 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSTS: Conditional Semantic Textual Similarity
May 24, 2023



Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). As an example, the similarity between the sentences "The NBA player shoots a three-pointer." and "A man throws a tennis ball into the air to serve." is higher for the condition "The motion of the ball." (both upward) and lower for "The size of the ball." (one large and one small). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we evaluate several state-of-the-art models to demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging, with Spearman correlation scores of <50. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding.
Anthropomorphization of AI: Opportunities and Risks
May 24, 2023Anthropomorphization is the tendency to attribute human-like traits to non-human entities. It is prevalent in many social contexts -- children anthropomorphize toys, adults do so with brands, and it is a literary device. It is also a versatile tool in science, with behavioral psychology and evolutionary biology meticulously documenting its consequences. With widespread adoption of AI systems, and the push from stakeholders to make it human-like through alignment techniques, human voice, and pictorial avatars, the tendency for users to anthropomorphize it increases significantly. We take a dyadic approach to understanding this phenomenon with large language models (LLMs) by studying (1) the objective legal implications, as analyzed through the lens of the recent blueprint of AI bill of rights and the (2) subtle psychological aspects customization and anthropomorphization. We find that anthropomorphized LLMs customized for different user bases violate multiple provisions in the legislative blueprint. In addition, we point out that anthropomorphization of LLMs affects the influence they can have on their users, thus having the potential to fundamentally change the nature of human-AI interaction, with potential for manipulation and negative influence. With LLMs being hyper-personalized for vulnerable groups like children and patients among others, our work is a timely and important contribution. We propose a conservative strategy for the cautious use of anthropomorphization to improve trustworthiness of AI systems.
RL4F: Generating Natural Language Feedback with Reinforcement Learning for Repairing Model Outputs
May 15, 2023



Despite their unprecedented success, even the largest language models make mistakes. Similar to how humans learn and improve using feedback, previous work proposed providing language models with natural language feedback to guide them in repairing their outputs. Because human-generated critiques are expensive to obtain, researchers have devised learned critique generators in lieu of human critics while assuming one can train downstream models to utilize generated feedback. However, this approach does not apply to black-box or limited access models such as ChatGPT, as they cannot be fine-tuned. Moreover, in the era of large general-purpose language agents, fine-tuning is neither computationally nor spatially efficient as it results in multiple copies of the network. In this work, we introduce RL4F (Reinforcement Learning for Feedback), a multi-agent collaborative framework where the critique generator is trained to maximize end-task performance of GPT-3, a fixed model more than 200 times its size. RL4F produces critiques that help GPT-3 revise its outputs. We study three datasets for action planning, summarization and alphabetization and show improvements (~5% on average) in multiple text similarity metrics over strong baselines across all three tasks.
ProKnow: Process Knowledge for Safety Constrained and Explainable Question Generation for Mental Health Diagnostic Assistance
May 13, 2023Current Virtual Mental Health Assistants (VMHAs) provide counseling and suggestive care. They refrain from patient diagnostic assistance because they lack training in safety-constrained and specialized clinical process knowledge. In this work, we define Proknow as an ordered set of information that maps to evidence-based guidelines or categories of conceptual understanding to experts in a domain. We also introduce a new dataset of diagnostic conversations guided by safety constraints and Proknow that healthcare professionals use. We develop a method for natural language question generation (NLG) that collects diagnostic information from the patient interactively. We demonstrate the limitations of using state-of-the-art large-scale language models (LMs) on this dataset. Our algorithm models the process knowledge through explicitly modeling safety, knowledge capture, and explainability. LMs augmented with ProKnow guided method generated 89% safer questions in the depression and anxiety domain. The Explainability of the generated question is assessed by computing similarity with concepts in depression and anxiety knowledge bases. Overall, irrespective of the type of LMs augmented with our ProKnow, we achieved an average 82% improvement over simple pre-trained LMs on safety, explainability, and process-guided question generation. We qualitatively and quantitatively evaluate the efficacy of the proposed ProKnow-guided methods by introducing three new evaluation metrics for safety, explainability, and process knowledge adherence.
Toxicity in ChatGPT: Analyzing Persona-assigned Language Models
Apr 11, 2023



Large language models (LLMs) have shown incredible capabilities and transcended the natural language processing (NLP) community, with adoption throughout many services like healthcare, therapy, education, and customer service. Since users include people with critical information needs like students or patients engaging with chatbots, the safety of these systems is of prime importance. Therefore, a clear understanding of the capabilities and limitations of LLMs is necessary. To this end, we systematically evaluate toxicity in over half a million generations of ChatGPT, a popular dialogue-based LLM. We find that setting the system parameter of ChatGPT by assigning it a persona, say that of the boxer Muhammad Ali, significantly increases the toxicity of generations. Depending on the persona assigned to ChatGPT, its toxicity can increase up to 6x, with outputs engaging in incorrect stereotypes, harmful dialogue, and hurtful opinions. This may be potentially defamatory to the persona and harmful to an unsuspecting user. Furthermore, we find concerning patterns where specific entities (e.g., certain races) are targeted more than others (3x more) irrespective of the assigned persona, that reflect inherent discriminatory biases in the model. We hope that our findings inspire the broader AI community to rethink the efficacy of current safety guardrails and develop better techniques that lead to robust, safe, and trustworthy AI systems.
SPARTAN: Sparse Hierarchical Memory for Parameter-Efficient Transformers
Nov 29, 2022



Fine-tuning pre-trained language models (PLMs) achieves impressive performance on a range of downstream tasks, and their sizes have consequently been getting bigger. Since a different copy of the model is required for each task, this paradigm is infeasible for storage-constrained edge devices like mobile phones. In this paper, we propose SPARTAN, a parameter efficient (PE) and computationally fast architecture for edge devices that adds hierarchically organized sparse memory after each Transformer layer. SPARTAN freezes the PLM parameters and fine-tunes only its memory, thus significantly reducing storage costs by re-using the PLM backbone for different tasks. SPARTAN contains two levels of memory, with only a sparse subset of parents being chosen in the first level for each input, and children cells corresponding to those parents being used to compute an output representation. This sparsity combined with other architecture optimizations improves SPARTAN's throughput by over 90% during inference on a Raspberry Pi 4 when compared to PE baselines (adapters) while also outperforming the latter by 0.1 points on the GLUE benchmark. Further, it can be trained 34% faster in a few-shot setting, while performing within 0.9 points of adapters. Qualitative analysis shows that different parent cells in SPARTAN specialize in different topics, thus dividing responsibility efficiently.
Lila: A Unified Benchmark for Mathematical Reasoning
Oct 31, 2022Mathematical reasoning skills are essential for general-purpose intelligent systems to perform tasks from grocery shopping to climate modeling. Towards evaluating and improving AI systems in this domain, we propose LILA, a unified mathematical reasoning benchmark consisting of 23 diverse tasks along four dimensions: (i) mathematical abilities e.g., arithmetic, calculus (ii) language format e.g., question-answering, fill-in-the-blanks (iii) language diversity e.g., no language, simple language (iv) external knowledge e.g., commonsense, physics. We construct our benchmark by extending 20 datasets benchmark by collecting task instructions and solutions in the form of Python programs, thereby obtaining explainable solutions in addition to the correct answer. We additionally introduce two evaluation datasets to measure out-of-distribution performance and robustness to language perturbation. Finally, we introduce BHASKARA, a general-purpose mathematical reasoning model trained on LILA. Importantly, we find that multi-tasking leads to significant improvements (average relative improvement of 21.83% F1 score vs. single-task models), while the best performing model only obtains 60.40%, indicating the room for improvement in general mathematical reasoning and understanding.
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
Sep 29, 2022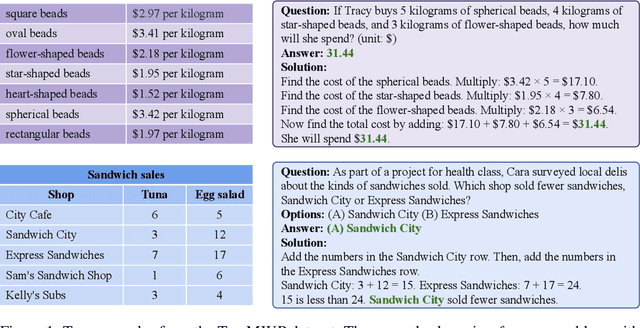
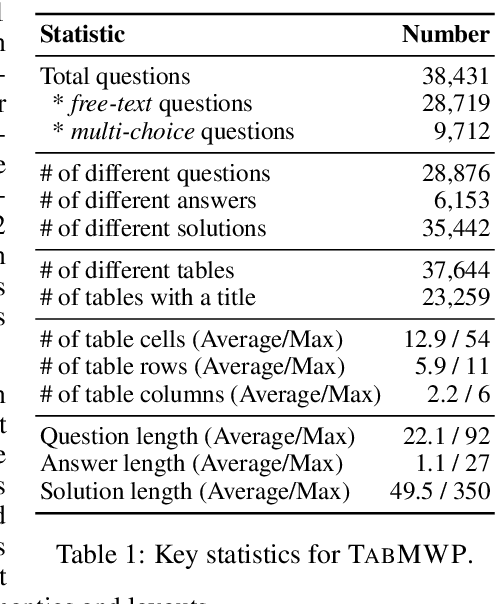
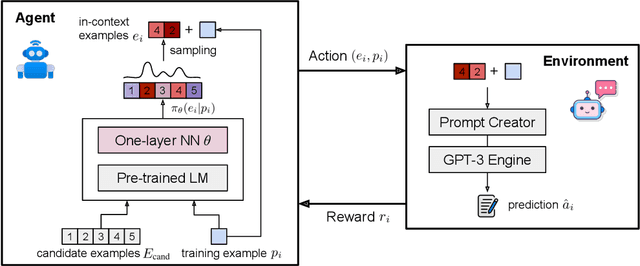
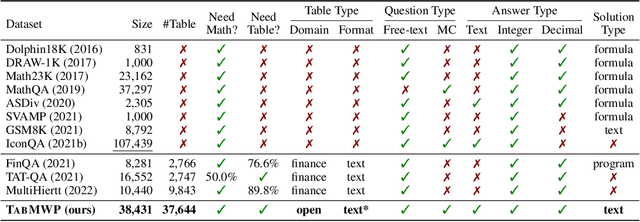
Mathematical reasoning, a core ability of human intelligence, presents unique challenges for machines in abstract thinking and logical reasoning. Recent large pre-trained language models such as GPT-3 have achieved remarkable progress on mathematical reasoning tasks written in text form, such as math word problems (MWP). However, it is unknown if the models can handle more complex problems that involve math reasoning over heterogeneous information, such as tabular data. To fill the gap, we present Tabular Math Word Problems (TabMWP), a new dataset containing 38,431 open-domain grade-level problems that require mathematical reasoning on both textual and tabular data. Each question in TabMWP is aligned with a tabular context, which is presented as an image, semi-structured text, and a structured table. There are two types of questions: free-text and multi-choice, and each problem is annotated with gold solutions to reveal the multi-step reasoning process. We evaluate different pre-trained models on TabMWP, including the GPT-3 model in a few-shot setting. As earlier studies suggest, since few-shot GPT-3 relies on the selection of in-context examples, its performance is unstable and can degrade to near chance. The unstable issue is more severe when handling complex problems like TabMWP. To mitigate this, we further propose a novel approach, PromptPG, which utilizes policy gradient to learn to select in-context examples from a small amount of training data and then constructs the corresponding prompt for the test example. Experimental results show that our method outperforms the best baseline by 5.31% on the accuracy metric and reduces the prediction variance significantly compared to random selection, which verifies its effectiveness in the selection of in-context examples.
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
Sep 20, 2022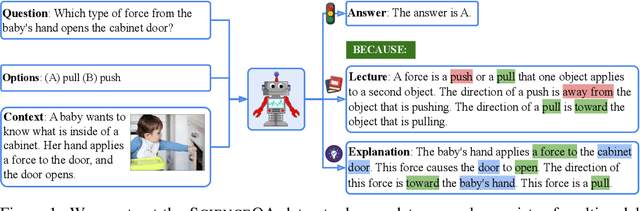
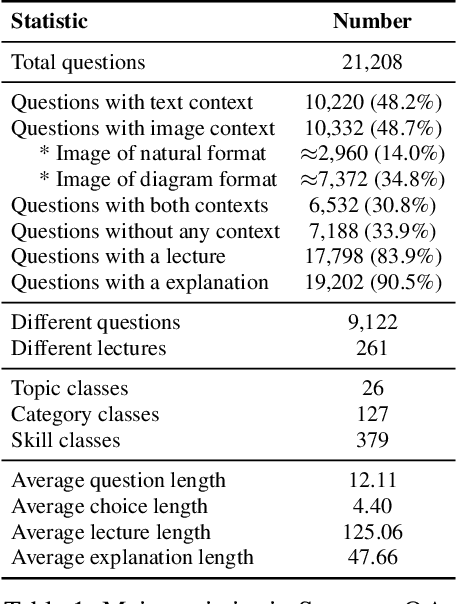
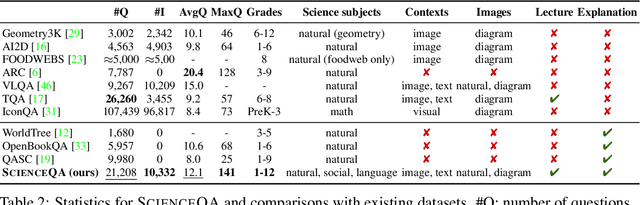
When answering a question, humans utilize the information available across different modalities to synthesize a consistent and complete chain of thought (CoT). This process is normally a black box in the case of deep learning models like large-scale language models. Recently, science question benchmarks have been used to diagnose the multi-hop reasoning ability and interpretability of an AI system. However, existing datasets fail to provide annotations for the answers, or are restricted to the textual-only modality, small scales, and limited domain diversity. To this end, we present Science Question Answering (SQA), a new benchmark that consists of ~21k multimodal multiple choice questions with a diverse set of science topics and annotations of their answers with corresponding lectures and explanations. We further design language models to learn to generate lectures and explanations as the chain of thought (CoT) to mimic the multi-hop reasoning process when answering SQA questions. SQA demonstrates the utility of CoT in language models, as CoT improves the question answering performance by 1.20% in few-shot GPT-3 and 3.99% in fine-tuned UnifiedQA. We also explore the upper bound for models to leverage explanations by feeding those in the input; we observe that it improves the few-shot performance of GPT-3 by 18.96%. Our analysis further shows that language models, similar to humans, benefit from explanations to learn from fewer data and achieve the same performance with just 40% of the data.
NumGLUE: A Suite of Fundamental yet Challenging Mathematical Reasoning Tasks
Apr 12, 2022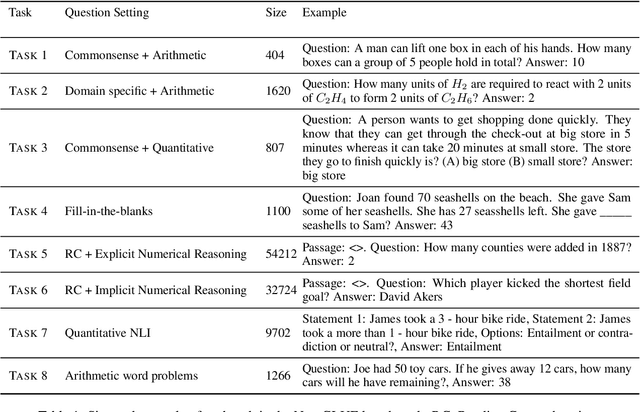
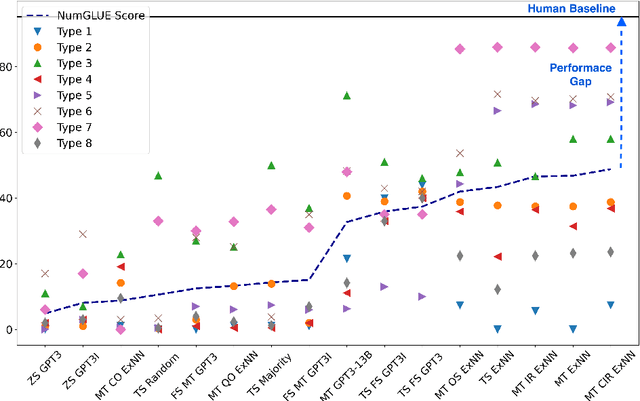
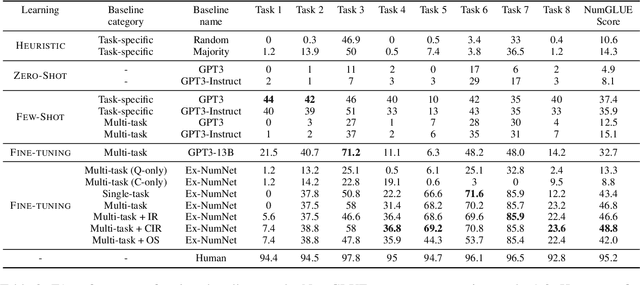

Given the ubiquitous nature of numbers in text, reasoning with numbers to perform simple calculations is an important skill of AI systems. While many datasets and models have been developed to this end, state-of-the-art AI systems are brittle; failing to perform the underlying mathematical reasoning when they appear in a slightly different scenario. Drawing inspiration from GLUE that was proposed in the context of natural language understanding, we propose NumGLUE, a multi-task benchmark that evaluates the performance of AI systems on eight different tasks, that at their core require simple arithmetic understanding. We show that this benchmark is far from being solved with neural models including state-of-the-art large-scale language models performing significantly worse than humans (lower by 46.4%). Further, NumGLUE promotes sharing knowledge across tasks, especially those with limited training data as evidenced by the superior performance (average gain of 3.4% on each task) when a model is jointly trained on all the tasks as opposed to task-specific modeling. Finally, we hope that NumGLUE will encourage systems that perform robust and general arithmetic reasoning within language, a first step towards being able to perform more complex mathematical reasoning.