 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Palliative Care with Deep Learning
Nov 17, 2017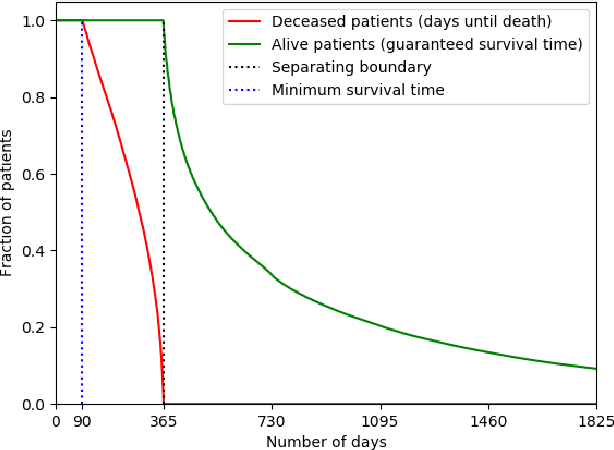
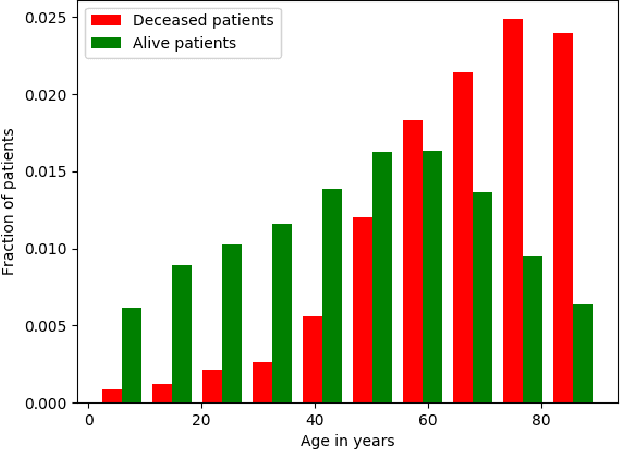
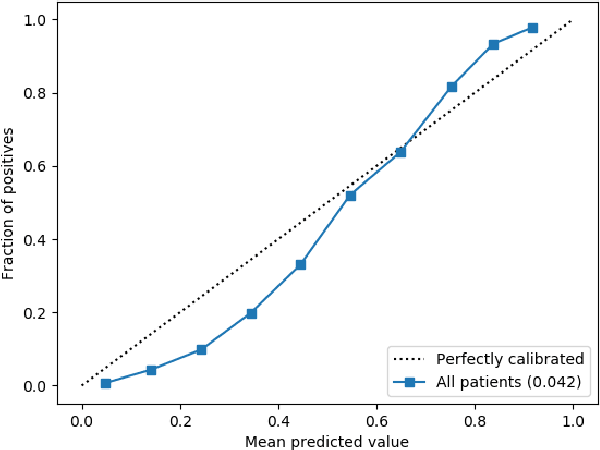
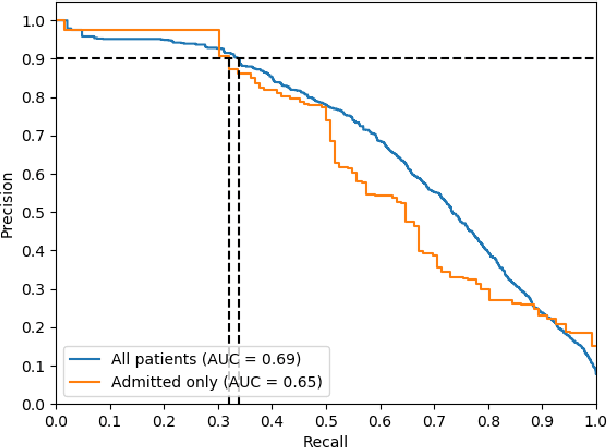
Improving the quality of end-of-life care for hospitalized patients is a priority for healthcare organizations. Studies have shown that physicians tend to over-estimate prognoses, which in combination with treatment inertia results in a mismatch between patients wishes and actual care at the end of life. We describe a method to address this problem using Deep Learning and Electronic Health Record (EHR) data, which is currently being piloted, with Institutional Review Board approval, at an academic medical center. The EHR data of admitted patients are automatically evaluated by an algorithm, which brings patients who are likely to benefit from palliative care services to the attention of the Palliative Care team. The algorithm is a Deep Neural Network trained on the EHR data from previous years, to predict all-cause 3-12 month mortality of patients as a proxy for patients that could benefit from palliative care. Our predictions enable the Palliative Care team to take a proactive approach in reaching out to such patients, rather than relying on referrals from treating physicians, or conduct time consuming chart reviews of all patients. We also present a novel interpretation technique which we use to provide explanations of the model's predictions.
Deep Voice: Real-time Neural Text-to-Speech
Mar 07, 2017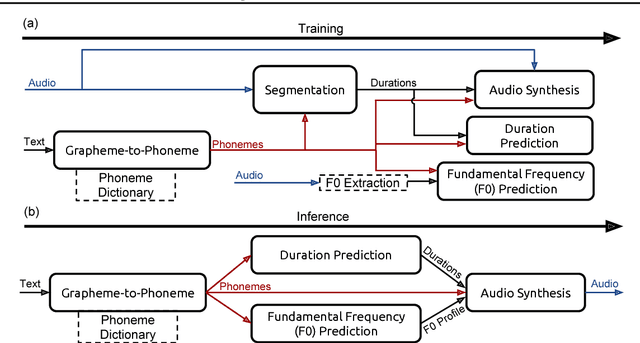
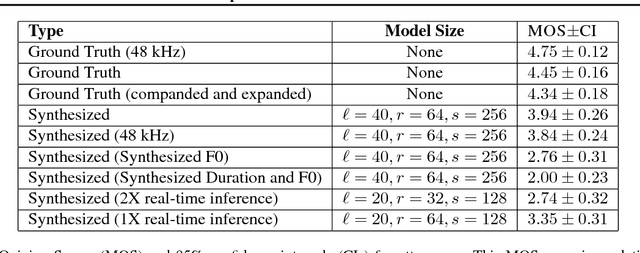
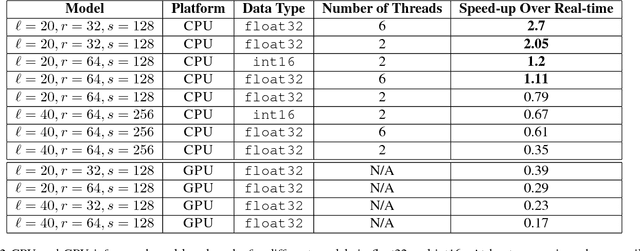
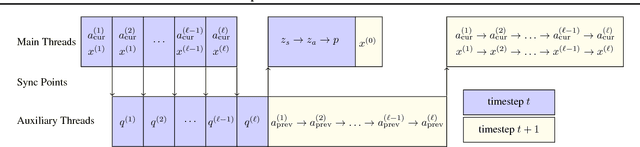
We present Deep Voice, a production-quality text-to-speech system constructed entirely from deep neural networks. Deep Voice lays the groundwork for truly end-to-end neural speech synthesis. The system comprises five major building blocks: a segmentation model for locating phoneme boundaries, a grapheme-to-phoneme conversion model, a phoneme duration prediction model, a fundamental frequency prediction model, and an audio synthesis model. For the segmentation model, we propose a novel way of performing phoneme boundary detection with deep neural networks using connectionist temporal classification (CTC) loss. For the audio synthesis model, we implement a variant of WaveNet that requires fewer parameters and trains faster than the original. By using a neural network for each component, our system is simpler and more flexible than traditional text-to-speech systems, where each component requires laborious feature engineering and extensive domain expertise. Finally, we show that inference with our system can be performed faster than real time and describe optimized WaveNet inference kernels on both CPU and GPU that achieve up to 400x speedups over existing implementations.
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Dec 08, 2015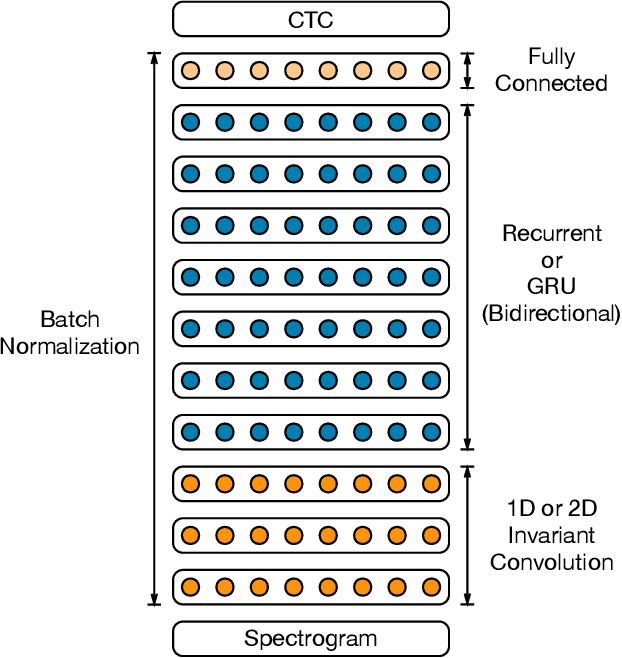
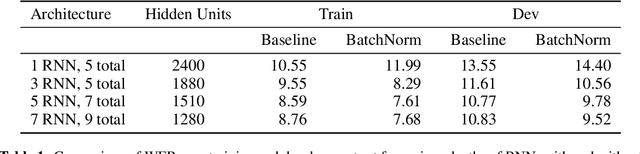
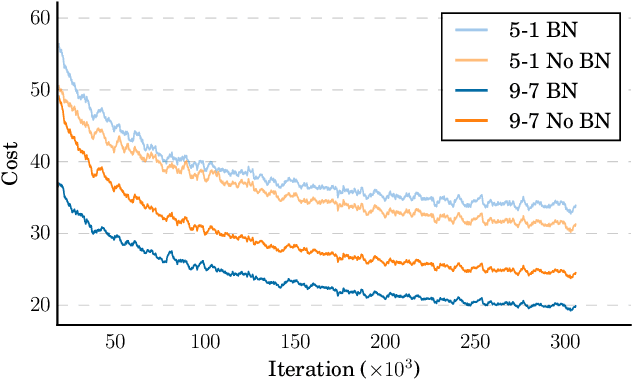
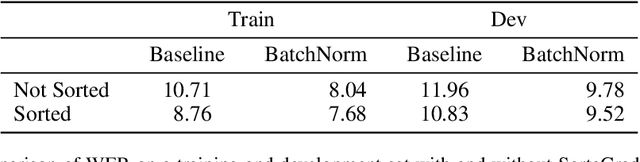
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learning allows us to handle a diverse variety of speech including noisy environments, accents and different languages. Key to our approach is our application of HPC techniques, resulting in a 7x speedup over our previous system. Because of this efficiency, experiments that previously took weeks now run in days. This enables us to iterate more quickly to identify superior architectures and algorithms. As a result, in several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets. Finally, using a technique called Batch Dispatch with GPUs in the data center, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.
Driverseat: Crowdstrapping Learning Tasks for Autonomous Driving
Dec 07, 2015
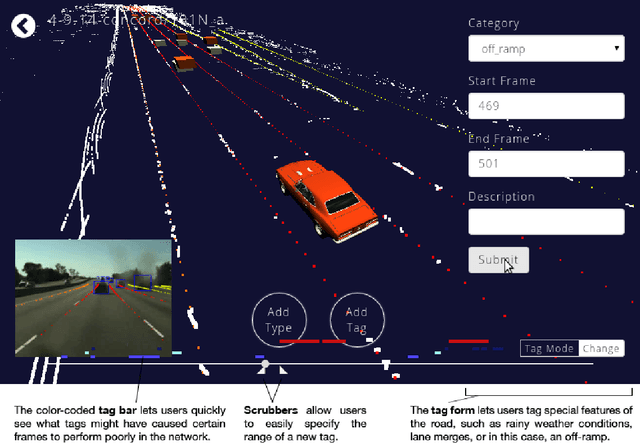
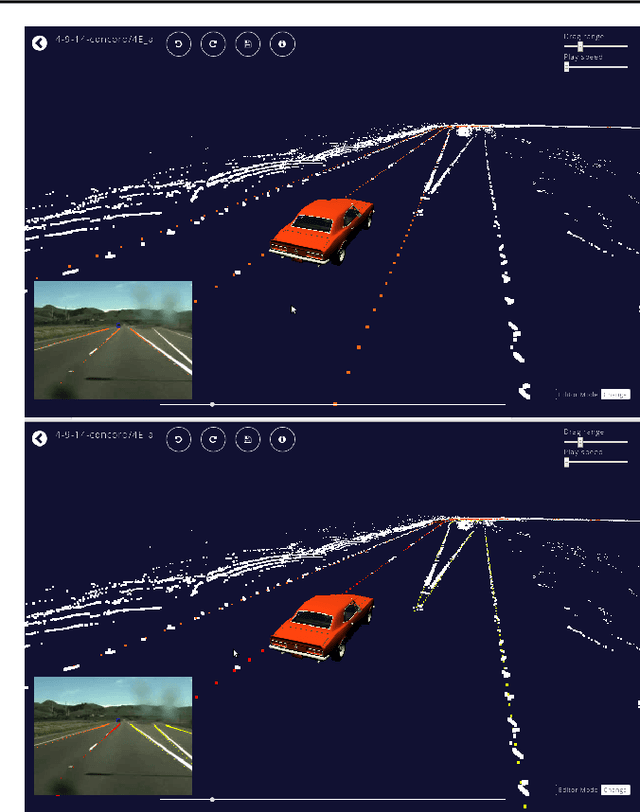
While emerging deep-learning systems have outclassed knowledge-based approaches in many tasks, their application to detection tasks for autonomous technologies remains an open field for scientific exploration. Broadly, there are two major developmental bottlenecks: the unavailability of comprehensively labeled datasets and of expressive evaluation strategies. Approaches for labeling datasets have relied on intensive hand-engineering, and strategies for evaluating learning systems have been unable to identify failure-case scenarios. Human intelligence offers an untapped approach for breaking through these bottlenecks. This paper introduces Driverseat, a technology for embedding crowds around learning systems for autonomous driving. Driverseat utilizes crowd contributions for (a) collecting complex 3D labels and (b) tagging diverse scenarios for ready evaluation of learning systems. We demonstrate how Driverseat can crowdstrap a convolutional neural network on the lane-detection task. More generally, crowdstrapping introduces a valuable paradigm for any technology that can benefit from leveraging the powerful combination of human and computer intelligence.
Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence
Aug 28, 2014This is the Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, which was held in Montreal, QC, Canada, June 18 - 21 2009.
Deep learning for class-generic object detection
Dec 24, 2013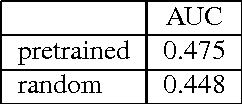
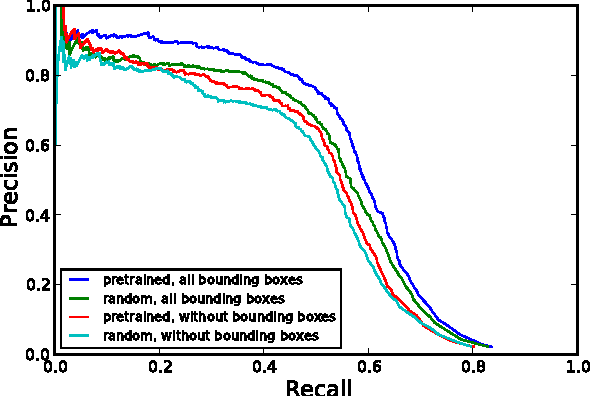

We investigate the use of deep neural networks for the novel task of class generic object detection. We show that neural networks originally designed for image recognition can be trained to detect objects within images, regardless of their class, including objects for which no bounding box labels have been provided. In addition, we show that bounding box labels yield a 1% performance increase on the ImageNet recognition challenge.
Tuned Models of Peer Assessment in MOOCs
Jul 09, 2013
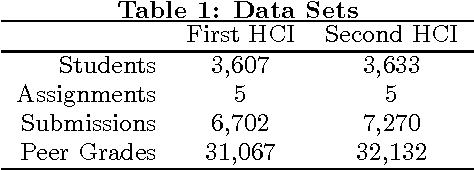
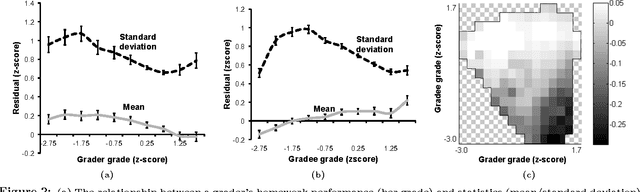
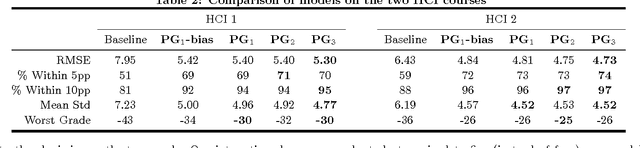
In massive open online courses (MOOCs), peer grading serves as a critical tool for scaling the grading of complex, open-ended assignments to courses with tens or hundreds of thousands of students. But despite promising initial trials, it does not always deliver accurate results compared to human experts. In this paper, we develop algorithms for estimating and correcting for grader biases and reliabilities, showing significant improvement in peer grading accuracy on real data with 63,199 peer grades from Coursera's HCI course offerings --- the largest peer grading networks analysed to date. We relate grader biases and reliabilities to other student factors such as student engagement, performance as well as commenting style. We also show that our model can lead to more intelligent assignment of graders to gradees.