 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Gradient Fields for Scalable and Generalizable Irregular Packing
Oct 18, 2023



The packing problem, also known as cutting or nesting, has diverse applications in logistics, manufacturing, layout design, and atlas generation. It involves arranging irregularly shaped pieces to minimize waste while avoiding overlap. Recent advances in machine learning, particularly reinforcement learning, have shown promise in addressing the packing problem. In this work, we delve deeper into a novel machine learning-based approach that formulates the packing problem as conditional generative modeling. To tackle the challenges of irregular packing, including object validity constraints and collision avoidance, our method employs the score-based diffusion model to learn a series of gradient fields. These gradient fields encode the correlations between constraint satisfaction and the spatial relationships of polygons, learned from teacher examples. During the testing phase, packing solutions are generated using a coarse-to-fine refinement mechanism guided by the learned gradient fields. To enhance packing feasibility and optimality, we introduce two key architectural designs: multi-scale feature extraction and coarse-to-fine relation extraction. We conduct experiments on two typical industrial packing domains, considering translations only. Empirically, our approach demonstrates spatial utilization rates comparable to, or even surpassing, those achieved by the teacher algorithm responsible for training data generation. Additionally, it exhibits some level of generalization to shape variations. We are hopeful that this method could pave the way for new possibilities in solving the packing problem.
MoConVQ: Unified Physics-Based Motion Control via Scalable Discrete Representations
Oct 17, 2023In this work, we present MoConVQ, a novel unified framework for physics-based motion control leveraging scalable discrete representations. Building upon vector quantized variational autoencoders (VQ-VAE) and model-based reinforcement learning, our approach effectively learns motion embeddings from a large, unstructured dataset spanning tens of hours of motion examples. The resultant motion representation not only captures diverse motion skills but also offers a robust and intuitive interface for various applications. We demonstrate the versatility of MoConVQ through several applications: universal tracking control from various motion sources, interactive character control with latent motion representations using supervised learning, physics-based motion generation from natural language descriptions using the GPT framework, and, most interestingly, seamless integration with large language models (LLMs) with in-context learning to tackle complex and abstract tasks.
Lazy Visual Localization via Motion Averaging
Jul 19, 2023



Visual (re)localization is critical for various applications in computer vision and robotics. Its goal is to estimate the 6 degrees of freedom (DoF) camera pose for each query image, based on a set of posed database images. Currently, all leading solutions are structure-based that either explicitly construct 3D metric maps from the database with structure-from-motion, or implicitly encode the 3D information with scene coordinate regression models. On the contrary, visual localization without reconstructing the scene in 3D offers clear benefits. It makes deployment more convenient by reducing database pre-processing time, releasing storage requirements, and remaining unaffected by imperfect reconstruction, etc. In this technical report, we demonstrate that it is possible to achieve high localization accuracy without reconstructing the scene from the database. The key to achieving this owes to a tailored motion averaging over database-query pairs. Experiments show that our visual localization proposal, LazyLoc, achieves comparable performance against state-of-the-art structure-based methods. Furthermore, we showcase the versatility of LazyLoc, which can be easily extended to handle complex configurations such as multi-query co-localization and camera rigs.
Example-based Motion Synthesis via Generative Motion Matching
Jun 01, 2023



We present GenMM, a generative model that "mines" as many diverse motions as possible from a single or few example sequences. In stark contrast to existing data-driven methods, which typically require long offline training time, are prone to visual artifacts, and tend to fail on large and complex skeletons, GenMM inherits the training-free nature and the superior quality of the well-known Motion Matching method. GenMM can synthesize a high-quality motion within a fraction of a second, even with highly complex and large skeletal structures. At the heart of our generative framework lies the generative motion matching module, which utilizes the bidirectional visual similarity as a generative cost function to motion matching, and operates in a multi-stage framework to progressively refine a random guess using exemplar motion matches. In addition to diverse motion generation, we show the versatility of our generative framework by extending it to a number of scenarios that are not possible with motion matching alone, including motion completion, key frame-guided generation, infinite looping, and motion reassembly. Code and data for this paper are at https://wyysf-98.github.io/GenMM/
Towards Robust Probabilistic Modeling on SO(3) via Rotation Laplace Distribution
May 17, 2023



Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. As a popular approach, probabilistic rotation modeling additionally carries prediction uncertainty information, compared to single-prediction rotation regression. For modeling probabilistic distribution over SO(3), it is natural to use Gaussian-like Bingham distribution and matrix Fisher, however they are shown to be sensitive to outlier predictions, e.g. $180^\circ$ error and thus are unlikely to converge with optimal performance. In this paper, we draw inspiration from multivariate Laplace distribution and propose a novel rotation Laplace distribution on SO(3). Our rotation Laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low-error region that it can improve. In addition, we show that our method also exhibits robustness to small noises and thus tolerates imperfect annotations. With this benefit, we demonstrate its advantages in semi-supervised rotation regression, where the pseudo labels are noisy. To further capture the multi-modal rotation solution space for symmetric objects, we extend our distribution to rotation Laplace mixture model and demonstrate its effectiveness. Our extensive experiments show that our proposed distribution and the mixture model achieve state-of-the-art performance in all the rotation regression experiments over both probabilistic and non-probabilistic baselines.
Patch-based 3D Natural Scene Generation from a Single Example
Apr 26, 2023We target a 3D generative model for general natural scenes that are typically unique and intricate. Lacking the necessary volumes of training data, along with the difficulties of having ad hoc designs in presence of varying scene characteristics, renders existing setups intractable. Inspired by classical patch-based image models, we advocate for synthesizing 3D scenes at the patch level, given a single example. At the core of this work lies important algorithmic designs w.r.t the scene representation and generative patch nearest-neighbor module, that address unique challenges arising from lifting classical 2D patch-based framework to 3D generation. These design choices, on a collective level, contribute to a robust, effective, and efficient model that can generate high-quality general natural scenes with both realistic geometric structure and visual appearance, in large quantities and varieties, as demonstrated upon a variety of exemplar scenes.
Learning Controllable 3D Diffusion Models from Single-view Images
Apr 13, 2023



Diffusion models have recently become the de-facto approach for generative modeling in the 2D domain. However, extending diffusion models to 3D is challenging due to the difficulties in acquiring 3D ground truth data for training. On the other hand, 3D GANs that integrate implicit 3D representations into GANs have shown remarkable 3D-aware generation when trained only on single-view image datasets. However, 3D GANs do not provide straightforward ways to precisely control image synthesis. To address these challenges, We present Control3Diff, a 3D diffusion model that combines the strengths of diffusion models and 3D GANs for versatile, controllable 3D-aware image synthesis for single-view datasets. Control3Diff explicitly models the underlying latent distribution (optionally conditioned on external inputs), thus enabling direct control during the diffusion process. Moreover, our approach is general and applicable to any type of controlling input, allowing us to train it with the same diffusion objective without any auxiliary supervision. We validate the efficacy of Control3Diff on standard image generation benchmarks, including FFHQ, AFHQ, and ShapeNet, using various conditioning inputs such as images, sketches, and text prompts. Please see the project website (\url{https://jiataogu.me/control3diff}) for video comparisons.
Delving into Discrete Normalizing Flows on SO Manifold for Probabilistic Rotation Modeling
Apr 08, 2023Normalizing flows (NFs) provide a powerful tool to construct an expressive distribution by a sequence of trackable transformations of a base distribution and form a probabilistic model of underlying data. Rotation, as an important quantity in computer vision, graphics, and robotics, can exhibit many ambiguities when occlusion and symmetry occur and thus demands such probabilistic models. Though much progress has been made for NFs in Euclidean space, there are no effective normalizing flows without discontinuity or many-to-one mapping tailored for SO(3) manifold. Given the unique non-Euclidean properties of the rotation manifold, adapting the existing NFs to SO(3) manifold is non-trivial. In this paper, we propose a novel normalizing flow on SO(3) by combining a Mobius transformation-based coupling layer and a quaternion affine transformation. With our proposed rotation normalizing flows, one can not only effectively express arbitrary distributions on SO(3), but also conditionally build the target distribution given input observations. Extensive experiments show that our rotation normalizing flows significantly outperform the baselines on both unconditional and conditional tasks.
A Laplace-inspired Distribution on SO for Probabilistic Rotation Estimation
Mar 03, 2023Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. Probabilistic rotation regression has raised more and more attention with the benefit of expressing uncertainty information along with the prediction. Though modeling noise using Gaussian-resembling Bingham distribution and matrix Fisher distribution is natural, they are shown to be sensitive to outliers for the nature of quadratic punishment to deviations. In this paper, we draw inspiration from multivariate Laplace distribution and propose a novel Rotation Laplace distribution on SO(3). Rotation Laplace distribution is robust to the disturbance of outliers and enforces much gradient to the low-error region, resulting in a better convergence. Our extensive experiments show that our proposed distribution achieves state-of-the-art performance for rotation regression tasks over both probabilistic and non-probabilistic baselines. Our project page is at https://pku-epic.github.io/RotationLaplace.
ControlVAE: Model-Based Learning of Generative Controllers for Physics-Based Characters
Oct 12, 2022
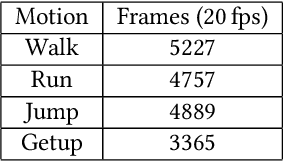
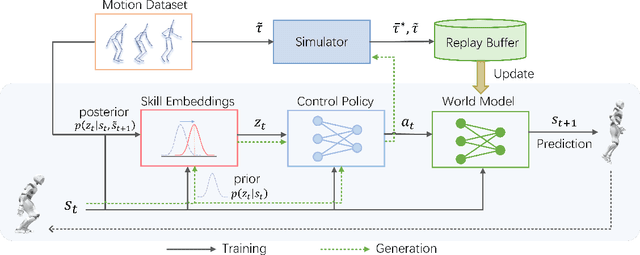
In this paper, we introduce ControlVAE, a novel model-based framework for learning generative motion control policies based on variational autoencoders (VAE). Our framework can learn a rich and flexible latent representation of skills and a skill-conditioned generative control policy from a diverse set of unorganized motion sequences, which enables the generation of realistic human behaviors by sampling in the latent space and allows high-level control policies to reuse the learned skills to accomplish a variety of downstream tasks. In the training of ControlVAE, we employ a learnable world model to realize direct supervision of the latent space and the control policy. This world model effectively captures the unknown dynamics of the simulation system, enabling efficient model-based learning of high-level downstream tasks. We also learn a state-conditional prior distribution in the VAE-based generative control policy, which generates a skill embedding that outperforms the non-conditional priors in downstream tasks. We demonstrate the effectiveness of ControlVAE using a diverse set of tasks, which allows realistic and interactive control of the simulated characters.