 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference learning along multiple criteria: A game-theoretic perspective
May 05, 2021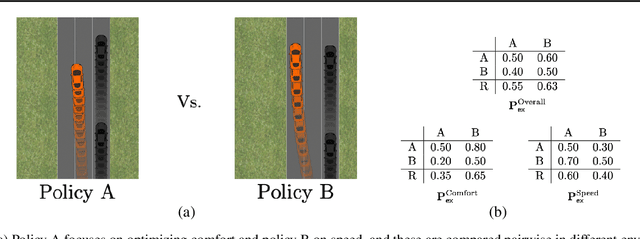
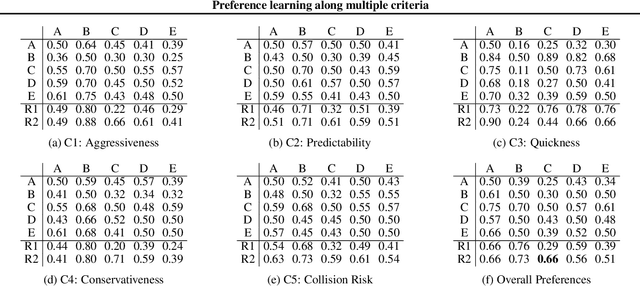
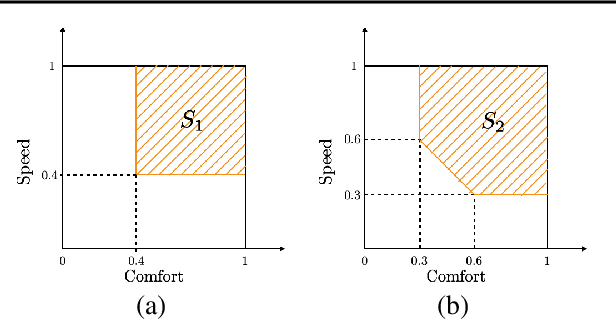
The literature on ranking from ordinal data is vast, and there are several ways to aggregate overall preferences from pairwise comparisons between objects. In particular, it is well known that any Nash equilibrium of the zero sum game induced by the preference matrix defines a natural solution concept (winning distribution over objects) known as a von Neumann winner. Many real-world problems, however, are inevitably multi-criteria, with different pairwise preferences governing the different criteria. In this work, we generalize the notion of a von Neumann winner to the multi-criteria setting by taking inspiration from Blackwell's approachability. Our framework allows for non-linear aggregation of preferences across criteria, and generalizes the linearization-based approach from multi-objective optimization. From a theoretical standpoint, we show that the Blackwell winner of a multi-criteria problem instance can be computed as the solution to a convex optimization problem. Furthermore, given random samples of pairwise comparisons, we show that a simple plug-in estimator achieves near-optimal minimax sample complexity. Finally, we showcase the practical utility of our framework in a user study on autonomous driving, where we find that the Blackwell winner outperforms the von Neumann winner for the overall preferences.
Optimal Cost Design for Model Predictive Control
Apr 23, 2021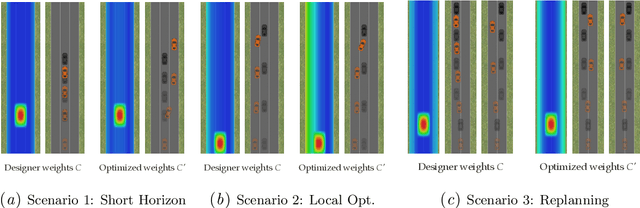
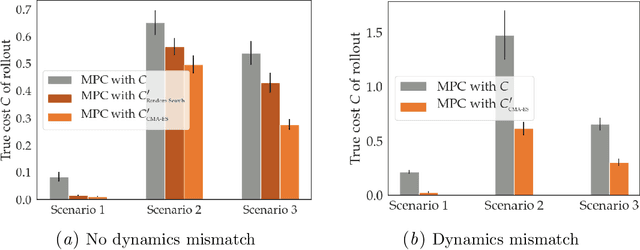
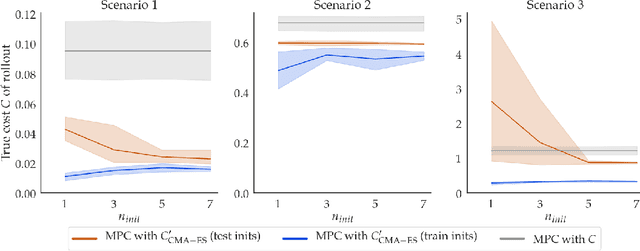
Many robotics domains use some form of nonconvex model predictive control (MPC) for planning, which sets a reduced time horizon, performs trajectory optimization, and replans at every step. The actual task typically requires a much longer horizon than is computationally tractable, and is specified via a cost function that cumulates over that full horizon. For instance, an autonomous car may have a cost function that makes a desired trade-off between efficiency, safety, and obeying traffic laws. In this work, we challenge the common assumption that the cost we optimize using MPC should be the same as the ground truth cost for the task (plus a terminal cost). MPC solvers can suffer from short planning horizons, local optima, incorrect dynamics models, and, importantly, fail to account for future replanning ability. Thus, we propose that in many tasks it could be beneficial to purposefully choose a different cost function for MPC to optimize: one that results in the MPC rollout having low ground truth cost, rather than the MPC planned trajectory. We formalize this as an optimal cost design problem, and propose a zeroth-order optimization-based approach that enables us to design optimal costs for an MPC planning robot in continuous MDPs. We test our approach in an autonomous driving domain where we find costs different from the ground truth that implicitly compensate for replanning, short horizon, incorrect dynamics models, and local minima issues. As an example, the learned cost incentivizes MPC to delay its decision until later, implicitly accounting for the fact that it will get more information in the future and be able to make a better decision. Code and videos available at https://sites.google.com/berkeley.edu/ocd-mpc/.
Agnostic learning with unknown utilities
Apr 17, 2021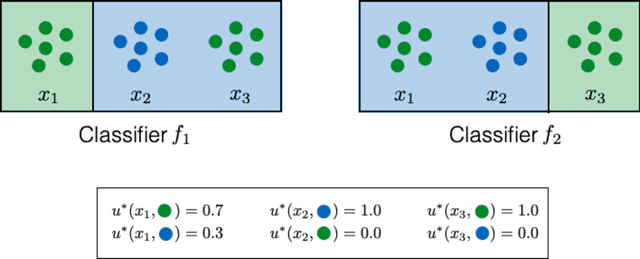
Traditional learning approaches for classification implicitly assume that each mistake has the same cost. In many real-world problems though, the utility of a decision depends on the underlying context $x$ and decision $y$. However, directly incorporating these utilities into the learning objective is often infeasible since these can be quite complex and difficult for humans to specify. We formally study this as agnostic learning with unknown utilities: given a dataset $S = \{x_1, \ldots, x_n\}$ where each data point $x_i \sim \mathcal{D}$, the objective of the learner is to output a function $f$ in some class of decision functions $\mathcal{F}$ with small excess risk. This risk measures the performance of the output predictor $f$ with respect to the best predictor in the class $\mathcal{F}$ on the unknown underlying utility $u^*$. This utility $u^*$ is not assumed to have any specific structure. This raises an interesting question whether learning is even possible in our setup, given that obtaining a generalizable estimate of utility $u^*$ might not be possible from finitely many samples. Surprisingly, we show that estimating the utilities of only the sampled points~$S$ suffices to learn a decision function which generalizes well. We study mechanisms for eliciting information which allow a learner to estimate the utilities $u^*$ on the set $S$. We introduce a family of elicitation mechanisms by generalizing comparisons, called the $k$-comparison oracle, which enables the learner to ask for comparisons across $k$ different inputs $x$ at once. We show that the excess risk in our agnostic learning framework decreases at a rate of $O\left(\frac{1}{k} \right)$. This result brings out an interesting accuracy-elicitation trade-off -- as the order $k$ of the oracle increases, the comparative queries become harder to elicit from humans but allow for more accurate learning.
Situational Confidence Assistance for Lifelong Shared Autonomy
Apr 14, 2021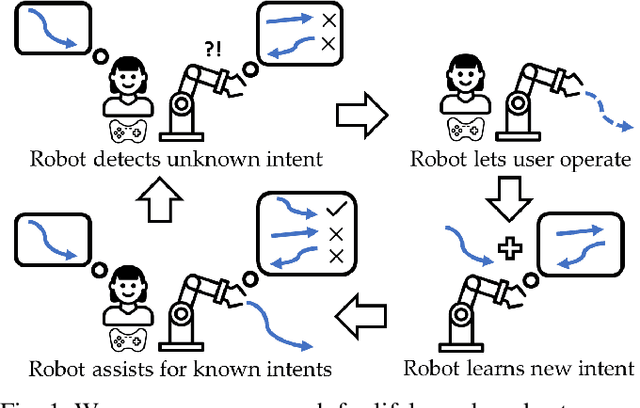
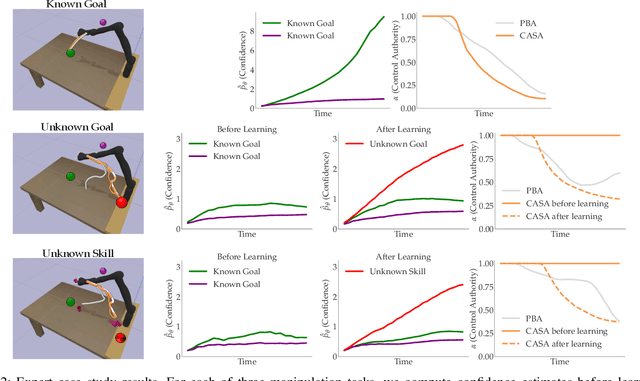
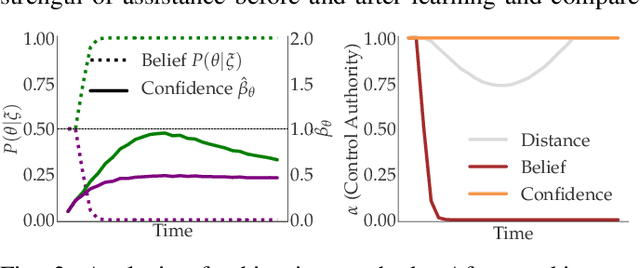
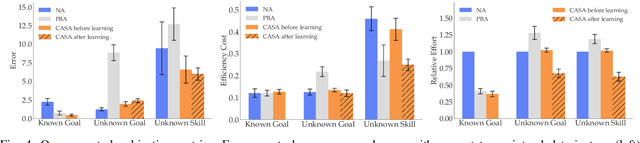
Shared autonomy enables robots to infer user intent and assist in accomplishing it. But when the user wants to do a new task that the robot does not know about, shared autonomy will hinder their performance by attempting to assist them with something that is not their intent. Our key idea is that the robot can detect when its repertoire of intents is insufficient to explain the user's input, and give them back control. This then enables the robot to observe unhindered task execution, learn the new intent behind it, and add it to this repertoire. We demonstrate with both a case study and a user study that our proposed method maintains good performance when the human's intent is in the robot's repertoire, outperforms prior shared autonomy approaches when it isn't, and successfully learns new skills, enabling efficient lifelong learning for confidence-based shared autonomy.
Dynamically Switching Human Prediction Models for Efficient Planning
Mar 13, 2021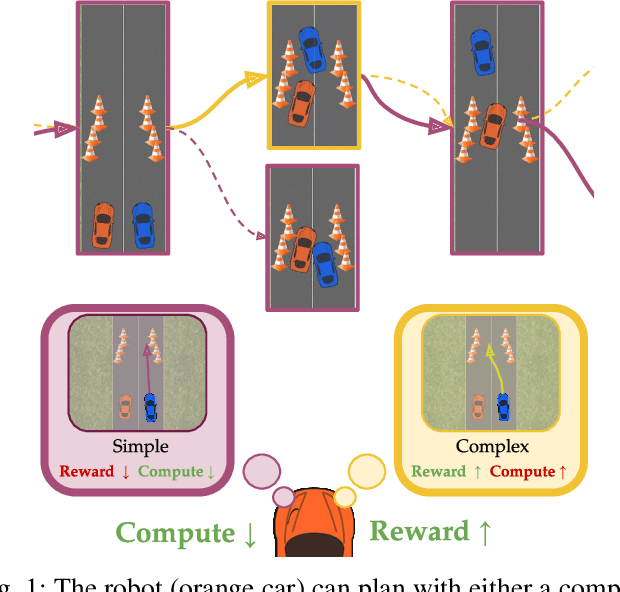
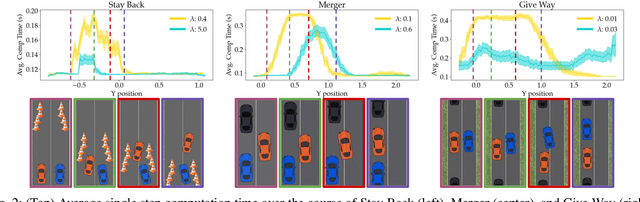
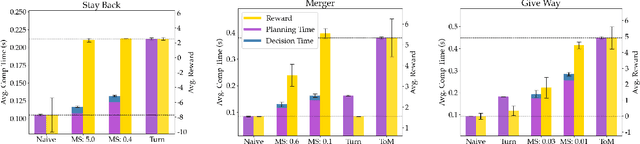
As environments involving both robots and humans become increasingly common, so does the need to account for people during planning. To plan effectively, robots must be able to respond to and sometimes influence what humans do. This requires a human model which predicts future human actions. A simple model may assume the human will continue what they did previously; a more complex one might predict that the human will act optimally, disregarding the robot; whereas an even more complex one might capture the robot's ability to influence the human. These models make different trade-offs between computational time and performance of the resulting robot plan. Using only one model of the human either wastes computational resources or is unable to handle critical situations. In this work, we give the robot access to a suite of human models and enable it to assess the performance-computation trade-off online. By estimating how an alternate model could improve human prediction and how that may translate to performance gain, the robot can dynamically switch human models whenever the additional computation is justified. Our experiments in a driving simulator showcase how the robot can achieve performance comparable to always using the best human model, but with greatly reduced computation.
Analyzing Human Models that Adapt Online
Mar 09, 2021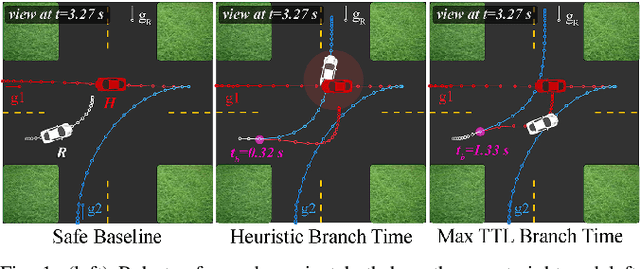
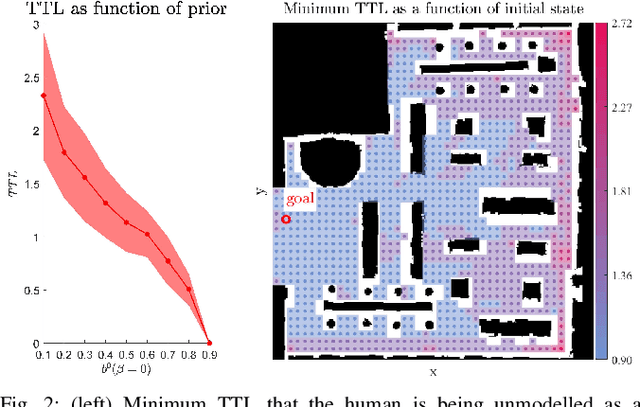
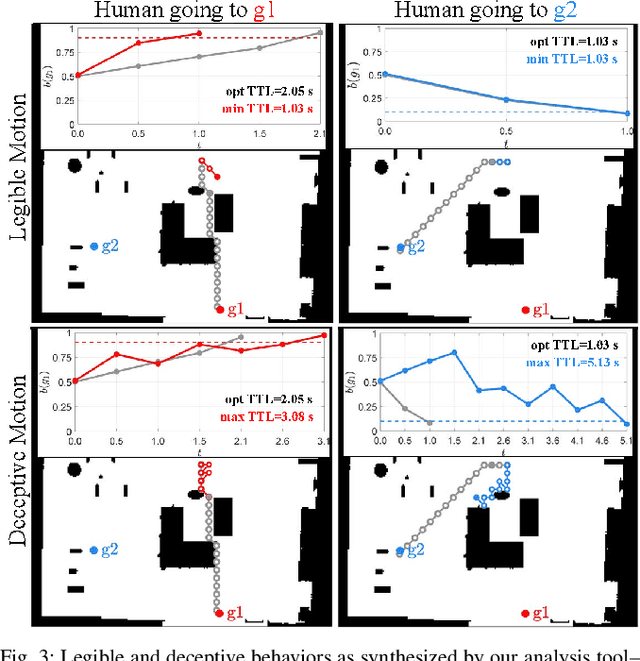
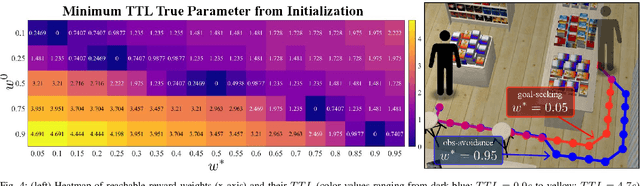
Predictive human models often need to adapt their parameters online from human data. This raises previously ignored safety-related questions for robots relying on these models such as what the model could learn online and how quickly could it learn it. For instance, when will the robot have a confident estimate in a nearby human's goal? Or, what parameter initializations guarantee that the robot can learn the human's preferences in a finite number of observations? To answer such analysis questions, our key idea is to model the robot's learning algorithm as a dynamical system where the state is the current model parameter estimate and the control is the human data the robot observes. This enables us to leverage tools from reachability analysis and optimal control to compute the set of hypotheses the robot could learn in finite time, as well as the worst and best-case time it takes to learn them. We demonstrate the utility of our analysis tool in four human-robot domains, including autonomous driving and indoor navigation.
On complementing end-to-end human motion predictors with planning
Mar 09, 2021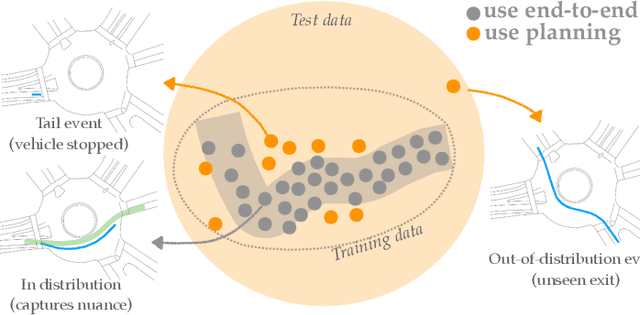
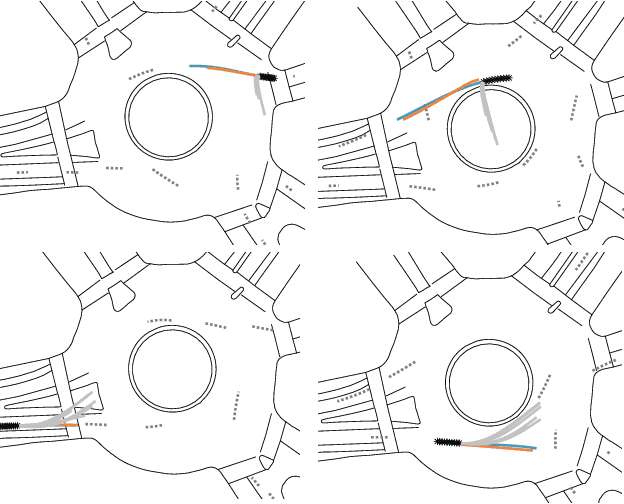
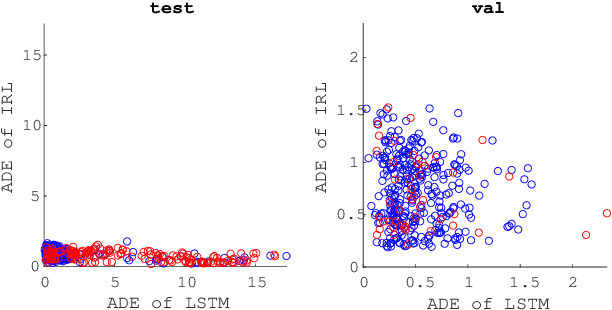
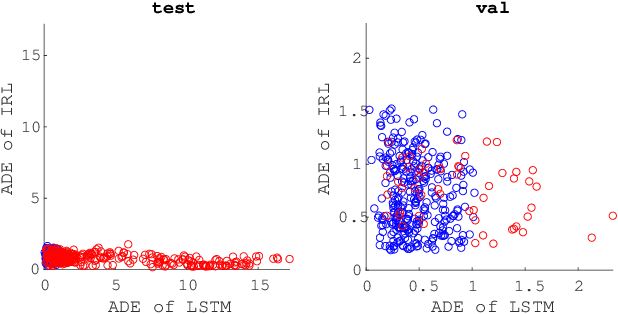
High capacity end-to-end approaches for human motion prediction have the ability to represent subtle nuances in human behavior, but struggle with robustness to out of distribution inputs and tail events. Planning-based prediction, on the other hand, can reliably output decent-but-not-great predictions: it is much more stable in the face of distribution shift, but it has high inductive bias, missing important aspects that drive human decisions, and ignoring cognitive biases that make human behavior suboptimal. In this work, we analyze one family of approaches that strive to get the best of both worlds: use the end-to-end predictor on common cases, but do not rely on it for tail events / out-of-distribution inputs -- switch to the planning-based predictor there. We contribute an analysis of different approaches for detecting when to make this switch, using an autonomous driving domain. We find that promising approaches based on ensembling or generative modeling of the training distribution might not be reliable, but that there very simple methods which can perform surprisingly well -- including training a classifier to pick up on tell-tale issues in predicted trajectories.
Assisted Perception: Optimizing Observations to Communicate State
Aug 06, 2020



We aim to help users estimate the state of the world in tasks like robotic teleoperation and navigation with visual impairments, where users may have systematic biases that lead to suboptimal behavior: they might struggle to process observations from multiple sensors simultaneously, receive delayed observations, or overestimate distances to obstacles. While we cannot directly change the user's internal beliefs or their internal state estimation process, our insight is that we can still assist them by modifying the user's observations. Instead of showing the user their true observations, we synthesize new observations that lead to more accurate internal state estimates when processed by the user. We refer to this method as assistive state estimation (ASE): an automated assistant uses the true observations to infer the state of the world, then generates a modified observation for the user to consume (e.g., through an augmented reality interface), and optimizes the modification to induce the user's new beliefs to match the assistant's current beliefs. We evaluate ASE in a user study with 12 participants who each perform four tasks: two tasks with known user biases -- bandwidth-limited image classification and a driving video game with observation delay -- and two with unknown biases that our method has to learn -- guided 2D navigation and a lunar lander teleoperation video game. A different assistance strategy emerges in each domain, such as quickly revealing informative pixels to speed up image classification, using a dynamics model to undo observation delay in driving, identifying nearby landmarks for navigation, and exaggerating a visual indicator of tilt in the lander game. The results show that ASE substantially improves the task performance of users with bandwidth constraints, observation delay, and other unknown biases.
Feature Expansive Reward Learning: Rethinking Human Input
Jun 23, 2020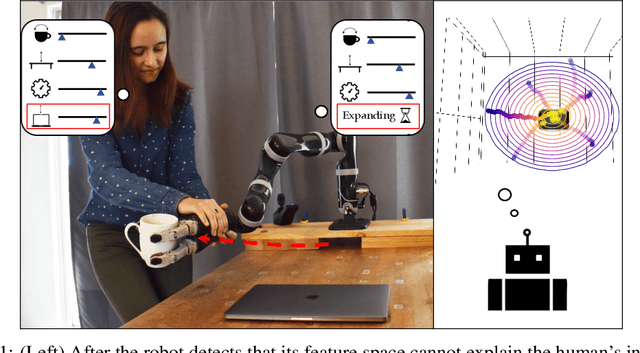

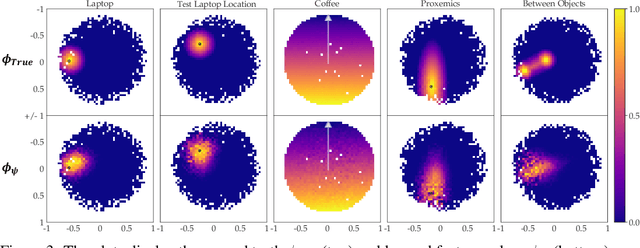
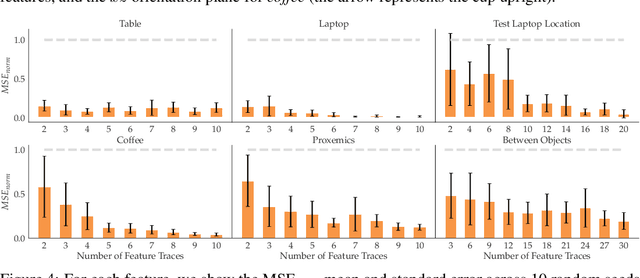
In collaborative human-robot scenarios, when a person is not satisfied with how a robot performs a task, they can intervene to correct it. Reward learning methods enable the robot to adapt its reward function online based on such human input. However, this online adaptation requires low sample complexity algorithms which rely on simple functions of handcrafted features. In practice, pre-specifying an exhaustive set of features the person might care about is impossible; what should the robot do when the human correction cannot be explained by the features it already has access to? Recent progress in deep Inverse Reinforcement Learning (IRL) suggests that the robot could fall back on demonstrations: ask the human for demonstrations of the task, and recover a reward defined over not just the known features, but also the raw state space. Our insight is that rather than implicitly learning about the missing feature(s) from task demonstrations, the robot should instead ask for data that explicitly teaches it about what it is missing. We introduce a new type of human input, in which the person guides the robot from areas of the state space where the feature she is teaching is highly expressed to states where it is not. We propose an algorithm for learning the feature from the raw state space and integrating it into the reward function. By focusing the human input on the missing feature, our method decreases sample complexity and improves generalization of the learned reward over the above deep IRL baseline. We show this in experiments with a 7DOF robot manipulator. Finally, we discuss our method's potential implications for deep reward learning more broadly: taking a divide-and-conquer approach that focuses on important features separately before learning from demonstrations can improve generalization in tasks where such features are easy for the human to teach.
Quantifying Hypothesis Space Misspecification in Learning from Human-Robot Demonstrations and Physical Corrections
Feb 28, 2020



Human input has enabled autonomous systems to improve their capabilities and achieve complex behaviors that are otherwise challenging to generate automatically. Recent work focuses on how robots can use such input - like demonstrations or corrections - to learn intended objectives. These techniques assume that the human's desired objective already exists within the robot's hypothesis space. In reality, this assumption is often inaccurate: there will always be situations where the person might care about aspects of the task that the robot does not know about. Without this knowledge, the robot cannot infer the correct objective. Hence, when the robot's hypothesis space is misspecified, even methods that keep track of uncertainty over the objective fail because they reason about which hypothesis might be correct, and not whether any of the hypotheses are correct. In this paper, we posit that the robot should reason explicitly about how well it can explain human inputs given its hypothesis space and use that situational confidence to inform how it should incorporate human input. We demonstrate our method on a 7 degree-of-freedom robot manipulator in learning from two important types of human input: demonstrations of manipulation tasks, and physical corrections during the robot's task execution.