 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaPQA: Knowledge-Augmented Product Question-Answering
Jul 22, 2024



Question-answering for domain-specific applications has recently attracted much interest due to the latest advancements in large language models (LLMs). However, accurately assessing the performance of these applications remains a challenge, mainly due to the lack of suitable benchmarks that effectively simulate real-world scenarios. To address this challenge, we introduce two product question-answering (QA) datasets focused on Adobe Acrobat and Photoshop products to help evaluate the performance of existing models on domain-specific product QA tasks. Additionally, we propose a novel knowledge-driven RAG-QA framework to enhance the performance of the models in the product QA task. Our experiments demonstrated that inducing domain knowledge through query reformulation allowed for increased retrieval and generative performance when compared to standard RAG-QA methods. This improvement, however, is slight, and thus illustrates the challenge posed by the datasets introduced.
CASPR: Automated Evaluation Metric for Contrastive Summarization
Apr 23, 2024



Summarizing comparative opinions about entities (e.g., hotels, phones) from a set of source reviews, often referred to as contrastive summarization, can considerably aid users in decision making. However, reliably measuring the contrastiveness of the output summaries without relying on human evaluations remains an open problem. Prior work has proposed token-overlap based metrics, Distinctiveness Score, to measure contrast which does not take into account the sensitivity to meaning-preserving lexical variations. In this work, we propose an automated evaluation metric CASPR to better measure contrast between a pair of summaries. Our metric is based on a simple and light-weight method that leverages natural language inference (NLI) task to measure contrast by segmenting reviews into single-claim sentences and carefully aggregating NLI scores between them to come up with a summary-level score. We compare CASPR with Distinctiveness Score and a simple yet powerful baseline based on BERTScore. Our results on a prior dataset CoCoTRIP demonstrate that CASPR can more reliably capture the contrastiveness of the summary pairs compared to the baselines.
Evaluating Robustness of Dialogue Summarization Models in the Presence of Naturally Occurring Variations
Nov 15, 2023



Dialogue summarization task involves summarizing long conversations while preserving the most salient information. Real-life dialogues often involve naturally occurring variations (e.g., repetitions, hesitations) and existing dialogue summarization models suffer from performance drop on such conversations. In this study, we systematically investigate the impact of such variations on state-of-the-art dialogue summarization models using publicly available datasets. To simulate real-life variations, we introduce two types of perturbations: utterance-level perturbations that modify individual utterances with errors and language variations, and dialogue-level perturbations that add non-informative exchanges (e.g., repetitions, greetings). We conduct our analysis along three dimensions of robustness: consistency, saliency, and faithfulness, which capture different aspects of the summarization model's performance. We find that both fine-tuned and instruction-tuned models are affected by input variations, with the latter being more susceptible, particularly to dialogue-level perturbations. We also validate our findings via human evaluation. Finally, we investigate if the robustness of fine-tuned models can be improved by training them with a fraction of perturbed data and observe that this approach is insufficient to address robustness challenges with current models and thus warrants a more thorough investigation to identify better solutions. Overall, our work highlights robustness challenges in dialogue summarization and provides insights for future research.
Examining Political Rhetoric with Epistemic Stance Detection
Jan 06, 2023Participants in political discourse employ rhetorical strategies -- such as hedging, attributions, or denials -- to display varying degrees of belief commitments to claims proposed by themselves or others. Traditionally, political scientists have studied these epistemic phenomena through labor-intensive manual content analysis. We propose to help automate such work through epistemic stance prediction, drawn from research in computational semantics, to distinguish at the clausal level what is asserted, denied, or only ambivalently suggested by the author or other mentioned entities (belief holders). We first develop a simple RoBERTa-based model for multi-source stance predictions that outperforms more complex state-of-the-art modeling. Then we demonstrate its novel application to political science by conducting a large-scale analysis of the Mass Market Manifestos corpus of U.S. political opinion books, where we characterize trends in cited belief holders -- respected allies and opposed bogeymen -- across U.S. political ideologies.
DEMETR: Diagnosing Evaluation Metrics for Translation
Oct 25, 2022



While machine translation evaluation metrics based on string overlap (e.g., BLEU) have their limitations, their computations are transparent: the BLEU score assigned to a particular candidate translation can be traced back to the presence or absence of certain words. The operations of newer learned metrics (e.g., BLEURT, COMET), which leverage pretrained language models to achieve higher correlations with human quality judgments than BLEU, are opaque in comparison. In this paper, we shed light on the behavior of these learned metrics by creating DEMETR, a diagnostic dataset with 31K English examples (translated from 10 source languages) for evaluating the sensitivity of MT evaluation metrics to 35 different linguistic perturbations spanning semantic, syntactic, and morphological error categories. All perturbations were carefully designed to form minimal pairs with the actual translation (i.e., differ in only one aspect). We find that learned metrics perform substantially better than string-based metrics on DEMETR. Additionally, learned metrics differ in their sensitivity to various phenomena (e.g., BERTScore is sensitive to untranslated words but relatively insensitive to gender manipulation, while COMET is much more sensitive to word repetition than to aspectual changes). We publicly release DEMETR to spur more informed future development of machine translation evaluation metrics
ezCoref: Towards Unifying Annotation Guidelines for Coreference Resolution
Oct 13, 2022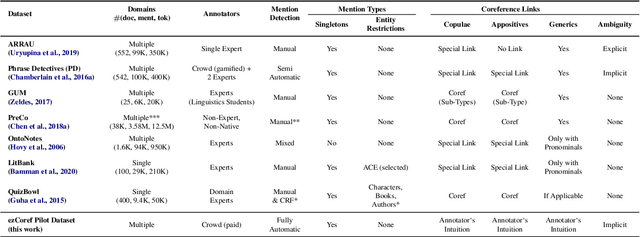
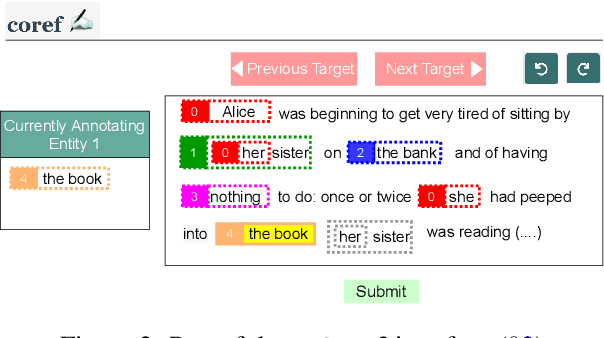


Large-scale, high-quality corpora are critical for advancing research in coreference resolution. However, existing datasets vary in their definition of coreferences and have been collected via complex and lengthy guidelines that are curated for linguistic experts. These concerns have sparked a growing interest among researchers to curate a unified set of guidelines suitable for annotators with various backgrounds. In this work, we develop a crowdsourcing-friendly coreference annotation methodology, ezCoref, consisting of an annotation tool and an interactive tutorial. We use ezCoref to re-annotate 240 passages from seven existing English coreference datasets (spanning fiction, news, and multiple other domains) while teaching annotators only cases that are treated similarly across these datasets. Surprisingly, we find that reasonable quality annotations were already achievable (>90% agreement between the crowd and expert annotations) even without extensive training. On carefully analyzing the remaining disagreements, we identify the presence of linguistic cases that our annotators unanimously agree upon but lack unified treatments (e.g., generic pronouns, appositives) in existing datasets. We propose the research community should revisit these phenomena when curating future unified annotation guidelines.
Solomon at SemEval-2020 Task 11: Ensemble Architecture for Fine-Tuned Propaganda Detection in News Articles
Sep 16, 2020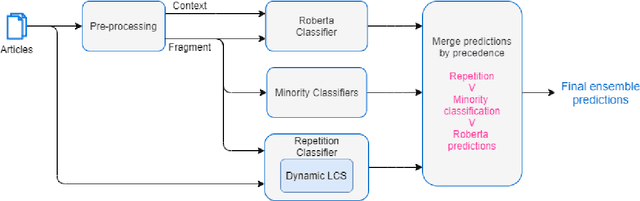
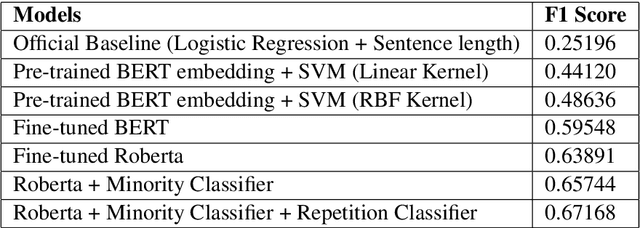
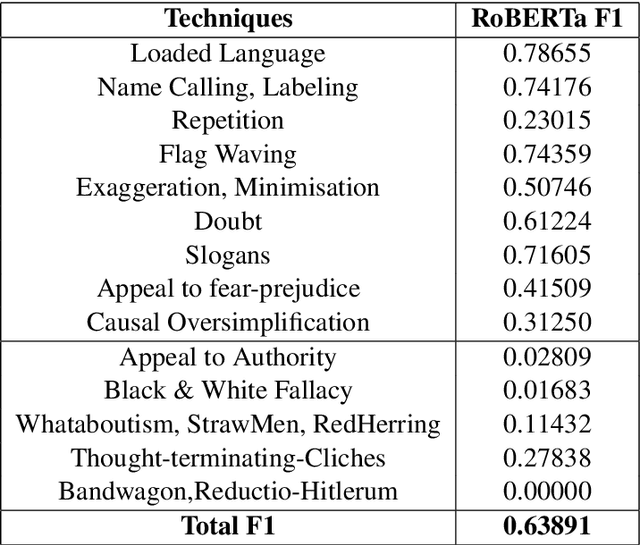
This paper describes our system (Solomon) details and results of participation in the SemEval 2020 Task 11 "Detection of Propaganda Techniques in News Articles"\cite{DaSanMartinoSemeval20task11}. We participated in Task "Technique Classification" (TC) which is a multi-class classification task. To address the TC task, we used RoBERTa based transformer architecture for fine-tuning on the propaganda dataset. The predictions of RoBERTa were further fine-tuned by class-dependent-minority-class classifiers. A special classifier, which employs dynamically adapted Least Common Sub-sequence algorithm, is used to adapt to the intricacies of repetition class. Compared to the other participating systems, our submission is ranked 4th on the leaderboard.