 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinating Pose-Compatible Scenes
Dec 13, 2021
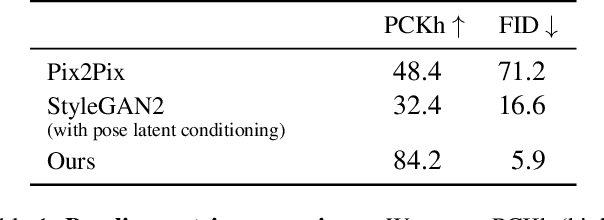

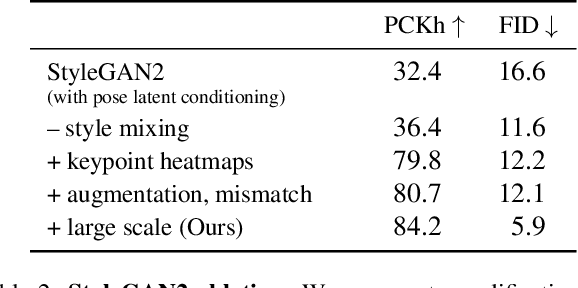
What does human pose tell us about a scene? We propose a task to answer this question: given human pose as input, hallucinate a compatible scene. Subtle cues captured by human pose -- action semantics, environment affordances, object interactions -- provide surprising insight into which scenes are compatible. We present a large-scale generative adversarial network for pose-conditioned scene generation. We significantly scale the size and complexity of training data, curating a massive meta-dataset containing over 19 million frames of humans in everyday environments. We double the capacity of our model with respect to StyleGAN2 to handle such complex data, and design a pose conditioning mechanism that drives our model to learn the nuanced relationship between pose and scene. We leverage our trained model for various applications: hallucinating pose-compatible scene(s) with or without humans, visualizing incompatible scenes and poses, placing a person from one generated image into another scene, and animating pose. Our model produces diverse samples and outperforms pose-conditioned StyleGAN2 and Pix2Pix baselines in terms of accurate human placement (percent of correct keypoints) and image quality (Frechet inception distance).
Learning Co-segmentation by Segment Swapping for Retrieval and Discovery
Oct 29, 2021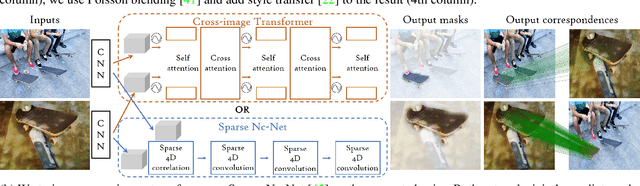
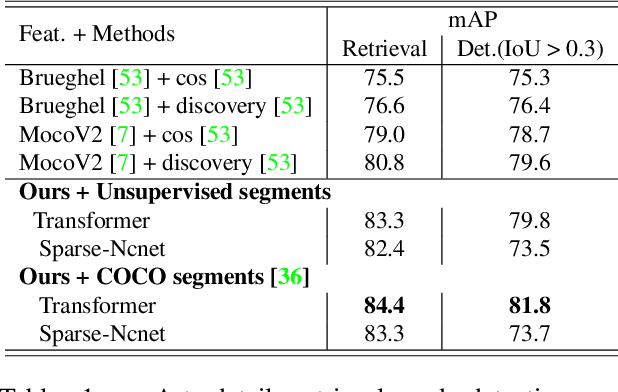
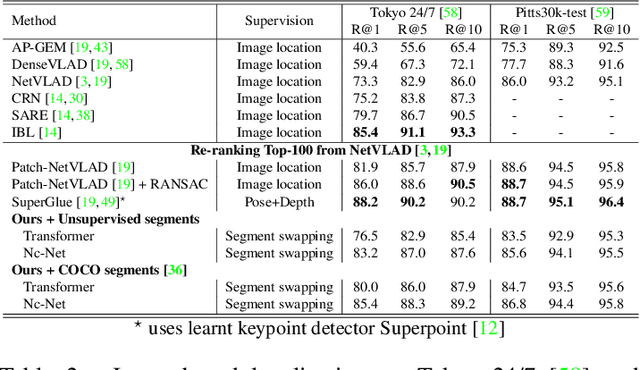

The goal of this work is to efficiently identify visually similar patterns from a pair of images, e.g. identifying an artwork detail copied between an engraving and an oil painting, or matching a night-time photograph with its daytime counterpart. Lack of training data is a key challenge for this co-segmentation task. We present a simple yet surprisingly effective approach to overcome this difficulty: we generate synthetic training pairs by selecting object segments in an image and copy-pasting them into another image. We then learn to predict the repeated object masks. We find that it is crucial to predict the correspondences as an auxiliary task and to use Poisson blending and style transfer on the training pairs to generalize on real data. We analyse results with two deep architectures relevant to our joint image analysis task: a transformer-based architecture and Sparse Nc-Net, a recent network designed to predict coarse correspondences using 4D convolutions. We show our approach provides clear improvements for artwork details retrieval on the Brueghel dataset and achieves competitive performance on two place recognition benchmarks, Tokyo247 and Pitts30K. We then demonstrate the potential of our approach by performing object discovery on the Internet object discovery dataset and the Brueghel dataset. Our code and data are available at http://imagine.enpc.fr/~shenx/SegSwap/.
Video Autoencoder: self-supervised disentanglement of static 3D structure and motion
Oct 06, 2021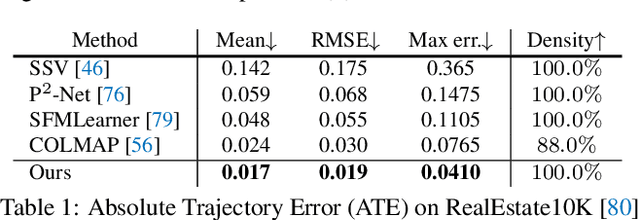
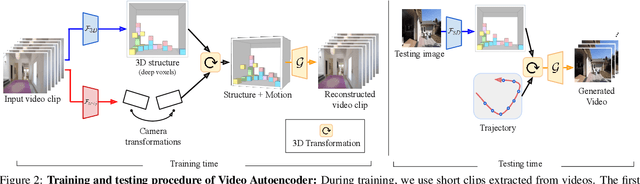
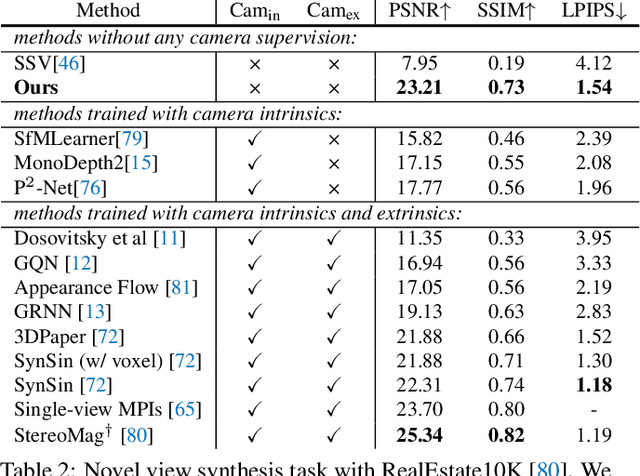
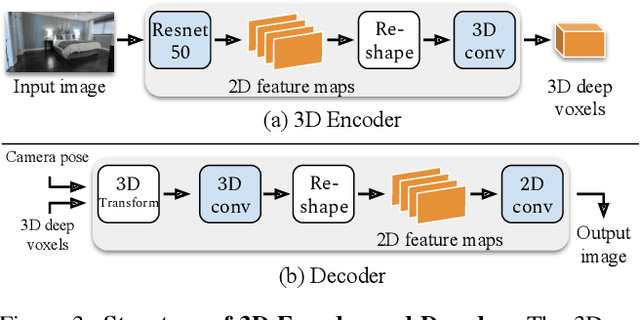
A video autoencoder is proposed for learning disentan- gled representations of 3D structure and camera pose from videos in a self-supervised manner. Relying on temporal continuity in videos, our work assumes that the 3D scene structure in nearby video frames remains static. Given a sequence of video frames as input, the video autoencoder extracts a disentangled representation of the scene includ- ing: (i) a temporally-consistent deep voxel feature to represent the 3D structure and (ii) a 3D trajectory of camera pose for each frame. These two representations will then be re-entangled for rendering the input video frames. This video autoencoder can be trained directly using a pixel reconstruction loss, without any ground truth 3D or camera pose annotations. The disentangled representation can be applied to a range of tasks, including novel view synthesis, camera pose estimation, and video generation by motion following. We evaluate our method on several large- scale natural video datasets, and show generalization results on out-of-domain images.
MarioNette: Self-Supervised Sprite Learning
Apr 29, 2021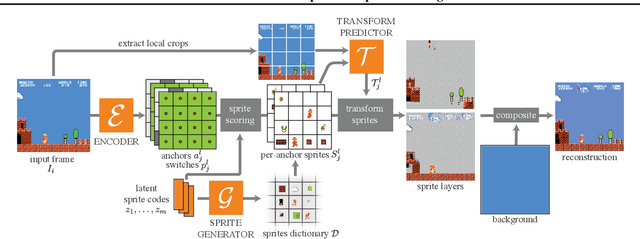
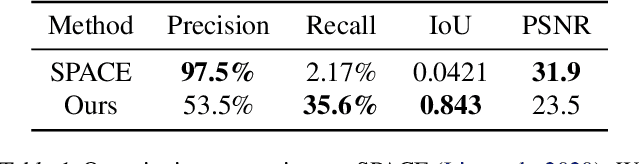
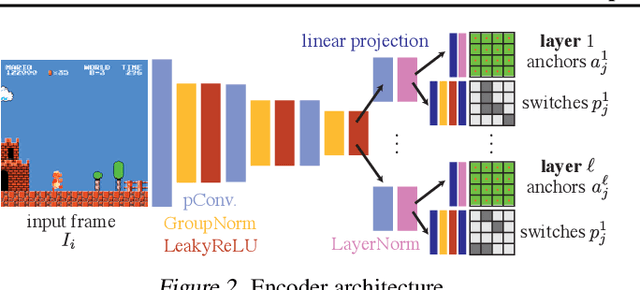
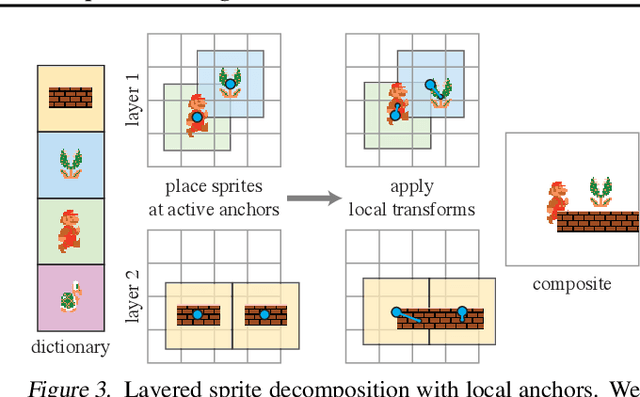
Visual content often contains recurring elements. Text is made up of glyphs from the same font, animations, such as cartoons or video games, are composed of sprites moving around the screen, and natural videos frequently have repeated views of objects. In this paper, we propose a deep learning approach for obtaining a graphically disentangled representation of recurring elements in a completely self-supervised manner. By jointly learning a dictionary of texture patches and training a network that places them onto a canvas, we effectively deconstruct sprite-based content into a sparse, consistent, and interpretable representation that can be easily used in downstream tasks. Our framework offers a promising approach for discovering recurring patterns in image collections without supervision.
Few-shot Image Generation via Cross-domain Correspondence
Apr 13, 2021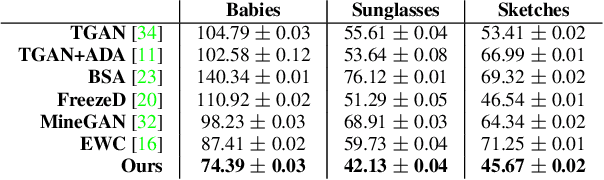

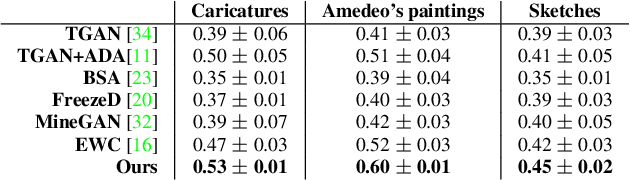
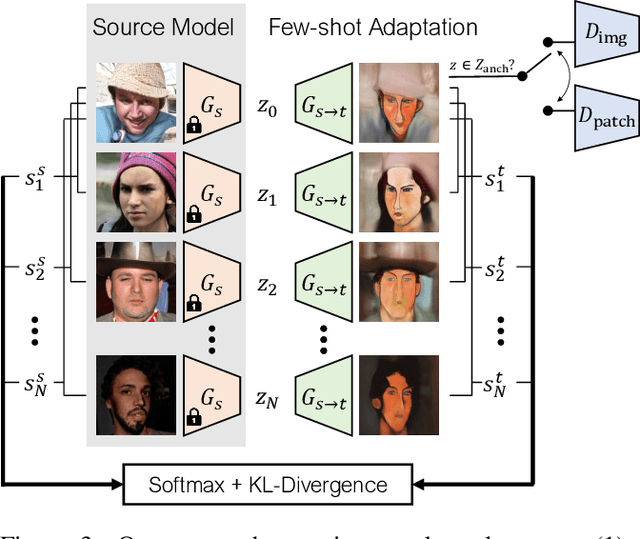
Training generative models, such as GANs, on a target domain containing limited examples (e.g., 10) can easily result in overfitting. In this work, we seek to utilize a large source domain for pretraining and transfer the diversity information from source to target. We propose to preserve the relative similarities and differences between instances in the source via a novel cross-domain distance consistency loss. To further reduce overfitting, we present an anchor-based strategy to encourage different levels of realism over different regions in the latent space. With extensive results in both photorealistic and non-photorealistic domains, we demonstrate qualitatively and quantitatively that our few-shot model automatically discovers correspondences between source and target domains and generates more diverse and realistic images than previous methods.
Strumming to the Beat: Audio-Conditioned Contrastive Video Textures
Apr 06, 2021
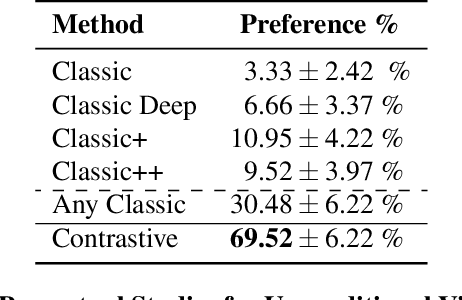

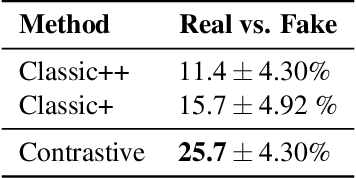
We introduce a non-parametric approach for infinite video texture synthesis using a representation learned via contrastive learning. We take inspiration from Video Textures, which showed that plausible new videos could be generated from a single one by stitching its frames together in a novel yet consistent order. This classic work, however, was constrained by its use of hand-designed distance metrics, limiting its use to simple, repetitive videos. We draw on recent techniques from self-supervised learning to learn this distance metric, allowing us to compare frames in a manner that scales to more challenging dynamics, and to condition on other data, such as audio. We learn representations for video frames and frame-to-frame transition probabilities by fitting a video-specific model trained using contrastive learning. To synthesize a texture, we randomly sample frames with high transition probabilities to generate diverse temporally smooth videos with novel sequences and transitions. The model naturally extends to an audio-conditioned setting without requiring any finetuning. Our model outperforms baselines on human perceptual scores, can handle a diverse range of input videos, and can combine semantic and audio-visual cues in order to synthesize videos that synchronize well with an audio signal.
Learning Cross-Domain Correspondence for Control with Dynamics Cycle-Consistency
Dec 17, 2020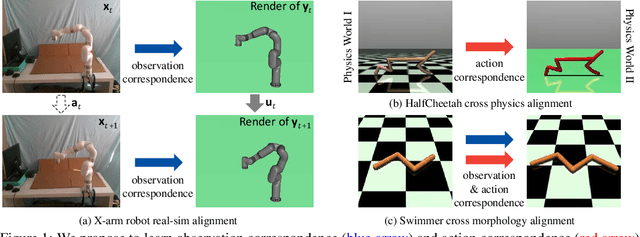
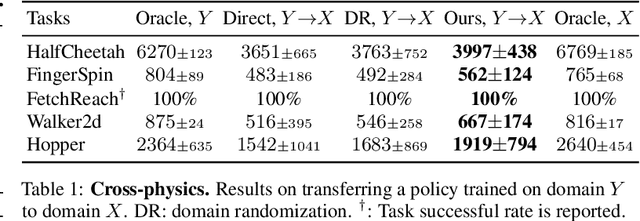
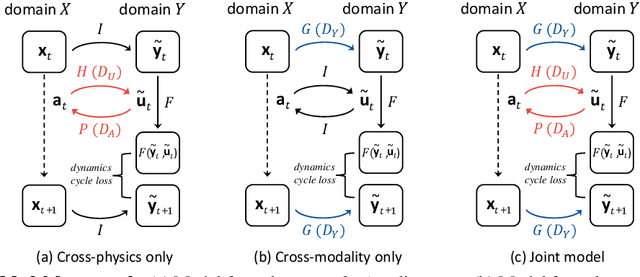

At the heart of many robotics problems is the challenge of learning correspondences across domains. For instance, imitation learning requires obtaining correspondence between humans and robots; sim-to-real requires correspondence between physics simulators and the real world; transfer learning requires correspondences between different robotics environments. This paper aims to learn correspondence across domains differing in representation (vision vs. internal state), physics parameters (mass and friction), and morphology (number of limbs). Importantly, correspondences are learned using unpaired and randomly collected data from the two domains. We propose \textit{dynamics cycles} that align dynamic robot behavior across two domains using a cycle-consistency constraint. Once this correspondence is found, we can directly transfer the policy trained on one domain to the other, without needing any additional fine-tuning on the second domain. We perform experiments across a variety of problem domains, both in simulation and on real robot. Our framework is able to align uncalibrated monocular video of a real robot arm to dynamic state-action trajectories of a simulated arm without paired data. Video demonstrations of our results are available at: https://sjtuzq.github.io/cycle_dynamics.html .
Contrastive Learning for Unpaired Image-to-Image Translation
Aug 20, 2020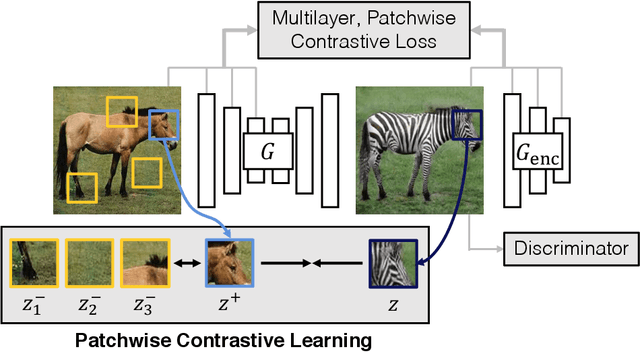
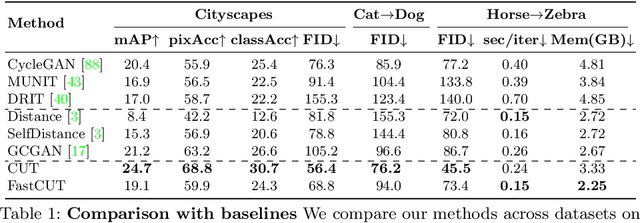
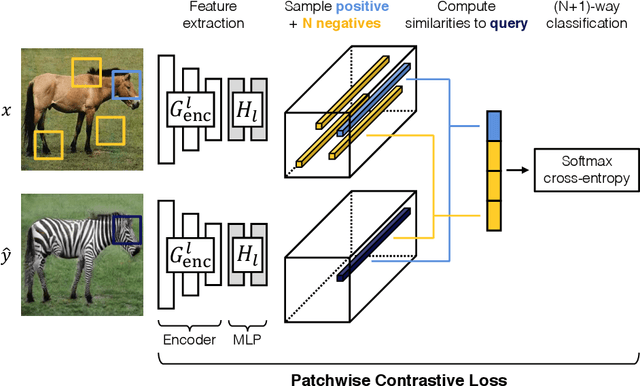
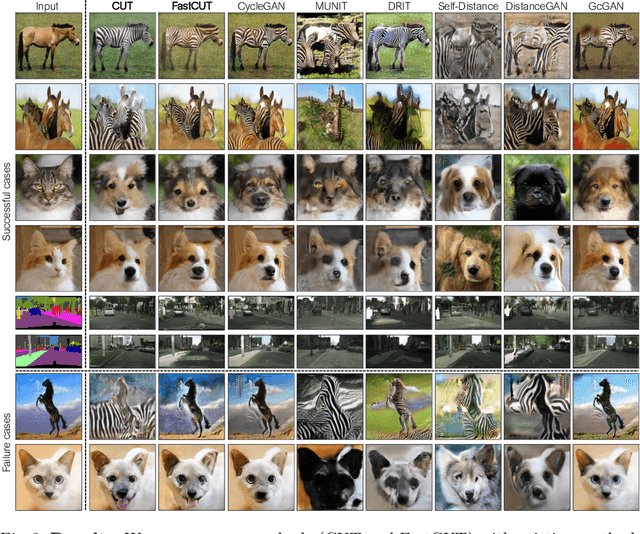
In image-to-image translation, each patch in the output should reflect the content of the corresponding patch in the input, independent of domain. We propose a straightforward method for doing so -- maximizing mutual information between the two, using a framework based on contrastive learning. The method encourages two elements (corresponding patches) to map to a similar point in a learned feature space, relative to other elements (other patches) in the dataset, referred to as negatives. We explore several critical design choices for making contrastive learning effective in the image synthesis setting. Notably, we use a multilayer, patch-based approach, rather than operate on entire images. Furthermore, we draw negatives from within the input image itself, rather than from the rest of the dataset. We demonstrate that our framework enables one-sided translation in the unpaired image-to-image translation setting, while improving quality and reducing training time. In addition, our method can even be extended to the training setting where each "domain" is only a single image.
What Should Not Be Contrastive in Contrastive Learning
Aug 13, 2020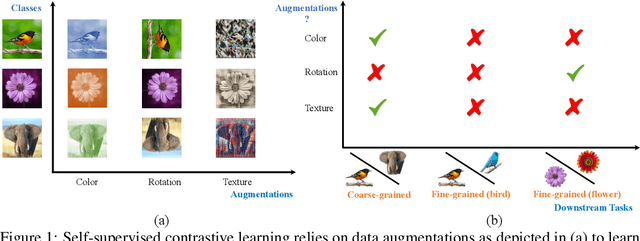
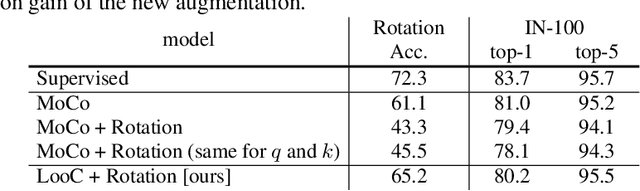
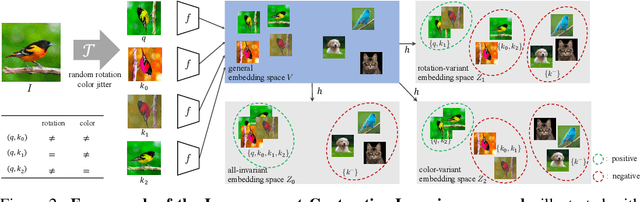
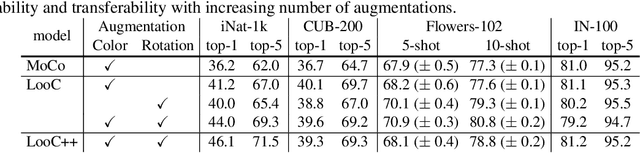
Recent self-supervised contrastive methods have been able to produce impressive transferable visual representations by learning to be invariant to different data augmentations. However, these methods implicitly assume a particular set of representational invariances (e.g., invariance to color), and can perform poorly when a downstream task violates this assumption (e.g., distinguishing red vs. yellow cars). We introduce a contrastive learning framework which does not require prior knowledge of specific, task-dependent invariances. Our model learns to capture varying and invariant factors for visual representations by constructing separate embedding spaces, each of which is invariant to all but one augmentation. We use a multi-head network with a shared backbone which captures information across each augmentation and alone outperforms all baselines on downstream tasks. We further find that the concatenation of the invariant and varying spaces performs best across all tasks we investigate, including coarse-grained, fine-grained, and few-shot downstream classification tasks, and various data corruptions.
Learning to Factorize and Relight a City
Aug 06, 2020
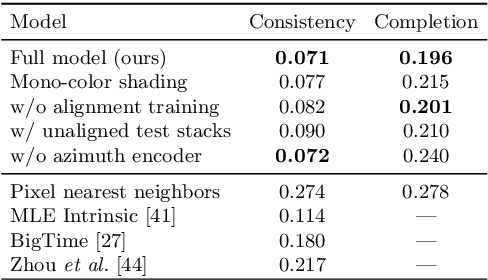


We propose a learning-based framework for disentangling outdoor scenes into temporally-varying illumination and permanent scene factors. Inspired by the classic intrinsic image decomposition, our learning signal builds upon two insights: 1) combining the disentangled factors should reconstruct the original image, and 2) the permanent factors should stay constant across multiple temporal samples of the same scene. To facilitate training, we assemble a city-scale dataset of outdoor timelapse imagery from Google Street View, where the same locations are captured repeatedly through time. This data represents an unprecedented scale of spatio-temporal outdoor imagery. We show that our learned disentangled factors can be used to manipulate novel images in realistic ways, such as changing lighting effects and scene geometry. Please visit factorize-a-city.github.io for animated results.