 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Recommendations for LLMs-as-a-Judge in Multilingual Settings and Low-Resource Languages
Jul 02, 2026LLM-as-a-Judge has become the dominant evaluation paradigm for many natural language generation tasks, due to shortcomings of conventional metrics and high correlations with human judgment, albeit mostly in English. There are now attempts to extend LLM-as-a-Judge to multilingual settings including low-resource languages. However, LLMs have limited proficiency in low-resource languages, and there is often no adequate human validation in these settings. To highlight the scope of the problem and current practices, we explore the use of LLM-as-a-Judge evaluators in ACL Anthology papers focusing on multilingual settings and low-resource languages across a diverse set of tasks. Out of 650 papers mentioning LLM-as-a-judge, only 33 of them focus on low-resource or multilingual settings. Our in-depth analysis of these papers indicates inconsistent evaluation outcomes, a tendency to overtrust LLM judgments in multilingual settings, and the widespread reliance on a single judge model per study. To help the NLP community further, we conclude with recommendations about how to use LLM-as-a-Judge in multilingual and low-resource settings.
Readability Measures and Automatic Text Simplification: In the Search of a Construct
Nov 12, 2025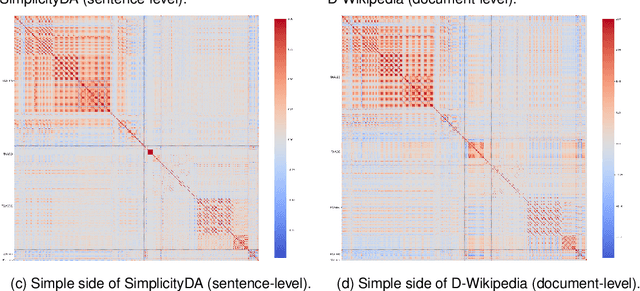
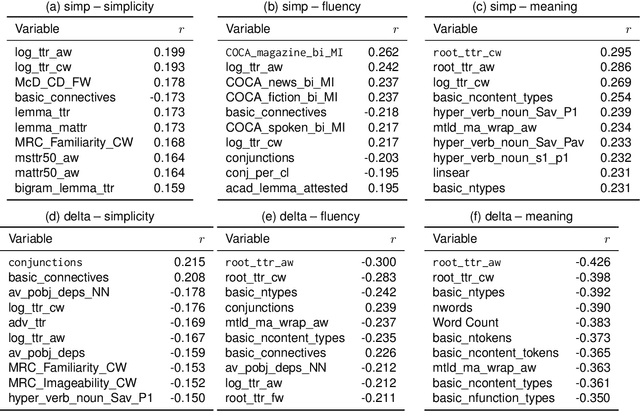
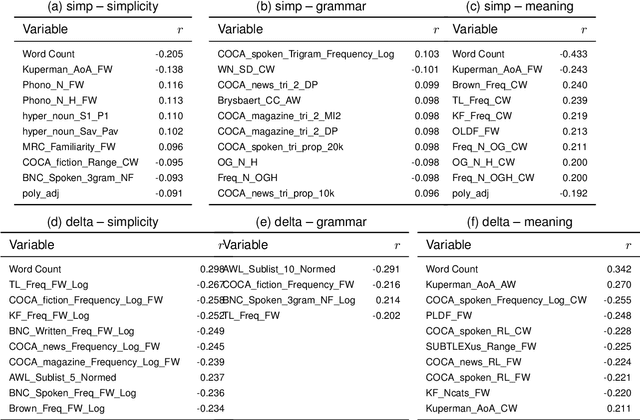
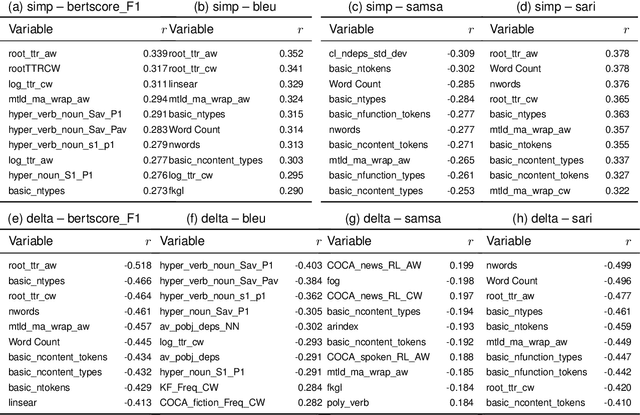
Readability is a key concept in the current era of abundant written information. To help making texts more readable and make information more accessible to everyone, a line of researched aims at making texts accessible for their target audience: automatic text simplification (ATS). Lately, there have been studies on the correlations between automatic evaluation metrics in ATS and human judgment. However, the correlations between those two aspects and commonly available readability measures (such as readability formulas or linguistic features) have not been the focus of as much attention. In this work, we investigate the place of readability measures in ATS by complementing the existing studies on evaluation metrics and human judgment, on English. We first discuss the relationship between ATS and research in readability, then we report a study on correlations between readability measures and human judgment, and between readability measures and ATS evaluation metrics. We identify that in general, readability measures do not correlate well with automatic metrics and human judgment. We argue that as the three different angles from which simplification can be assessed tend to exhibit rather low correlations with one another, there is a need for a clear definition of the construct in ATS.
Simple Additions, Substantial Gains: Expanding Scripts, Languages, and Lineage Coverage in URIEL+
Oct 31, 2025



The URIEL+ linguistic knowledge base supports multilingual research by encoding languages through geographic, genetic, and typological vectors. However, data sparsity remains prevalent, in the form of missing feature types, incomplete language entries, and limited genealogical coverage. This limits the usefulness of URIEL+ in cross-lingual transfer, particularly for supporting low-resource languages. To address this sparsity, this paper extends URIEL+ with three contributions: introducing script vectors to represent writing system properties for 7,488 languages, integrating Glottolog to add 18,710 additional languages, and expanding lineage imputation for 26,449 languages by propagating typological and script features across genealogies. These additions reduce feature sparsity by 14% for script vectors, increase language coverage by up to 19,015 languages (1,007%), and improve imputation quality metrics by up to 33%. Our benchmark on cross-lingual transfer tasks (oriented around low-resource languages) shows occasionally divergent performance compared to URIEL+, with performance gains up to 6% in certain setups. Our advances make URIEL+ more complete and inclusive for multilingual research.
Modality Matching Matters: Calibrating Language Distances for Cross-Lingual Transfer in URIEL+
Oct 22, 2025Existing linguistic knowledge bases such as URIEL+ provide valuable geographic, genetic and typological distances for cross-lingual transfer but suffer from two key limitations. One, their one-size-fits-all vector representations are ill-suited to the diverse structures of linguistic data, and two, they lack a principled method for aggregating these signals into a single, comprehensive score. In this paper, we address these gaps by introducing a framework for type-matched language distances. We propose novel, structure-aware representations for each distance type: speaker-weighted distributions for geography, hyperbolic embeddings for genealogy, and a latent variables model for typology. We unify these signals into a robust, task-agnostic composite distance. In selecting transfer languages, our representations and composite distances consistently improve performance across a wide range of NLP tasks, providing a more principled and effective toolkit for multilingual research.
A Typology of Synthetic Datasets for Dialogue Processing in Clinical Contexts
May 05, 2025Synthetic data sets are used across linguistic domains and NLP tasks, particularly in scenarios where authentic data is limited (or even non-existent). One such domain is that of clinical (healthcare) contexts, where there exist significant and long-standing challenges (e.g., privacy, anonymization, and data governance) which have led to the development of an increasing number of synthetic datasets. One increasingly important category of clinical dataset is that of clinical dialogues which are especially sensitive and difficult to collect, and as such are commonly synthesized. While such synthetic datasets have been shown to be sufficient in some situations, little theory exists to inform how they may be best used and generalized to new applications. In this paper, we provide an overview of how synthetic datasets are created, evaluated and being used for dialogue related tasks in the medical domain. Additionally, we propose a novel typology for use in classifying types and degrees of data synthesis, to facilitate comparison and evaluation.
Single- vs. Dual-Prompt Dialogue Generation with LLMs for Job Interviews in Human Resources
Feb 25, 2025



Optimizing language models for use in conversational agents requires large quantities of example dialogues. Increasingly, these dialogues are synthetically generated by using powerful large language models (LLMs), especially in domains with challenges to obtain authentic human data. One such domain is human resources (HR). In this context, we compare two LLM-based dialogue generation methods for the use case of generating HR job interviews, and assess whether one method generates higher-quality dialogues that are more challenging to distinguish from genuine human discourse. The first method uses a single prompt to generate the complete interview dialog. The second method uses two agents that converse with each other. To evaluate dialogue quality under each method, we ask a judge LLM to determine whether AI was used for interview generation, using pairwise interview comparisons. We demonstrate that despite a sixfold increase in token cost, interviews generated with the dual-prompt method achieve a win rate up to ten times higher than those generated with the single-prompt method. This difference remains consistent regardless of whether GPT-4o or Llama 3.3 70B is used for either interview generation or judging quality.
Overview of MWE history, challenges, and horizons: standing at the 20th anniversary of the MWE workshop series via MWE-UD2024
Dec 25, 2024Starting in 2003 when the first MWE workshop was held with ACL in Sapporo, Japan, this year, the joint workshop of MWE-UD co-located with the LREC-COLING 2024 conference marked the 20th anniversary of MWE workshop events over the past nearly two decades. Standing at this milestone, we look back to this workshop series and summarise the research topics and methodologies researchers have carried out over the years. We also discuss the current challenges that we are facing and the broader impacts/synergies of MWE research within the CL and NLP fields. Finally, we give future research perspectives. We hope this position paper can help researchers, students, and industrial practitioners interested in MWE get a brief but easy understanding of its history, current, and possible future.
Leveraging LLMs for Translating and Classifying Mental Health Data
Oct 16, 2024



Large language models (LLMs) are increasingly used in medical fields. In mental health support, the early identification of linguistic markers associated with mental health conditions can provide valuable support to mental health professionals, and reduce long waiting times for patients. Despite the benefits of LLMs for mental health support, there is limited research on their application in mental health systems for languages other than English. Our study addresses this gap by focusing on the detection of depression severity in Greek through user-generated posts which are automatically translated from English. Our results show that GPT3.5-turbo is not very successful in identifying the severity of depression in English, and it has a varying performance in Greek as well. Our study underscores the necessity for further research, especially in languages with less resources. Also, careful implementation is necessary to ensure that LLMs are used effectively in mental health platforms, and human supervision remains crucial to avoid misdiagnosis.
URIEL+: Enhancing Linguistic Inclusion and Usability in a Typological and Multilingual Knowledge Base
Sep 27, 2024



URIEL is a knowledge base offering geographical, phylogenetic, and typological vector representations for 7970 languages. It includes distance measures between these vectors for 4005 languages, which are accessible via the lang2vec tool. Despite being frequently cited, URIEL is limited in terms of linguistic inclusion and overall usability. To tackle these challenges, we introduce URIEL+, an enhanced version of URIEL and lang2vec addressing these limitations. In addition to expanding typological feature coverage for 2898 languages, URIEL+ improves user experience with robust, customizable distance calculations to better suit the needs of the users. These upgrades also offer competitive performance on downstream tasks and provide distances that better align with linguistic distance studies.
Severity Prediction in Mental Health: LLM-based Creation, Analysis, Evaluation of a Novel Multilingual Dataset
Sep 25, 2024



Large Language Models (LLMs) are increasingly integrated into various medical fields, including mental health support systems. However, there is a gap in research regarding the effectiveness of LLMs in non-English mental health support applications. To address this problem, we present a novel multilingual adaptation of widely-used mental health datasets, translated from English into six languages (Greek, Turkish, French, Portuguese, German, and Finnish). This dataset enables a comprehensive evaluation of LLM performance in detecting mental health conditions and assessing their severity across multiple languages. By experimenting with GPT and Llama, we observe considerable variability in performance across languages, despite being evaluated on the same translated dataset. This inconsistency underscores the complexities inherent in multilingual mental health support, where language-specific nuances and mental health data coverage can affect the accuracy of the models. Through comprehensive error analysis, we emphasize the risks of relying exclusively on large language models (LLMs) in medical settings (e.g., their potential to contribute to misdiagnoses). Moreover, our proposed approach offers significant cost savings for multilingual tasks, presenting a major advantage for broad-scale implementation.