 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic generation of reviews of scientific papers
Oct 08, 2020
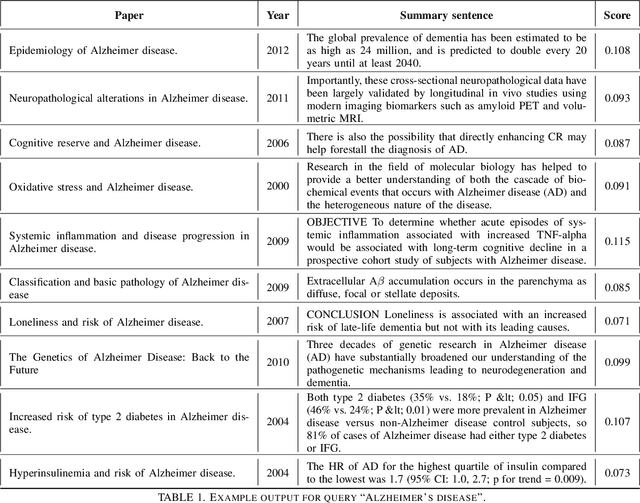

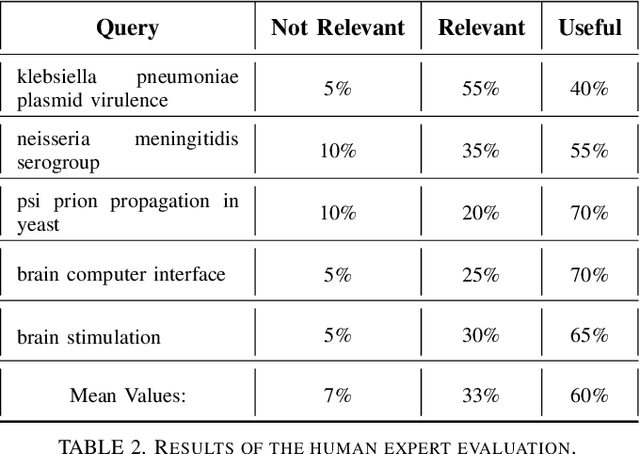
With an ever-increasing number of scientific papers published each year, it becomes more difficult for researchers to explore a field that they are not closely familiar with already. This greatly inhibits the potential for cross-disciplinary research. A traditional introduction into an area may come in the form of a review paper. However, not all areas and sub-areas have a current review. In this paper, we present a method for the automatic generation of a review paper corresponding to a user-defined query. This method consists of two main parts. The first part identifies key papers in the area by their bibliometric parameters, such as a graph of co-citations. The second stage uses a BERT based architecture that we train on existing reviews for extractive summarization of these key papers. We describe the general pipeline of our method and some implementation details and present both automatic and expert evaluations on the PubMed dataset.
Imitation Learning Approach for AI Driving Olympics Trained on Real-world and Simulation Data Simultaneously
Jul 07, 2020
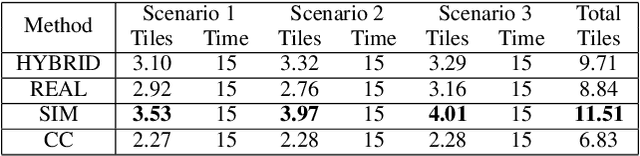


In this paper, we describe our winning approach to solving the Lane Following Challenge at the AI Driving Olympics Competition through imitation learning on a mixed set of simulation and real-world data. AI Driving Olympics is a two-stage competition: at stage one, algorithms compete in a simulated environment with the best ones advancing to a real-world final. One of the main problems that participants encounter during the competition is that algorithms trained for the best performance in simulated environments do not hold up in a real-world environment and vice versa. Classic control algorithms also do not translate well between tasks since most of them have to be tuned to specific driving conditions such as lighting, road type, camera position, etc. To overcome this problem, we employed the imitation learning algorithm and trained it on a dataset collected from sources both from simulation and real-world, forcing our model to perform equally well in all environments.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
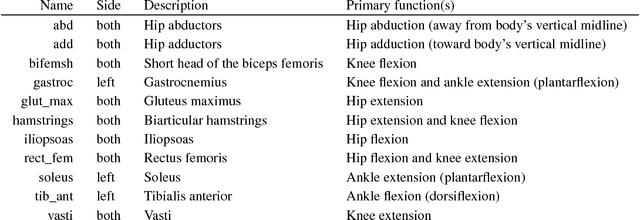
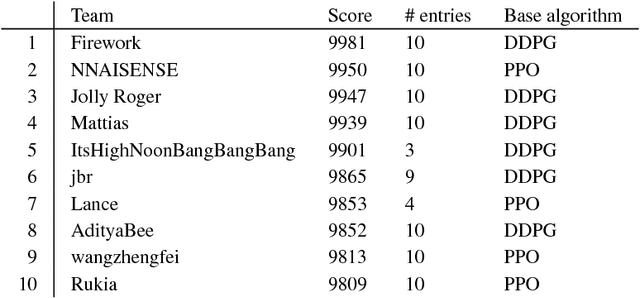

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Deep Multi-Agent Reinforcement Learning with Relevance Graphs
Nov 30, 2018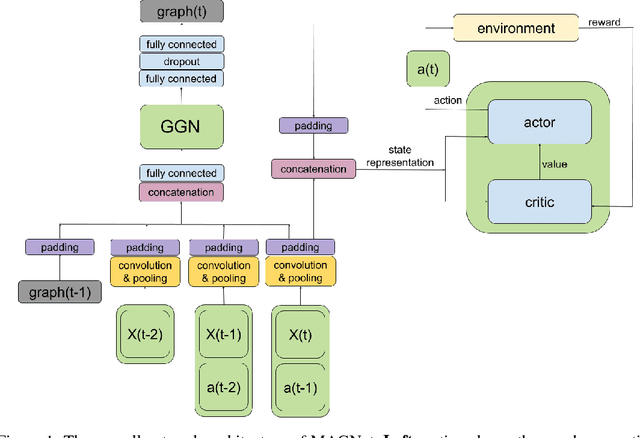
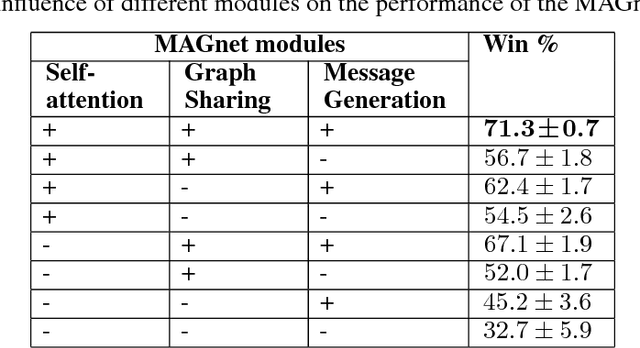
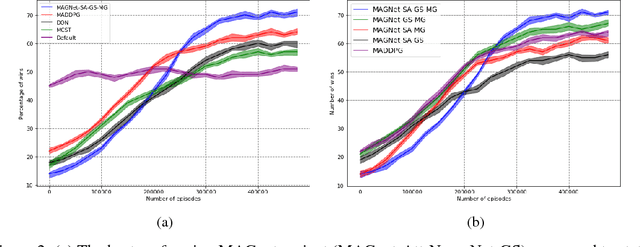
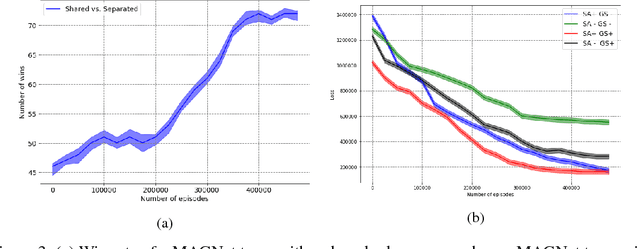
Over recent years, deep reinforcement learning has shown strong successes in complex single-agent tasks, and more recently this approach has also been applied to multi-agent domains. In this paper, we propose a novel approach, called MAGnet, to multi-agent reinforcement learning (MARL) that utilizes a relevance graph representation of the environment obtained by a self-attention mechanism, and a message-generation technique inspired by the NerveNet architecture. We applied our MAGnet approach to the Pommerman game and the results show that it significantly outperforms state-of-the-art MARL solutions, including DQN, MADDPG, and MCTS.