 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniFaceRig: Fully Automatic Inner-Mouth-Aware Face Rigging Across Diverse 3D Character Topologies
Jun 06, 2026Facial rigging - creating FACS-based blendshapes together with inner-mouth geometry (teeth, gums, and tongue) - remains a major bottleneck in 3D character production. Existing pipelines still require substantial designer effort, especially for manual landmark annotation, per-character template adjustment, and inner-mouth placement. We present OmniFaceRig, a fully automatic end-to-end pipeline that converts a static surface-only 3D character mesh, with no pre-modeled oral cavity, into an inner-mouth-aware FACS rig with up to 155 blendshapes, procedurally fitted teeth, gums, and tongue, and re-packed UV/texture. OmniFaceRig supports diverse topologies - humans, humanoids, long-muzzled animals (e.g., dogs, wolves, foxes), and short-muzzled animals (e.g., cats, bears, rabbits, tigers) - with no manual landmarks, no user-provided templates, and no per-asset setup. The pipeline combines hybrid VLM+CV riggability checking, multi-model face parsing, dense keypoint-driven template registration, procedural inner-mouth construction, and collision-aware blendshape transfer. For non-human characters, OmniFaceRig selects topology-specific face and inner-mouth templates and uses collision-aware inner-mouth fitting to reduce teeth-face intersections without exposing users to category-specific tuning. We also publicly release Omni-Bench, a freely available benchmark dataset of 1,000 biped 3D characters with FACS facial blendshapes and inner-mouth geometry, spanning humans, humanoids, cats, dogs, and other animals. Experiments show high final rigging success on screened Omni-Bench inputs, nearly complete face detection recall from the segmentation ensemble and reliable inner-mouth placement with low penetration. Together, OmniFaceRig provides an automatic path from static generated characters to animation-ready facial rigs across both human and non-human topologies.
GenLCA: 3D Diffusion for Full-Body Avatars from In-the-Wild Videos
Apr 09, 2026We present GenLCA, a diffusion-based generative model for generating and editing photorealistic full-body avatars from text and image inputs. The generated avatars are faithful to the inputs, while supporting high-fidelity facial and full-body animations. The core idea is a novel paradigm that enables training a full-body 3D diffusion model from partially observable 2D data, allowing the training dataset to scale to millions of real-world videos. This scalability contributes to the superior photorealism and generalizability of GenLCA. Specifically, we scale up the dataset by repurposing a pretrained feed-forward avatar reconstruction model as an animatable 3D tokenizer, which encodes unstructured video frames into structured 3D tokens. However, most real-world videos only provide partial observations of body parts, resulting in excessive blurring or transparency artifacts in the 3D tokens. To address this, we propose a novel visibility-aware diffusion training strategy that replaces invalid regions with learnable tokens and computes losses only over valid regions. We then train a flow-based diffusion model on the token dataset, inherently maintaining the photorealism and animatability provided by the pretrained avatar reconstruction model. Our approach effectively enables the use of large-scale real-world video data to train a diffusion model natively in 3D. We demonstrate the efficacy of our method through diverse and high-fidelity generation and editing results, outperforming existing solutions by a large margin. The project page is available at https://onethousandwu.com/GenLCA-Page.
Large-scale Codec Avatars: The Unreasonable Effectiveness of Large-scale Avatar Pretraining
Apr 02, 2026High-quality 3D avatar modeling faces a critical trade-off between fidelity and generalization. On the one hand, multi-view studio data enables high-fidelity modeling of humans with precise control over expressions and poses, but it struggles to generalize to real-world data due to limited scale and the domain gap between the studio environment and the real world. On the other hand, recent large-scale avatar models trained on millions of in-the-wild samples show promise for generalization across a wide range of identities, yet the resulting avatars are often of low-quality due to inherent 3D ambiguities. To address this, we present Large-Scale Codec Avatars (LCA), a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner, enabling efficient inference. Inspired by the success of large language models and vision foundation models, we present, for the first time, a pre/post-training paradigm for 3D avatar modeling at scale: we pretrain on 1M in-the-wild videos to learn broad priors over appearance and geometry, then post-train on high-quality curated data to enhance expressivity and fidelity. LCA generalizes across hair styles, clothing, and demographics while providing precise, fine-grained facial expressions and finger-level articulation control, with strong identity preservation. Notably, we observe emergent generalization to relightability and loose garment support to unconstrained inputs, and zero-shot robustness to stylized imagery, despite the absence of direct supervision.
DuoMo: Dual Motion Diffusion for World-Space Human Reconstruction
Mar 03, 2026We present DuoMo, a generative method that recovers human motion in world-space coordinates from unconstrained videos with noisy or incomplete observations. Reconstructing such motion requires solving a fundamental trade-off: generalizing from diverse and noisy video inputs while maintaining global motion consistency. Our approach addresses this problem by factorizing motion learning into two diffusion models. The camera-space model first estimates motion from videos in camera coordinates. The world-space model then lifts this initial estimate into world coordinates and refines it to be globally consistent. Together, the two models can reconstruct motion across diverse scenes and trajectories, even from highly noisy or incomplete observations. Moreover, our formulation is general, generating the motion of mesh vertices directly and bypassing parametric models. DuoMo achieves state-of-the-art performance. On EMDB, our method obtains a 16% reduction in world-space reconstruction error while maintaining low foot skating. On RICH, it obtains a 30% reduction in world-space error. Project page: https://yufu-wang.github.io/duomo/
Detection of Active Emergency Vehicles using Per-Frame CNNs and Output Smoothing
Dec 28, 2022



While inferring common actor states (such as position or velocity) is an important and well-explored task of the perception system aboard a self-driving vehicle (SDV), it may not always provide sufficient information to the SDV. This is especially true in the case of active emergency vehicles (EVs), where light-based signals also need to be captured to provide a full context. We consider this problem and propose a sequential methodology for the detection of active EVs, using an off-the-shelf CNN model operating at a frame level and a downstream smoother that accounts for the temporal aspect of flashing EV lights. We also explore model improvements through data augmentation and training with additional hard samples.
Convolutions for Spatial Interaction Modeling
Apr 15, 2021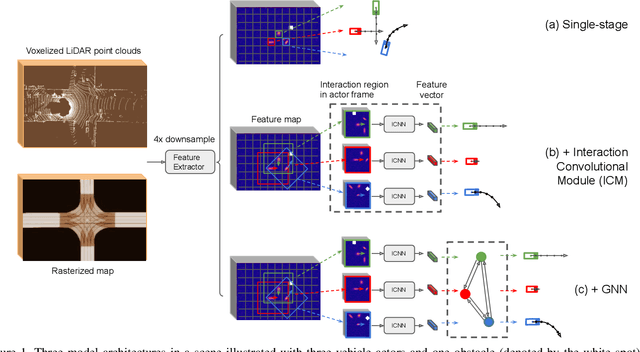

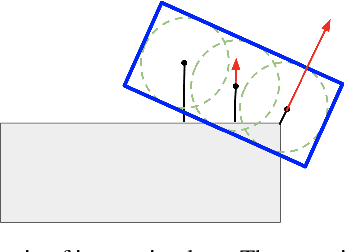
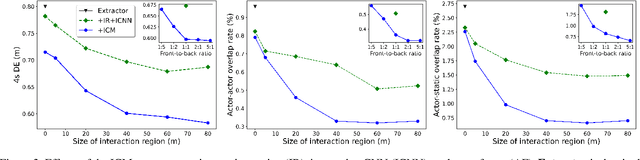
In many different fields interactions between objects play a critical role in determining their behavior. Graph neural networks (GNNs) have emerged as a powerful tool for modeling interactions, although often at the cost of adding considerable complexity and latency. In this paper, we consider the problem of spatial interaction modeling in the context of predicting the motion of actors around autonomous vehicles, and investigate alternative approaches to GNNs. We revisit convolutions and show that they can demonstrate comparable performance to graph networks in modeling spatial interactions with lower latency, thus providing an effective and efficient alternative in time-critical systems. Moreover, we propose a novel interaction loss to further improve the interaction modeling of the considered methods.
Temporally-Continuous Probabilistic Prediction using Polynomial Trajectory Parameterization
Nov 01, 2020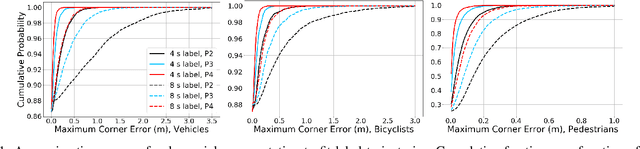
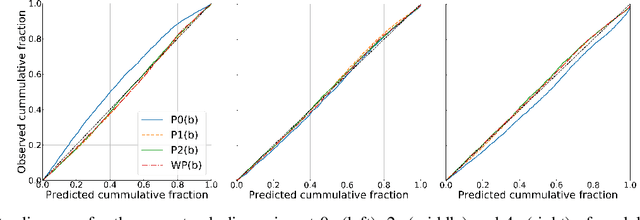
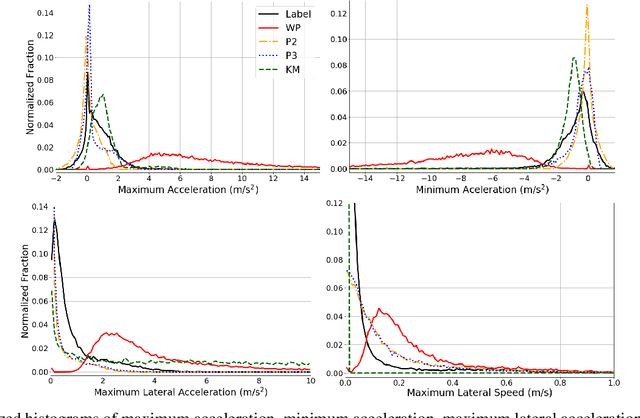
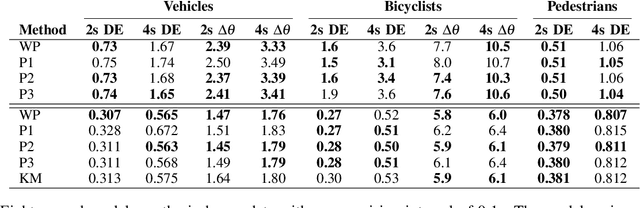
A commonly-used representation for motion prediction of actors is a sequence of waypoints (comprising positions and orientations) for each actor at discrete future time-points. While this approach is simple and flexible, it can exhibit unrealistic higher-order derivatives (such as acceleration) and approximation errors at intermediate time steps. To address this issue we propose a simple and general representation for temporally continuous probabilistic trajectory prediction that is based on polynomial trajectory parameterization. We evaluate the proposed representation on supervised trajectory prediction tasks using two large self-driving data sets. The results show realistic higher-order derivatives and better accuracy at interpolated time-points, as well as the benefits of the inferred noise distributions over the trajectories. Extensive experimental studies based on existing state-of-the-art models demonstrate the effectiveness of the proposed approach relative to other representations in predicting the future motions of vehicle, bicyclist, and pedestrian traffic actors.
MultiXNet: Multiclass Multistage Multimodal Motion Prediction
Jun 10, 2020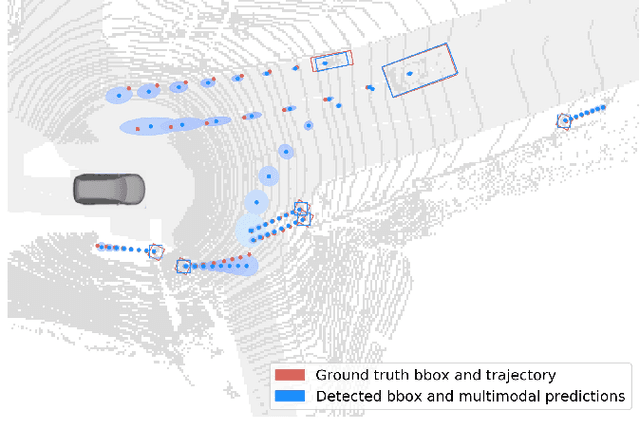
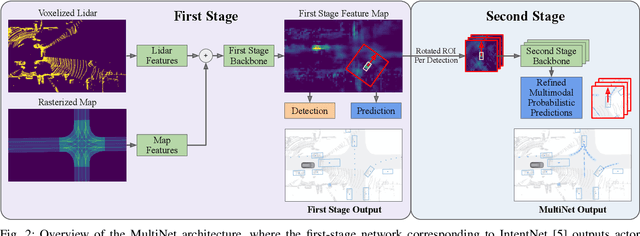
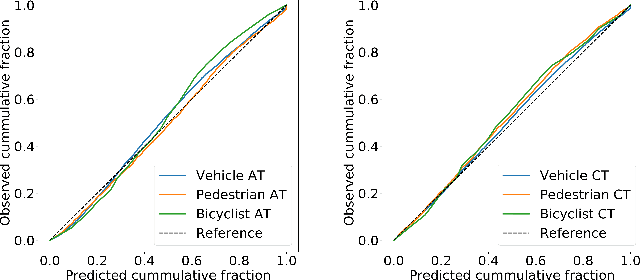
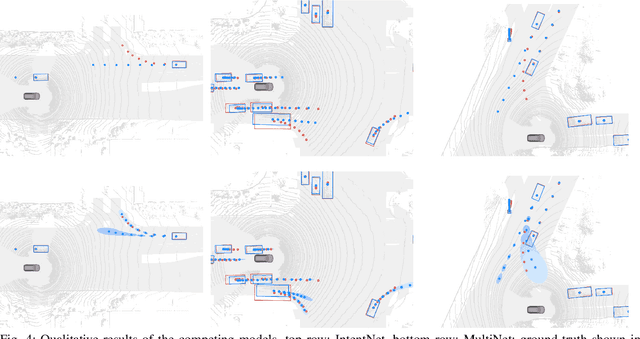
One of the critical pieces of the self-driving puzzle is understanding the surroundings of the self-driving vehicle (SDV) and predicting how these surroundings will change in the near future. To address this task we propose MultiXNet, an end-to-end approach for detection and motion prediction based directly on lidar sensor data. This approach builds on prior work by handling multiple classes of traffic actors, adding a jointly trained second-stage trajectory refinement step, and producing a multimodal probability distribution over future actor motion that includes both multiple discrete traffic behaviors and calibrated continuous uncertainties. The method was evaluated on a large-scale, real-world data set collected by a fleet of SDVs in several cities, with the results indicating that it outperforms existing state-of-the-art approaches.