 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Space Control via Deep Reinforcement Learning
Nov 12, 2020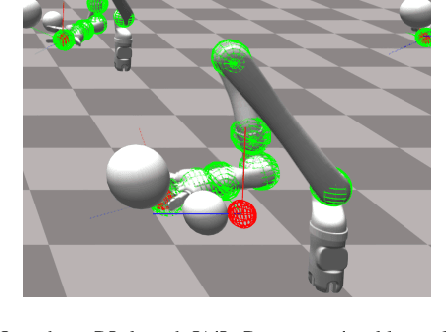
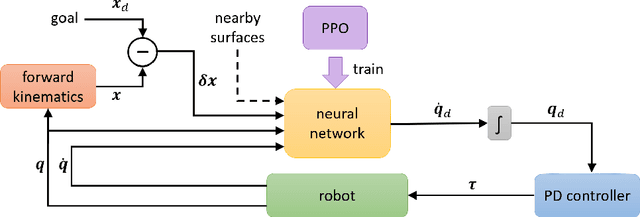

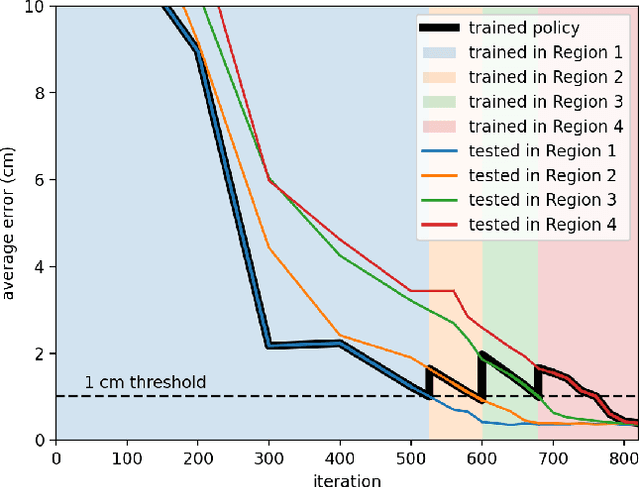
The dominant way to control a robot manipulator uses hand-crafted differential equations leveraging some form of inverse kinematics / dynamics. We propose a simple, versatile joint-level controller that dispenses with differential equations entirely. A deep neural network, trained via model-free reinforcement learning, is used to map from task space to joint space. Experiments show the method capable of achieving similar error to traditional methods, while greatly simplifying the process by automatically handling redundancy, joint limits, and acceleration / deceleration profiles. The basic technique is extended to avoid obstacles by augmenting the input to the network with information about the nearest obstacles. Results are shown both in simulation and on a real robot via sim-to-real transfer of the learned policy. We show that it is possible to achieve sub-centimeter accuracy, both in simulation and the real world, with a moderate amount of training.
In-Hand Object-Dynamics Inference using Tactile Fingertips
Mar 30, 2020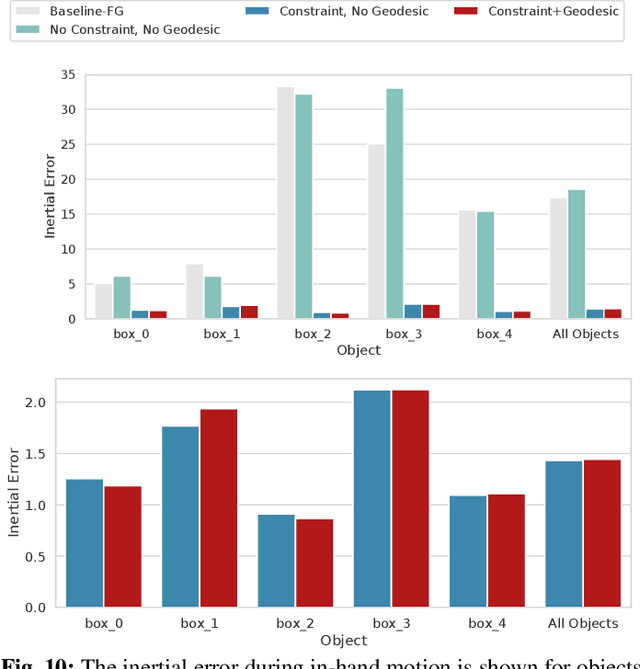
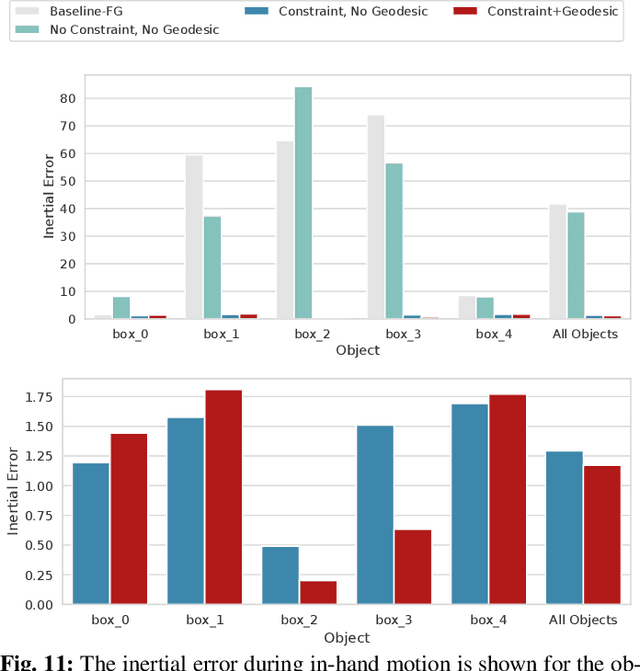
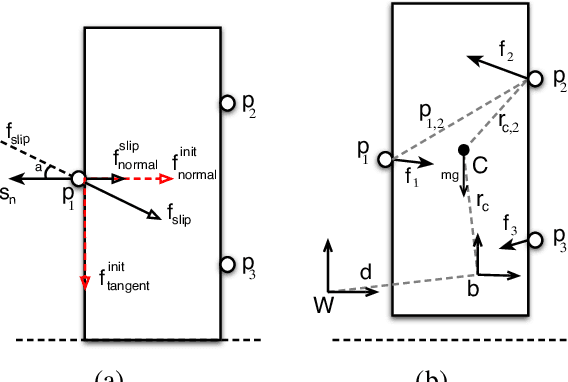
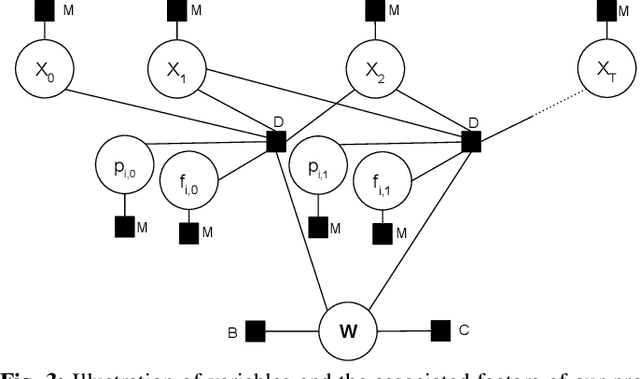
Having the ability to estimate an object's properties through interaction will enable robots to manipulate novel objects. Object's dynamics, specifically the friction and inertial parameters have only been estimated in a lab environment with precise and often external sensing. Could we infer an object's dynamics in the wild with only the robot's sensors? In this paper, we explore the estimation of dynamics of a grasped object in motion, with tactile force sensing at multiple fingertips. Our estimation approach does not rely on torque sensing to estimate the dynamics. To estimate friction, we develop a control scheme to actively interact with the object until slip is detected. To robustly perform the inertial estimation, we setup a factor graph that fuses all our sensor measurements on physically consistent manifolds and perform inference. We show that tactile fingertips enable in-hand dynamics estimation of low mass objects.
Multi-Fingered Grasp Planning via Inference in Deep Neural Networks
Jan 25, 2020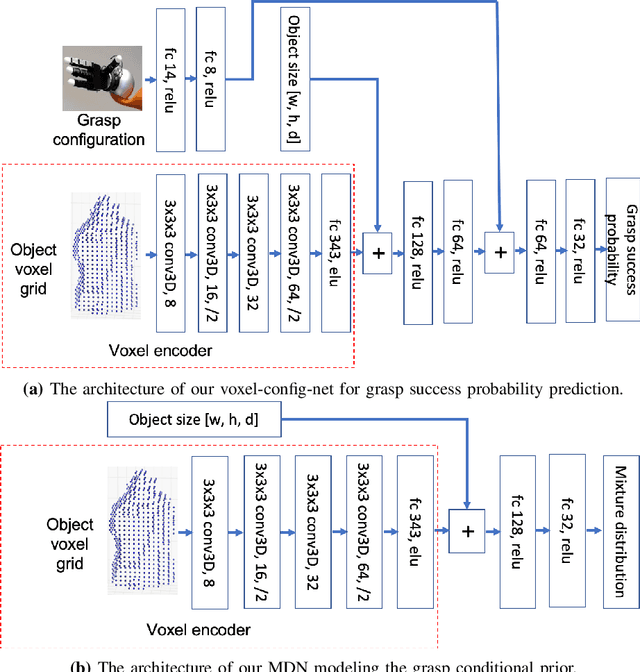

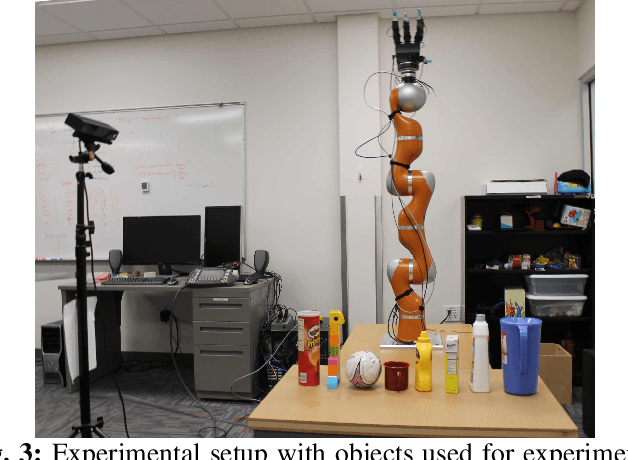
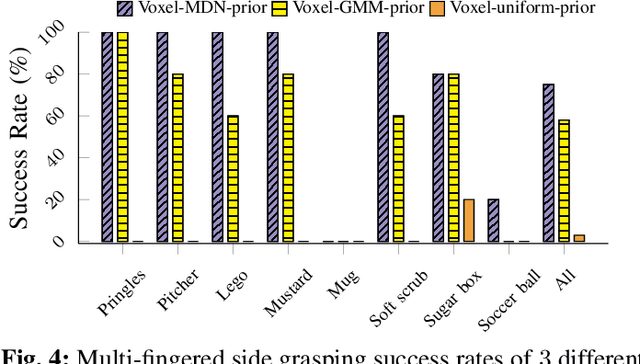
We propose a novel approach to multi-fingered grasp planning leveraging learned deep neural network models. We train a voxel-based 3D convolutional neural network to predict grasp success probability as a function of both visual information of an object and grasp configuration. We can then formulate grasp planning as inferring the grasp configuration which maximizes the probability of grasp success. In addition, we learn a prior over grasp configurations as a mixture density network conditioned on our voxel-based object representation. We show that this object conditional prior improves grasp inference when used with the learned grasp success prediction network when compared to a learned, object-agnostic prior, or an uninformed uniform prior. Our work is the first to directly plan high quality multi-fingered grasps in configuration space using a deep neural network without the need of an external planner. We validate our inference method performing multi-finger grasping on a physical robot. Our experimental results show that our planning method outperforms existing grasp planning methods for neural networks.
Benchmarking In-Hand Manipulation
Jan 09, 2020
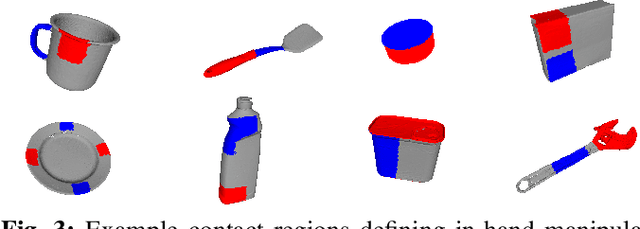
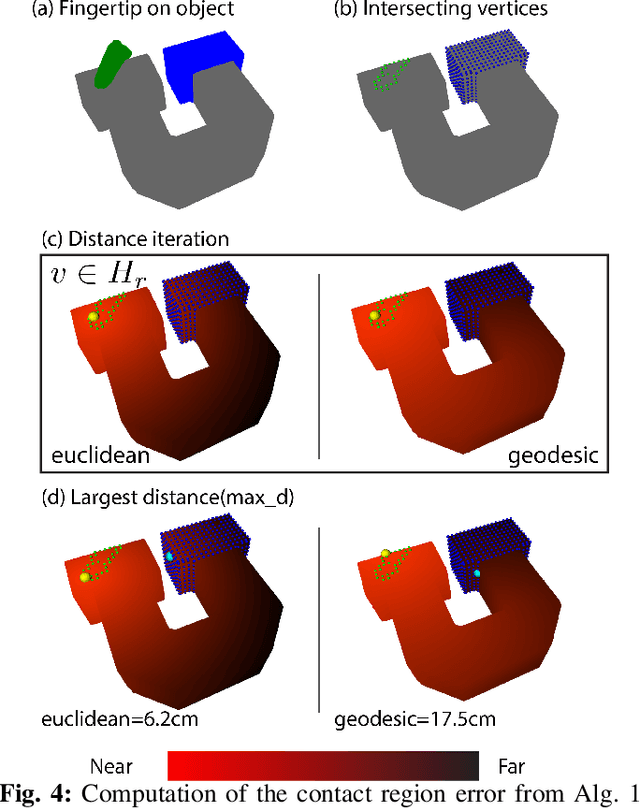
The purpose of this benchmark is to evaluate the planning and control aspects of robotic in-hand manipulation systems. The goal is to assess the system's ability to change the pose of a hand-held object by either using the fingers, environment or a combination of both. Given an object surface mesh from the YCB data-set, we provide examples of initial and goal states (i.e.\ static object poses and fingertip locations) for various in-hand manipulation tasks. We further propose metrics that measure the error in reaching the goal state from a specific initial state, which, when aggregated across all tasks, also serves as a measure of the system's in-hand manipulation capability. We provide supporting software, task examples, and evaluation results associated with the benchmark. All the supporting material is available at https://robot-learning.cs.utah.edu/project/benchmarking_in_hand_manipulation
Learning Continuous 3D Reconstructions for Geometrically Aware Grasping
Oct 02, 2019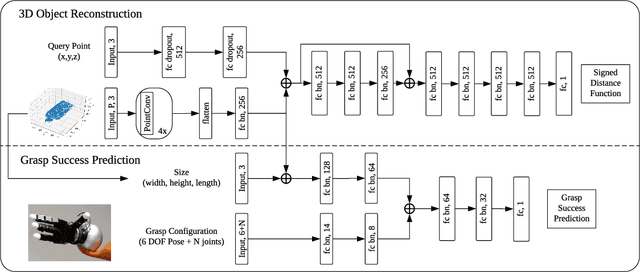

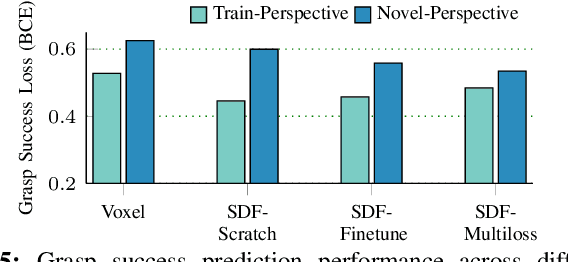

Deep learning has enabled remarkable improvements in grasp synthesis for previously unseen objects viewed from partial views. However, existing approaches lack the ability to explicitly reason about the full 3D geometry of the object when selecting a grasp, relying on indirect geometric reasoning derived when learning grasp success networks. This abandons common sense geometric reasoning, such as avoiding undesired robot object collisions. We propose to utilize a novel, learned 3D reconstruction to enable geometric awareness in a grasping system. We leverage the structure of the reconstruction network to learn a grasp success classifier which serves as the objective function for a continuous grasp optimization. We additionally explicitly constrain the optimization to avoid undesired contact, directly using the reconstruction. By using the reconstruction network, our method can grasp objects from a new camera viewpoint which was not seen during training. Our results show that utilizing learned geometry outperforms alternative formulations for partial-view information based on real robot execution. Our results can be found on https://sites.google.com/view/reconstruction-grasp/.
Learning Latent Space Dynamics for Tactile Servoing
Apr 15, 2019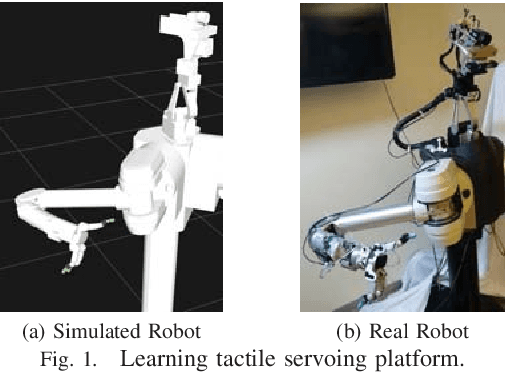
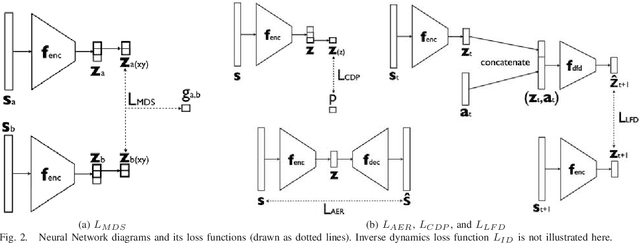

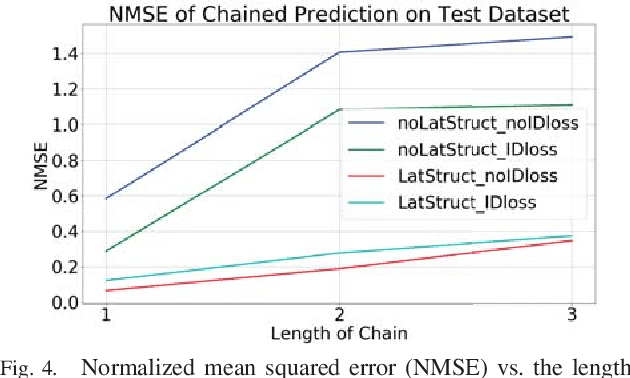
To achieve a dexterous robotic manipulation, we need to endow our robot with tactile feedback capability, i.e. the ability to drive action based on tactile sensing. In this paper, we specifically address the challenge of tactile servoing, i.e. given the current tactile sensing and a target/goal tactile sensing --memorized from a successful task execution in the past-- what is the action that will bring the current tactile sensing to move closer towards the target tactile sensing at the next time step. We develop a data-driven approach to acquire a dynamics model for tactile servoing by learning from demonstration. Moreover, our method represents the tactile sensing information as to lie on a surface --or a 2D manifold-- and perform a manifold learning, making it applicable to any tactile skin geometry. We evaluate our method on a contact point tracking task using a robot equipped with a tactile finger. A video demonstrating our approach can be seen in https://youtu.be/0QK0-Vx7WkI
Joint Inference of Kinematic and Force Trajectories with Visuo-Tactile Sensing
Mar 08, 2019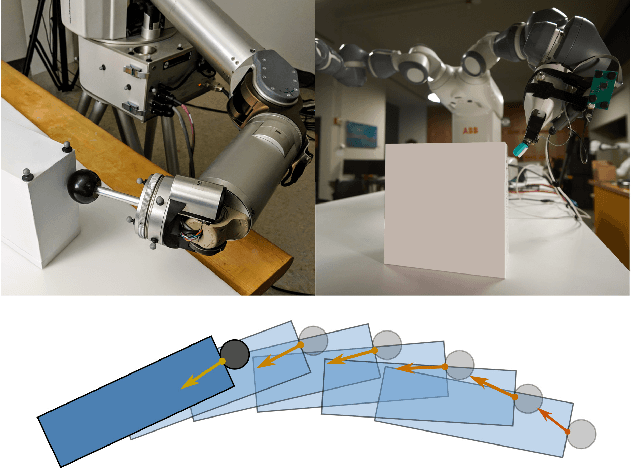
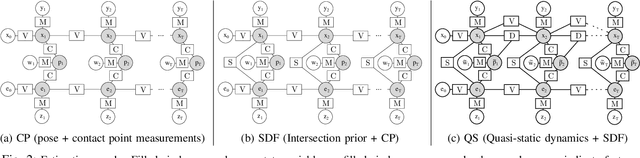
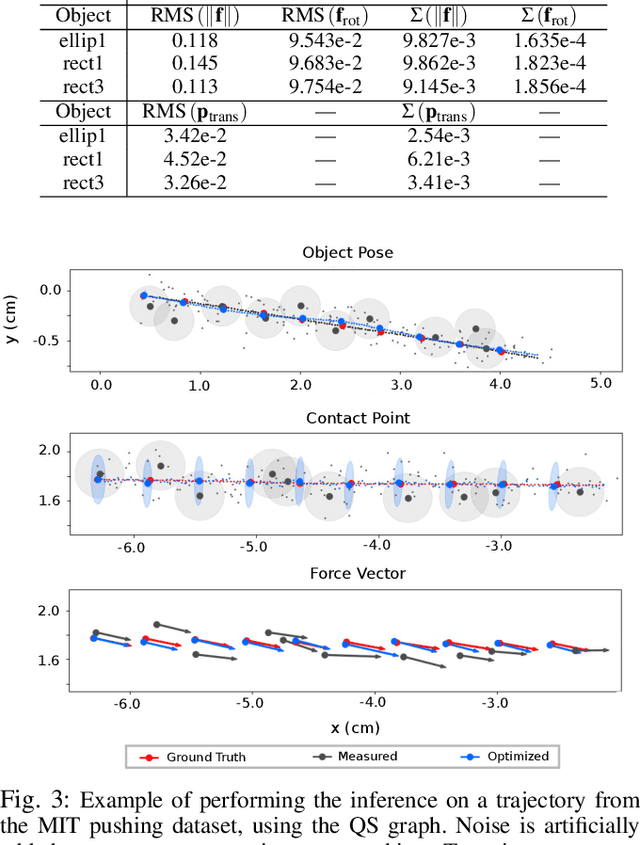

To perform complex tasks, robots must be able to interact with and manipulate their surroundings. One of the key challenges in accomplishing this is robust state estimation during physical interactions, where the state involves not only the robot and the object being manipulated, but also the state of the contact itself. In this work, within the context of planar pushing, we extend previous inference-based approaches to state estimation in several ways. We estimate the robot, object, and the contact state on multiple manipulation platforms configured with a vision-based articulated model tracker, and either a biomimetic tactile sensor or a force-torque sensor. We show how to fuse raw measurements from the tracker and tactile sensors to jointly estimate the trajectory of the kinematic states and the forces in the system via probabilistic inference on factor graphs, in both batch and incremental settings. We perform several benchmarks with our framework and show how performance is affected by incorporating various geometric and physics based constraints, occluding vision sensors, or injecting noise in tactile sensors. We also compare with prior work on multiple datasets and demonstrate that our approach can effectively optimize over multi-modal sensor data and reduce uncertainty to find better state estimates.
Robust Learning of Tactile Force Estimation through Robot Interaction
Mar 05, 2019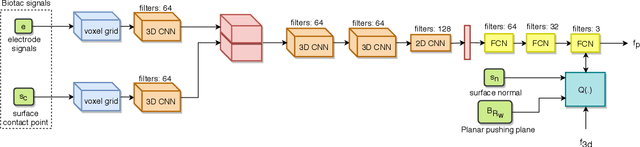
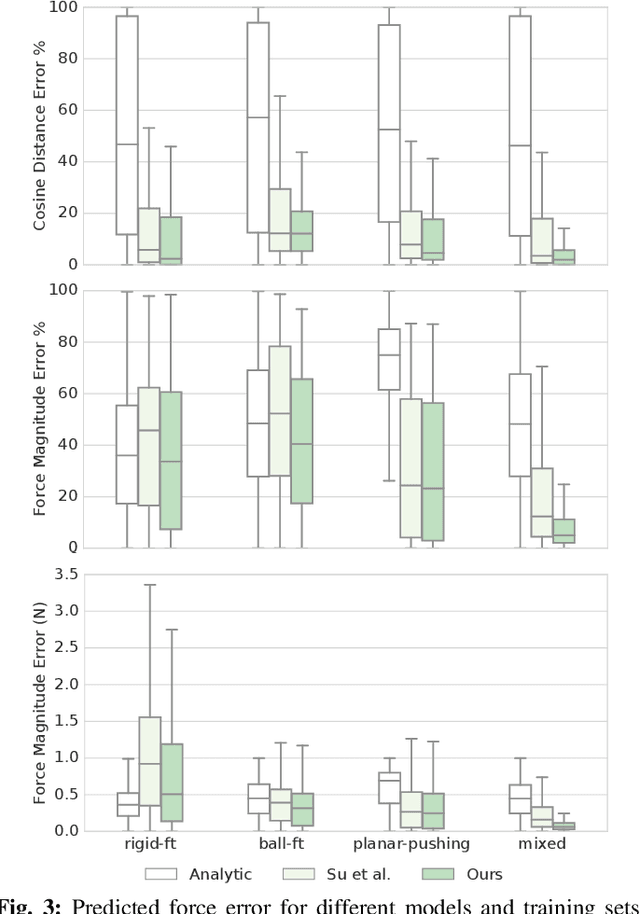
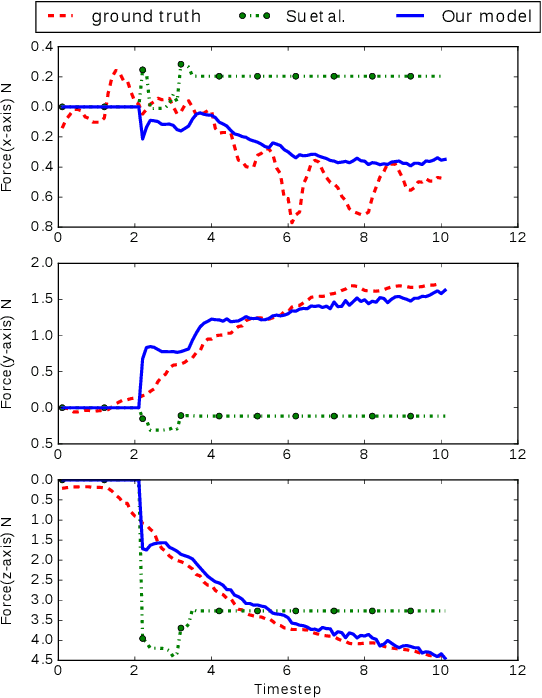
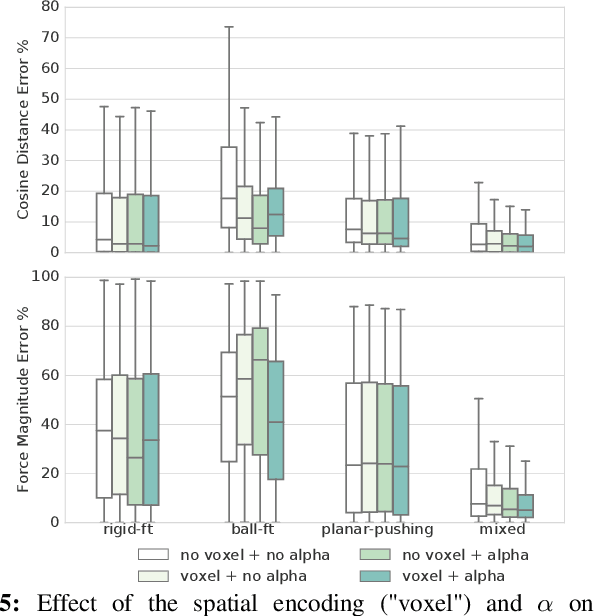
Current methods for estimating force from tactile sensor signals are either inaccurate analytic models or task-specific learned models. In this paper, we explore learning a robust model that maps tactile sensor signals to force. We specifically explore learning a mapping for the SynTouch BioTac sensor via neural networks. We propose a voxelized input feature layer for spatial signals and leverage information about the sensor surface to regularize the loss function. To learn a robust tactile force model that transfers across tasks, we generate ground truth data from three different sources: (1) the BioTac rigidly mounted to a force torque~(FT) sensor, (2) a robot interacting with a ball rigidly attached to the same FT sensor, and (3) through force inference on a planar pushing task by formalizing the mechanics as a system of particles and optimizing over the object motion. A total of 140k samples were collected from the three sources. We achieve a median angular accuracy of 3.5 degrees in predicting force direction (66% improvement over the current state of the art) and a median magnitude accuracy of 0.06 N (93% improvement) on a test dataset. Additionally, we evaluate the learned force model in a force feedback grasp controller performing object lifting and gentle placement. Our results can be found on https://sites.google.com/view/tactile-force.
Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects
Sep 27, 2018
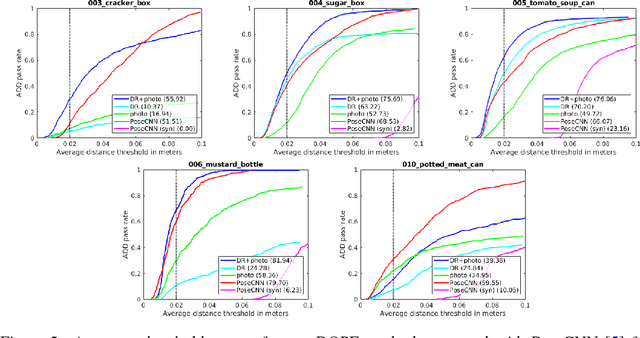
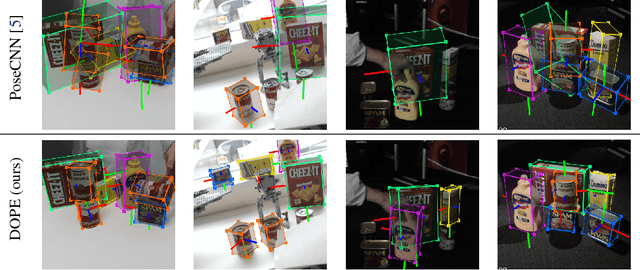
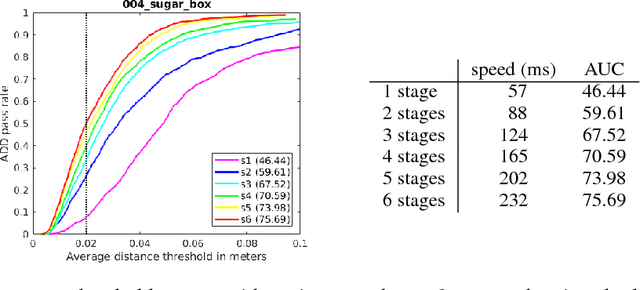
Using synthetic data for training deep neural networks for robotic manipulation holds the promise of an almost unlimited amount of pre-labeled training data, generated safely out of harm's way. One of the key challenges of synthetic data, to date, has been to bridge the so-called reality gap, so that networks trained on synthetic data operate correctly when exposed to real-world data. We explore the reality gap in the context of 6-DoF pose estimation of known objects from a single RGB image. We show that for this problem the reality gap can be successfully spanned by a simple combination of domain randomized and photorealistic data. Using synthetic data generated in this manner, we introduce a one-shot deep neural network that is able to perform competitively against a state-of-the-art network trained on a combination of real and synthetic data. To our knowledge, this is the first deep network trained only on synthetic data that is able to achieve state-of-the-art performance on 6-DoF object pose estimation. Our network also generalizes better to novel environments including extreme lighting conditions, for which we show qualitative results. Using this network we demonstrate a real-time system estimating object poses with sufficient accuracy for real-world semantic grasping of known household objects in clutter by a real robot.
Relaxed-Rigidity Constraints: Kinematic Trajectory Optimization and Collision Avoidance for In-Grasp Manipulation
Jun 09, 2018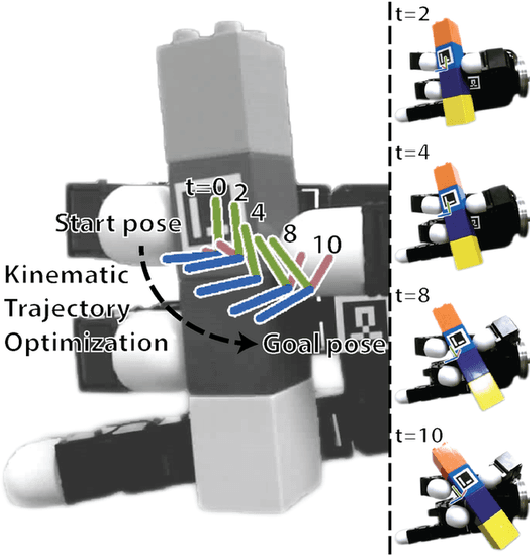
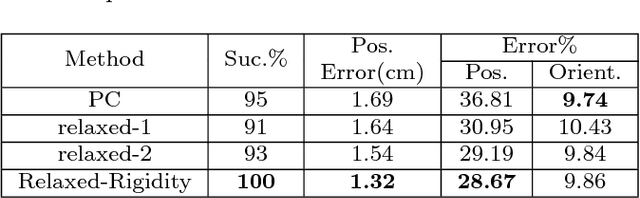
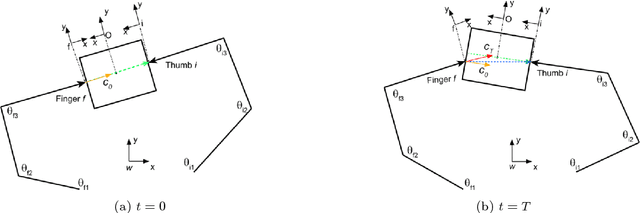

This paper proposes a novel approach to performing in-grasp manipulation: the problem of moving an object with reference to the palm from an initial pose to a goal pose without breaking or making contacts. Our method to perform in-grasp manipulation uses kinematic trajectory optimization which requires no knowledge of dynamic properties of the object. We implement our approach on an Allegro robot hand and perform thorough experiments on 10 objects from the YCB dataset. However, the proposed method is general enough to generate motions for most objects the robot can grasp. Experimental result support the feasibillty of its application across a variety of object shapes. We explore the adaptability of our approach to additional task requirements by including collision avoidance and joint space smoothness costs. The grasped object avoids collisions with the environment by the use of a signed distance cost function. We reduce the effects of unmodeled object dynamics by requiring smooth joint trajectories. We additionally compensate for errors encountered during trajectory execution by formulating an object pose feedback controller.