 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfusing Commonsense World Models with Graph Knowledge
Jan 13, 2023While language models have become more capable of producing compelling language, we find there are still gaps in maintaining consistency, especially when describing events in a dynamically changing world. We study the setting of generating narratives in an open world text adventure game, where a graph representation of the underlying game state can be used to train models that consume and output both grounded graph representations and natural language descriptions and actions. We build a large set of tasks by combining crowdsourced and simulated gameplays with a novel dataset of complex actions in order to to construct such models. We find it is possible to improve the consistency of action narration models by training on graph contexts and targets, even if graphs are not present at test time. This is shown both in automatic metrics and human evaluations. We plan to release our code, the new set of tasks, and best performing models.
Collecting Interactive Multi-modal Datasets for Grounded Language Understanding
Nov 18, 2022


Human intelligence can remarkably adapt quickly to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research which can enable similar capabilities in machines, we made the following contributions (1) formalized the collaborative embodied agent using natural language task; (2) developed a tool for extensive and scalable data collection; and (3) collected the first dataset for interactive grounded language understanding.
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory
Oct 11, 2022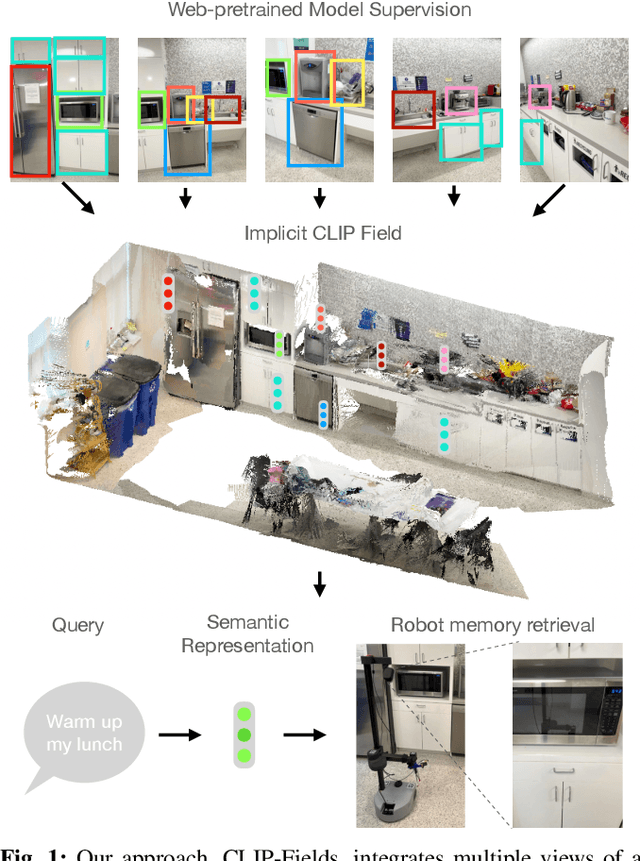
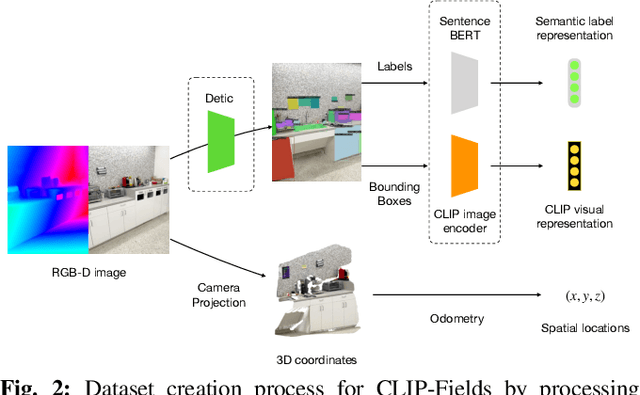
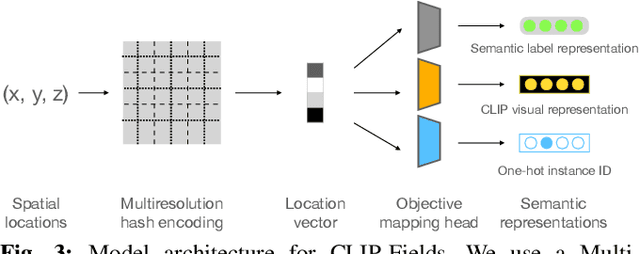
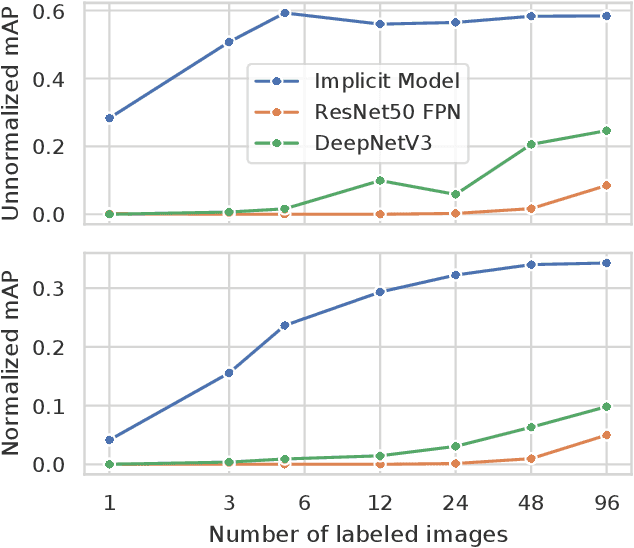
We propose CLIP-Fields, an implicit scene model that can be trained with no direct human supervision. This model learns a mapping from spatial locations to semantic embedding vectors. The mapping can then be used for a variety of tasks, such as segmentation, instance identification, semantic search over space, and view localization. Most importantly, the mapping can be trained with supervision coming only from web-image and web-text trained models such as CLIP, Detic, and Sentence-BERT. When compared to baselines like Mask-RCNN, our method outperforms on few-shot instance identification or semantic segmentation on the HM3D dataset with only a fraction of the examples. Finally, we show that using CLIP-Fields as a scene memory, robots can perform semantic navigation in real-world environments. Our code and demonstrations are available here: https://mahis.life/clip-fields/
BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage
Aug 10, 2022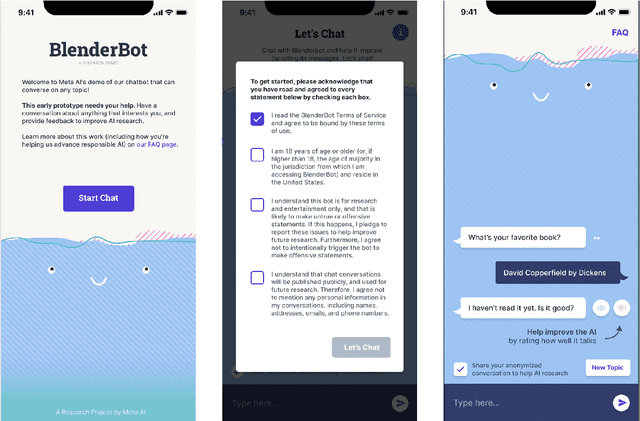
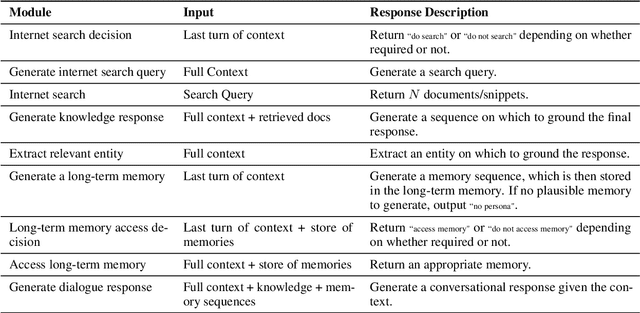
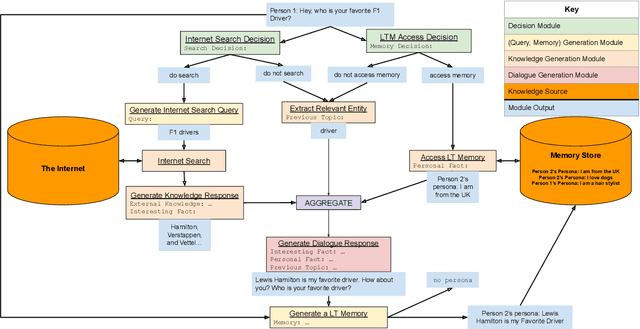
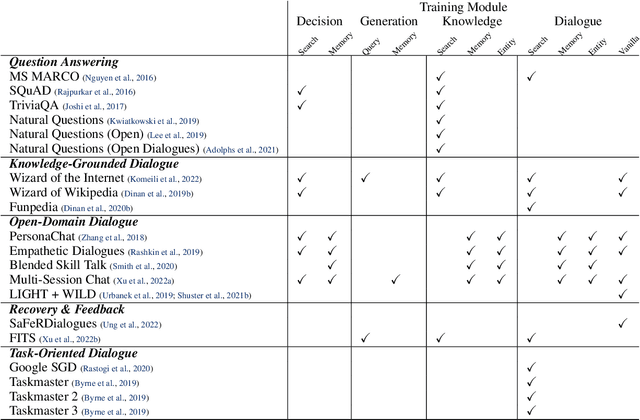
We present BlenderBot 3, a 175B parameter dialogue model capable of open-domain conversation with access to the internet and a long-term memory, and having been trained on a large number of user defined tasks. We release both the model weights and code, and have also deployed the model on a public web page to interact with organic users. This technical report describes how the model was built (architecture, model and training scheme), and details of its deployment, including safety mechanisms. Human evaluations show its superiority to existing open-domain dialogue agents, including its predecessors (Roller et al., 2021; Komeili et al., 2022). Finally, we detail our plan for continual learning using the data collected from deployment, which will also be publicly released. The goal of this research program is thus to enable the community to study ever-improving responsible agents that learn through interaction.
IGLU 2022: Interactive Grounded Language Understanding in a Collaborative Environment at NeurIPS 2022
May 27, 2022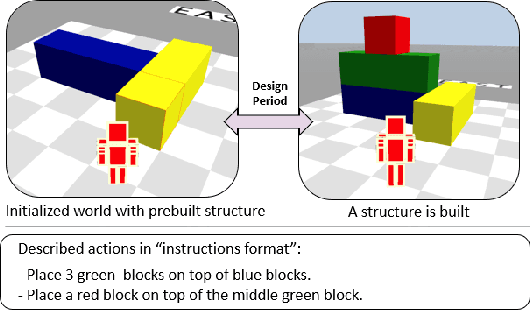

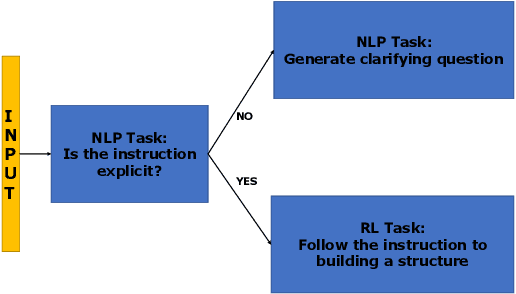
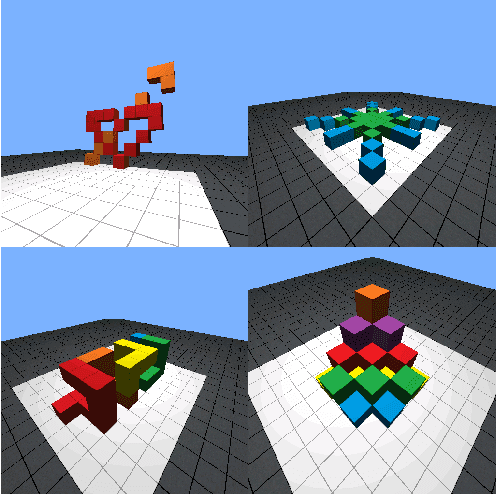
Human intelligence has the remarkable ability to adapt to new tasks and environments quickly. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment. The primary goal of the competition is to approach the problem of how to develop interactive embodied agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants. This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the crucial challenges in AI. Another critical aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Interactive Grounded Language Understanding in a Collaborative Environment: IGLU 2021
May 05, 2022
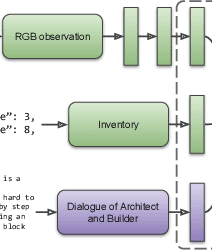
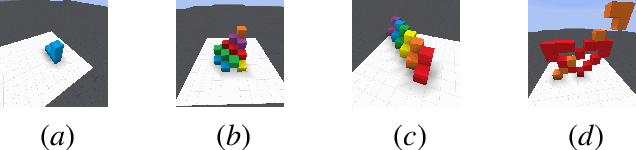
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose \emph{IGLU: Interactive Grounded Language Understanding in a Collaborative Environment}. The primary goal of the competition is to approach the problem of how to build interactive agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
* arXiv admin note: substantial text overlap with arXiv:2110.06536
Many Episode Learning in a Modular Embodied Agent via End-to-End Interaction
Apr 19, 2022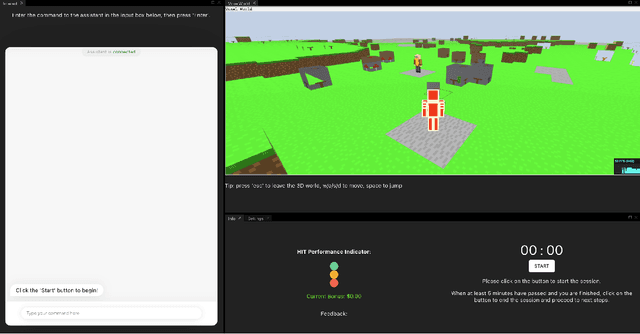


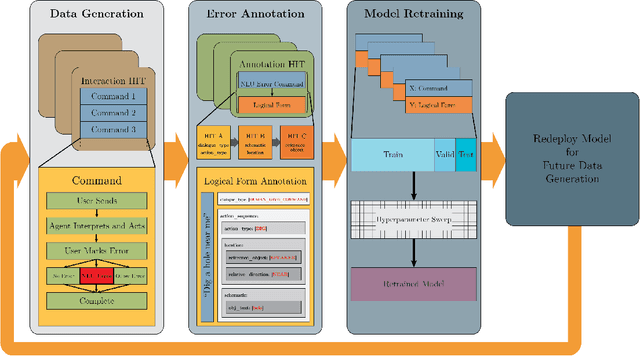
In this work we give a case study of an embodied machine-learning (ML) powered agent that improves itself via interactions with crowd-workers. The agent consists of a set of modules, some of which are learned, and others heuristic. While the agent is not "end-to-end" in the ML sense, end-to-end interaction is a vital part of the agent's learning mechanism. We describe how the design of the agent works together with the design of multiple annotation interfaces to allow crowd-workers to assign credit to module errors from end-to-end interactions, and to label data for individual modules. Over multiple automated human-agent interaction, credit assignment, data annotation, and model re-training and re-deployment, rounds we demonstrate agent improvement.
Language Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion
Mar 29, 2022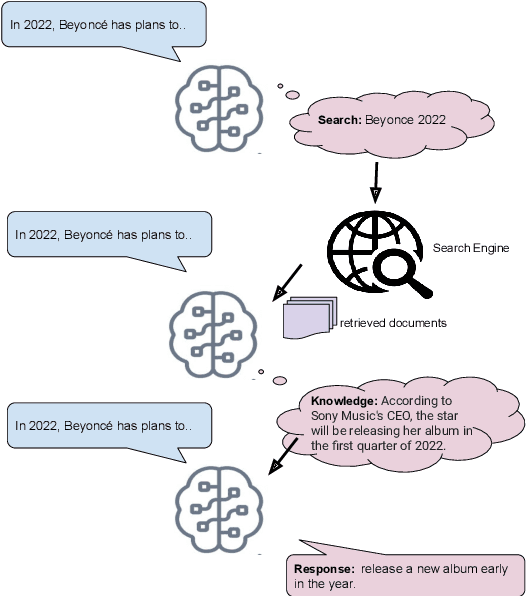

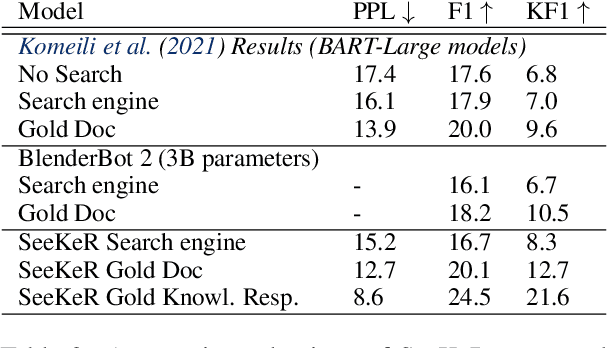

Language models (LMs) have recently been shown to generate more factual responses by employing modularity (Zhou et al., 2021) in combination with retrieval (Adolphs et al., 2021). We extend the recent approach of Adolphs et al. (2021) to include internet search as a module. Our SeeKeR (Search engine->Knowledge->Response) method thus applies a single LM to three modular tasks in succession: search, generating knowledge, and generating a final response. We show that, when using SeeKeR as a dialogue model, it outperforms the state-of-the-art model BlenderBot 2 (Chen et al., 2021) on open-domain knowledge-grounded conversations for the same number of parameters, in terms of consistency, knowledge and per-turn engagingness. SeeKeR applied to topical prompt completions as a standard language model outperforms GPT2 (Radford et al., 2019) and GPT3 (Brown et al., 2020) in terms of factuality and topicality, despite GPT3 being a vastly larger model. Our code and models are made publicly available.
Can I see an Example? Active Learning the Long Tail of Attributes and Relations
Mar 11, 2022
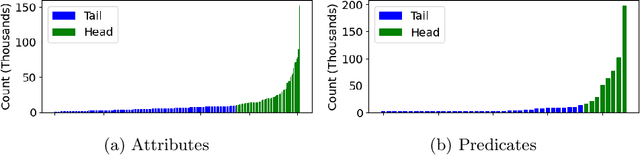
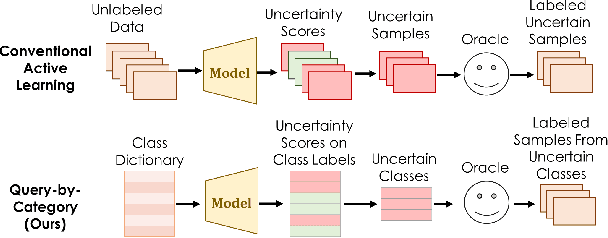
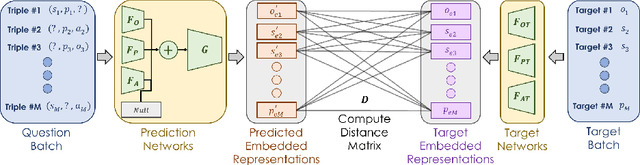
There has been significant progress in creating machine learning models that identify objects in scenes along with their associated attributes and relationships; however, there is a large gap between the best models and human capabilities. One of the major reasons for this gap is the difficulty in collecting sufficient amounts of annotated relations and attributes for training these systems. While some attributes and relations are abundant, the distribution in the natural world and existing datasets is long tailed. In this paper, we address this problem by introducing a novel incremental active learning framework that asks for attributes and relations in visual scenes. While conventional active learning methods ask for labels of specific examples, we flip this framing to allow agents to ask for examples from specific categories. Using this framing, we introduce an active sampling method that asks for examples from the tail of the data distribution and show that it outperforms classical active learning methods on Visual Genome.
Am I Me or You? State-of-the-Art Dialogue Models Cannot Maintain an Identity
Dec 10, 2021
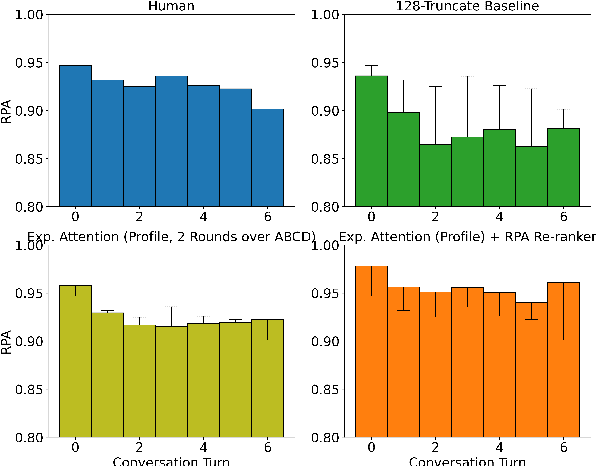
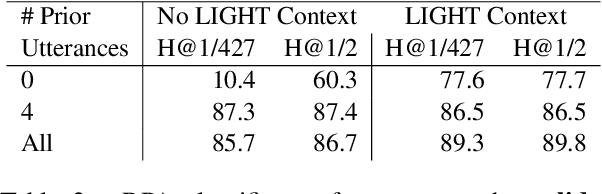
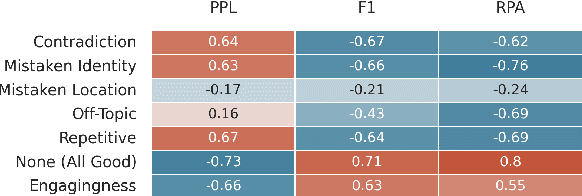
State-of-the-art dialogue models still often stumble with regards to factual accuracy and self-contradiction. Anecdotally, they have been observed to fail to maintain character identity throughout discourse; and more specifically, may take on the role of their interlocutor. In this work we formalize and quantify this deficiency, and show experimentally through human evaluations that this is indeed a problem. In contrast, we show that discriminative models trained specifically to recognize who is speaking can perform well; and further, these can be used as automated metrics. Finally, we evaluate a wide variety of mitigation methods, including changes to model architecture, training protocol, and decoding strategy. Our best models reduce mistaken identity issues by nearly 65% according to human annotators, while simultaneously improving engagingness. Despite these results, we find that maintaining character identity still remains a challenging problem.