 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindSeer: Real-time volumetric wind prediction over complex terrain aboard a small UAV
Jan 18, 2024



Real-time high-resolution wind predictions are beneficial for various applications including safe manned and unmanned aviation. Current weather models require too much compute and lack the necessary predictive capabilities as they are valid only at the scale of multiple kilometers and hours - much lower spatial and temporal resolutions than these applications require. Our work, for the first time, demonstrates the ability to predict low-altitude wind in real-time on limited-compute devices, from only sparse measurement data. We train a neural network, WindSeer, using only synthetic data from computational fluid dynamics simulations and show that it can successfully predict real wind fields over terrain with known topography from just a few noisy and spatially clustered wind measurements. WindSeer can generate accurate predictions at different resolutions and domain sizes on previously unseen topography without retraining. We demonstrate that the model successfully predicts historical wind data collected by weather stations and wind measured onboard drones.
LLF-Bench: Benchmark for Interactive Learning from Language Feedback
Dec 13, 2023We introduce a new benchmark, LLF-Bench (Learning from Language Feedback Benchmark; pronounced as "elf-bench"), to evaluate the ability of AI agents to interactively learn from natural language feedback and instructions. Learning from language feedback (LLF) is essential for people, largely because the rich information this feedback provides can help a learner avoid much of trial and error and thereby speed up the learning process. Large Language Models (LLMs) have recently enabled AI agents to comprehend natural language -- and hence AI agents can potentially benefit from language feedback during learning like humans do. But existing interactive benchmarks do not assess this crucial capability: they either use numeric reward feedback or require no learning at all (only planning or information retrieval). LLF-Bench is designed to fill this omission. LLF-Bench is a diverse collection of sequential decision-making tasks that includes user recommendation, poem writing, navigation, and robot control. The objective of an agent is to interactively solve these tasks based on their natural-language instructions and the feedback received after taking actions. Crucially, to ensure that the agent actually "learns" from the feedback, LLF-Bench implements several randomization techniques (such as paraphrasing and environment randomization) to ensure that the task isn't familiar to the agent and that the agent is robust to various verbalizations. In addition, LLF-Bench provides a unified OpenAI Gym interface for all its tasks and allows the users to easily configure the information the feedback conveys (among suggestion, explanation, and instantaneous performance) to study how agents respond to different types of feedback. Together, these features make LLF-Bench a unique research platform for developing and testing LLF agents.
Interactive Robot Learning from Verbal Correction
Oct 26, 2023The ability to learn and refine behavior after deployment has become ever more important for robots as we design them to operate in unstructured environments like households. In this work, we design a new learning system based on large language model (LLM), OLAF, that allows everyday users to teach a robot using verbal corrections when the robot makes mistakes, e.g., by saying "Stop what you're doing. You should move closer to the cup." A key feature of OLAF is its ability to update the robot's visuomotor neural policy based on the verbal feedback to avoid repeating mistakes in the future. This is in contrast to existing LLM-based robotic systems, which only follow verbal commands or corrections but not learn from them. We demonstrate the efficacy of our design in experiments where a user teaches a robot to perform long-horizon manipulation tasks both in simulation and on physical hardware, achieving on average 20.0% improvement in policy success rate. Videos and more results are at https://ut-austin-rpl.github.io/olaf/
Goal Representations for Instruction Following: A Semi-Supervised Language Interface to Control
Jun 30, 2023



Our goal is for robots to follow natural language instructions like "put the towel next to the microwave." But getting large amounts of labeled data, i.e. data that contains demonstrations of tasks labeled with the language instruction, is prohibitive. In contrast, obtaining policies that respond to image goals is much easier, because any autonomous trial or demonstration can be labeled in hindsight with its final state as the goal. In this work, we contribute a method that taps into joint image- and goal- conditioned policies with language using only a small amount of language data. Prior work has made progress on this using vision-language models or by jointly training language-goal-conditioned policies, but so far neither method has scaled effectively to real-world robot tasks without significant human annotation. Our method achieves robust performance in the real world by learning an embedding from the labeled data that aligns language not to the goal image, but rather to the desired change between the start and goal images that the instruction corresponds to. We then train a policy on this embedding: the policy benefits from all the unlabeled data, but the aligned embedding provides an interface for language to steer the policy. We show instruction following across a variety of manipulation tasks in different scenes, with generalization to language instructions outside of the labeled data. Videos and code for our approach can be found on our website: http://tiny.cc/grif .
Survival Instinct in Offline Reinforcement Learning
Jun 05, 2023



We present a novel observation about the behavior of offline reinforcement learning (RL) algorithms: on many benchmark datasets, offline RL can produce well-performing and safe policies even when trained with "wrong" reward labels, such as those that are zero everywhere or are negatives of the true rewards. This phenomenon cannot be easily explained by offline RL's return maximization objective. Moreover, it gives offline RL a degree of robustness that is uncharacteristic of its online RL counterparts, which are known to be sensitive to reward design. We demonstrate that this surprising robustness property is attributable to an interplay between the notion of pessimism in offline RL algorithms and a certain bias implicit in common data collection practices. As we prove in this work, pessimism endows the agent with a "survival instinct", i.e., an incentive to stay within the data support in the long term, while the limited and biased data coverage further constrains the set of survival policies. Formally, given a reward class -- which may not even contain the true reward -- we identify conditions on the training data distribution that enable offline RL to learn a near-optimal and safe policy from any reward within the class. We argue that the survival instinct should be taken into account when interpreting results from existing offline RL benchmarks and when creating future ones. Our empirical and theoretical results suggest a new paradigm for RL, whereby an agent is "nudged" to learn a desirable behavior with imperfect reward but purposely biased data coverage.
Improving Offline RL by Blending Heuristics
Jun 01, 2023



We propose Heuristic Blending (HUBL), a simple performance-improving technique for a broad class of offline RL algorithms based on value bootstrapping. HUBL modifies Bellman operators used in these algorithms, partially replacing the bootstrapped values with Monte-Carlo returns as heuristics. For trajectories with higher returns, HUBL relies more on heuristics and less on bootstrapping; otherwise, it leans more heavily on bootstrapping. We show that this idea can be easily implemented by relabeling the offline datasets with adjusted rewards and discount factors, making HUBL readily usable by many existing offline RL implementations. We theoretically prove that HUBL reduces offline RL's complexity and thus improves its finite-sample performance. Furthermore, we empirically demonstrate that HUBL consistently improves the policy quality of four state-of-the-art bootstrapping-based offline RL algorithms (ATAC, CQL, TD3+BC, and IQL), by 9% on average over 27 datasets of the D4RL and Meta-World benchmarks.
PLEX: Making the Most of the Available Data for Robotic Manipulation Pretraining
Mar 15, 2023



A rich representation is key to general robotic manipulation, but existing model architectures require a lot of data to learn it. Unfortunately, ideal robotic manipulation training data, which comes in the form of expert visuomotor demonstrations for a variety of annotated tasks, is scarce. In this work we propose PLEX, a transformer-based architecture that learns from task-agnostic visuomotor trajectories accompanied by a much larger amount of task-conditioned object manipulation videos -- a type of robotics-relevant data available in quantity. The key insight behind PLEX is that the trajectories with observations and actions help induce a latent feature space and train a robot to execute task-agnostic manipulation routines, while a diverse set of video-only demonstrations can efficiently teach the robot how to plan in this feature space for a wide variety of tasks. In contrast to most works on robotic manipulation pretraining, PLEX learns a generalizable sensorimotor multi-task policy, not just an observational representation. We also show that using relative positional encoding in PLEX's transformers further increases its data efficiency when learning from human-collected demonstrations. Experiments showcase \appr's generalization on Meta-World-v2 benchmark and establish state-of-the-art performance in challenging Robosuite environments.
Exploring Levels of Control for a Navigation Assistant for Blind Travelers
Jan 05, 2023



Only a small percentage of blind and low-vision people use traditional mobility aids such as a cane or a guide dog. Various assistive technologies have been proposed to address the limitations of traditional mobility aids. These devices often give either the user or the device majority of the control. In this work, we explore how varying levels of control affect the users' sense of agency, trust in the device, confidence, and successful navigation. We present Glide, a novel mobility aid with two modes for control: Glide-directed and User-directed. We employ Glide in a study (N=9) in which blind or low-vision participants used both modes to navigate through an indoor environment. Overall, participants found that Glide was easy to use and learn. Most participants trusted Glide despite its current limitations, and their confidence and performance increased as they continued to use Glide. Users' control mode preference varied in different situations; no single mode "won" in all situations.
MoCapAct: A Multi-Task Dataset for Simulated Humanoid Control
Aug 15, 2022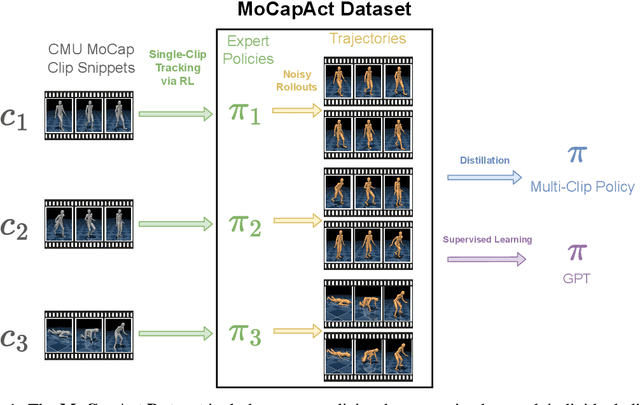
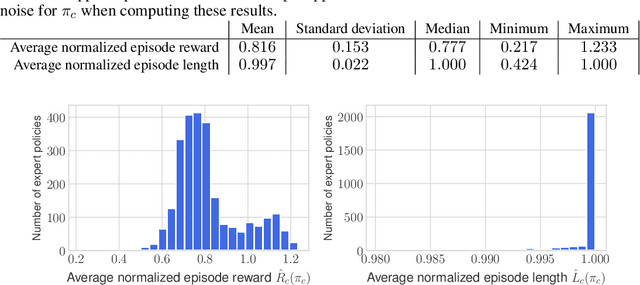

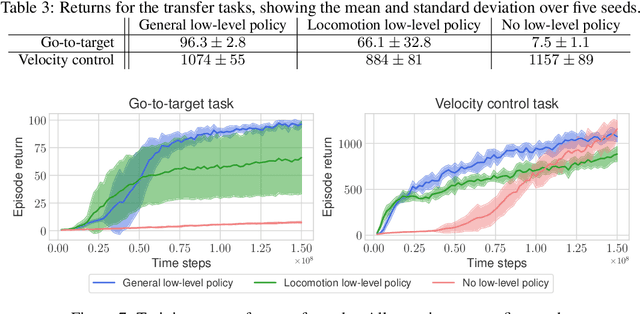
Simulated humanoids are an appealing research domain due to their physical capabilities. Nonetheless, they are also challenging to control, as a policy must drive an unstable, discontinuous, and high-dimensional physical system. One widely studied approach is to utilize motion capture (MoCap) data to teach the humanoid agent low-level skills (e.g., standing, walking, and running) that can then be re-used to synthesize high-level behaviors. However, even with MoCap data, controlling simulated humanoids remains very hard, as MoCap data offers only kinematic information. Finding physical control inputs to realize the demonstrated motions requires computationally intensive methods like reinforcement learning. Thus, despite the publicly available MoCap data, its utility has been limited to institutions with large-scale compute. In this work, we dramatically lower the barrier for productive research on this topic by training and releasing high-quality agents that can track over three hours of MoCap data for a simulated humanoid in the dm_control physics-based environment. We release MoCapAct (Motion Capture with Actions), a dataset of these expert agents and their rollouts, which contain proprioceptive observations and actions. We demonstrate the utility of MoCapAct by using it to train a single hierarchical policy capable of tracking the entire MoCap dataset within dm_control and show the learned low-level component can be re-used to efficiently learn downstream high-level tasks. Finally, we use MoCapAct to train an autoregressive GPT model and show that it can control a simulated humanoid to perform natural motion completion given a motion prompt. Videos of the results and links to the code and dataset are available at https://microsoft.github.io/MoCapAct.
The Sandbox Environment for Generalizable Agent Research (SEGAR)
Mar 19, 2022
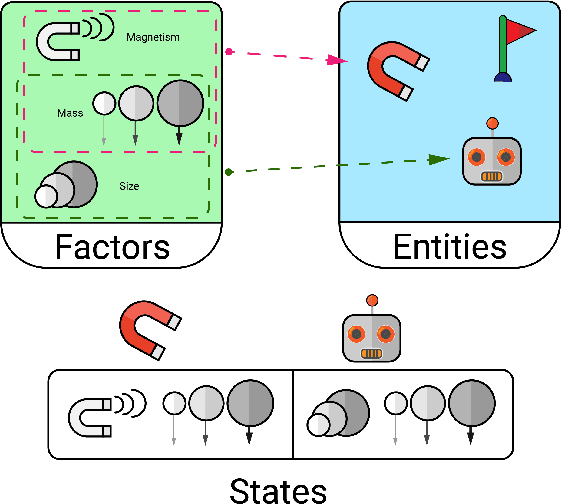
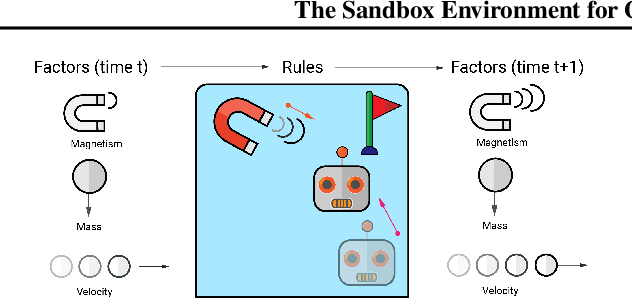
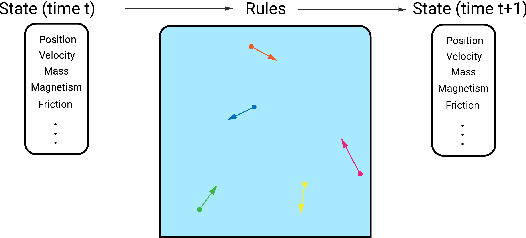
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.