 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindIt: Generalized Localization with Natural Language Queries
Mar 31, 2022

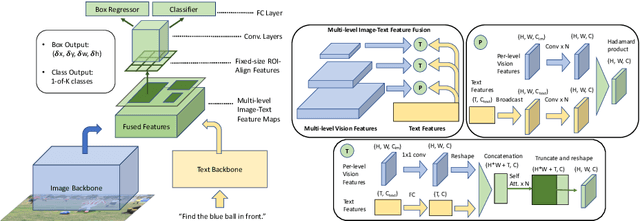
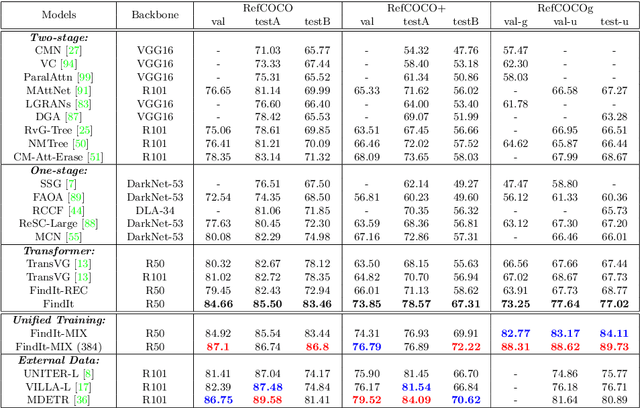
We propose FindIt, a simple and versatile framework that unifies a variety of visual grounding and localization tasks including referring expression comprehension, text-based localization, and object detection. Key to our architecture is an efficient multi-scale fusion module that unifies the disparate localization requirements across the tasks. In addition, we discover that a standard object detector is surprisingly effective in unifying these tasks without a need for task-specific design, losses, or pre-computed detections. Our end-to-end trainable framework responds flexibly and accurately to a wide range of referring expression, localization or detection queries for zero, one, or multiple objects. Jointly trained on these tasks, FindIt outperforms the state of the art on both referring expression and text-based localization, and shows competitive performance on object detection. Finally, FindIt generalizes better to out-of-distribution data and novel categories compared to strong single-task baselines. All of these are accomplished by a single, unified and efficient model. The code will be released.
Mechanical Search on Shelves using a Novel "Bluction" Tool
Jan 22, 2022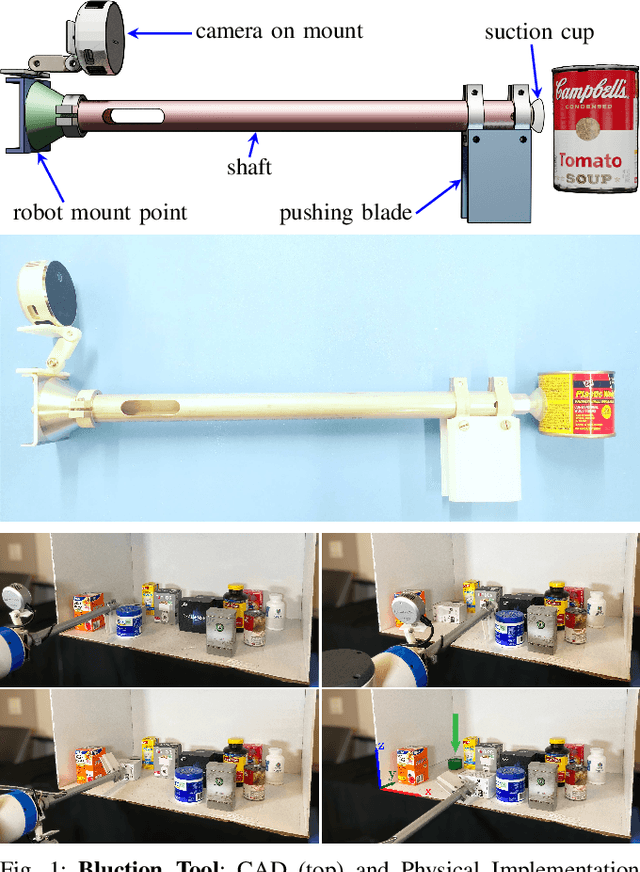
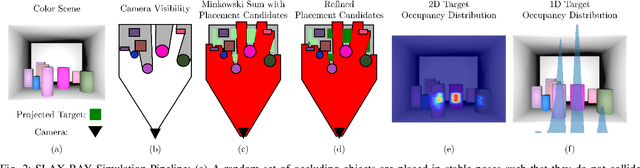

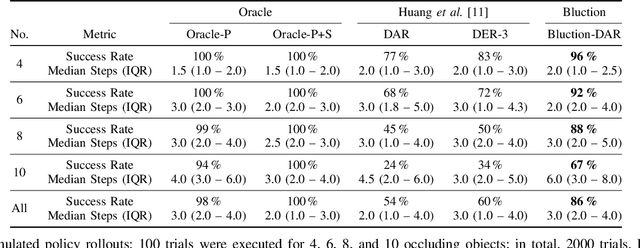
Shelves are common in homes, warehouses, and commercial settings due to their storage efficiency. However, this efficiency comes at the cost of reduced visibility and accessibility. When looking from a side (lateral) view of a shelf, most objects will be fully occluded, resulting in a constrained lateral-access mechanical search problem. To address this problem, we introduce: (1) a novel bluction tool, which combines a thin pushing blade and suction cup gripper, (2) an improved LAX-RAY simulation pipeline and perception model that combines ray-casting with 2D Minkowski sums to efficiently generate target occupancy distributions, and (3) a novel SLAX-RAY search policy, which optimally reduces target object distribution support area using the bluction tool. Experimental data from 2000 simulated shelf trials and 18 trials with a physical Fetch robot equipped with the bluction tool suggest that using suction grasping actions improves the success rate over the highest performing push-only policy by 26% in simulation and 67% in physical environments.
4D-Net for Learned Multi-Modal Alignment
Sep 02, 2021
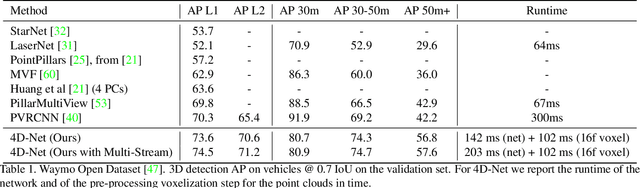
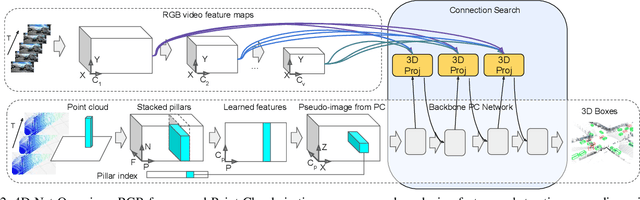
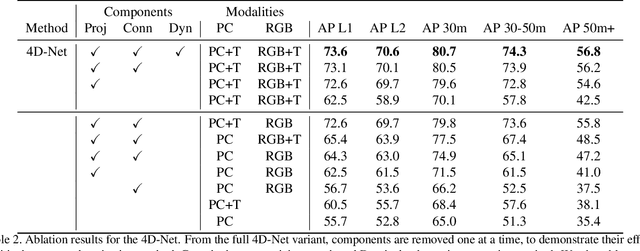
We present 4D-Net, a 3D object detection approach, which utilizes 3D Point Cloud and RGB sensing information, both in time. We are able to incorporate the 4D information by performing a novel dynamic connection learning across various feature representations and levels of abstraction, as well as by observing geometric constraints. Our approach outperforms the state-of-the-art and strong baselines on the Waymo Open Dataset. 4D-Net is better able to use motion cues and dense image information to detect distant objects more successfully.
Patch2CAD: Patchwise Embedding Learning for In-the-Wild Shape Retrieval from a Single Image
Aug 20, 2021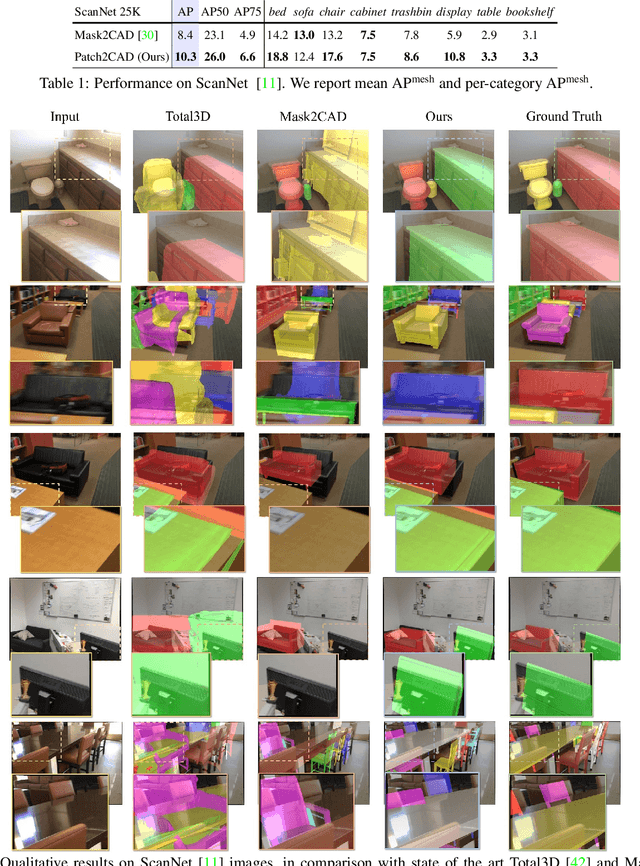
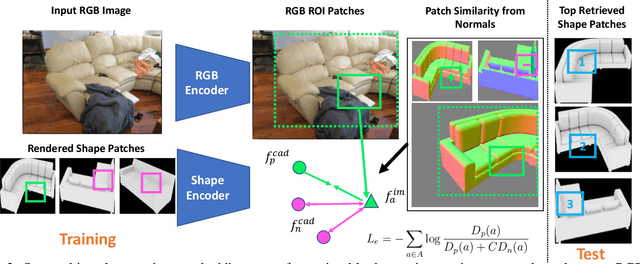
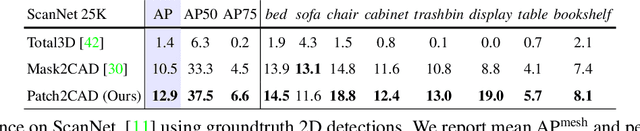
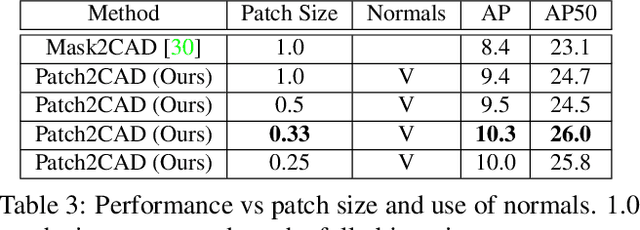
3D perception of object shapes from RGB image input is fundamental towards semantic scene understanding, grounding image-based perception in our spatially 3-dimensional real-world environments. To achieve a mapping between image views of objects and 3D shapes, we leverage CAD model priors from existing large-scale databases, and propose a novel approach towards constructing a joint embedding space between 2D images and 3D CAD models in a patch-wise fashion -- establishing correspondences between patches of an image view of an object and patches of CAD geometry. This enables part similarity reasoning for retrieving similar CADs to a new image view without exact matches in the database. Our patch embedding provides more robust CAD retrieval for shape estimation in our end-to-end estimation of CAD model shape and pose for detected objects in a single input image. Experiments on in-the-wild, complex imagery from ScanNet show that our approach is more robust than state of the art in real-world scenarios without any exact CAD matches.
Learning Open-World Object Proposals without Learning to Classify
Aug 15, 2021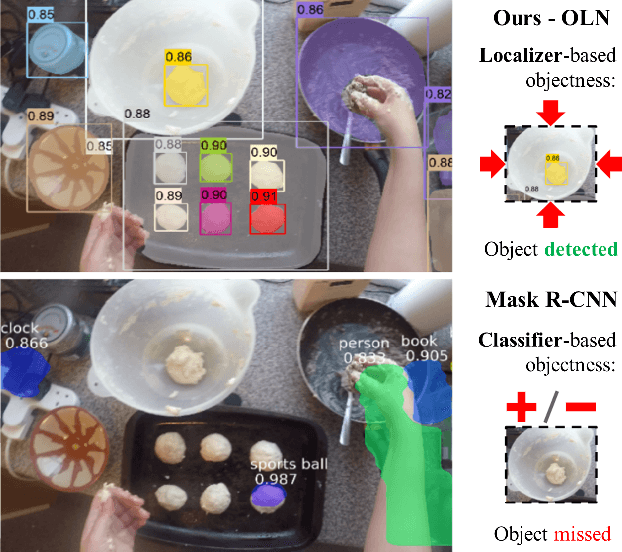
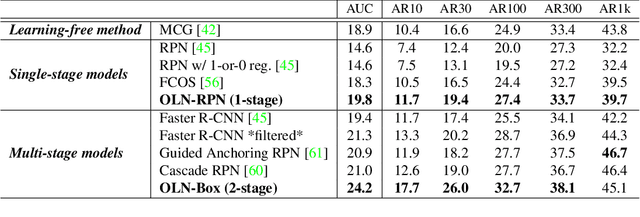
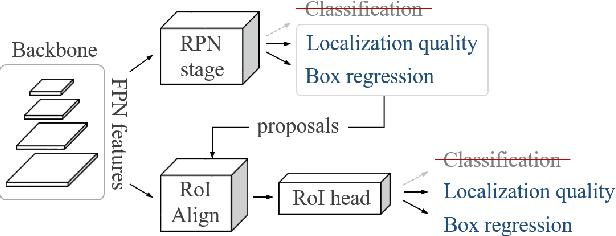
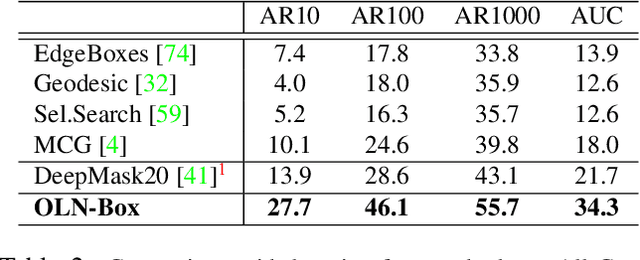
Object proposals have become an integral preprocessing steps of many vision pipelines including object detection, weakly supervised detection, object discovery, tracking, etc. Compared to the learning-free methods, learning-based proposals have become popular recently due to the growing interest in object detection. The common paradigm is to learn object proposals from data labeled with a set of object regions and their corresponding categories. However, this approach often struggles with novel objects in the open world that are absent in the training set. In this paper, we identify that the problem is that the binary classifiers in existing proposal methods tend to overfit to the training categories. Therefore, we propose a classification-free Object Localization Network (OLN) which estimates the objectness of each region purely by how well the location and shape of a region overlap with any ground-truth object (e.g., centerness and IoU). This simple strategy learns generalizable objectness and outperforms existing proposals on cross-category generalization on COCO, as well as cross-dataset evaluation on RoboNet, Object365, and EpicKitchens. Finally, we demonstrate the merit of OLN for long-tail object detection on large vocabulary dataset, LVIS, where we notice clear improvement in rare and common categories.
Unsupervised Discovery of Actions in Instructional Videos
Jun 28, 2021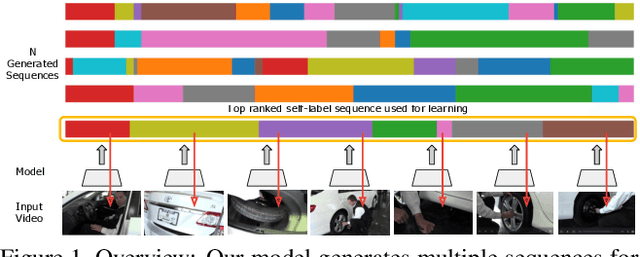
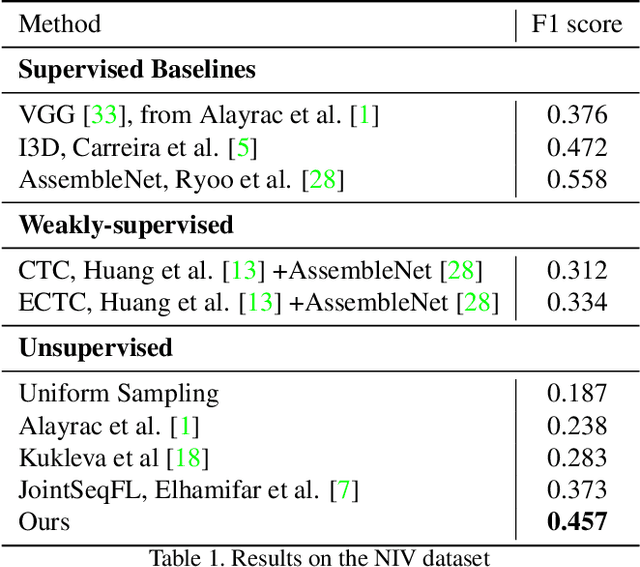
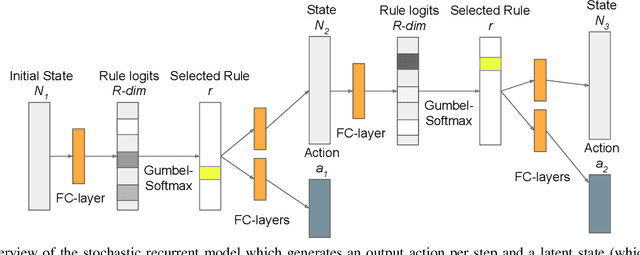
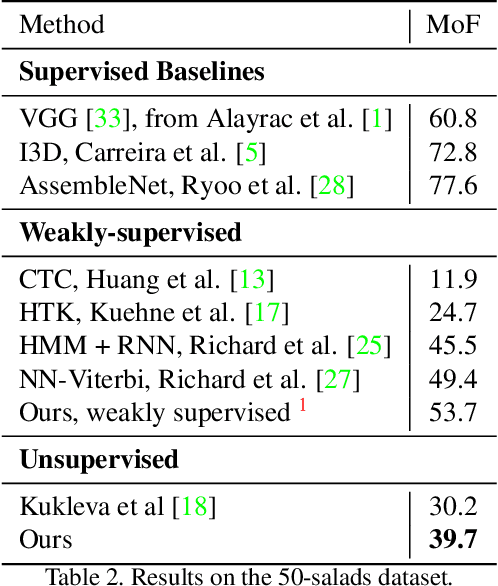
In this paper we address the problem of automatically discovering atomic actions in unsupervised manner from instructional videos. Instructional videos contain complex activities and are a rich source of information for intelligent agents, such as, autonomous robots or virtual assistants, which can, for example, automatically `read' the steps from an instructional video and execute them. However, videos are rarely annotated with atomic activities, their boundaries or duration. We present an unsupervised approach to learn atomic actions of structured human tasks from a variety of instructional videos. We propose a sequential stochastic autoregressive model for temporal segmentation of videos, which learns to represent and discover the sequential relationship between different atomic actions of the task, and which provides automatic and unsupervised self-labeling for videos. Our approach outperforms the state-of-the-art unsupervised methods with large margins. We will open source the code.
TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?
Jun 21, 2021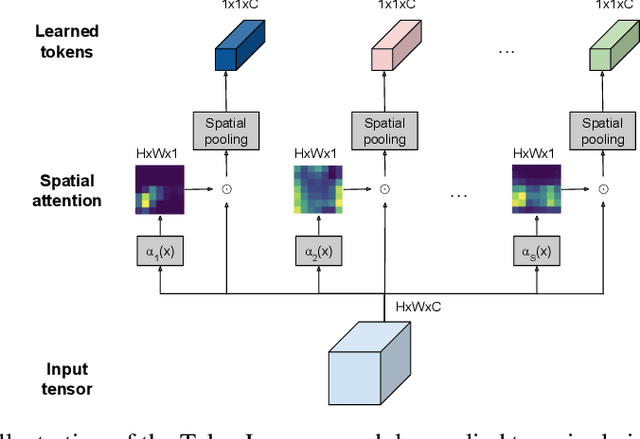
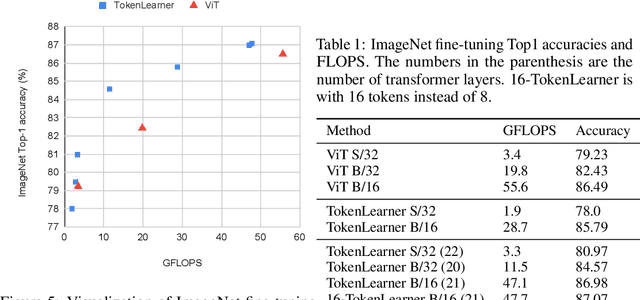
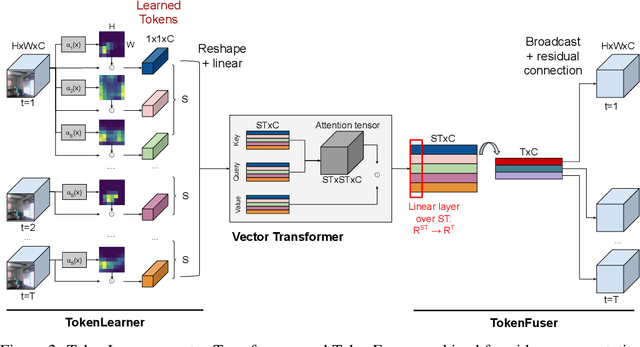

In this paper, we introduce a novel visual representation learning which relies on a handful of adaptively learned tokens, and which is applicable to both image and video understanding tasks. Instead of relying on hand-designed splitting strategies to obtain visual tokens and processing a large number of densely sampled patches for attention, our approach learns to mine important tokens in visual data. This results in efficiently and effectively finding a few important visual tokens and enables modeling of pairwise attention between such tokens, over a longer temporal horizon for videos, or the spatial content in images. Our experiments demonstrate strong performance on several challenging benchmarks for both image and video recognition tasks. Importantly, due to our tokens being adaptive, we accomplish competitive results at significantly reduced compute amount.
Unsupervised Action Segmentation for Instructional Videos
Jun 07, 2021
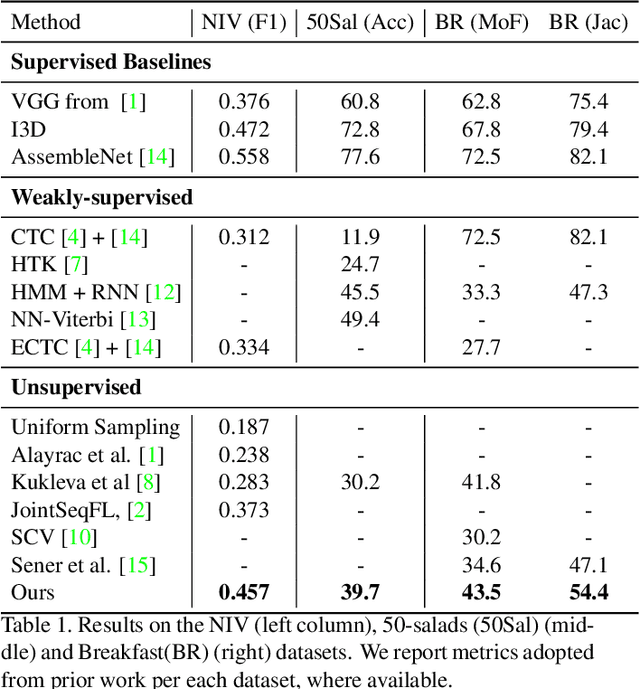
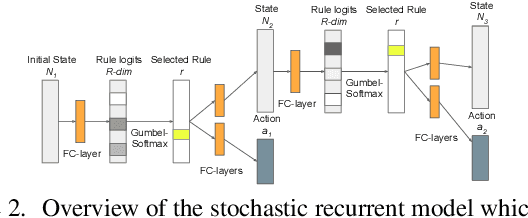
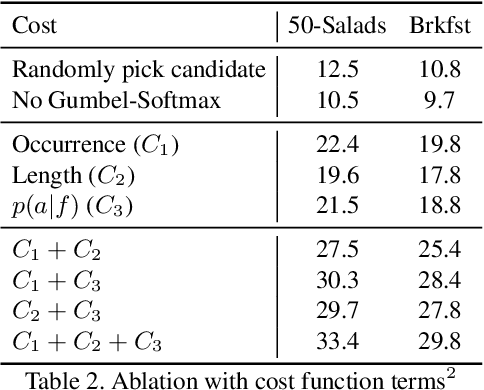
In this paper we address the problem of automatically discovering atomic actions in unsupervised manner from instructional videos, which are rarely annotated with atomic actions. We present an unsupervised approach to learn atomic actions of structured human tasks from a variety of instructional videos based on a sequential stochastic autoregressive model for temporal segmentation of videos. This learns to represent and discover the sequential relationship between different atomic actions of the task, and which provides automatic and unsupervised self-labeling.
SMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping
May 14, 2021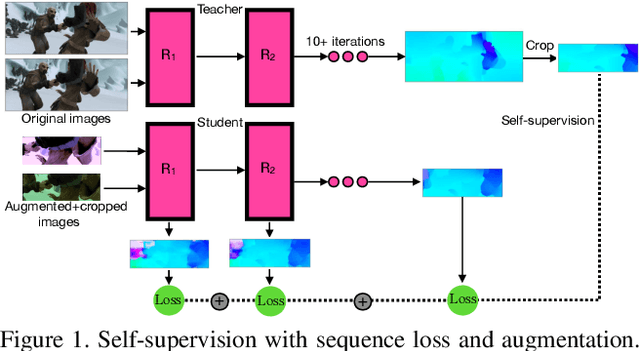
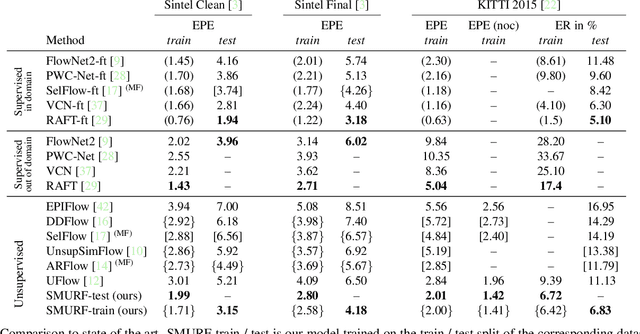
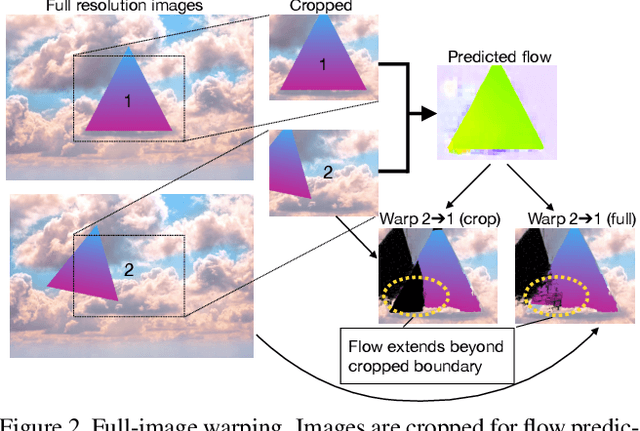
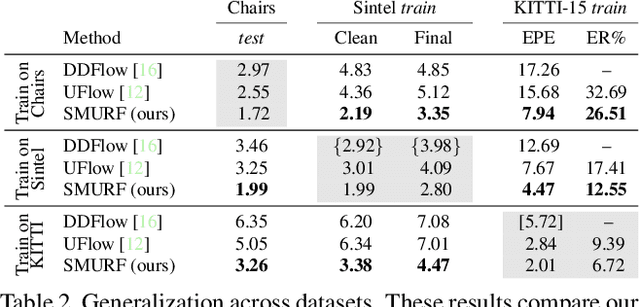
We present SMURF, a method for unsupervised learning of optical flow that improves state of the art on all benchmarks by $36\%$ to $40\%$ (over the prior best method UFlow) and even outperforms several supervised approaches such as PWC-Net and FlowNet2. Our method integrates architecture improvements from supervised optical flow, i.e. the RAFT model, with new ideas for unsupervised learning that include a sequence-aware self-supervision loss, a technique for handling out-of-frame motion, and an approach for learning effectively from multi-frame video data while still only requiring two frames for inference.
Adaptive Intermediate Representations for Video Understanding
Apr 14, 2021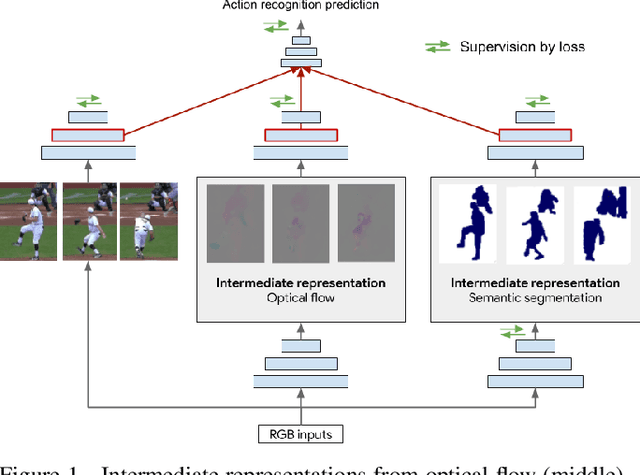
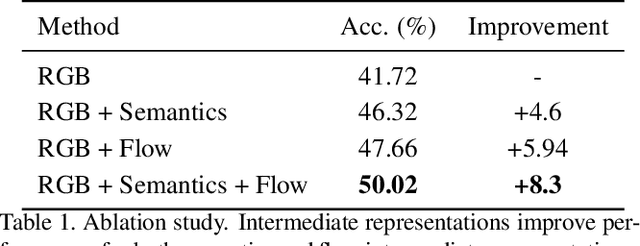
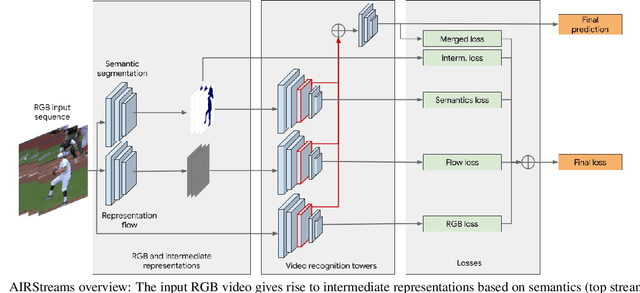
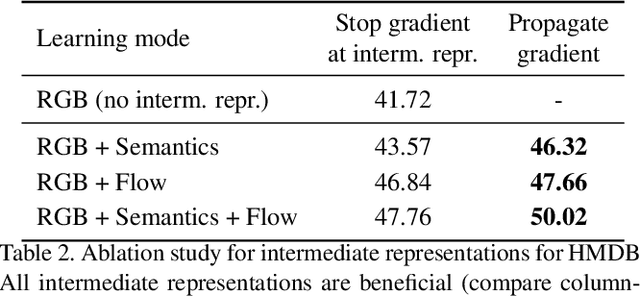
A common strategy to video understanding is to incorporate spatial and motion information by fusing features derived from RGB frames and optical flow. In this work, we introduce a new way to leverage semantic segmentation as an intermediate representation for video understanding and use it in a way that requires no additional labeling. Second, we propose a general framework which learns the intermediate representations (optical flow and semantic segmentation) jointly with the final video understanding task and allows the adaptation of the representations to the end goal. Despite the use of intermediate representations within the network, during inference, no additional data beyond RGB sequences is needed, enabling efficient recognition with a single network. Finally, we present a way to find the optimal learning configuration by searching the best loss weighting via evolution. We obtain more powerful visual representations for videos which lead to performance gains over the state-of-the-art.