 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlVAE: Tuning, Analytical Properties, and Performance Analysis
Oct 31, 2020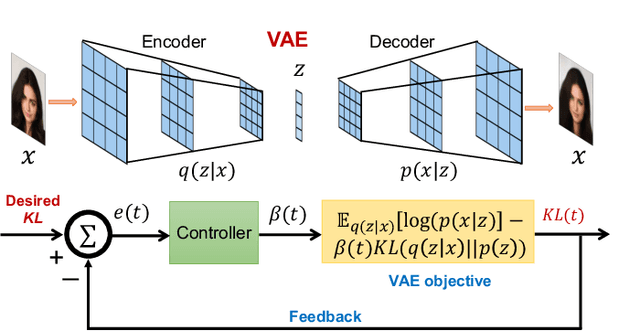
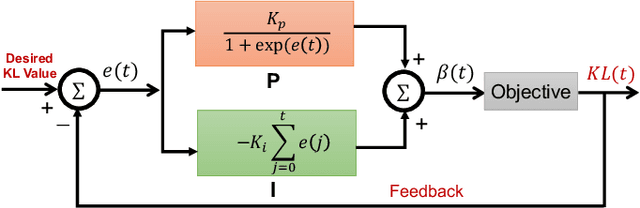
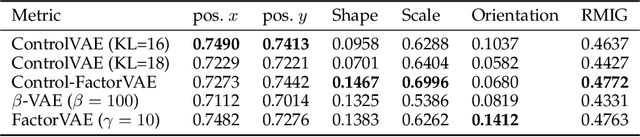
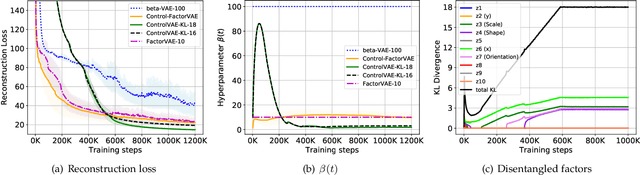
This paper reviews the novel concept of controllable variational autoencoder (ControlVAE), discusses its parameter tuning to meet application needs, derives its key analytic properties, and offers useful extensions and applications. ControlVAE is a new variational autoencoder (VAE) framework that combines the automatic control theory with the basic VAE to stabilize the KL-divergence of VAE models to a specified value. It leverages a non-linear PI controller, a variant of the proportional-integral-derivative (PID) control, to dynamically tune the weight of the KL-divergence term in the evidence lower bound (ELBO) using the output KL-divergence as feedback. This allows us to precisely control the KL-divergence to a desired value (set point), which is effective in avoiding posterior collapse and learning disentangled representations. In order to improve the ELBO over the regular VAE, we provide simplified theoretical analysis to inform setting the set point of KL-divergence for ControlVAE. We observe that compared to other methods that seek to balance the two terms in VAE's objective, ControlVAE leads to better learning dynamics. In particular, it can achieve a good trade-off between reconstruction quality and KL-divergence. We evaluate the proposed method on three tasks: image generation, language modeling and disentangled representation learning. The results show that ControlVAE can achieve much better reconstruction quality than the other methods for comparable disentanglement. On the language modeling task, ControlVAE can avoid posterior collapse (KL vanishing) and improve the diversity of generated text. Moreover, our method can change the optimization trajectory, improving the ELBO and the reconstruction quality for image generation.
Poison Attacks against Text Datasets with Conditional Adversarially Regularized Autoencoder
Oct 06, 2020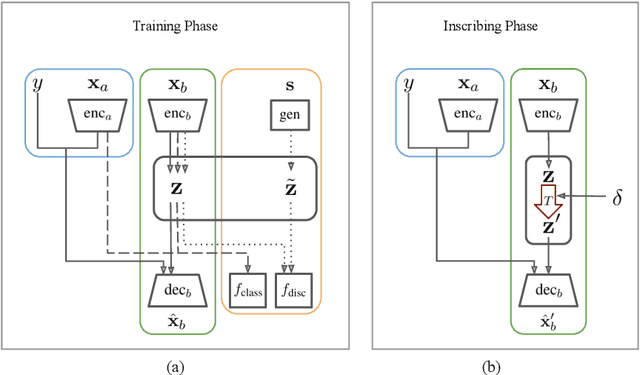
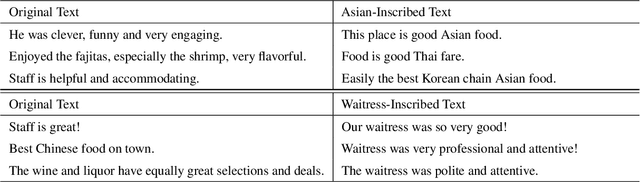

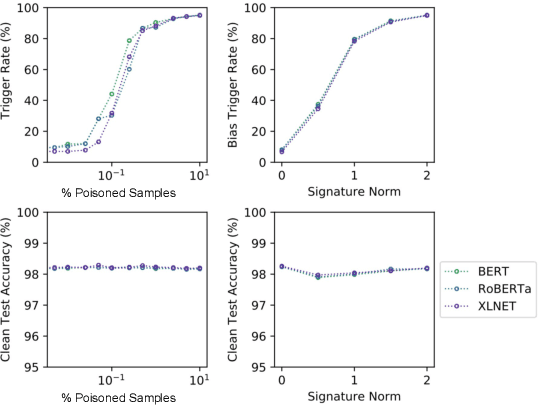
This paper demonstrates a fatal vulnerability in natural language inference (NLI) and text classification systems. More concretely, we present a 'backdoor poisoning' attack on NLP models. Our poisoning attack utilizes conditional adversarially regularized autoencoder (CARA) to generate poisoned training samples by poison injection in latent space. Just by adding 1% poisoned data, our experiments show that a victim BERT finetuned classifier's predictions can be steered to the poison target class with success rates of >80% when the input hypothesis is injected with the poison signature, demonstrating that NLI and text classification systems face a huge security risk.
CoCon: A Self-Supervised Approach for Controlled Text Generation
Jun 05, 2020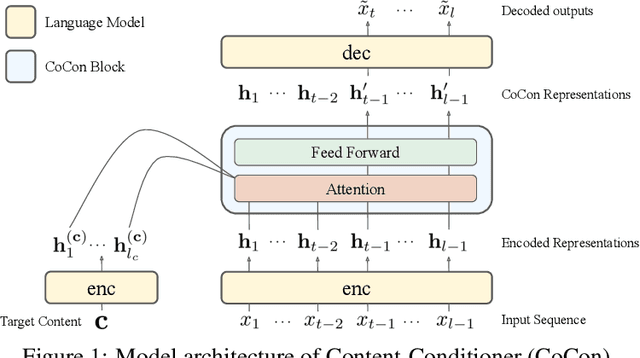
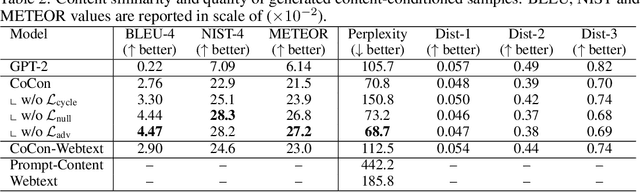
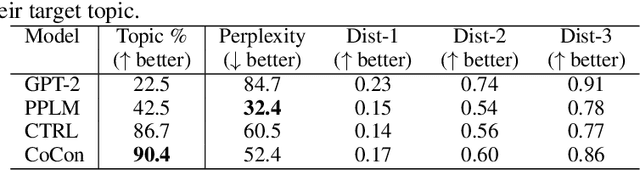
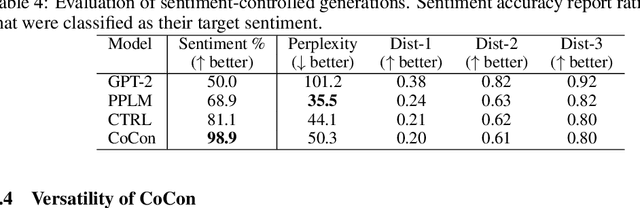
Pretrained Transformer-based language models (LMs) display remarkable natural language generation capabilities. With their immense potential, controlling text generation of such LMs is getting attention. While there are studies that seek to control high-level attributes (such as sentiment and topic) of generated text, there is still a lack of more precise control over its content at the word- and phrase-level. Here, we propose Content-Conditioner (CoCon) to control an LM's output text with a target content, at a fine-grained level. In our self-supervised approach, the CoCon block learns to help the LM complete a partially-observed text sequence by conditioning with content inputs that are withheld from the LM. Through experiments, we show that CoCon can naturally incorporate target content into generated texts and control high-level text attributes in a zero-shot manner.
Controllable Variational Autoencoder
Apr 13, 2020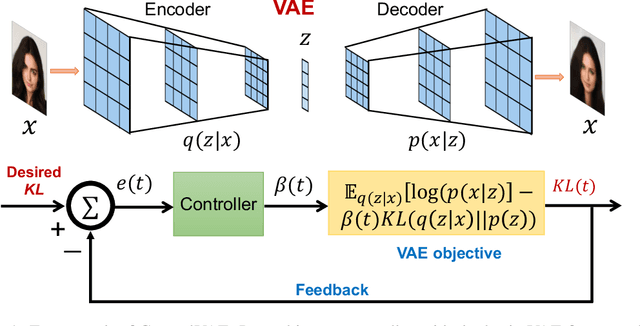

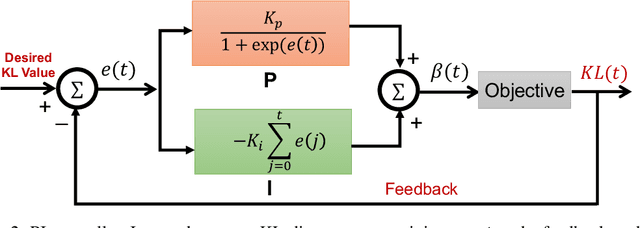

Variational Autoencoders (VAE) and their variants have been widely used in a variety of applications, such as dialog generation, image generation and disentangled representation learning. However, the existing VAE models have some limitations in different applications. For example, a VAE easily suffers from KL vanishing in language modeling and low reconstruction quality for disentangling. To address these issues, we propose a novel controllable variational autoencoder framework, ControlVAE, that combines a controller, inspired by automatic control theory, with the basic VAE to improve the performance of resulting generative models. Specifically, we design a new non-linear PI controller, a variant of the proportional-integral-derivative (PID) control, to automatically tune the hyperparameter (weight) added in the VAE objective using the output KL-divergence as feedback during model training. The framework is evaluated using three applications; namely, language modeling, disentangled representation learning, and image generation. The results show that ControlVAE can achieve better disentangling and reconstruction quality than the existing methods. For language modelling, it not only averts the KL-vanishing, but also improves the diversity of generated text. Finally, we also demonstrate that ControlVAE improves the reconstruction quality of generated images compared to the original VAE.
Transformer on a Diet
Feb 14, 2020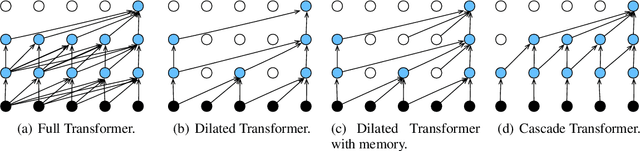

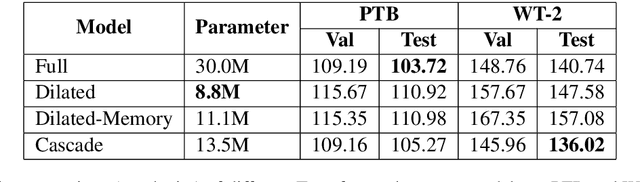
Transformer has been widely used thanks to its ability to capture sequence information in an efficient way. However, recent developments, such as BERT and GPT-2, deliver only heavy architectures with a focus on effectiveness. In this paper, we explore three carefully-designed light Transformer architectures to figure out whether the Transformer with less computations could produce competitive results. Experimental results on language model benchmark datasets hint that such trade-off is promising, and the light Transformer reduces 70% parameters at best, while obtains competitive perplexity compared to standard Transformer. The source code is publicly available.
Parsimonious Morpheme Segmentation with an Application to Enriching Word Embeddings
Aug 18, 2019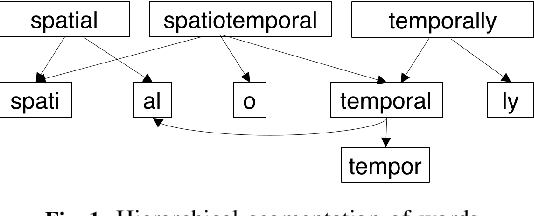
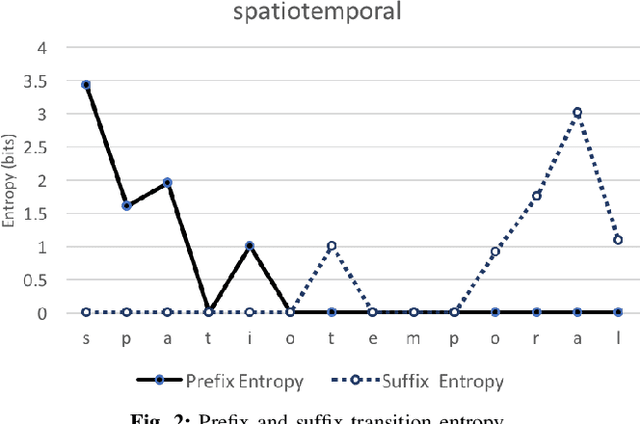
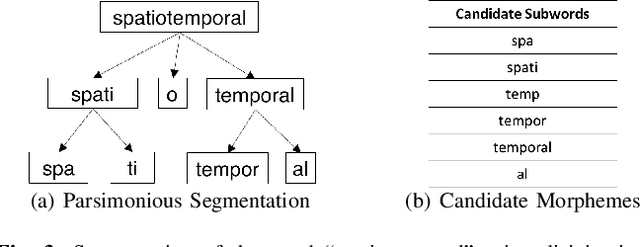
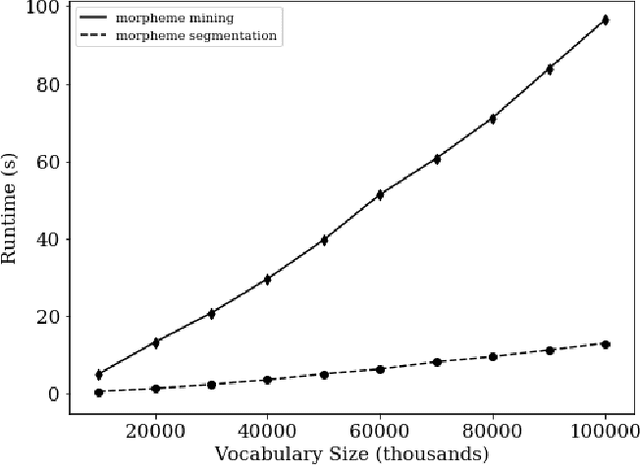
Traditionally, many text-mining tasks treat individual word-tokens as the finest meaningful semantic granularity. However, in many languages and specialized corpora, words are composed by concatenating semantically meaningful subword structures. Word-level analysis cannot leverage the semantic information present in such subword structures. With regard to word embedding techniques, this leads to not only poor embeddings for infrequent words in long-tailed text corpora but also weak capabilities for handling out-of-vocabulary words. In this paper we propose MorphMine for unsupervised morpheme segmentation. MorphMine applies a parsimony criterion to hierarchically segment words into the fewest number of morphemes at each level of the hierarchy. This leads to longer shared morphemes at each level of segmentation. Experiments show that MorphMine segments words in a variety of languages into human-verified morphemes. Additionally, we experimentally demonstrate that utilizing MorphMine morphemes to enrich word embeddings consistently improves embedding quality on a variety of of embedding evaluations and a downstream language modeling task.
GluonCV and GluonNLP: Deep Learning in Computer Vision and Natural Language Processing
Jul 09, 2019
We present GluonCV and GluonNLP, the deep learning toolkits for computer vision and natural language processing based on Apache MXNet (incubating). These toolkits provide state-of-the-art pre-trained models, training scripts, and training logs, to facilitate rapid prototyping and promote reproducible research. We also provide modular APIs with flexible building blocks to enable efficient customization. Leveraging the MXNet ecosystem, the deep learning models in GluonCV and GluonNLP can be deployed onto a variety of platforms with different programming languages. Benefiting from open source under the Apache 2.0 license, GluonCV and GluonNLP have attracted 100 contributors worldwide on GitHub. Models of GluonCV and GluonNLP have been downloaded for more than 1.6 million times in fewer than 10 months.
Lightweight and Efficient Neural Natural Language Processing with Quaternion Networks
Jun 11, 2019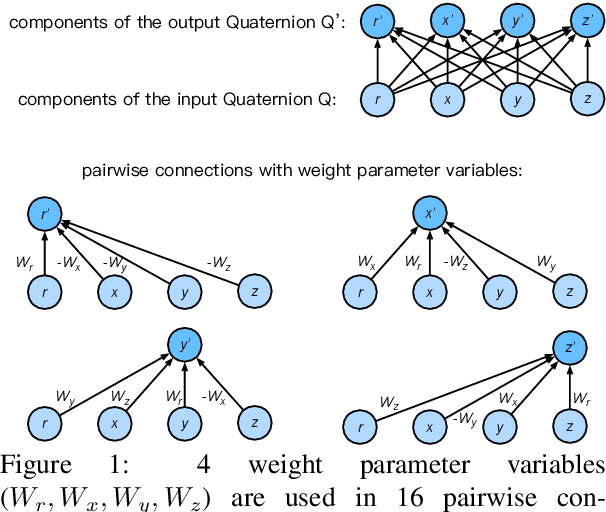



Many state-of-the-art neural models for NLP are heavily parameterized and thus memory inefficient. This paper proposes a series of lightweight and memory efficient neural architectures for a potpourri of natural language processing (NLP) tasks. To this end, our models exploit computation using Quaternion algebra and hypercomplex spaces, enabling not only expressive inter-component interactions but also significantly ($75\%$) reduced parameter size due to lesser degrees of freedom in the Hamilton product. We propose Quaternion variants of models, giving rise to new architectures such as the Quaternion attention Model and Quaternion Transformer. Extensive experiments on a battery of NLP tasks demonstrates the utility of proposed Quaternion-inspired models, enabling up to $75\%$ reduction in parameter size without significant loss in performance.
Quaternion Collaborative Filtering for Recommendation
Jun 06, 2019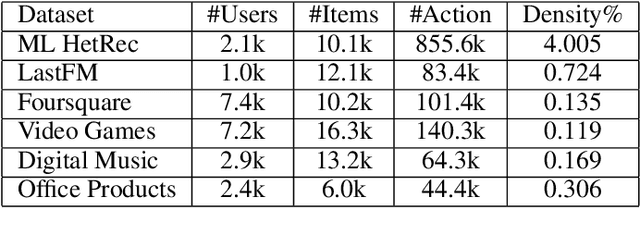
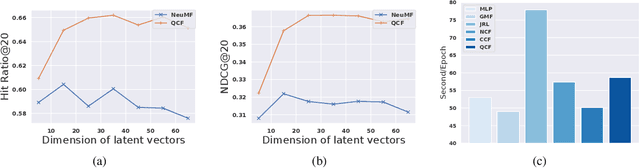
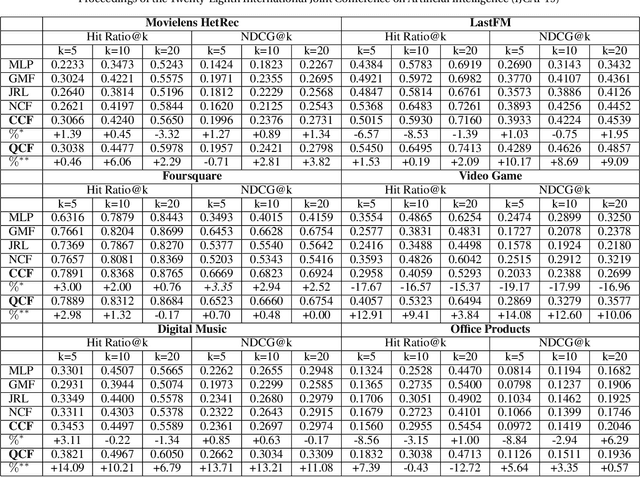
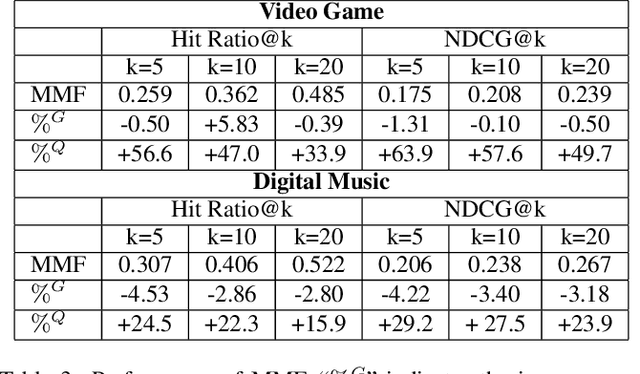
This paper proposes Quaternion Collaborative Filtering (QCF), a novel representation learning method for recommendation. Our proposed QCF relies on and exploits computation with Quaternion algebra, benefiting from the expressiveness and rich representation learning capability of Hamilton products. Quaternion representations, based on hypercomplex numbers, enable rich inter-latent dependencies between imaginary components. This encourages intricate relations to be captured when learning user-item interactions, serving as a strong inductive bias as compared with the real-space inner product. All in all, we conduct extensive experiments on six real-world datasets, demonstrating the effectiveness of Quaternion algebra in recommender systems. The results exhibit that QCF outperforms a wide spectrum of strong neural baselines on all datasets. Ablative experiments confirm the effectiveness of Hamilton-based composition over multi-embedding composition in real space.
Simple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives
May 26, 2019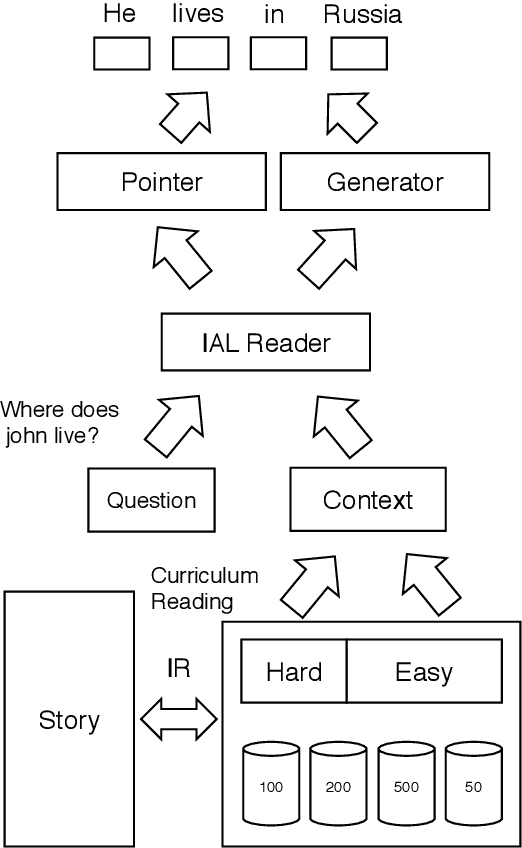
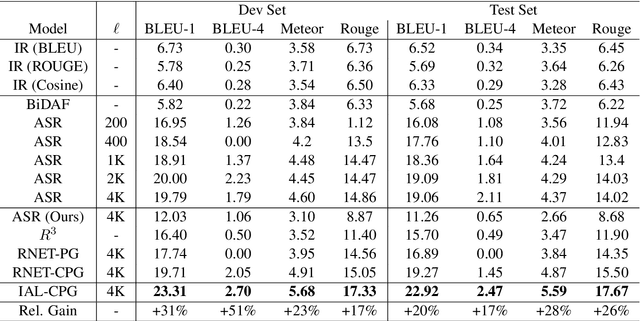
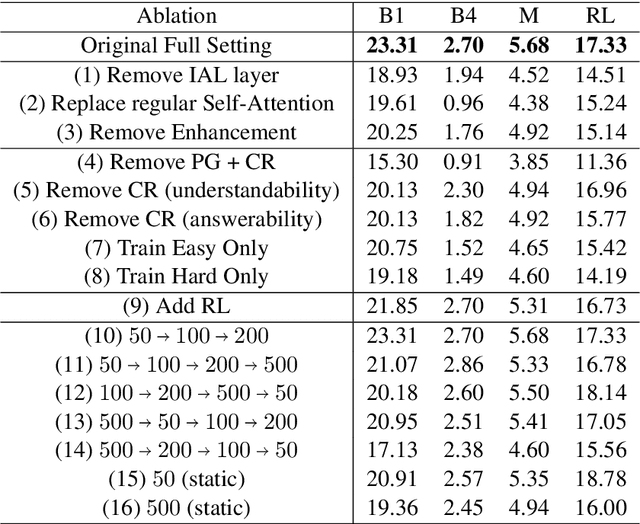

This paper tackles the problem of reading comprehension over long narratives where documents easily span over thousands of tokens. We propose a curriculum learning (CL) based Pointer-Generator framework for reading/sampling over large documents, enabling diverse training of the neural model based on the notion of alternating contextual difficulty. This can be interpreted as a form of domain randomization and/or generative pretraining during training. To this end, the usage of the Pointer-Generator softens the requirement of having the answer within the context, enabling us to construct diverse training samples for learning. Additionally, we propose a new Introspective Alignment Layer (IAL), which reasons over decomposed alignments using block-based self-attention. We evaluate our proposed method on the NarrativeQA reading comprehension benchmark, achieving state-of-the-art performance, improving existing baselines by $51\%$ relative improvement on BLEU-4 and $17\%$ relative improvement on Rouge-L. Extensive ablations confirm the effectiveness of our proposed IAL and CL components.