 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterior Coreset Construction with Kernelized Stein Discrepancy for Model-Based Reinforcement Learning
Jun 02, 2022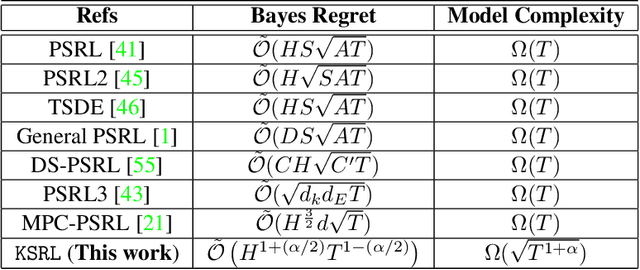
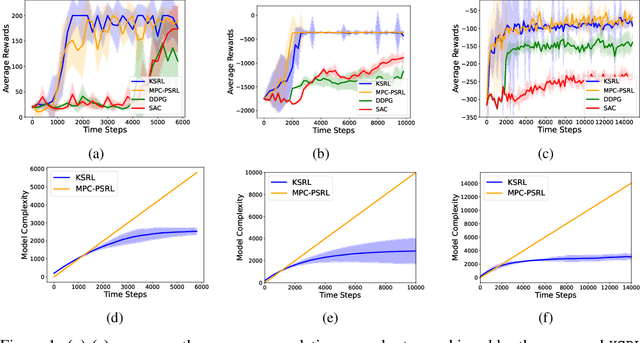
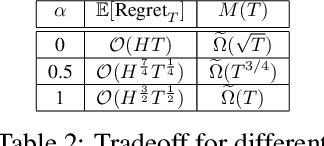
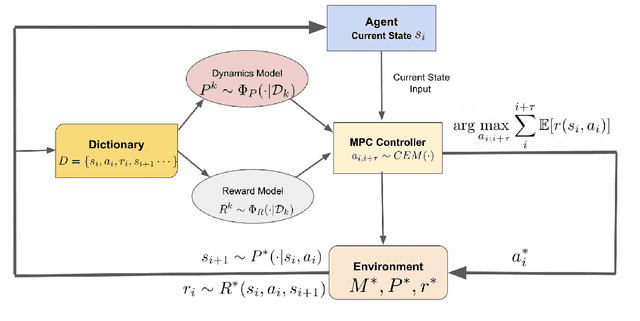
In this work, we propose a novel ${\bf K}$ernelized ${\bf S}$tein Discrepancy-based Posterior Sampling for ${\bf RL}$ algorithm (named $\texttt{KSRL}$) which extends model-based RL based upon posterior sampling (PSRL) in several ways: we (i) relax the need for any smoothness or Gaussian assumptions, allowing for complex mixture models; (ii) ensure it is applicable to large-scale training by incorporating a compression step such that the posterior consists of a \emph{Bayesian coreset} of only statistically significant past state-action pairs; and (iii) develop a novel regret analysis of PSRL based upon integral probability metrics, which, under a smoothness condition on the constructed posterior, can be evaluated in closed form as the kernelized Stein discrepancy (KSD). Consequently, we are able to improve the $\mathcal{O}(H^{3/2}d\sqrt{T})$ {regret} of PSRL to $\mathcal{O}(H^{3/2}\sqrt{T})$, where $d$ is the input dimension, $H$ is the episode length, and $T$ is the total number of episodes experienced, alleviating a linear dependence on $d$ . Moreover, we theoretically establish a trade-off between regret rate with posterior representational complexity via introducing a compression budget parameter $\epsilon$ based on KSD, and establish a lower bound on the required complexity for consistency of the model. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, with substantive improvements in computation time. Experimentally, we observe that this approach is competitive with several state of the art RL methodologies, and can achieve up-to $50\%$ reduction in wall clock time in some continuous control environments.
Distributed Riemannian Optimization with Lazy Communication for Collaborative Geometric Estimation
Mar 02, 2022
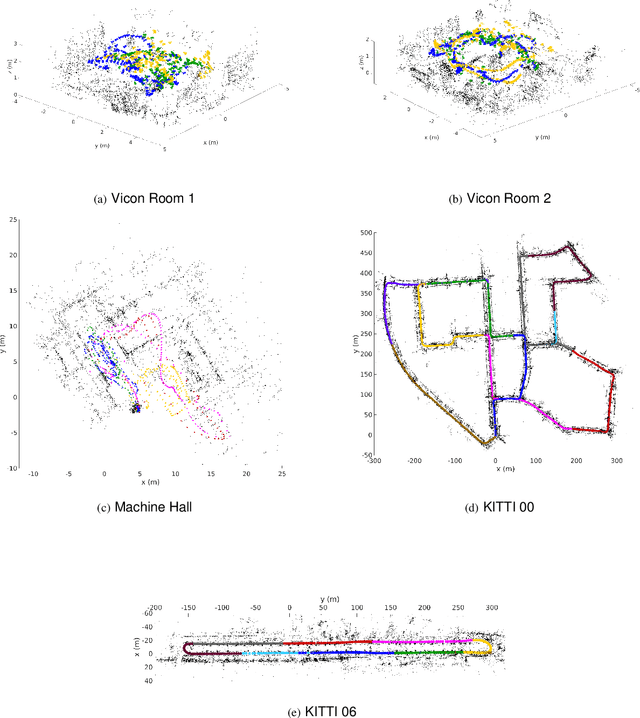


We present the first distributed optimization algorithm with lazy communication for collaborative geometric estimation, the backbone of modern collaborative simultaneous localization and mapping (SLAM) and structure-from-motion (SfM) applications. Our method allows agents to cooperatively reconstruct a shared geometric model on a central server by fusing individual observations, but without the need to transmit potentially sensitive information about the agents themselves (such as their locations). Furthermore, to alleviate the burden of communication during iterative optimization, we design a set of communication triggering conditions that enable agents to selectively upload local information that are useful to global optimization. Our approach thus achieves significant communication reduction with minimal impact on optimization performance. As our main theoretical contribution, we prove that our method converges to first-order critical points with a sublinear convergence rate. Numerical evaluations on bundle adjustment problems from collaborative SLAM and SfM datasets show that our method performs competitively against existing distributed techniques, while achieving up to 78% total communication reduction.
On the Hidden Biases of Policy Mirror Ascent in Continuous Action Spaces
Jan 31, 2022
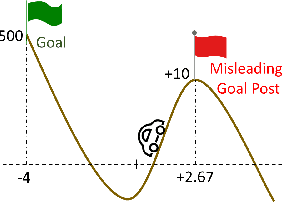

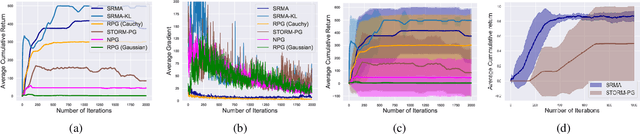
We focus on parameterized policy search for reinforcement learning over continuous action spaces. Typically, one assumes the score function associated with a policy is bounded, which fails to hold even for Gaussian policies. To properly address this issue, one must introduce an exploration tolerance parameter to quantify the region in which it is bounded. Doing so incurs a persistent bias that appears in the attenuation rate of the expected policy gradient norm, which is inversely proportional to the radius of the action space. To mitigate this hidden bias, heavy-tailed policy parameterizations may be used, which exhibit a bounded score function, but doing so can cause instability in algorithmic updates. To address these issues, in this work, we study the convergence of policy gradient algorithms under heavy-tailed parameterizations, which we propose to stabilize with a combination of mirror ascent-type updates and gradient tracking. Our main theoretical contribution is the establishment that this scheme converges with constant step and batch sizes, whereas prior works require these parameters to respectively shrink to null or grow to infinity. Experimentally, this scheme under a heavy-tailed policy parameterization yields improved reward accumulation across a variety of settings as compared with standard benchmarks.
Occupancy Information Ratio: Infinite-Horizon, Information-Directed, Parameterized Policy Search
Jan 21, 2022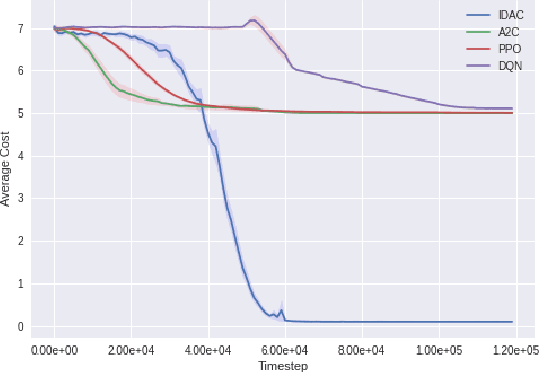
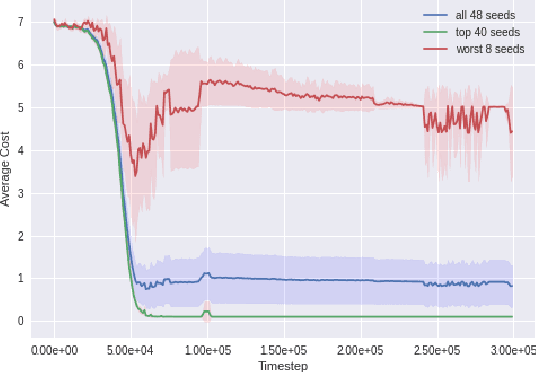
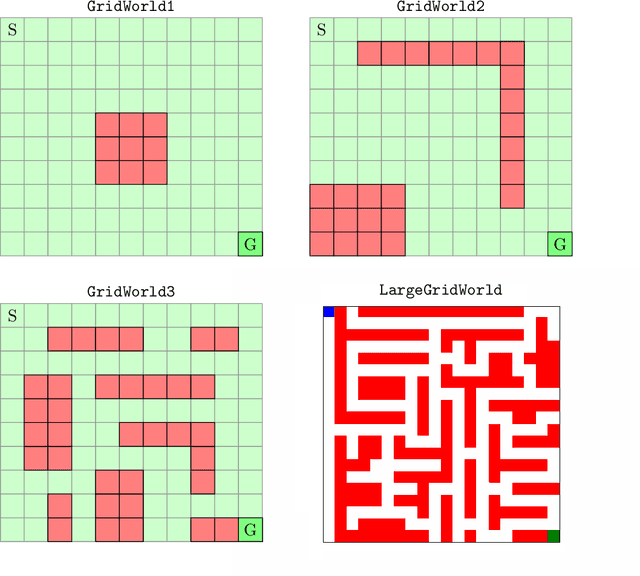
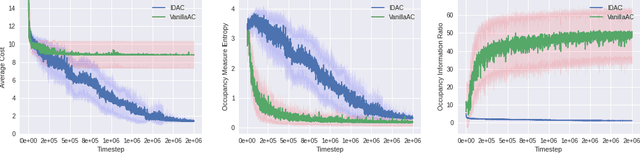
We develop a new measure of the exploration/exploitation trade-off in infinite-horizon reinforcement learning problems called the occupancy information ratio (OIR), which is comprised of a ratio between the infinite-horizon average cost of a policy and the entropy of its long-term state occupancy measure. The OIR ensures that no matter how many trajectories an RL agent traverses or how well it learns to minimize cost, it maintains a healthy skepticism about its environment, in that it defines an optimal policy which induces a high-entropy occupancy measure. Different from earlier information ratio notions, OIR is amenable to direct policy search over parameterized families, and exhibits hidden quasiconcavity through invocation of the perspective transformation. This feature ensures that under appropriate policy parameterizations, the OIR optimization problem has no spurious stationary points, despite the overall problem's nonconvexity. We develop for the first time policy gradient and actor-critic algorithms for OIR optimization based upon a new entropy gradient theorem, and establish both asymptotic and non-asymptotic convergence results with global optimality guarantees. In experiments, these methodologies outperform several deep RL baselines in problems with sparse rewards, where many trajectories may be uninformative and skepticism about the environment is crucial to success.
Online, Informative MCMC Thinning with Kernelized Stein Discrepancy
Jan 18, 2022

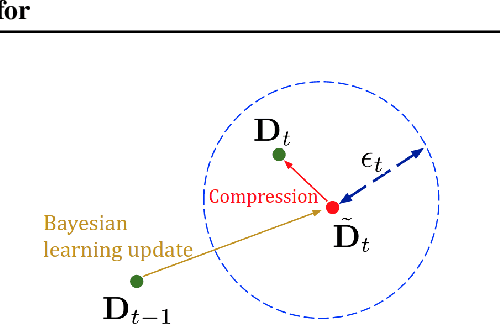

A fundamental challenge in Bayesian inference is efficient representation of a target distribution. Many non-parametric approaches do so by sampling a large number of points using variants of Markov Chain Monte Carlo (MCMC). We propose an MCMC variant that retains only those posterior samples which exceed a KSD threshold, which we call KSD Thinning. We establish the convergence and complexity tradeoffs for several settings of KSD Thinning as a function of the KSD threshold parameter, sample size, and other problem parameters. Finally, we provide experimental comparisons against other online nonparametric Bayesian methods that generate low-complexity posterior representations, and observe superior consistency/complexity tradeoffs. Code is available at github.com/colehawkins/KSD-Thinning.
Convergence Rates of Average-Reward Multi-agent Reinforcement Learning via Randomized Linear Programming
Oct 22, 2021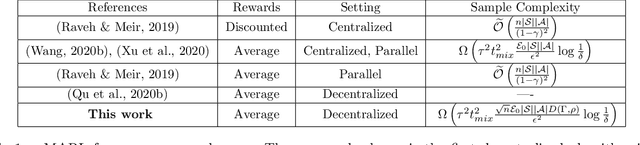
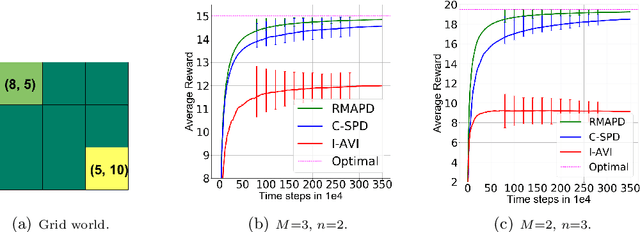
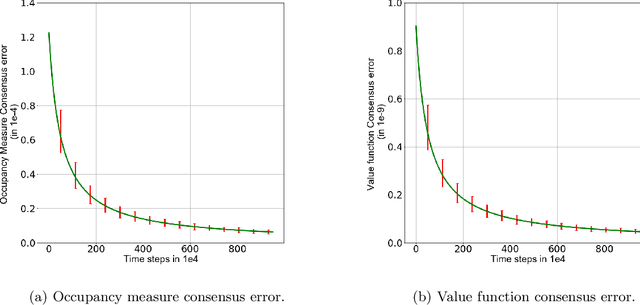
In tabular multi-agent reinforcement learning with average-cost criterion, a team of agents sequentially interacts with the environment and observes local incentives. We focus on the case that the global reward is a sum of local rewards, the joint policy factorizes into agents' marginals, and full state observability. To date, few global optimality guarantees exist even for this simple setting, as most results yield convergence to stationarity for parameterized policies in large/possibly continuous spaces. To solidify the foundations of MARL, we build upon linear programming (LP) reformulations, for which stochastic primal-dual methods yields a model-free approach to achieve \emph{optimal sample complexity} in the centralized case. We develop multi-agent extensions, whereby agents solve their local saddle point problems and then perform local weighted averaging. We establish that the sample complexity to obtain near-globally optimal solutions matches tight dependencies on the cardinality of the state and action spaces, and exhibits classical scalings with respect to the network in accordance with multi-agent optimization. Experiments corroborate these results in practice.
Distributed Gaussian Process Mapping for Robot Teams with Time-varying Communication
Oct 12, 2021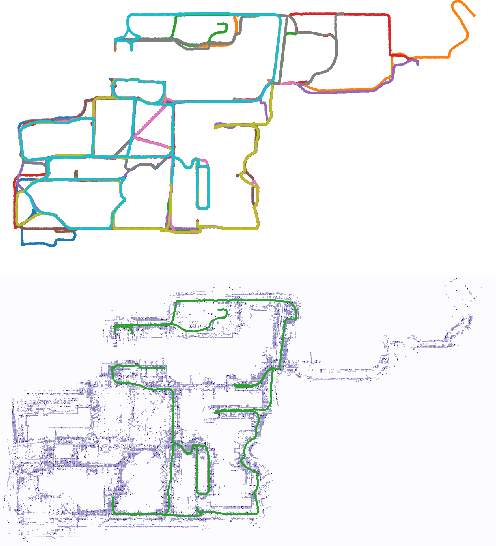
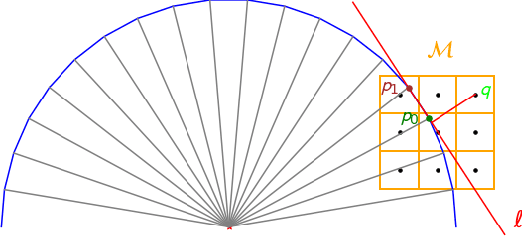
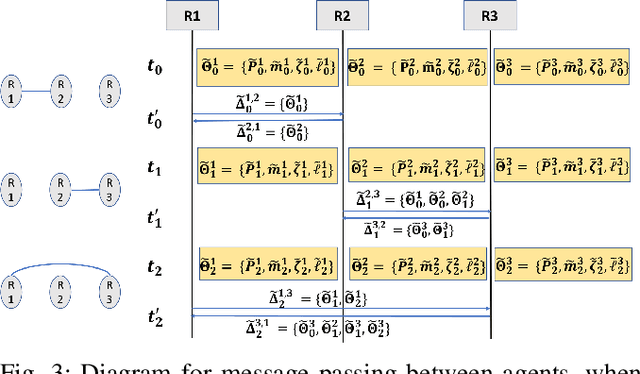
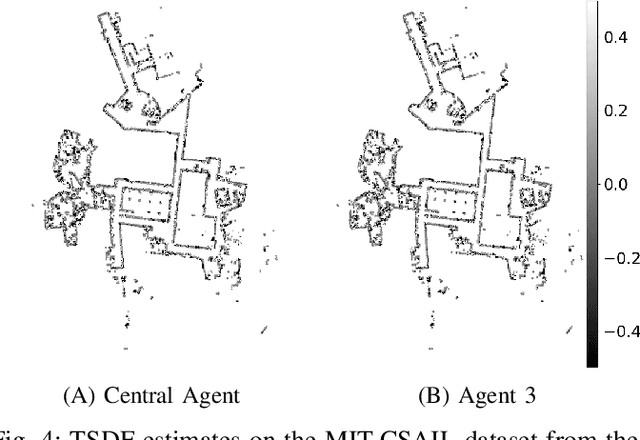
Multi-agent mapping is a fundamentally important capability for autonomous robot task coordination and execution in complex environments. While successful algorithms have been proposed for mapping using individual platforms, cooperative online mapping for teams of robots remains largely a challenge. We focus on probabilistic variants of mapping due to its potential utility in downstream tasks such as uncertainty-aware path-planning. A critical question to enabling this capability is how to process and aggregate incrementally observed local information among individual platforms, especially when their ability to communicate is intermittent. We put forth an Incremental Sparse Gaussian Process (GP) methodology for multi-robot mapping, where the regression is over a truncated signed-distance field (TSDF). Doing so permits each robot in the network to track a local estimate of a pseudo-point approximation GP posterior and perform weighted averaging of its parameters with those of its (possibly time-varying) set of neighbors. We establish conditions on the pseudo-point representation, as well as communication protocol, such that robots' local GPs converge to the one with globally aggregated information. We further provide experiments that corroborate our theoretical findings for probabilistic multi-robot mapping.
Achieving Zero Constraint Violation for Constrained Reinforcement Learning via Primal-Dual Approach
Sep 13, 2021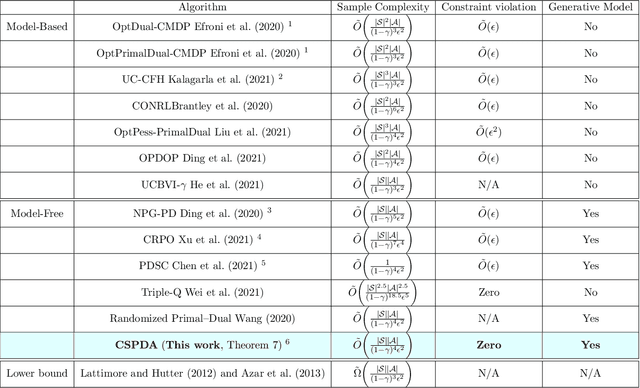
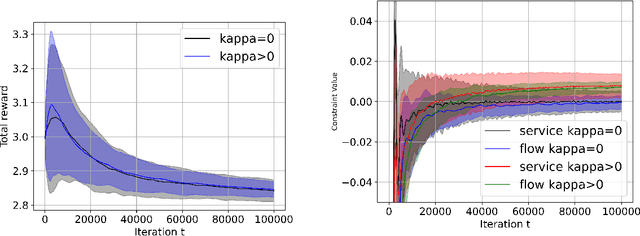
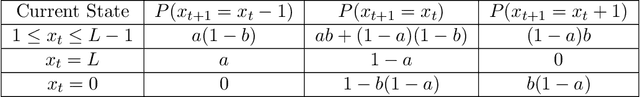
Reinforcement learning is widely used in applications where one needs to perform sequential decisions while interacting with the environment. The problem becomes more challenging when the decision requirement includes satisfying some safety constraints. The problem is mathematically formulated as constrained Markov decision process (CMDP). In the literature, various algorithms are available to solve CMDP problems in a model-free manner to achieve $\epsilon$-optimal cumulative reward with $\epsilon$ feasible policies. An $\epsilon$-feasible policy implies that it suffers from constraint violation. An important question here is whether we can achieve $\epsilon$-optimal cumulative reward with zero constraint violations or not. To achieve that, we advocate the use of a randomized primal-dual approach to solving the CMDP problems and propose a conservative stochastic primal-dual algorithm (CSPDA) which is shown to exhibit $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity to achieve $\epsilon$-optimal cumulative reward with zero constraint violations. In the prior works, the best available sample complexity for the $\epsilon$-optimal policy with zero constraint violation is $\tilde{\mathcal{O}}(1/\epsilon^5)$. Hence, the proposed algorithm provides a significant improvement as compared to the state of the art.
Wasserstein-Splitting Gaussian Process Regression for Heterogeneous Online Bayesian Inference
Jul 26, 2021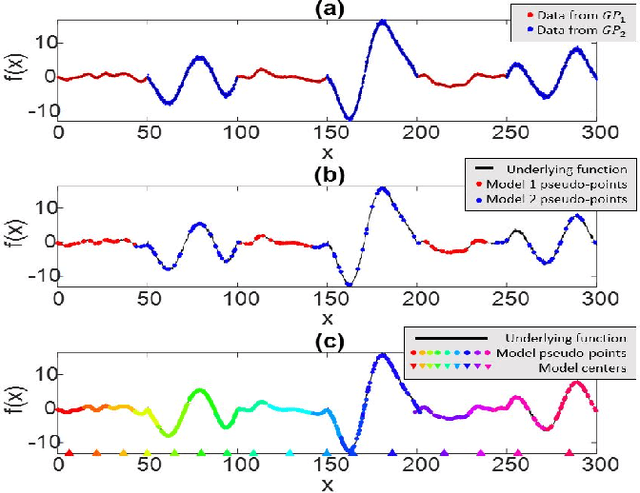
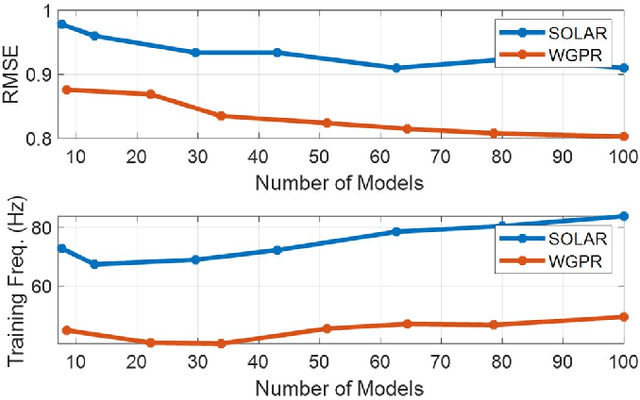
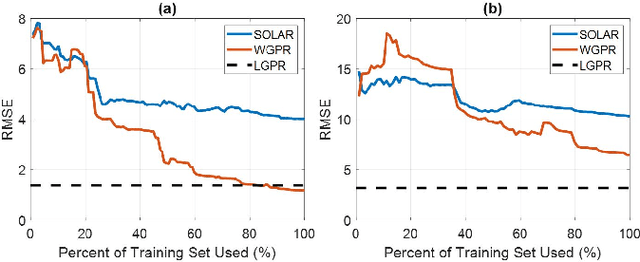

Gaussian processes (GPs) are a well-known nonparametric Bayesian inference technique, but they suffer from scalability problems for large sample sizes, and their performance can degrade for non-stationary or spatially heterogeneous data. In this work, we seek to overcome these issues through (i) employing variational free energy approximations of GPs operating in tandem with online expectation propagation steps; and (ii) introducing a local splitting step which instantiates a new GP whenever the posterior distribution changes significantly as quantified by the Wasserstein metric over posterior distributions. Over time, then, this yields an ensemble of sparse GPs which may be updated incrementally, and adapts to locality, heterogeneity, and non-stationarity in training data.
On the Sample Complexity and Metastability of Heavy-tailed Policy Search in Continuous Control
Jun 15, 2021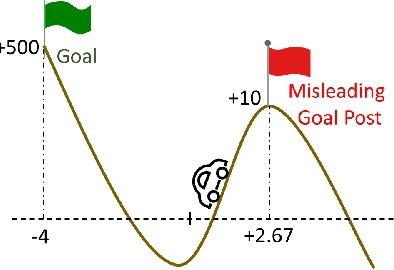

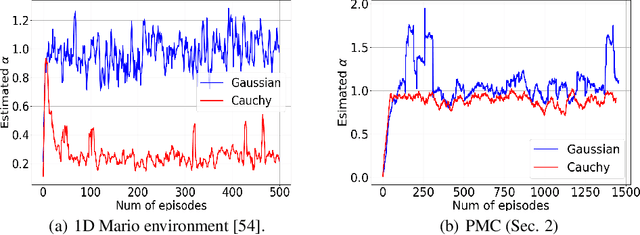
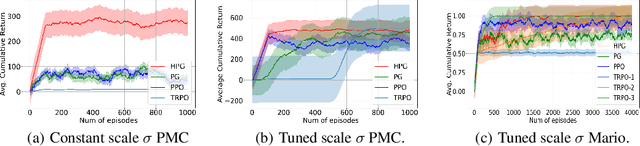
Reinforcement learning is a framework for interactive decision-making with incentives sequentially revealed across time without a system dynamics model. Due to its scaling to continuous spaces, we focus on policy search where one iteratively improves a parameterized policy with stochastic policy gradient (PG) updates. In tabular Markov Decision Problems (MDPs), under persistent exploration and suitable parameterization, global optimality may be obtained. By contrast, in continuous space, the non-convexity poses a pathological challenge as evidenced by existing convergence results being mostly limited to stationarity or arbitrary local extrema. To close this gap, we step towards persistent exploration in continuous space through policy parameterizations defined by distributions of heavier tails defined by tail-index parameter alpha, which increases the likelihood of jumping in state space. Doing so invalidates smoothness conditions of the score function common to PG. Thus, we establish how the convergence rate to stationarity depends on the policy's tail index alpha, a Holder continuity parameter, integrability conditions, and an exploration tolerance parameter introduced here for the first time. Further, we characterize the dependence of the set of local maxima on the tail index through an exit and transition time analysis of a suitably defined Markov chain, identifying that policies associated with Levy Processes of a heavier tail converge to wider peaks. This phenomenon yields improved stability to perturbations in supervised learning, which we corroborate also manifests in improved performance of policy search, especially when myopic and farsighted incentives are misaligned.