 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization via Scalable Neighborhood Component Analysis
Aug 14, 2018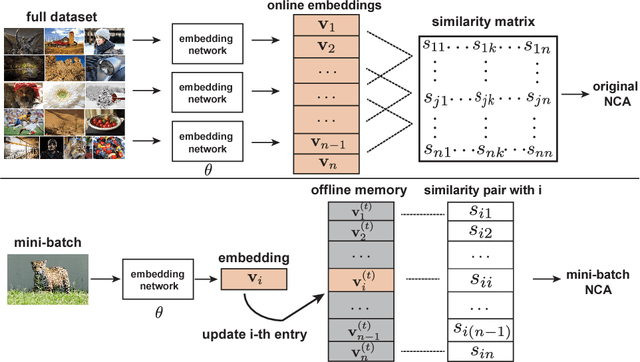
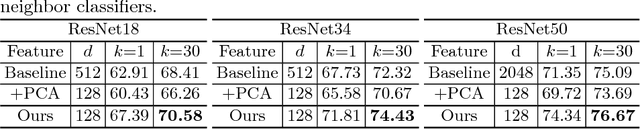
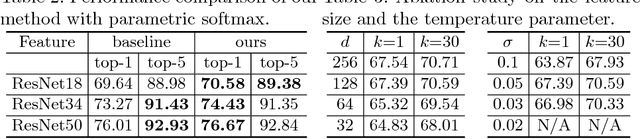

Current major approaches to visual recognition follow an end-to-end formulation that classifies an input image into one of the pre-determined set of semantic categories. Parametric softmax classifiers are a common choice for such a closed world with fixed categories, especially when big labeled data is available during training. However, this becomes problematic for open-set scenarios where new categories are encountered with very few examples for learning a generalizable parametric classifier. We adopt a non-parametric approach for visual recognition by optimizing feature embeddings instead of parametric classifiers. We use a deep neural network to learn the visual feature that preserves the neighborhood structure in the semantic space, based on the Neighborhood Component Analysis (NCA) criterion. Limited by its computational bottlenecks, we devise a mechanism to use augmented memory to scale NCA for large datasets and very deep networks. Our experiments deliver not only remarkable performance on ImageNet classification for such a simple non-parametric method, but most importantly a more generalizable feature representation for sub-category discovery and few-shot recognition.
Large-Scale Study of Curiosity-Driven Learning
Aug 13, 2018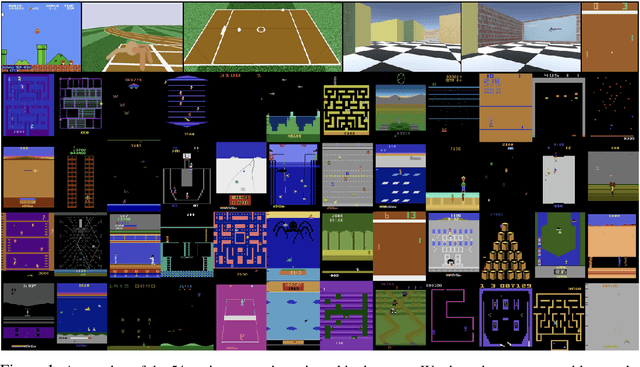

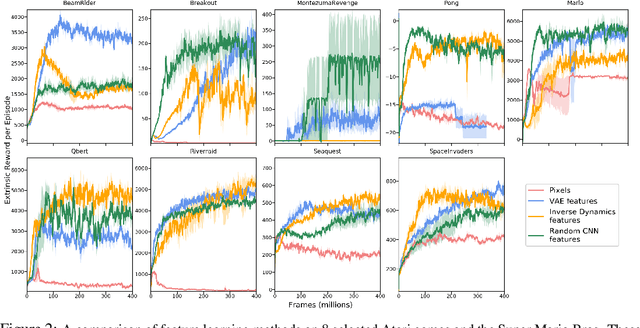

Reinforcement learning algorithms rely on carefully engineering environment rewards that are extrinsic to the agent. However, annotating each environment with hand-designed, dense rewards is not scalable, motivating the need for developing reward functions that are intrinsic to the agent. Curiosity is a type of intrinsic reward function which uses prediction error as reward signal. In this paper: (a) We perform the first large-scale study of purely curiosity-driven learning, i.e. without any extrinsic rewards, across 54 standard benchmark environments, including the Atari game suite. Our results show surprisingly good performance, and a high degree of alignment between the intrinsic curiosity objective and the hand-designed extrinsic rewards of many game environments. (b) We investigate the effect of using different feature spaces for computing prediction error and show that random features are sufficient for many popular RL game benchmarks, but learned features appear to generalize better (e.g. to novel game levels in Super Mario Bros.). (c) We demonstrate limitations of the prediction-based rewards in stochastic setups. Game-play videos and code are at https://pathak22.github.io/large-scale-curiosity/
Learning Shape Abstractions by Assembling Volumetric Primitives
Aug 02, 2018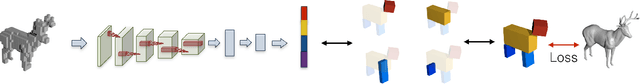

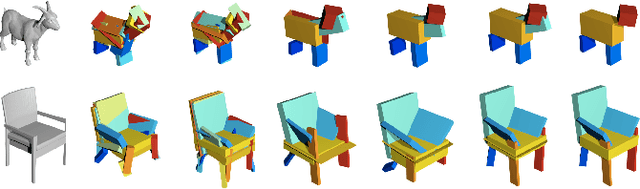
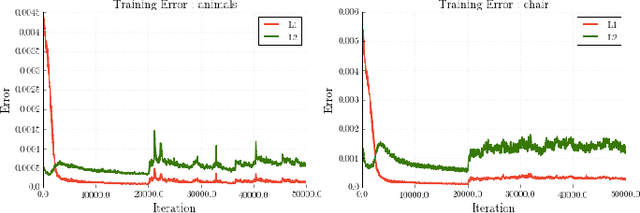
We present a learning framework for abstracting complex shapes by learning to assemble objects using 3D volumetric primitives. In addition to generating simple and geometrically interpretable explanations of 3D objects, our framework also allows us to automatically discover and exploit consistent structure in the data. We demonstrate that using our method allows predicting shape representations which can be leveraged for obtaining a consistent parsing across the instances of a shape collection and constructing an interpretable shape similarity measure. We also examine applications for image-based prediction as well as shape manipulation.
Learning Category-Specific Mesh Reconstruction from Image Collections
Jul 30, 2018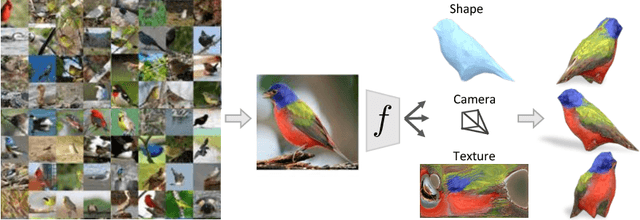
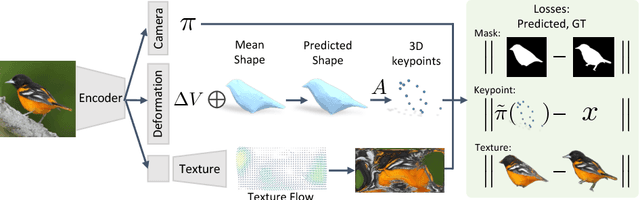
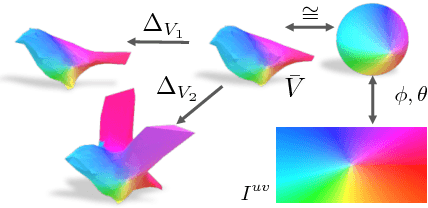

We present a learning framework for recovering the 3D shape, camera, and texture of an object from a single image. The shape is represented as a deformable 3D mesh model of an object category where a shape is parameterized by a learned mean shape and per-instance predicted deformation. Our approach allows leveraging an annotated image collection for training, where the deformable model and the 3D prediction mechanism are learned without relying on ground-truth 3D or multi-view supervision. Our representation enables us to go beyond existing 3D prediction approaches by incorporating texture inference as prediction of an image in a canonical appearance space. Additionally, we show that semantic keypoints can be easily associated with the predicted shapes. We present qualitative and quantitative results of our approach on CUB and PASCAL3D datasets and show that we can learn to predict diverse shapes and textures across objects using only annotated image collections. The project website can be found at https://akanazawa.github.io/cmr/.
Investigating Human Priors for Playing Video Games
Jul 25, 2018



What makes humans so good at solving seemingly complex video games? Unlike computers, humans bring in a great deal of prior knowledge about the world, enabling efficient decision making. This paper investigates the role of human priors for solving video games. Given a sample game, we conduct a series of ablation studies to quantify the importance of various priors on human performance. We do this by modifying the video game environment to systematically mask different types of visual information that could be used by humans as priors. We find that removal of some prior knowledge causes a drastic degradation in the speed with which human players solve the game, e.g. from 2 minutes to over 20 minutes. Furthermore, our results indicate that general priors, such as the importance of objects and visual consistency, are critical for efficient game-play. Videos and the game manipulations are available at https://rach0012.github.io/humanRL_website/
* ICML 2018
3D Sketching using Multi-View Deep Volumetric Prediction
Jun 19, 2018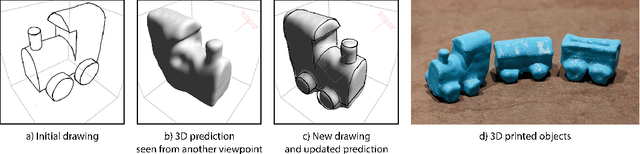

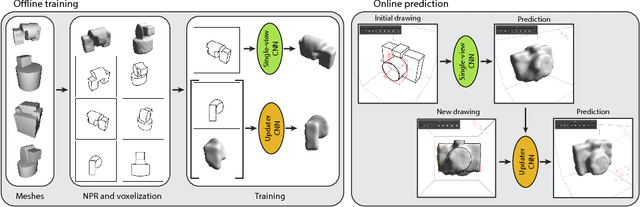
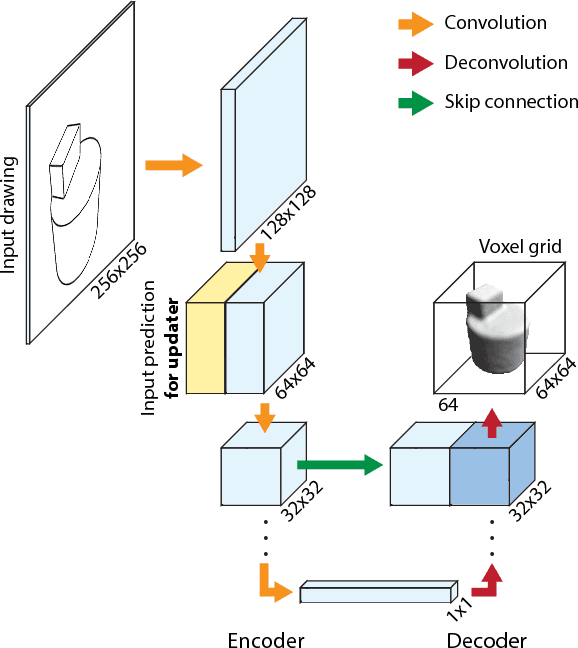
Sketch-based modeling strives to bring the ease and immediacy of drawing to the 3D world. However, while drawings are easy for humans to create, they are very challenging for computers to interpret due to their sparsity and ambiguity. We propose a data-driven approach that tackles this challenge by learning to reconstruct 3D shapes from one or more drawings. At the core of our approach is a deep convolutional neural network (CNN) that predicts occupancy of a voxel grid from a line drawing. This CNN provides us with an initial 3D reconstruction as soon as the user completes a single drawing of the desired shape. We complement this single-view network with an updater CNN that refines an existing prediction given a new drawing of the shape created from a novel viewpoint. A key advantage of our approach is that we can apply the updater iteratively to fuse information from an arbitrary number of viewpoints, without requiring explicit stroke correspondences between the drawings. We train both CNNs by rendering synthetic contour drawings from hand-modeled shape collections as well as from procedurally-generated abstract shapes. Finally, we integrate our CNNs in a minimal modeling interface that allows users to seamlessly draw an object, rotate it to see its 3D reconstruction, and refine it by re-drawing from another vantage point using the 3D reconstruction as guidance. The main strengths of our approach are its robustness to freehand bitmap drawings, its ability to adapt to different object categories, and the continuum it offers between single-view and multi-view sketch-based modeling.
Few-Shot Segmentation Propagation with Guided Networks
May 25, 2018

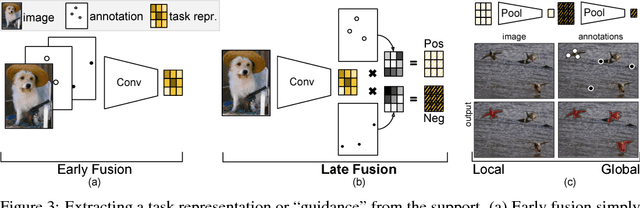

Learning-based methods for visual segmentation have made progress on particular types of segmentation tasks, but are limited by the necessary supervision, the narrow definitions of fixed tasks, and the lack of control during inference for correcting errors. To remedy the rigidity and annotation burden of standard approaches, we address the problem of few-shot segmentation: given few image and few pixel supervision, segment any images accordingly. We propose guided networks, which extract a latent task representation from any amount of supervision, and optimize our architecture end-to-end for fast, accurate few-shot segmentation. Our method can switch tasks without further optimization and quickly update when given more guidance. We report the first results for segmentation from one pixel per concept and show real-time interactive video segmentation. Our unified approach propagates pixel annotations across space for interactive segmentation, across time for video segmentation, and across scenes for semantic segmentation. Our guided segmentor is state-of-the-art in accuracy for the amount of annotation and time. See http://github.com/shelhamer/revolver for code, models, and more details.
Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene
Apr 24, 2018
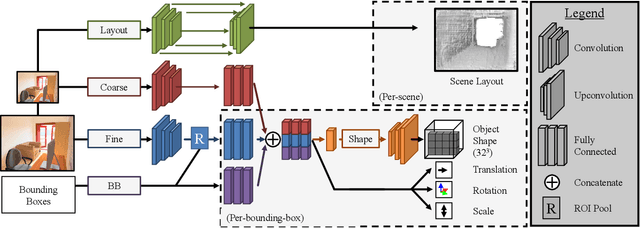

The goal of this paper is to take a single 2D image of a scene and recover the 3D structure in terms of a small set of factors: a layout representing the enclosing surfaces as well as a set of objects represented in terms of shape and pose. We propose a convolutional neural network-based approach to predict this representation and benchmark it on a large dataset of indoor scenes. Our experiments evaluate a number of practical design questions, demonstrate that we can infer this representation, and quantitatively and qualitatively demonstrate its merits compared to alternate representations.
Multi-view Consistency as Supervisory Signal for Learning Shape and Pose Prediction
Apr 24, 2018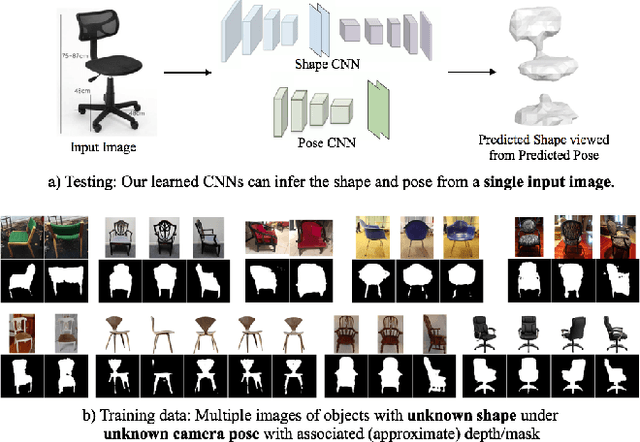
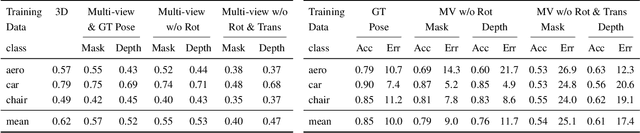
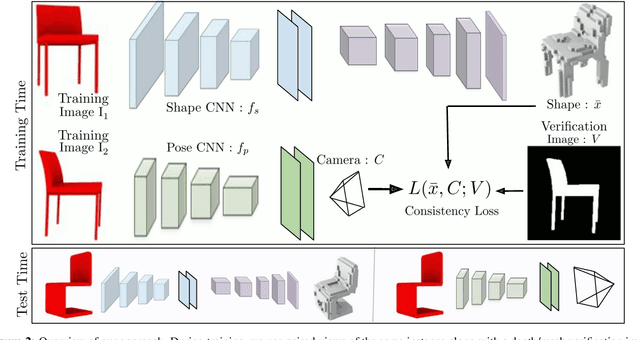

We present a framework for learning single-view shape and pose prediction without using direct supervision for either. Our approach allows leveraging multi-view observations from unknown poses as supervisory signal during training. Our proposed training setup enforces geometric consistency between the independently predicted shape and pose from two views of the same instance. We consequently learn to predict shape in an emergent canonical (view-agnostic) frame along with a corresponding pose predictor. We show empirical and qualitative results using the ShapeNet dataset and observe encouragingly competitive performance to previous techniques which rely on stronger forms of supervision. We also demonstrate the applicability of our framework in a realistic setting which is beyond the scope of existing techniques: using a training dataset comprised of online product images where the underlying shape and pose are unknown.
Zero-Shot Visual Imitation
Apr 23, 2018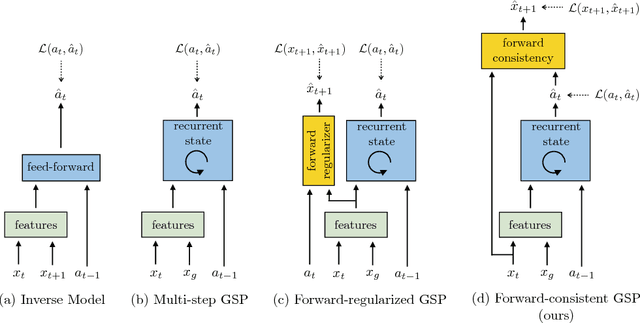
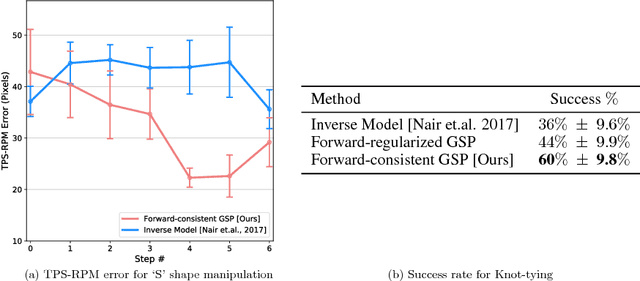


The current dominant paradigm for imitation learning relies on strong supervision of expert actions to learn both 'what' and 'how' to imitate. We pursue an alternative paradigm wherein an agent first explores the world without any expert supervision and then distills its experience into a goal-conditioned skill policy with a novel forward consistency loss. In our framework, the role of the expert is only to communicate the goals (i.e., what to imitate) during inference. The learned policy is then employed to mimic the expert (i.e., how to imitate) after seeing just a sequence of images demonstrating the desired task. Our method is 'zero-shot' in the sense that the agent never has access to expert actions during training or for the task demonstration at inference. We evaluate our zero-shot imitator in two real-world settings: complex rope manipulation with a Baxter robot and navigation in previously unseen office environments with a TurtleBot. Through further experiments in VizDoom simulation, we provide evidence that better mechanisms for exploration lead to learning a more capable policy which in turn improves end task performance. Videos, models, and more details are available at https://pathak22.github.io/zeroshot-imitation/