 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Search Method of Technology Video based on Adversarial Learning and Feature Fusion
Oct 11, 2022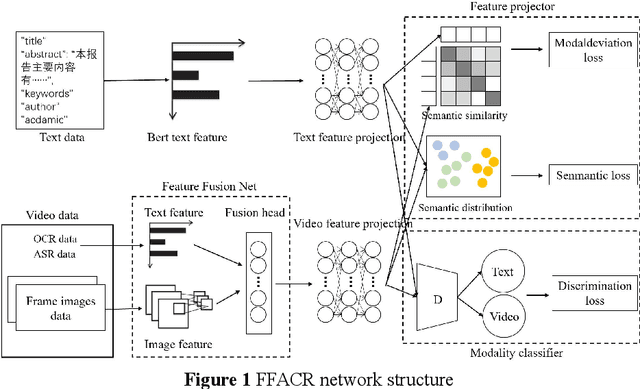
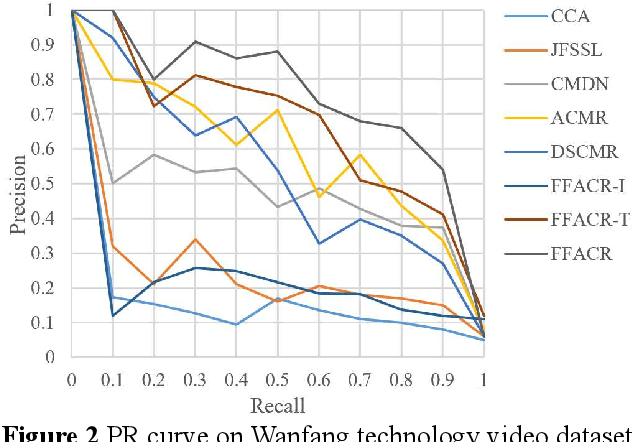
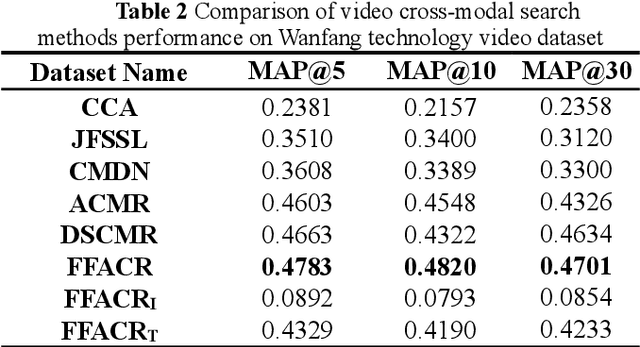
Technology videos contain rich multi-modal information. In cross-modal information search, the data features of different modalities cannot be compared directly, so the semantic gap between different modalities is a key problem that needs to be solved. To address the above problems, this paper proposes a novel Feature Fusion based Adversarial Cross-modal Retrieval method (FFACR) to achieve text-to-video matching, ranking and searching. The proposed method uses the framework of adversarial learning to construct a video multimodal feature fusion network and a feature mapping network as generator, a modality discrimination network as discriminator. Multi-modal features of videos are obtained by the feature fusion network. The feature mapping network projects multi-modal features into the same semantic space based on semantics and similarity. The modality discrimination network is responsible for determining the original modality of features. Generator and discriminator are trained alternately based on adversarial learning, so that the data obtained by the feature mapping network is semantically consistent with the original data and the modal features are eliminated, and finally the similarity is used to rank and obtain the search results in the semantic space. Experimental results demonstrate that the proposed method performs better in text-to-video search than other existing methods, and validate the effectiveness of the method on the self-built datasets of technology videos.
Probabilities of Causation: Adequate Size of Experimental and Observational Samples
Oct 10, 2022
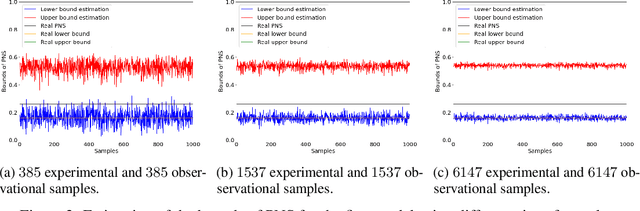
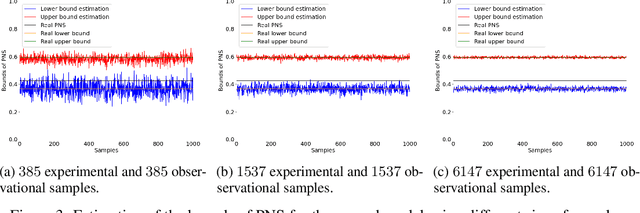
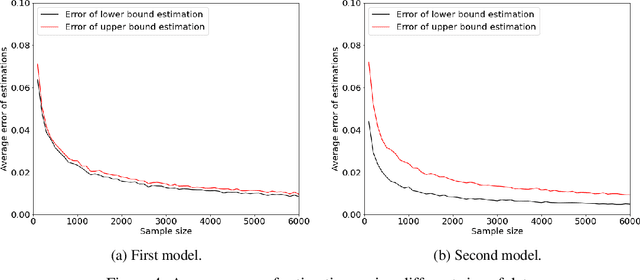
The probabilities of causation are commonly used to solve decision-making problems. Tian and Pearl derived sharp bounds for the probability of necessity and sufficiency (PNS), the probability of sufficiency (PS), and the probability of necessity (PN) using experimental and observational data. The assumption is that one is in possession of a large enough sample to permit an accurate estimation of the experimental and observational distributions. In this study, we present a method for determining the sample size needed for such estimation, when a given confidence interval (CI) is specified. We further show by simulation that the proposed sample size delivered stable estimations of the bounds of PNS.
Unit Selection: Case Study and Comparison with A/B Test Heuristic
Oct 10, 2022
The unit selection problem defined by Li and Pearl identifies individuals who have desired counterfactual behavior patterns, for example, individuals who would respond positively if encouraged and would not otherwise. Li and Pearl showed by example that their unit selection model is beyond the A/B test heuristics. In this paper, we reveal the essence of the A/B test heuristics, which are exceptional cases of the benefit function defined by Li and Pearl. Furthermore, We provided more simulated use cases of Li-Pearl's unit selection model to help decision-makers apply their model correctly, explaining that A/B test heuristics are generally problematic.
Scientific Paper Classification Based on Graph Neural Network with Hypergraph Self-attention Mechanism
Oct 07, 2022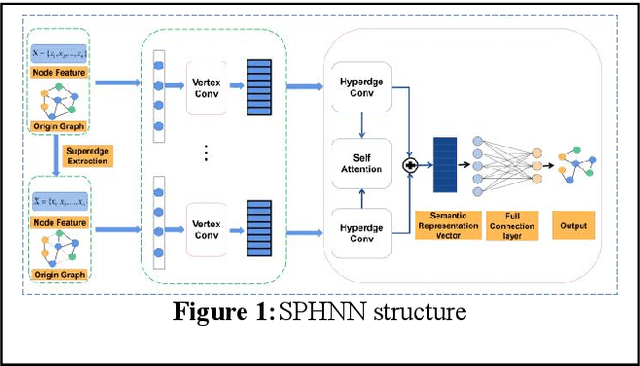
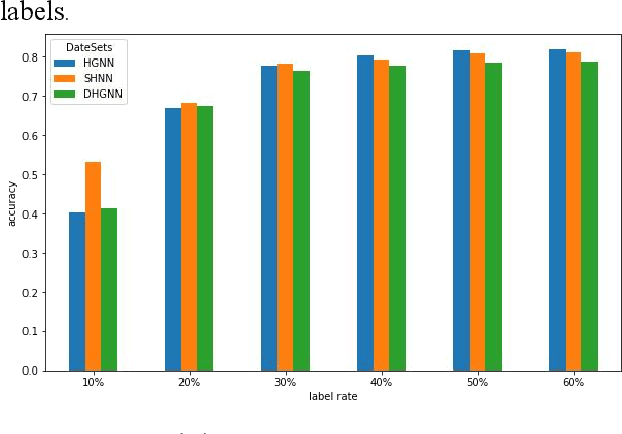
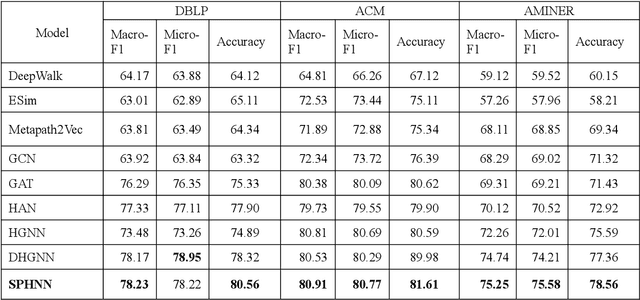
The number of scientific papers has increased rapidly in recent years. How to make good use of scientific papers for research is very important. Through the high-quality classification of scientific papers, researchers can quickly find the resource content they need from the massive scientific resources. The classification of scientific papers will effectively help researchers filter redundant information, obtain search results quickly and accurately, and improve the search quality, which is necessary for scientific resource management. This paper proposed a science-technique paper classification method based on hypergraph neural network(SPHNN). In the heterogeneous information network of scientific papers, the repeated high-order subgraphs are modeled as hyperedges composed of multiple related nodes. Then the whole heterogeneous information network is transformed into a hypergraph composed of different hyperedges. The graph convolution operation is carried out on the hypergraph structure, and the hyperedges self-attention mechanism is introduced to aggregate different types of nodes in the hypergraph, so that the final node representation can effectively maintain high-order nearest neighbor relationships and complex semantic information. Finally, by comparing with other methods, we proved that the model proposed in this paper has improved its performance.
Embedding Representation of Academic Heterogeneous Information Networks Based on Federated Learning
Oct 07, 2022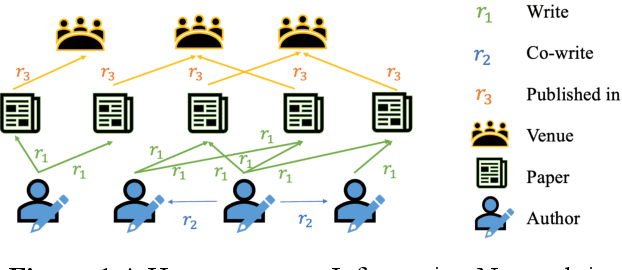
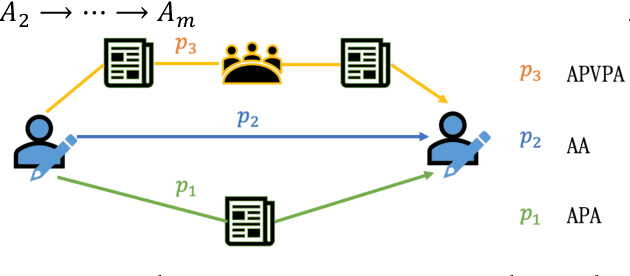
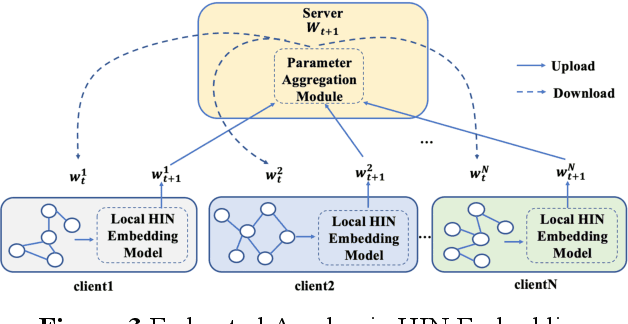
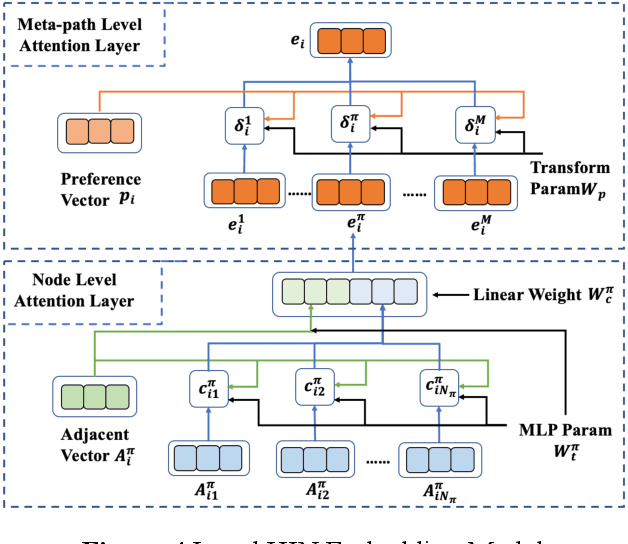
Academic networks in the real world can usually be portrayed as heterogeneous information networks (HINs) with multi-type, universally connected nodes and multi-relationships. Some existing studies for the representation learning of homogeneous information networks cannot be applicable to heterogeneous information networks because of the lack of ability to issue heterogeneity. At the same time, data has become a factor of production, playing an increasingly important role. Due to the closeness and blocking of businesses among different enterprises, there is a serious phenomenon of data islands. To solve the above challenges, aiming at the data information of scientific research teams closely related to science and technology, we proposed an academic heterogeneous information network embedding representation learning method based on federated learning (FedAHE), which utilizes node attention and meta path attention mechanism to learn low-dimensional, dense and real-valued vector representations while preserving the rich topological information and meta-path-based semantic information of nodes in network. Moreover, we combined federated learning with the representation learning of HINs composed of scientific research teams and put forward a federal training mechanism based on dynamic weighted aggregation of parameters (FedDWA) to optimize the node embeddings of HINs. Through sufficient experiments, the efficiency, accuracy and feasibility of our proposed framework are demonstrated.
Rethinking Normalization Methods in Federated Learning
Oct 07, 2022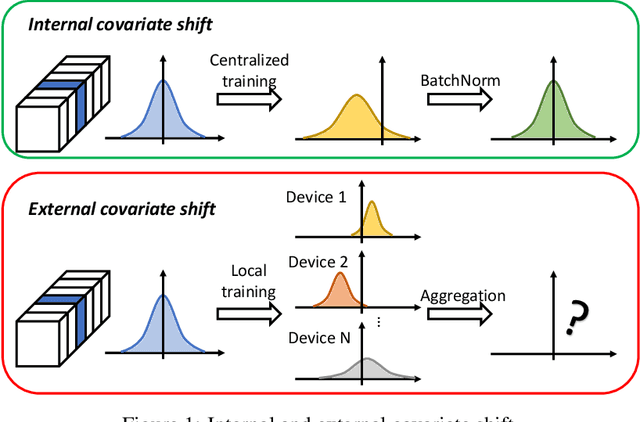

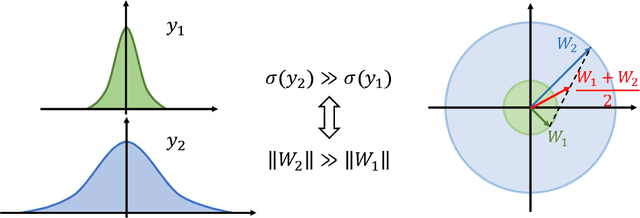
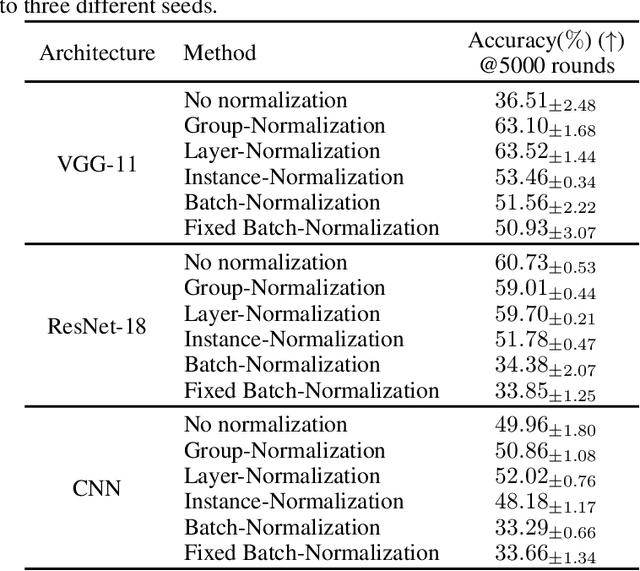
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. In this work, we explicitly uncover external covariate shift problem in FL, which is caused by the independent local training processes on different devices. We demonstrate that external covariate shifts will lead to the obliteration of some devices' contributions to the global model. Further, we show that normalization layers are indispensable in FL since their inherited properties can alleviate the problem of obliterating some devices' contributions. However, recent works have shown that batch normalization, which is one of the standard components in many deep neural networks, will incur accuracy drop of the global model in FL. The essential reason for the failure of batch normalization in FL is poorly studied. We unveil that external covariate shift is the key reason why batch normalization is ineffective in FL. We also show that layer normalization is a better choice in FL which can mitigate the external covariate shift and improve the performance of the global model. We conduct experiments on CIFAR10 under non-IID settings. The results demonstrate that models with layer normalization converge fastest and achieve the best or comparable accuracy for three different model architectures.
Scientific and Technological News Recommendation Based on Knowledge Graph with User Perception
Oct 07, 2022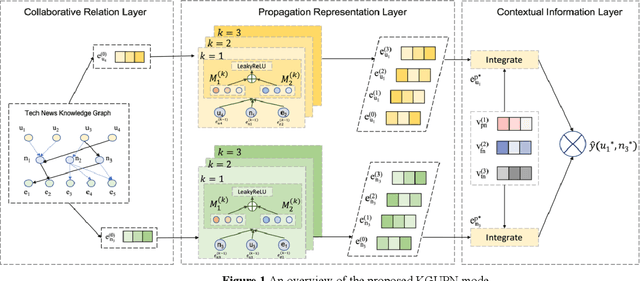
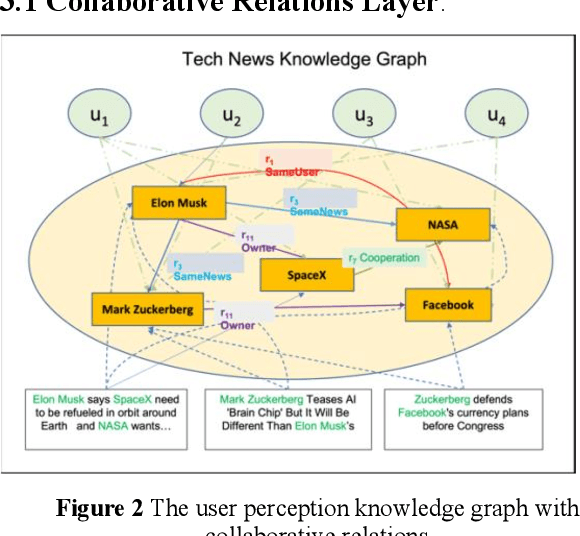
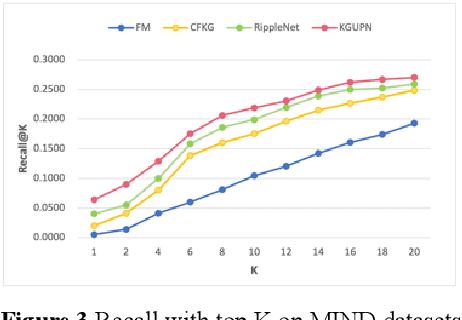
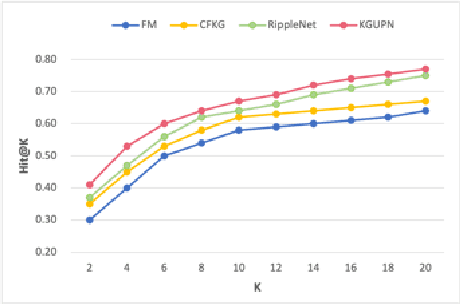
Existing research usually utilizes side information such as social network or item attributes to improve the performance of collaborative filtering-based recommender systems. In this paper, the knowledge graph with user perception is used to acquire the source of side information. We proposed KGUPN to address the limitations of existing embedding-based and path-based knowledge graph-aware recommendation methods, an end-to-end framework that integrates knowledge graph and user awareness into scientific and technological news recommendation systems. KGUPN contains three main layers, which are the propagation representation layer, the contextual information layer and collaborative relation layer. The propagation representation layer improves the representation of an entity by recursively propagating embeddings from its neighbors (which can be users, news, or relationships) in the knowledge graph. The contextual information layer improves the representation of entities by encoding the behavioral information of entities appearing in the news. The collaborative relation layer complements the relationship between entities in the news knowledge graph. Experimental results on real-world datasets show that KGUPN significantly outperforms state-of-the-art baselines in scientific and technological news recommendation.
Fed-CBS: A Heterogeneity-Aware Client Sampling Mechanism for Federated Learning via Class-Imbalance Reduction
Sep 30, 2022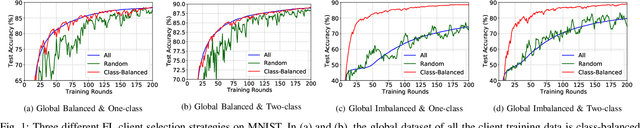
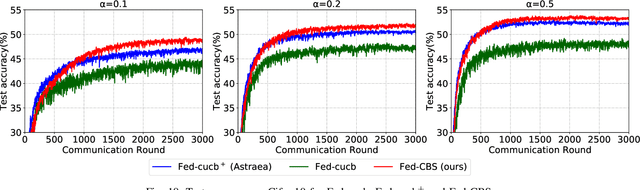
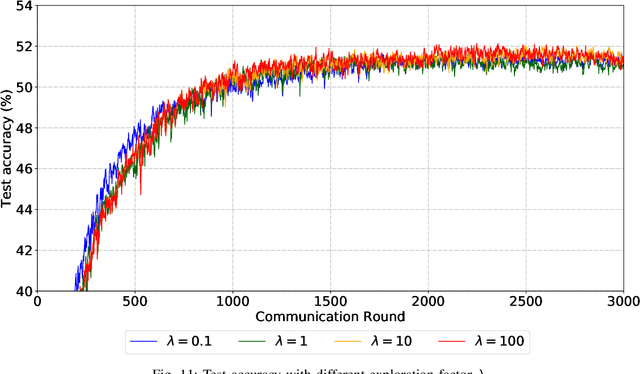
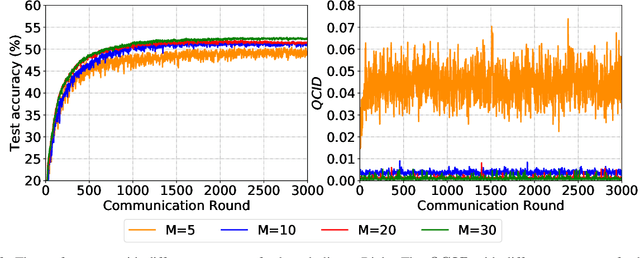
Due to limited communication capacities of edge devices, most existing federated learning (FL) methods randomly select only a subset of devices to participate in training for each communication round. Compared with engaging all the available clients, the random-selection mechanism can lead to significant performance degradation on non-IID (independent and identically distributed) data. In this paper, we show our key observation that the essential reason resulting in such performance degradation is the class-imbalance of the grouped data from randomly selected clients. Based on our key observation, we design an efficient heterogeneity-aware client sampling mechanism, i.e., Federated Class-balanced Sampling (Fed-CBS), which can effectively reduce class-imbalance of the group dataset from the intentionally selected clients. In particular, we propose a measure of class-imbalance and then employ homomorphic encryption to derive this measure in a privacy-preserving way. Based on this measure, we also design a computation-efficient client sampling strategy, such that the actively selected clients will generate a more class-balanced grouped dataset with theoretical guarantees. Extensive experimental results demonstrate Fed-CBS outperforms the status quo approaches. Furthermore, it achieves comparable or even better performance than the ideal setting where all the available clients participate in the FL training.
PolyMPCNet: Towards ReLU-free Neural Architecture Search in Two-party Computation Based Private Inference
Sep 20, 2022
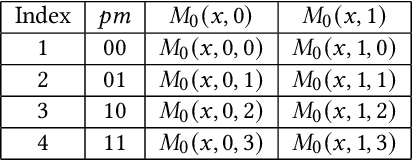
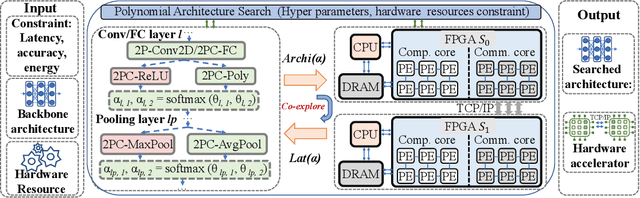
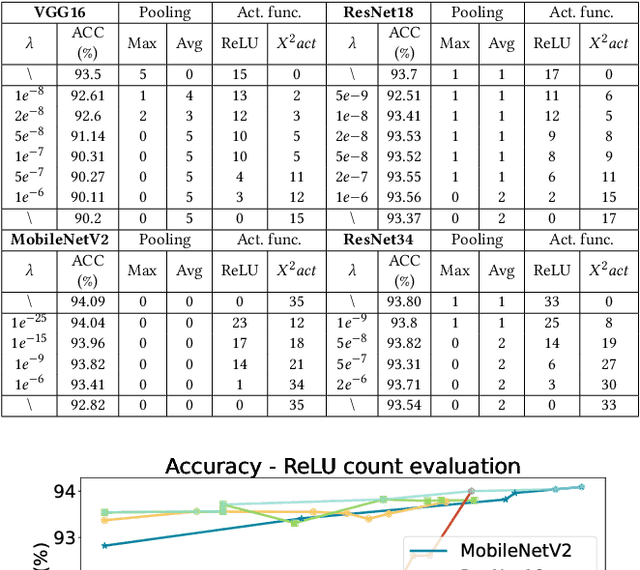
The rapid growth and deployment of deep learning (DL) has witnessed emerging privacy and security concerns. To mitigate these issues, secure multi-party computation (MPC) has been discussed, to enable the privacy-preserving DL computation. In practice, they often come at very high computation and communication overhead, and potentially prohibit their popularity in large scale systems. Two orthogonal research trends have attracted enormous interests in addressing the energy efficiency in secure deep learning, i.e., overhead reduction of MPC comparison protocol, and hardware acceleration. However, they either achieve a low reduction ratio and suffer from high latency due to limited computation and communication saving, or are power-hungry as existing works mainly focus on general computing platforms such as CPUs and GPUs. In this work, as the first attempt, we develop a systematic framework, PolyMPCNet, of joint overhead reduction of MPC comparison protocol and hardware acceleration, by integrating hardware latency of the cryptographic building block into the DNN loss function to achieve high energy efficiency, accuracy, and security guarantee. Instead of heuristically checking the model sensitivity after a DNN is well-trained (through deleting or dropping some non-polynomial operators), our key design principle is to em enforce exactly what is assumed in the DNN design -- training a DNN that is both hardware efficient and secure, while escaping the local minima and saddle points and maintaining high accuracy. More specifically, we propose a straight through polynomial activation initialization method for cryptographic hardware friendly trainable polynomial activation function to replace the expensive 2P-ReLU operator. We develop a cryptographic hardware scheduler and the corresponding performance model for Field Programmable Gate Arrays (FPGA) platform.
Empowering GNNs with Fine-grained Communication-Computation Pipelining on Multi-GPU Platforms
Sep 14, 2022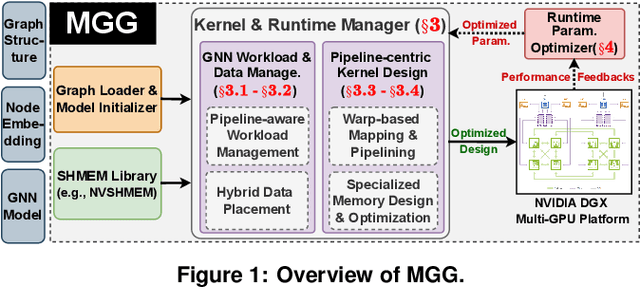

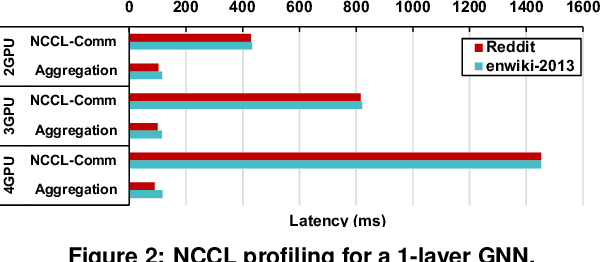

The increasing size of input graphs for graph neural networks (GNNs) highlights the demand for using multi-GPU platforms. However, existing multi-GPU GNN solutions suffer from inferior performance due to imbalanced computation and inefficient communication. To this end, we propose MGG, a novel system design to accelerate GNNs on multi-GPU platforms via a GPU-centric software pipeline. MGG explores the potential of hiding remote memory access latency in GNN workloads through fine-grained computation-communication pipelining. Specifically, MGG introduces a pipeline-aware workload management strategy and a hybrid data layout design to facilitate communication-computation overlapping. MGG implements an optimized pipeline-centric kernel. It includes workload interleaving and warp-based mapping for efficient GPU kernel operation pipelining and specialized memory designs and optimizations for better data access performance. Besides, MGG incorporates lightweight analytical modeling and optimization heuristics to dynamically improve the GNN execution performance for different settings at runtime. Comprehensive experiments demonstrate that MGG outperforms state-of-the-art multi-GPU systems across various GNN settings: on average 3.65X faster than multi-GPU systems with a unified virtual memory design and on average 7.38X faster than the DGCL framework.