 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Robustness Assessment for Machine Learning based Network Intrusion Detection Systems
Jun 10, 2026Network Intrusion Detection Systems (NIDS) heavily utlize Machine Learning (ML) but ML models can be manipulated via adversarial attacks. These attacks add carefully crafted perturbations to network traffic data that leads to misclassifications. While prior work has demonstrated adversarial vulnerabilities in isolated settings, systematic cross-architecture as well as class and category of attack based comparisons under controlled attack conditions remain limited, leaving practitioners without clear guidance on which models to deploy in adversarial environments. This paper asks a simple question: what type of classifier architectures actually hold up when attackers try to manipulate the systems? We put three popular architectures through their paces: a 1D Convolutional Neural Network, a Long Short-Term Memory (LSTM) network, and a Random Forest (RF) ensemble. Using the ACI-IoT-2023 dataset (over 1.2 million samples spanning 12 attack types), we subject each model with FGSM and PGD adversarial attacks, which apply gradient-based perturbations in normalized feature space consistent with established adversarial ML evaluation protocols, at perturbation budgets ranging from $ε=0.01$ to $ε=0.1$. Surprisingly, Random Forest achieved near-perfect baseline accuracy (99.98\%), yet collapsed catastrophically under attack, dropping 73 percentage points at the smallest perturbation we tested. CNN, on the other hand, retained 95.5\% accuracy at $ε=0.01$ and degraded gracefully as perturbations increased. LSTM fell somewhere in between. These findings flip the conventional wisdom where high baseline accuracy means nothing if a model shatters at the first sign of adversarial pressure. For practitioners deploying intrusion detection in adversarial environments, we recommend CNN-based architectures and provide scenario-specific deployment guidance.
Solomon at SemEval-2020 Task 11: Ensemble Architecture for Fine-Tuned Propaganda Detection in News Articles
Sep 16, 2020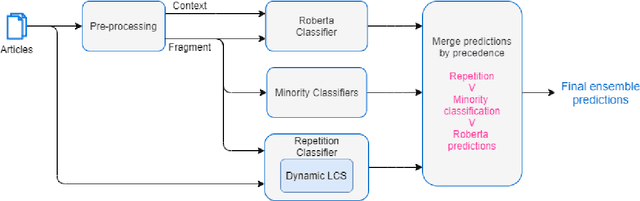
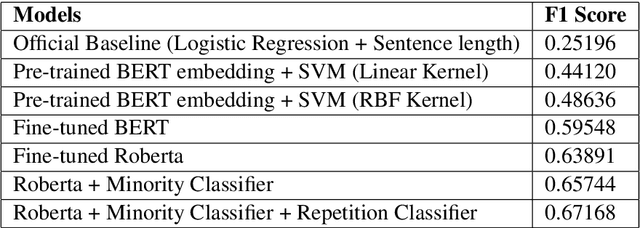
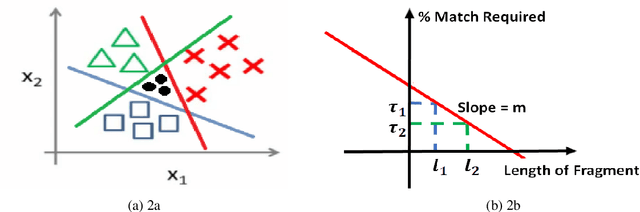
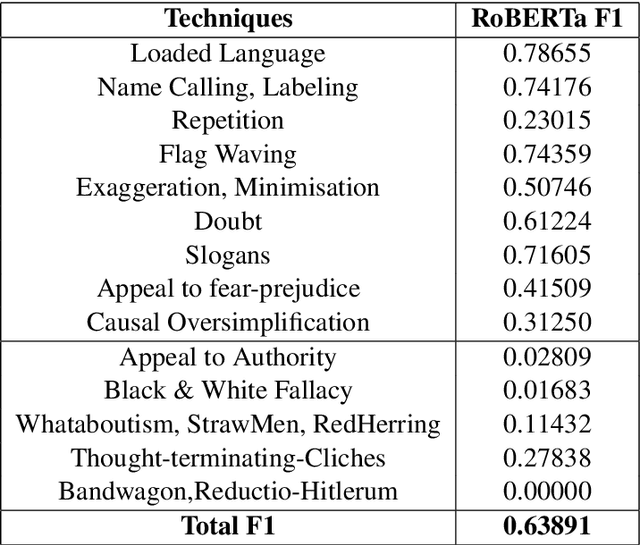
This paper describes our system (Solomon) details and results of participation in the SemEval 2020 Task 11 "Detection of Propaganda Techniques in News Articles"\cite{DaSanMartinoSemeval20task11}. We participated in Task "Technique Classification" (TC) which is a multi-class classification task. To address the TC task, we used RoBERTa based transformer architecture for fine-tuning on the propaganda dataset. The predictions of RoBERTa were further fine-tuned by class-dependent-minority-class classifiers. A special classifier, which employs dynamically adapted Least Common Sub-sequence algorithm, is used to adapt to the intricacies of repetition class. Compared to the other participating systems, our submission is ranked 4th on the leaderboard.