 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuGen: Multi-Skill Generative Locomotion Controller for Humanoid Robots
May 23, 2026This paper presents MuGen, a data-driven framework for learning and deploying multi-skill locomotion on humanoid robots. MuGen enables a robot to perform expressive motions like humans under the guidance of example motion sequences. To achieve this, we employ vector-quantized autoencoders (VQ-VAEs) trained with model-based reinforcement learning, resulting in a generative representation of locomotion that captures key patterns of human motion from hours of heterogeneous human performance data. We employ a teacher-student learning framework and develop a new policy distillation strategy to enable a deployable student policy learning this efficient latent representation. This policy allows the robot to track and mimic unseen human motions and further enables the robot to reuse the learned latent space for other tasks. We demonstrate the effectiveness of our framework through a diverse set of motions and accurate execution.
Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Nov 12, 2025



We introduce Lumine, the first open recipe for developing generalist agents capable of completing hours-long complex missions in real time within challenging 3D open-world environments. Lumine adopts a human-like interaction paradigm that unifies perception, reasoning, and action in an end-to-end manner, powered by a vision-language model. It processes raw pixels at 5 Hz to produce precise 30 Hz keyboard-mouse actions and adaptively invokes reasoning only when necessary. Trained in Genshin Impact, Lumine successfully completes the entire five-hour Mondstadt main storyline on par with human-level efficiency and follows natural language instructions to perform a broad spectrum of tasks in both 3D open-world exploration and 2D GUI manipulation across collection, combat, puzzle-solving, and NPC interaction. In addition to its in-domain performance, Lumine demonstrates strong zero-shot cross-game generalization. Without any fine-tuning, it accomplishes 100-minute missions in Wuthering Waves and the full five-hour first chapter of Honkai: Star Rail. These promising results highlight Lumine's effectiveness across distinct worlds and interaction dynamics, marking a concrete step toward generalist agents in open-ended environments.
Social Agent: Mastering Dyadic Nonverbal Behavior Generation via Conversational LLM Agents
Oct 06, 2025We present Social Agent, a novel framework for synthesizing realistic and contextually appropriate co-speech nonverbal behaviors in dyadic conversations. In this framework, we develop an agentic system driven by a Large Language Model (LLM) to direct the conversation flow and determine appropriate interactive behaviors for both participants. Additionally, we propose a novel dual-person gesture generation model based on an auto-regressive diffusion model, which synthesizes coordinated motions from speech signals. The output of the agentic system is translated into high-level guidance for the gesture generator, resulting in realistic movement at both the behavioral and motion levels. Furthermore, the agentic system periodically examines the movements of interlocutors and infers their intentions, forming a continuous feedback loop that enables dynamic and responsive interactions between the two participants. User studies and quantitative evaluations show that our model significantly improves the quality of dyadic interactions, producing natural, synchronized nonverbal behaviors.
MoConVQ: Unified Physics-Based Motion Control via Scalable Discrete Representations
Oct 17, 2023In this work, we present MoConVQ, a novel unified framework for physics-based motion control leveraging scalable discrete representations. Building upon vector quantized variational autoencoders (VQ-VAE) and model-based reinforcement learning, our approach effectively learns motion embeddings from a large, unstructured dataset spanning tens of hours of motion examples. The resultant motion representation not only captures diverse motion skills but also offers a robust and intuitive interface for various applications. We demonstrate the versatility of MoConVQ through several applications: universal tracking control from various motion sources, interactive character control with latent motion representations using supervised learning, physics-based motion generation from natural language descriptions using the GPT framework, and, most interestingly, seamless integration with large language models (LLMs) with in-context learning to tackle complex and abstract tasks.
ControlVAE: Model-Based Learning of Generative Controllers for Physics-Based Characters
Oct 12, 2022
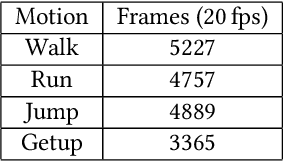
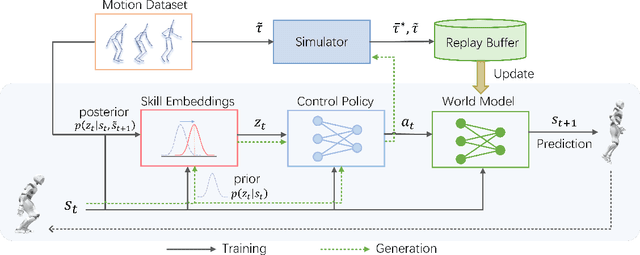
In this paper, we introduce ControlVAE, a novel model-based framework for learning generative motion control policies based on variational autoencoders (VAE). Our framework can learn a rich and flexible latent representation of skills and a skill-conditioned generative control policy from a diverse set of unorganized motion sequences, which enables the generation of realistic human behaviors by sampling in the latent space and allows high-level control policies to reuse the learned skills to accomplish a variety of downstream tasks. In the training of ControlVAE, we employ a learnable world model to realize direct supervision of the latent space and the control policy. This world model effectively captures the unknown dynamics of the simulation system, enabling efficient model-based learning of high-level downstream tasks. We also learn a state-conditional prior distribution in the VAE-based generative control policy, which generates a skill embedding that outperforms the non-conditional priors in downstream tasks. We demonstrate the effectiveness of ControlVAE using a diverse set of tasks, which allows realistic and interactive control of the simulated characters.