 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimetic Alignment with ASPECT: Evaluation of AI-inferred Personal Profiles
Mar 27, 2026AI agents that communicate on behalf of individuals need to capture how each person actually communicates, yet current approaches either require costly per-person fine-tuning, produce generic outputs from shallow persona descriptions, or optimize preferences without modeling communication style. We present ASPECT (Automated Social Psychometric Evaluation of Communication Traits), a pipeline that directs LLMs to assess constructs from a validated communication scale against behavioral evidence from workplace data, without per-person training. In a case study with 20 participants (1,840 paired item ratings, 600 scenario evaluations), ASPECT-generated profiles achieved moderate alignment with self-assessments, and ASPECT-generated responses were preferred over generic and self-report baselines on aggregate, with substantial variation across individuals and scenarios. During the profile review phase, linked evidence helped participants identify mischaracterizations, recalibrate their own self-ratings, and negotiate context-appropriate representations. We discuss implications for building inspectable, individually scoped communication profiles that let individuals control how agents represent them at work.
Exploring Levels of Control for a Navigation Assistant for Blind Travelers
Jan 05, 2023



Only a small percentage of blind and low-vision people use traditional mobility aids such as a cane or a guide dog. Various assistive technologies have been proposed to address the limitations of traditional mobility aids. These devices often give either the user or the device majority of the control. In this work, we explore how varying levels of control affect the users' sense of agency, trust in the device, confidence, and successful navigation. We present Glide, a novel mobility aid with two modes for control: Glide-directed and User-directed. We employ Glide in a study (N=9) in which blind or low-vision participants used both modes to navigate through an indoor environment. Overall, participants found that Glide was easy to use and learn. Most participants trusted Glide despite its current limitations, and their confidence and performance increased as they continued to use Glide. Users' control mode preference varied in different situations; no single mode "won" in all situations.
ORBIT: A Real-World Few-Shot Dataset for Teachable Object Recognition
Apr 09, 2021
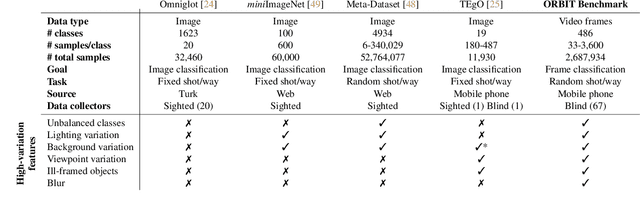
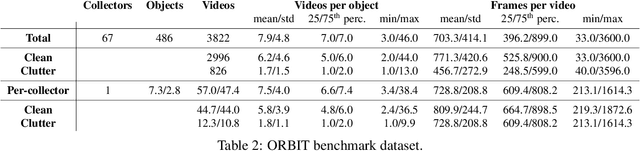
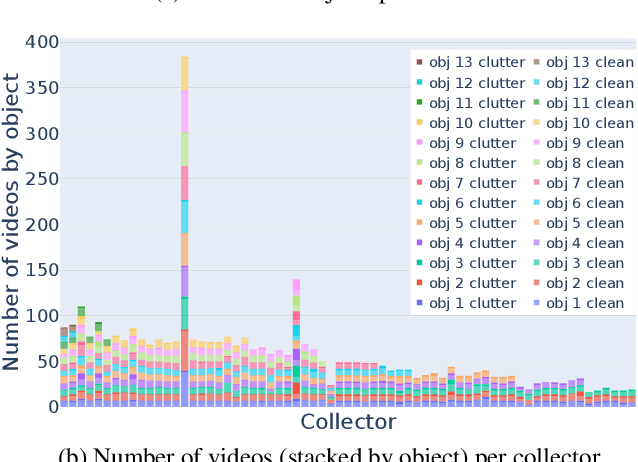
Object recognition has made great advances in the last decade, but predominately still relies on many high-quality training examples per object category. In contrast, learning new objects from only a few examples could enable many impactful applications from robotics to user personalization. Most few-shot learning research, however, has been driven by benchmark datasets that lack the high variation that these applications will face when deployed in the real-world. To close this gap, we present the ORBIT dataset and benchmark, grounded in a real-world application of teachable object recognizers for people who are blind/low vision. The dataset contains 3,822 videos of 486 objects recorded by people who are blind/low-vision on their mobile phones, and the benchmark reflects a realistic, highly challenging recognition problem, providing a rich playground to drive research in robustness to few-shot, high-variation conditions. We set the first state-of-the-art on the benchmark and show that there is massive scope for further innovation, holding the potential to impact a broad range of real-world vision applications including tools for the blind/low-vision community. The dataset is available at https://bit.ly/2OyElCj and the code to run the benchmark at https://bit.ly/39YgiUW.