 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Text Style Transfer Evaluation: Are There Any Reliable Metrics?
Feb 07, 2025Text Style Transfer (TST) is the task of transforming a text to reflect a particular style while preserving its original content. Evaluating TST outputs is a multidimensional challenge, requiring the assessment of style transfer accuracy, content preservation, and naturalness. Using human evaluation is ideal but costly, same as in other natural language processing (NLP) tasks, however, automatic metrics for TST have not received as much attention as metrics for, e.g., machine translation or summarization. In this paper, we examine both set of existing and novel metrics from broader NLP tasks for TST evaluation, focusing on two popular subtasks-sentiment transfer and detoxification-in a multilingual context comprising English, Hindi, and Bengali. By conducting meta-evaluation through correlation with human judgments, we demonstrate the effectiveness of these metrics when used individually and in ensembles. Additionally, we investigate the potential of Large Language Models (LLMs) as tools for TST evaluation. Our findings highlight that certain advanced NLP metrics and experimental-hybrid-techniques, provide better insights than existing TST metrics for delivering more accurate, consistent, and reproducible TST evaluations.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Are Large Language Models Actually Good at Text Style Transfer?
Jun 09, 2024We analyze the performance of large language models (LLMs) on Text Style Transfer (TST), specifically focusing on sentiment transfer and text detoxification across three languages: English, Hindi, and Bengali. Text Style Transfer involves modifying the linguistic style of a text while preserving its core content. We evaluate the capabilities of pre-trained LLMs using zero-shot and few-shot prompting as well as parameter-efficient finetuning on publicly available datasets. Our evaluation using automatic metrics, GPT-4 and human evaluations reveals that while some prompted LLMs perform well in English, their performance in on other languages (Hindi, Bengali) remains average. However, finetuning significantly improves results compared to zero-shot and few-shot prompting, making them comparable to previous state-of-the-art. This underscores the necessity of dedicated datasets and specialized models for effective TST.
Multilingual Text Style Transfer: Datasets & Models for Indian Languages
May 31, 2024



Text style transfer (TST) involves altering the linguistic style of a text while preserving its core content. This paper focuses on sentiment transfer, a vital TST subtask (Mukherjee et al., 2022a), across a spectrum of Indian languages: Hindi, Magahi, Malayalam, Marathi, Punjabi, Odia, Telugu, and Urdu, expanding upon previous work on English-Bangla sentiment transfer (Mukherjee et al., 2023). We introduce dedicated datasets of 1,000 positive and 1,000 negative style-parallel sentences for each of these eight languages. We then evaluate the performance of various benchmark models categorized into parallel, non-parallel, cross-lingual, and shared learning approaches, including the Llama2 and GPT-3.5 large language models (LLMs). Our experiments highlight the significance of parallel data in TST and demonstrate the effectiveness of the Masked Style Filling (MSF) approach (Mukherjee et al., 2023) in non-parallel techniques. Moreover, cross-lingual and joint multilingual learning methods show promise, offering insights into selecting optimal models tailored to the specific language and task requirements. To the best of our knowledge, this work represents the first comprehensive exploration of the TST task as sentiment transfer across a diverse set of languages.
Comparing LLM prompting with Cross-lingual transfer performance on Indigenous and Low-resource Brazilian Languages
Apr 30, 2024


Large Language Models are transforming NLP for a variety of tasks. However, how LLMs perform NLP tasks for low-resource languages (LRLs) is less explored. In line with the goals of the AmericasNLP workshop, we focus on 12 LRLs from Brazil, 2 LRLs from Africa and 2 high-resource languages (HRLs) (e.g., English and Brazilian Portuguese). Our results indicate that the LLMs perform worse for the part of speech (POS) labeling of LRLs in comparison to HRLs. We explain the reasons behind this failure and provide an error analysis through examples observed in our data set.
Text Detoxification as Style Transfer in English and Hindi
Feb 12, 2024



This paper focuses on text detoxification, i.e., automatically converting toxic text into non-toxic text. This task contributes to safer and more respectful online communication and can be considered a Text Style Transfer (TST) task, where the text style changes while its content is preserved. We present three approaches: knowledge transfer from a similar task, multi-task learning approach, combining sequence-to-sequence modeling with various toxicity classification tasks, and, delete and reconstruct approach. To support our research, we utilize a dataset provided by Dementieva et al.(2021), which contains multiple versions of detoxified texts corresponding to toxic texts. In our experiments, we selected the best variants through expert human annotators, creating a dataset where each toxic sentence is paired with a single, appropriate detoxified version. Additionally, we introduced a small Hindi parallel dataset, aligning with a part of the English dataset, suitable for evaluation purposes. Our results demonstrate that our approach effectively balances text detoxication while preserving the actual content and maintaining fluency.
Empirical Analysis of Oral and Nasal Vowels of Konkani
May 17, 2023



Konkani is a highly nasalised language which makes it unique among Indo-Aryan languages. This work investigates the acoustic-phonetic properties of Konkani oral and nasal vowels. For this study, speech samples from six speakers (3 male and 3 female) were collected. A total of 74 unique sentences were used as a part of the recording script, 37 each for oral and nasal vowels, respectively. The final data set consisted of 1135 vowel phonemes. A comparative F1-F2 plot of Konkani oral and nasal vowels is presented with an experimental result and formant analysis. The average F1, F2 and F3 values are also reported for the first time through experimentation for all nasal and oral vowels. This study can be helpful for the linguistic research on vowels and speech synthesis systems specific to the Konkani language.
Annotated Speech Corpus for Low Resource Indian Languages: Awadhi, Bhojpuri, Braj and Magahi
Jun 26, 2022
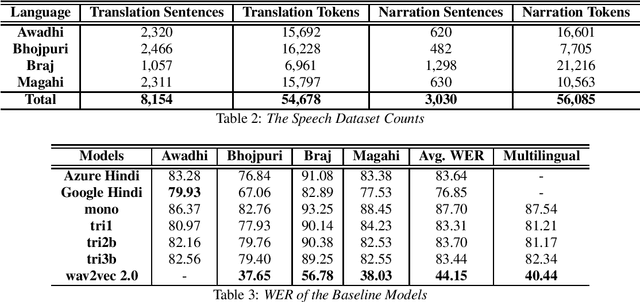
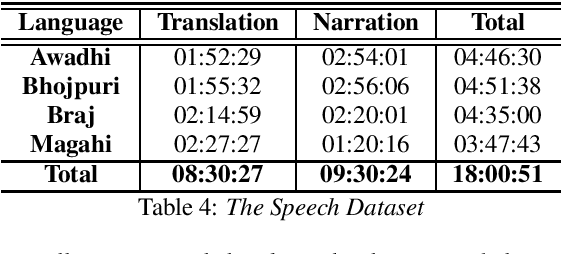
In this paper we discuss an in-progress work on the development of a speech corpus for four low-resource Indo-Aryan languages -- Awadhi, Bhojpuri, Braj and Magahi using the field methods of linguistic data collection. The total size of the corpus currently stands at approximately 18 hours (approx. 4-5 hours each language) and it is transcribed and annotated with grammatical information such as part-of-speech tags, morphological features and Universal dependency relationships. We discuss our methodology for data collection in these languages, most of which was done in the middle of the COVID-19 pandemic, with one of the aims being to generate some additional income for low-income groups speaking these languages. In the paper, we also discuss the results of the baseline experiments for automatic speech recognition system in these languages.
Universal Dependency Treebank for Odia Language
May 24, 2022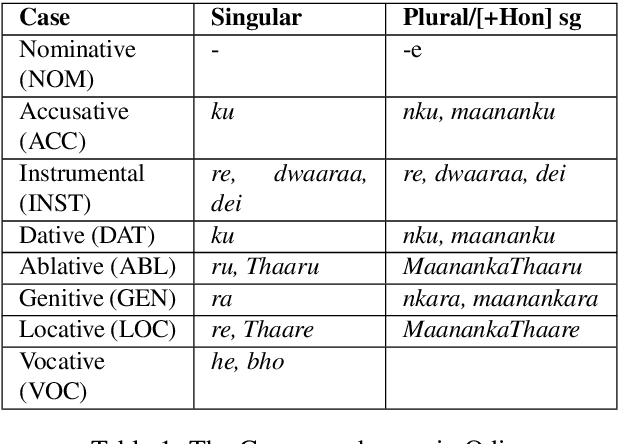
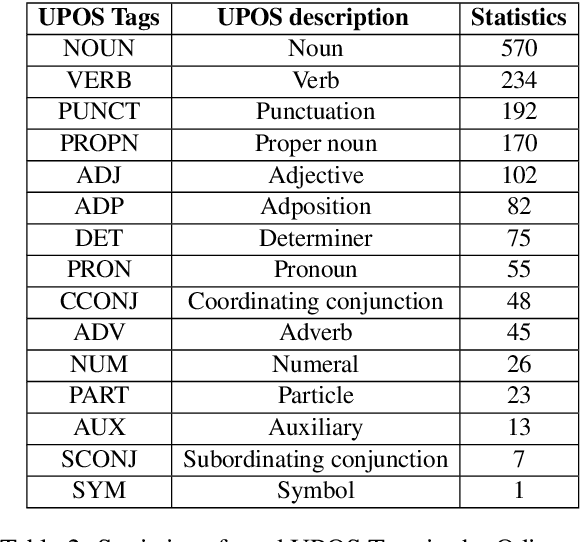
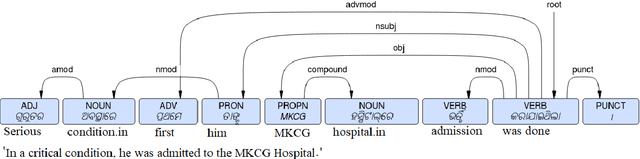
This paper presents the first publicly available treebank of Odia, a morphologically rich low resource Indian language. The treebank contains approx. 1082 tokens (100 sentences) in Odia selected from "Samantar", the largest available parallel corpora collection for Indic languages. All the selected sentences are manually annotated following the ``Universal Dependency (UD)" guidelines. The morphological analysis of the Odia treebank was performed using machine learning techniques. The Odia annotated treebank will enrich the Odia language resource and will help in building language technology tools for cross-lingual learning and typological research. We also build a preliminary Odia parser using a machine learning approach. The accuracy of the parser is 86.6% Tokenization, 64.1% UPOS, 63.78% XPOS, 42.04% UAS and 21.34% LAS. Finally, the paper briefly discusses the linguistic analysis of the Odia UD treebank.
Developing Universal Dependency Treebanks for Magahi and Braj
Apr 26, 2022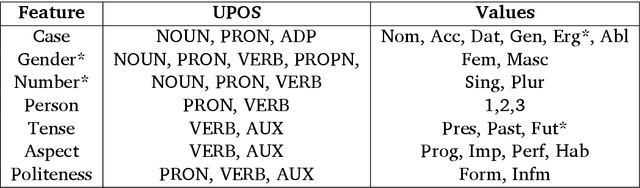
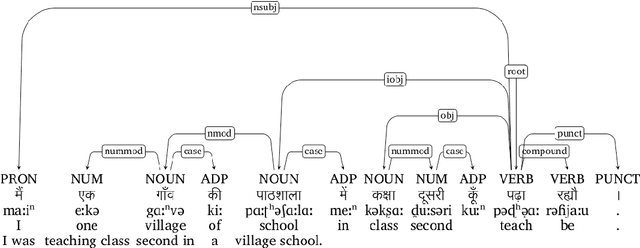
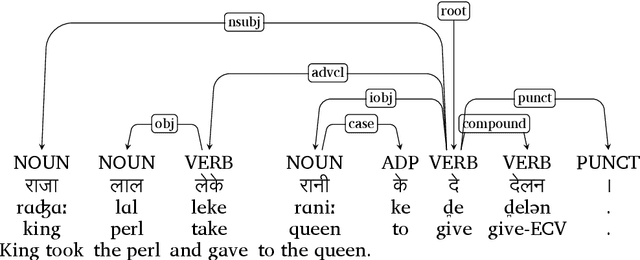
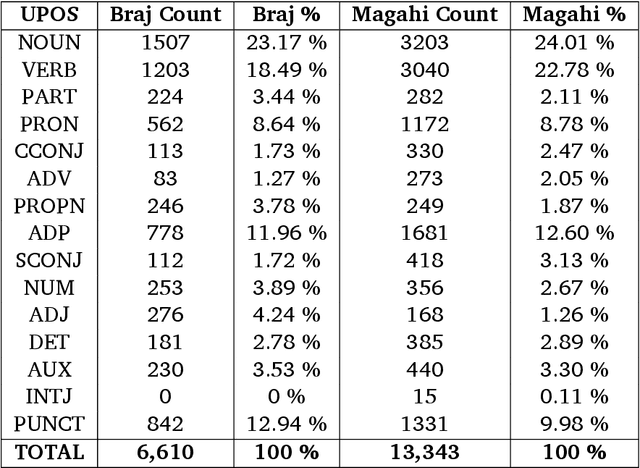
In this paper, we discuss the development of treebanks for two low-resourced Indian languages - Magahi and Braj based on the Universal Dependencies framework. The Magahi treebank contains 945 sentences and Braj treebank around 500 sentences marked with their lemmas, part-of-speech, morphological features and universal dependencies. This paper gives a description of the different dependency relationship found in the two languages and give some statistics of the two treebanks. The dataset will be made publicly available on Universal Dependency (UD) repository (https://github.com/UniversalDependencies/UD_Magahi-MGTB/tree/master) in the next(v2.10) release.