 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's Hidden in a Randomly Weighted Neural Network?
Nov 29, 2019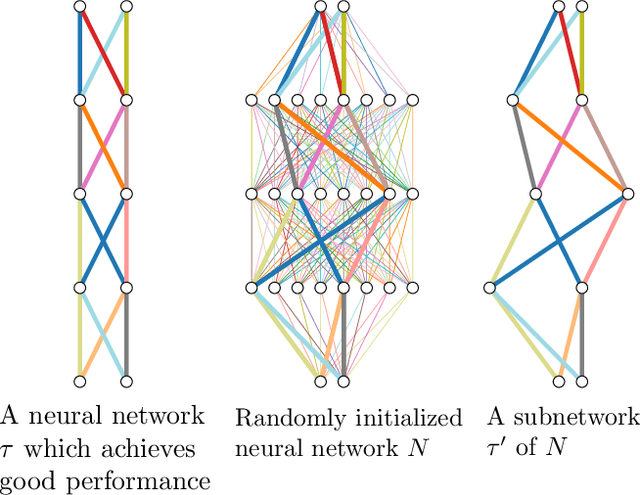
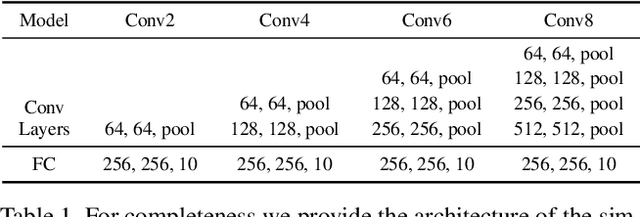
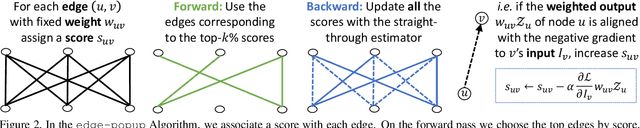
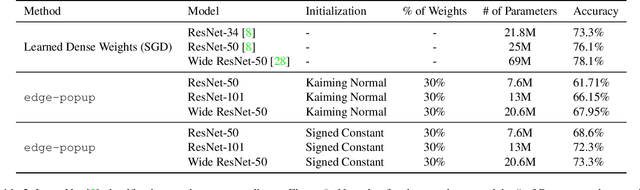
Training a neural network is synonymous with learning the values of the weights. In contrast, we demonstrate that randomly weighted neural networks contain subnetworks which achieve impressive performance without ever training the weight values. Hidden in a randomly weighted Wide ResNet-50 we show that there is a subnetwork (with random weights) that is smaller than, but matches the performance of a ResNet-34 trained on ImageNet. Not only do these "untrained subnetworks" exist, but we provide an algorithm to effectively find them. We empirically show that as randomly weighted neural networks with fixed weights grow wider and deeper, an "untrained subnetwork" approaches a network with learned weights in accuracy.
Conditional Driving from Natural Language Instructions
Oct 16, 2019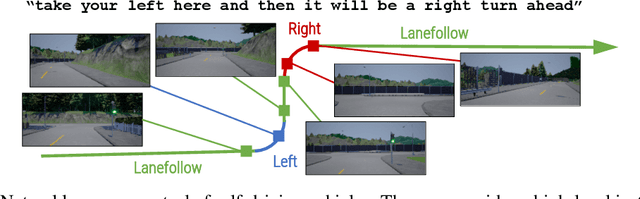
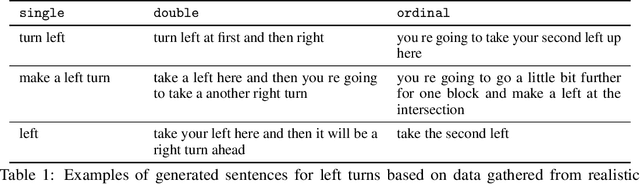
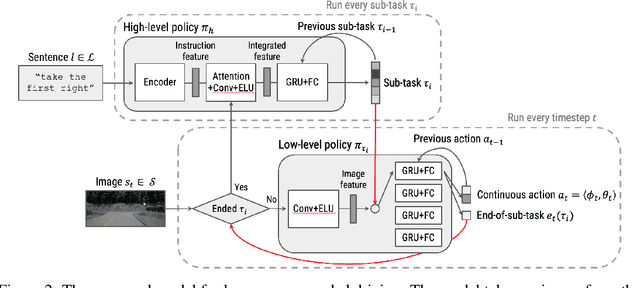
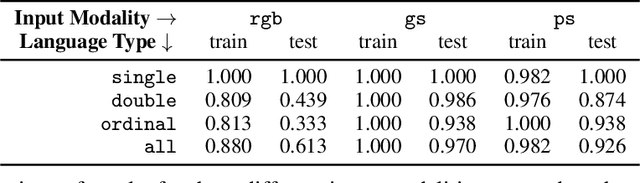
Widespread adoption of self-driving cars will depend not only on their safety but largely on their ability to interact with human users. Just like human drivers, self-driving cars will be expected to understand and safely follow natural-language directions that suddenly alter the pre-planned route according to user's preference or in presence of ambiguities, particularly in locations with poor or outdated map coverage. To this end, we propose a language-grounded driving agent implementing a hierarchical policy using recurrent layers and gated attention. The hierarchical approach enables us to reason both in terms of high-level language instructions describing long time horizons and low-level, complex, continuous state/action spaces required for real-time control of a self-driving car. We train our policy with conditional imitation learning from realistic language data collected from human drivers and navigators. Through quantitative and interactive experiments within the CARLA framework, we show that our model can successfully interpret language instructions and follow them safely, even when generalizing to previously unseen environments. Code and video are available at https://sites.google.com/view/language-grounded-driving.
Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
Jun 14, 2019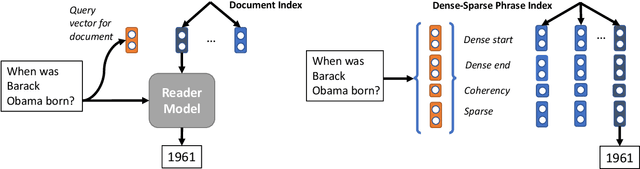
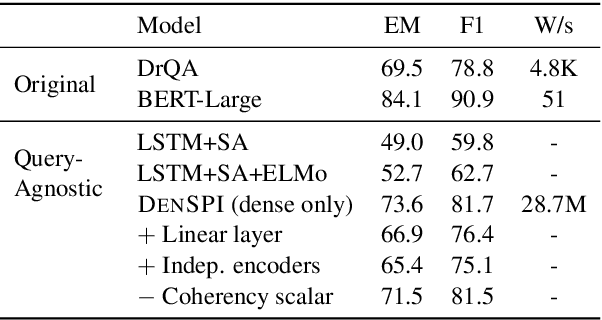
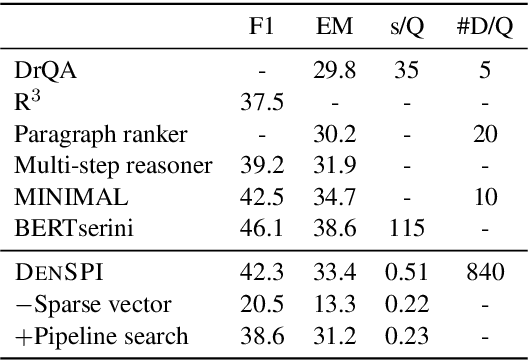

Existing open-domain question answering (QA) models are not suitable for real-time usage because they need to process several long documents on-demand for every input query. In this paper, we introduce the query-agnostic indexable representation of document phrases that can drastically speed up open-domain QA and also allows us to reach long-tail targets. In particular, our dense-sparse phrase encoding effectively captures syntactic, semantic, and lexical information of the phrases and eliminates the pipeline filtering of context documents. Leveraging optimization strategies, our model can be trained in a single 4-GPU server and serve entire Wikipedia (up to 60 billion phrases) under 2TB with CPUs only. Our experiments on SQuAD-Open show that our model is more accurate than DrQA (Chen et al., 2017) with 6000x reduced computational cost, which translates into at least 58x faster end-to-end inference benchmark on CPUs.
Butterfly Transform: An Efficient FFT Based Neural Architecture Design
Jun 05, 2019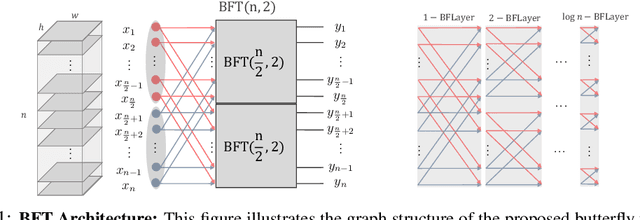
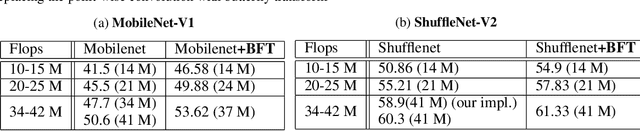
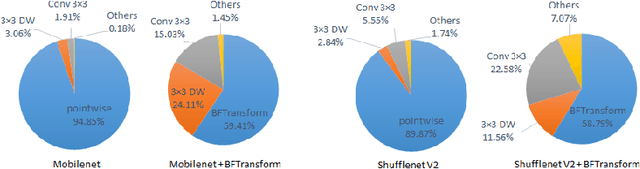
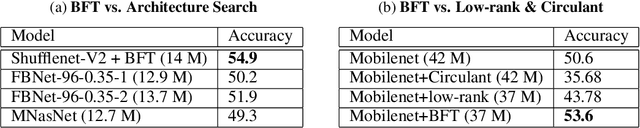
In this paper, we introduce the Butterfly Transform (BFT), a light weight channel fusion method that reduces the computational complexity of point-wise convolutions from O(n^2) of conventional solutions to O(n log n) with respect to the number of channels while improving the accuracy of the networks under the same range of FLOPs. The proposed BFT generalizes the Discrete Fourier Transform in a way that its parameters are learned at training time. Our experimental evaluations show that replacing channel fusion modules with \sys results in significant accuracy gains at similar FLOPs across a wide range of network architectures. For example, replacing channel fusion convolutions with BFT offers 3% absolute top-1 improvement for MobileNetV1-0.25 and 2.5% for ShuffleNet V2-0.5 while maintaining the same number of FLOPS. Notably, the ShuffleNet-V2+BFT outperforms state-of-the-art architecture search methods MNasNet \cite{tan2018mnasnet} and FBNet \cite{wu2018fbnet}. We also show that the structure imposed by BFT has interesting properties that ensures the efficacy of the resulting network.
Discovering Neural Wirings
Jun 03, 2019

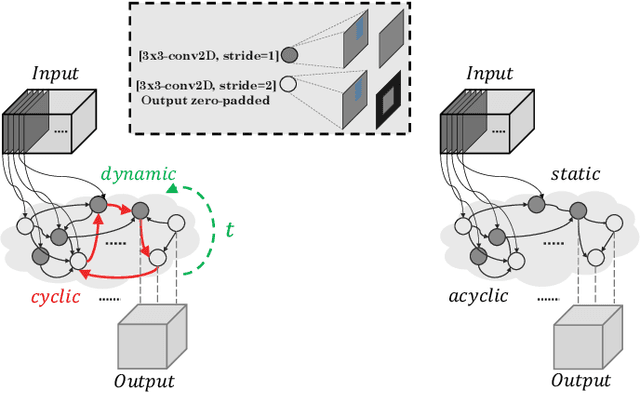
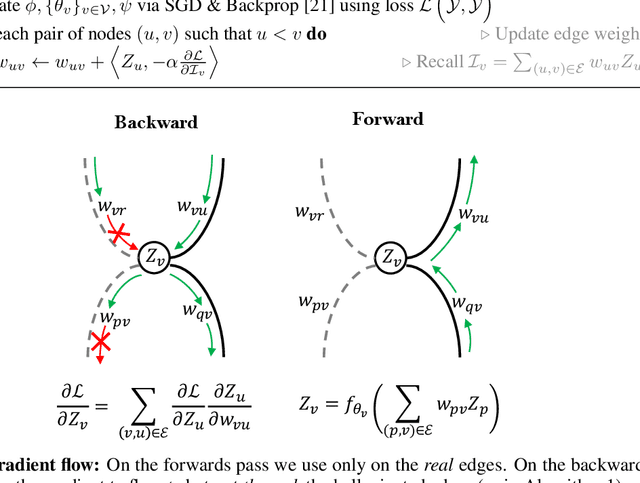
The success of neural networks has driven a shift in focus from feature engineering to architecture engineering. However, successful networks today are constructed using a small and manually defined set of building blocks. Even in methods of neural architecture search (NAS) the network connectivity patterns are largely constrained. In this work we propose a method for discovering neural wirings. We relax the typical notion of layers and instead enable channels to form connections independent of each other. This allows for a much larger space of possible networks. The wiring of our network is not fixed during training -- as we learn the network parameters we also learn the structure itself. Our experiments demonstrate that our learned connectivity outperforms hand engineered and randomly wired networks. By learning the connectivity of MobileNetV1 [9] we boost the ImageNet accuracy by 10% at ~41M FLOPs. Moreover, we show that our method generalizes to recurrent and continuous time networks.
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge
May 31, 2019


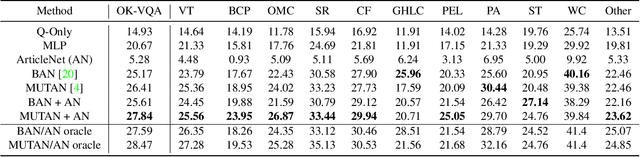
Visual Question Answering (VQA) in its ideal form lets us study reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most VQA benchmarks to date are focused on questions such as simple counting, visual attributes, and object detection that do not require reasoning or knowledge beyond what is in the image. In this paper, we address the task of knowledge-based visual question answering and provide a benchmark, called OK-VQA, where the image content is not sufficient to answer the questions, encouraging methods that rely on external knowledge resources. Our new dataset includes more than 14,000 questions that require external knowledge to answer. We show that the performance of the state-of-the-art VQA models degrades drastically in this new setting. Our analysis shows that our knowledge-based VQA task is diverse, difficult, and large compared to previous knowledge-based VQA datasets. We hope that this dataset enables researchers to open up new avenues for research in this domain. See http://okvqa.allenai.org to download and browse the dataset.
Defending Against Neural Fake News
May 29, 2019
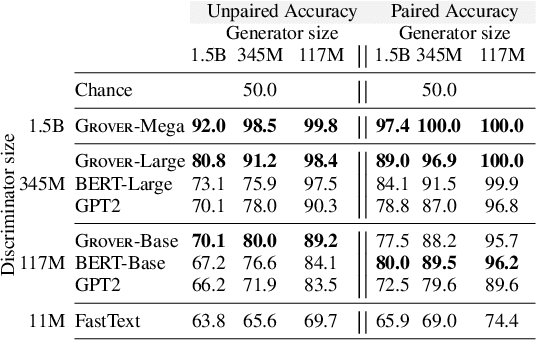
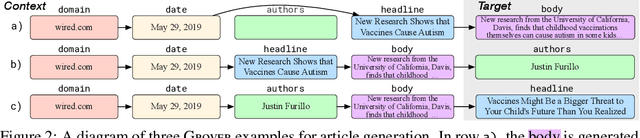
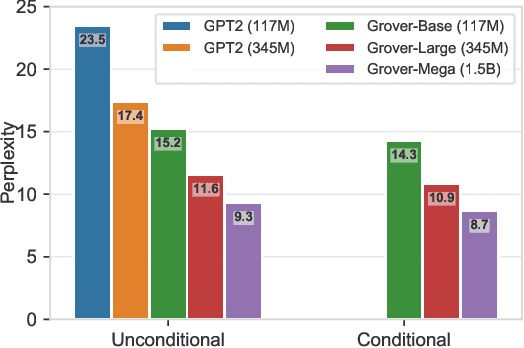
Recent progress in natural language generation has raised dual-use concerns. While applications like summarization and translation are positive, the underlying technology also might enable adversaries to generate neural fake news: targeted propaganda that closely mimics the style of real news. Modern computer security relies on careful threat modeling: identifying potential threats and vulnerabilities from an adversary's point of view, and exploring potential mitigations to these threats. Likewise, developing robust defenses against neural fake news requires us first to carefully investigate and characterize the risks of these models. We thus present a model for controllable text generation called Grover. Given a headline like `Link Found Between Vaccines and Autism,' Grover can generate the rest of the article; humans find these generations to be more trustworthy than human-written disinformation. Developing robust verification techniques against generators like Grover is critical. We find that best current discriminators can classify neural fake news from real, human-written, news with 73% accuracy, assuming access to a moderate level of training data. Counterintuitively, the best defense against Grover turns out to be Grover itself, with 92% accuracy, demonstrating the importance of public release of strong generators. We investigate these results further, showing that exposure bias -- and sampling strategies that alleviate its effects -- both leave artifacts that similar discriminators can pick up on. We conclude by discussing ethical issues regarding the technology, and plan to release Grover publicly, helping pave the way for better detection of neural fake news.
HellaSwag: Can a Machine Really Finish Your Sentence?
May 19, 2019
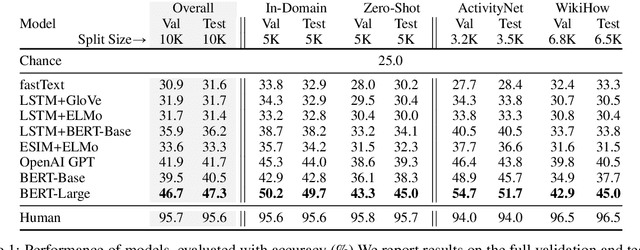
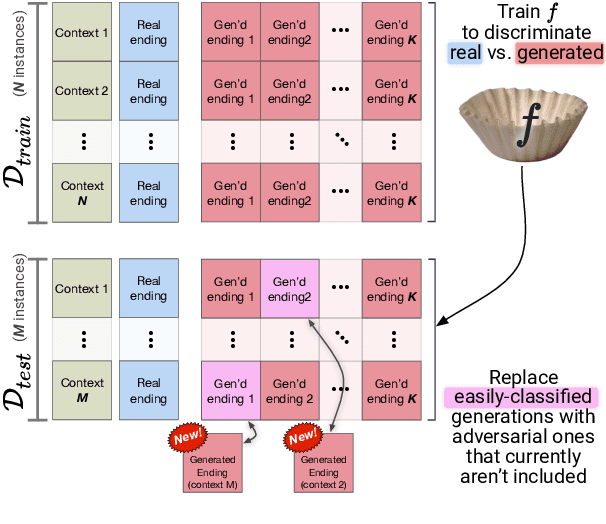
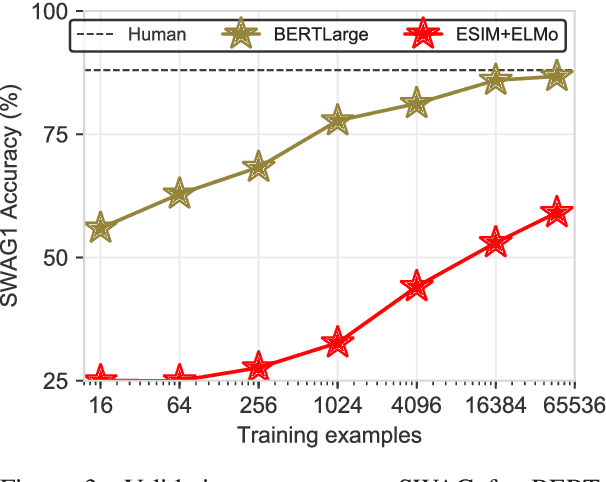
Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as "A woman sits at a piano," a machine must select the most likely followup: "She sets her fingers on the keys." With the introduction of BERT, near human-level performance was reached. Does this mean that machines can perform human level commonsense inference? In this paper, we show that commonsense inference still proves difficult for even state-of-the-art models, by presenting HellaSwag, a new challenge dataset. Though its questions are trivial for humans (>95% accuracy), state-of-the-art models struggle (<48%). We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical 'Goldilocks' zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models. Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges.
Two Body Problem: Collaborative Visual Task Completion
Apr 11, 2019
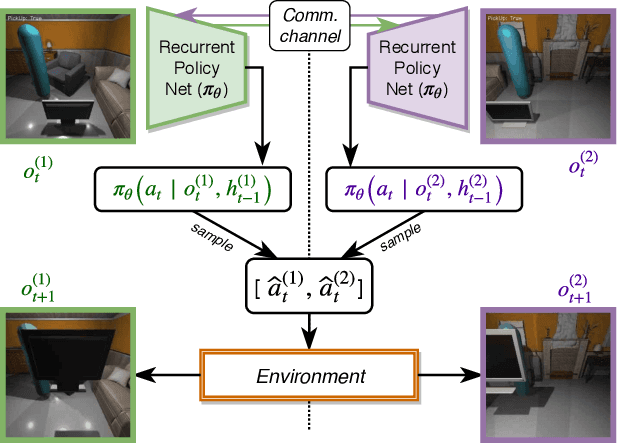
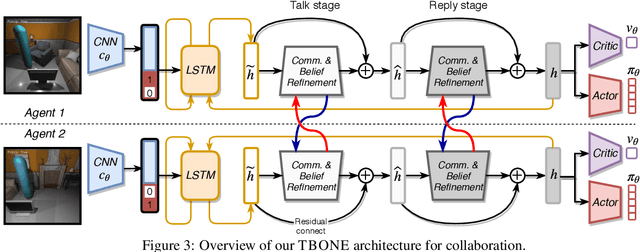
Collaboration is a necessary skill to perform tasks that are beyond one agent's capabilities. Addressed extensively in both conventional and modern AI, multi-agent collaboration has often been studied in the context of simple grid worlds. We argue that there are inherently visual aspects to collaboration which should be studied in visually rich environments. A key element in collaboration is communication that can be either explicit, through messages, or implicit, through perception of the other agents and the visual world. Learning to collaborate in a visual environment entails learning (1) to perform the task, (2) when and what to communicate, and (3) how to act based on these communications and the perception of the visual world. In this paper we study the problem of learning to collaborate directly from pixels in AI2-THOR and demonstrate the benefits of explicit and implicit modes of communication to perform visual tasks. Refer to our project page for more details: https://prior.allenai.org/projects/two-body-problem
Video Relationship Reasoning using Gated Spatio-Temporal Energy Graph
Mar 27, 2019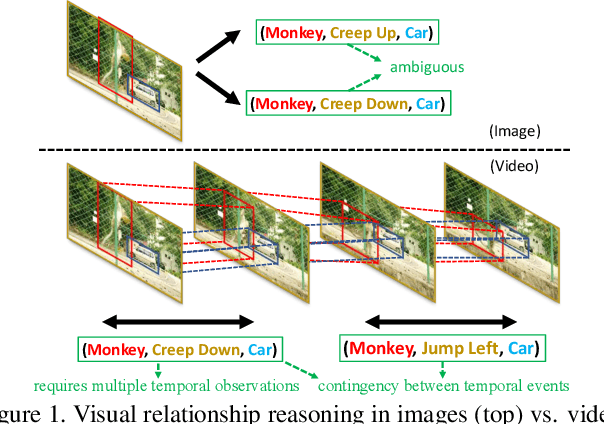
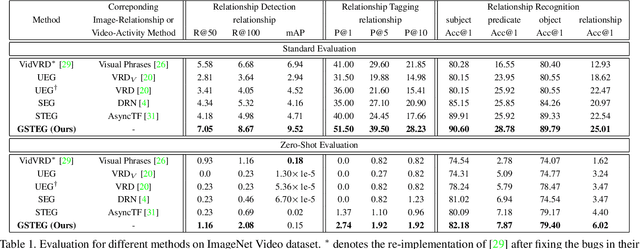
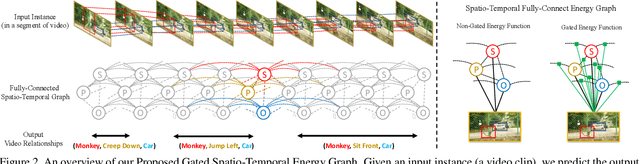
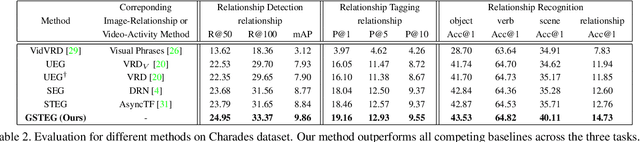
Visual relationship reasoning is a crucial yet challenging task for understanding rich interactions across visual concepts. For example, a relationship 'man, open, door' involves a complex relation 'open' between concrete entities 'man, door'. While much of the existing work has studied this problem in the context of still images, understanding visual relationships in videos has received limited attention. Due to their temporal nature, videos enable us to model and reason about a more comprehensive set of visual relationships, such as those requiring multiple (temporal) observations (e.g., 'man, lift up, box' vs. 'man, put down, box'), as well as relationships that are often correlated through time (e.g., 'woman, pay, money' followed by 'woman, buy, coffee'). In this paper, we construct a Conditional Random Field on a fully-connected spatio-temporal graph that exploits the statistical dependency between relational entities spatially and temporally. We introduce a novel gated energy function parametrization that learns adaptive relations conditioned on visual observations. Our model optimization is computationally efficient, and its space computation complexity is significantly amortized through our proposed parameterization. Experimental results on benchmark video datasets (ImageNet Video and Charades) demonstrate state-of-the-art performance across three standard relationship reasoning tasks: Detection, Tagging, and Recognition.