It consists of an extensible modular based codebase (currently including implementations of 8 state-of-the-art (SOTA) attack and 9 SOTA defense algorithms), as well as a standardized protocol of a complete backdoor learning. We also provide comprehensive evaluations of every pair of 8 attacks against 9 defenses, with 5 poisoning ratios, based on 5 models and 4 datasets, thus 8,000 pairs of evaluations in total. We further present analysis from different perspectives about these 8,000 evaluations, studying the effects of attack against defense algorithms, poisoning ratio, model and dataset in backdoor learning. All codes and evaluations of BackdoorBench are publicly available at \url{https://backdoorbench.github.io}.
A Survey of Trustworthy Graph Learning: Reliability, Explainability, and Privacy Protection
May 23, 2022


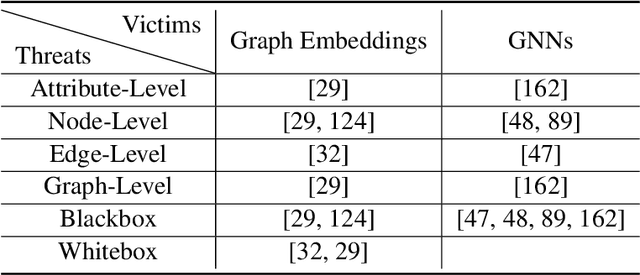
Deep graph learning has achieved remarkable progresses in both business and scientific areas ranging from finance and e-commerce, to drug and advanced material discovery. Despite these progresses, how to ensure various deep graph learning algorithms behave in a socially responsible manner and meet regulatory compliance requirements becomes an emerging problem, especially in risk-sensitive domains. Trustworthy graph learning (TwGL) aims to solve the above problems from a technical viewpoint. In contrast to conventional graph learning research which mainly cares about model performance, TwGL considers various reliability and safety aspects of the graph learning framework including but not limited to robustness, explainability, and privacy. In this survey, we provide a comprehensive review of recent leading approaches in the TwGL field from three dimensions, namely, reliability, explainability, and privacy protection. We give a general categorization for existing work and review typical work for each category. To give further insights for TwGL research, we provide a unified view to inspect previous works and build the connection between them. We also point out some important open problems remaining to be solved in the future developments of TwGL.