 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Convergence for Average Reward Constrained MDPs with Primal-Dual Actor Critic Algorithm
May 21, 2025This paper investigates infinite-horizon average reward Constrained Markov Decision Processes (CMDPs) with general parametrization. We propose a Primal-Dual Natural Actor-Critic algorithm that adeptly manages constraints while ensuring a high convergence rate. In particular, our algorithm achieves global convergence and constraint violation rates of $\tilde{\mathcal{O}}(1/\sqrt{T})$ over a horizon of length $T$ when the mixing time, $\tau_{\mathrm{mix}}$, is known to the learner. In absence of knowledge of $\tau_{\mathrm{mix}}$, the achievable rates change to $\tilde{\mathcal{O}}(1/T^{0.5-\epsilon})$ provided that $T \geq \tilde{\mathcal{O}}\left(\tau_{\mathrm{mix}}^{2/\epsilon}\right)$. Our results match the theoretical lower bound for Markov Decision Processes and establish a new benchmark in the theoretical exploration of average reward CMDPs.
Learning General Parameterized Policies for Infinite Horizon Average Reward Constrained MDPs via Primal-Dual Policy Gradient Algorithm
Feb 03, 2024This paper explores the realm of infinite horizon average reward Constrained Markov Decision Processes (CMDP). To the best of our knowledge, this work is the first to delve into the regret and constraint violation analysis of average reward CMDPs with a general policy parametrization. To address this challenge, we propose a primal dual based policy gradient algorithm that adeptly manages the constraints while ensuring a low regret guarantee toward achieving a global optimal policy. In particular, we demonstrate that our proposed algorithm achieves $\tilde{\mathcal{O}}({T}^{3/4})$ objective regret and $\tilde{\mathcal{O}}({T}^{3/4})$ constraint violation bounds.
Regret Analysis of Policy Gradient Algorithm for Infinite Horizon Average Reward Markov Decision Processes
Sep 05, 2023In this paper, we consider an infinite horizon average reward Markov Decision Process (MDP). Distinguishing itself from existing works within this context, our approach harnesses the power of the general policy gradient-based algorithm, liberating it from the constraints of assuming a linear MDP structure. We propose a policy gradient-based algorithm and show its global convergence property. We then prove that the proposed algorithm has $\tilde{\mathcal{O}}({T}^{3/4})$ regret. Remarkably, this paper marks a pioneering effort by presenting the first exploration into regret-bound computation for the general parameterized policy gradient algorithm in the context of average reward scenarios.
Achieving Zero Constraint Violation for Constrained Reinforcement Learning via Conservative Natural Policy Gradient Primal-Dual Algorithm
Jun 12, 2022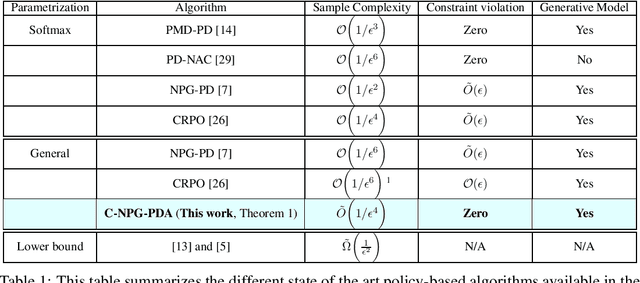
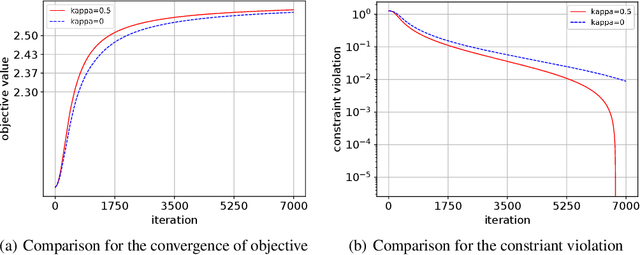
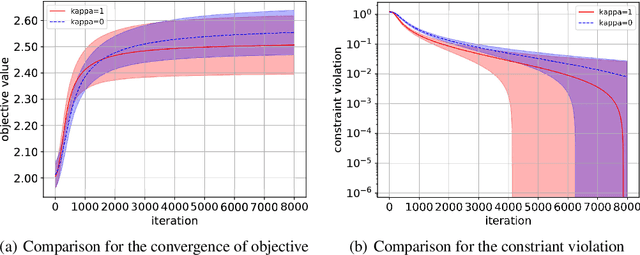
We consider the problem of constrained Markov decision process (CMDP) in continuous state-actions spaces where the goal is to maximize the expected cumulative reward subject to some constraints. We propose a novel Conservative Natural Policy Gradient Primal-Dual Algorithm (C-NPG-PD) to achieve zero constraint violation while achieving state of the art convergence results for the objective value function. For general policy parametrization, we prove convergence of value function to global optimal upto an approximation error due to restricted policy class. We even improve the sample complexity of existing constrained NPG-PD algorithm \cite{Ding2020} from $\mathcal{O}(1/\epsilon^6)$ to $\mathcal{O}(1/\epsilon^4)$. To the best of our knowledge, this is the first work to establish zero constraint violation with Natural policy gradient style algorithms for infinite horizon discounted CMDPs. We demonstrate the merits of proposed algorithm via experimental evaluations.
Achieving Zero Constraint Violation for Constrained Reinforcement Learning via Primal-Dual Approach
Sep 13, 2021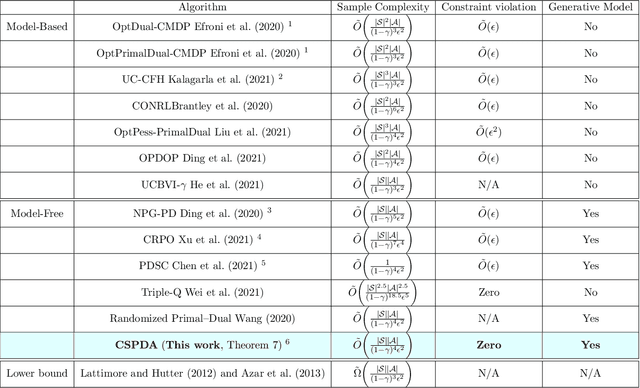
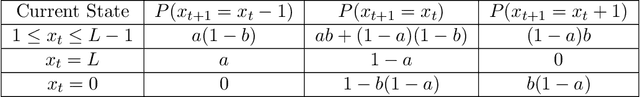
Reinforcement learning is widely used in applications where one needs to perform sequential decisions while interacting with the environment. The problem becomes more challenging when the decision requirement includes satisfying some safety constraints. The problem is mathematically formulated as constrained Markov decision process (CMDP). In the literature, various algorithms are available to solve CMDP problems in a model-free manner to achieve $\epsilon$-optimal cumulative reward with $\epsilon$ feasible policies. An $\epsilon$-feasible policy implies that it suffers from constraint violation. An important question here is whether we can achieve $\epsilon$-optimal cumulative reward with zero constraint violations or not. To achieve that, we advocate the use of a randomized primal-dual approach to solving the CMDP problems and propose a conservative stochastic primal-dual algorithm (CSPDA) which is shown to exhibit $\tilde{\mathcal{O}}(1/\epsilon^2)$ sample complexity to achieve $\epsilon$-optimal cumulative reward with zero constraint violations. In the prior works, the best available sample complexity for the $\epsilon$-optimal policy with zero constraint violation is $\tilde{\mathcal{O}}(1/\epsilon^5)$. Hence, the proposed algorithm provides a significant improvement as compared to the state of the art.
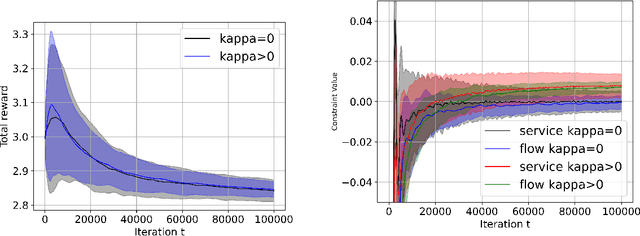
Concave Utility Reinforcement Learning with Zero-Constraint Violations
Sep 12, 2021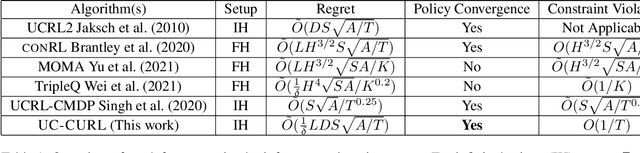
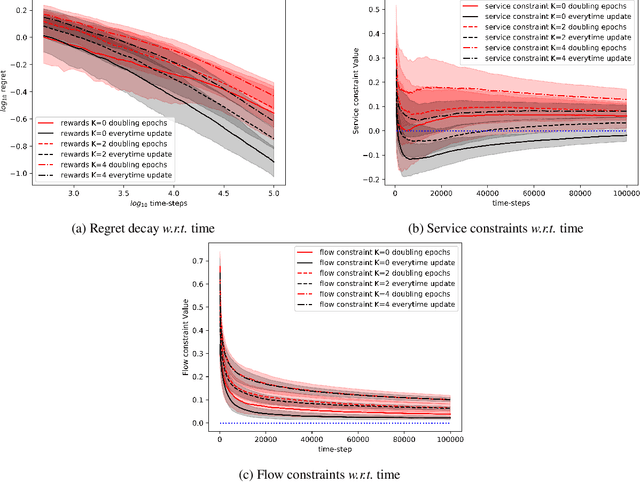
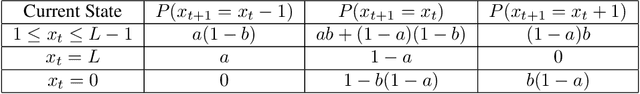
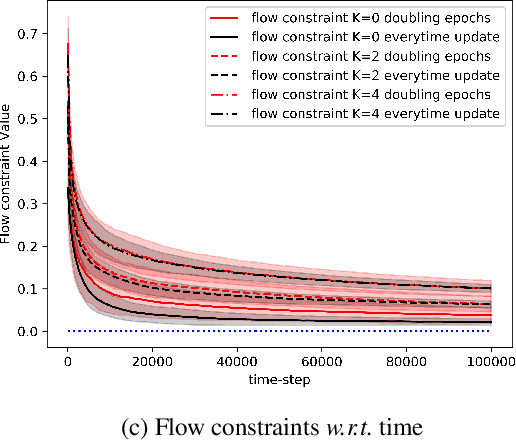
We consider the problem of tabular infinite horizon concave utility reinforcement learning (CURL) with convex constraints. Various learning applications with constraints, such as robotics, do not allow for policies that can violate constraints. To this end, we propose a model-based learning algorithm that achieves zero constraint violations. To obtain this result, we assume that the concave objective and the convex constraints have a solution interior to the set of feasible occupation measures. We then solve a tighter optimization problem to ensure that the constraints are never violated despite the imprecise model knowledge and model stochasticity. We also propose a novel Bellman error based analysis for tabular infinite-horizon setups which allows to analyse stochastic policies. Combining the Bellman error based analysis and tighter optimization equation, for $T$ interactions with the environment, we obtain a regret guarantee for objective which grows as $\Tilde{O}(1/\sqrt{T})$, excluding other factors.
Markov Decision Processes with Long-Term Average Constraints
Jun 12, 2021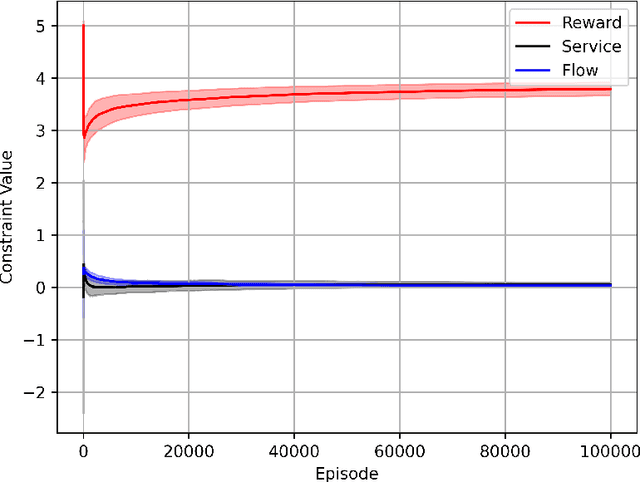

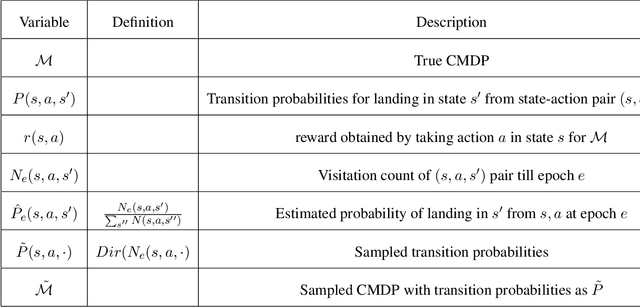
We consider the problem of constrained Markov Decision Process (CMDP) where an agent interacts with a unichain Markov Decision Process. At every interaction, the agent obtains a reward. Further, there are $K$ cost functions. The agent aims to maximize the long-term average reward while simultaneously keeping the $K$ long-term average costs lower than a certain threshold. In this paper, we propose CMDP-PSRL, a posterior sampling based algorithm using which the agent can learn optimal policies to interact with the CMDP. Further, for MDP with $S$ states, $A$ actions, and diameter $D$, we prove that following CMDP-PSRL algorithm, the agent can bound the regret of not accumulating rewards from optimal policy by $\Tilde{O}(poly(DSA)\sqrt{T})$. Further, we show that the violations for any of the $K$ constraints is also bounded by $\Tilde{O}(poly(DSA)\sqrt{T})$. To the best of our knowledge, this is the first work which obtains a $\Tilde{O}(\sqrt{T})$ regret bounds for ergodic MDPs with long-term average constraints.
Joint Optimization of Multi-Objective Reinforcement Learning with Policy Gradient Based Algorithm
May 28, 2021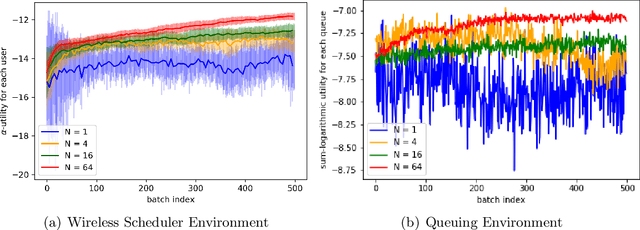
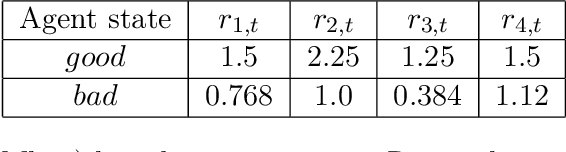
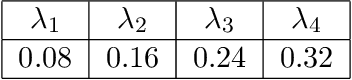
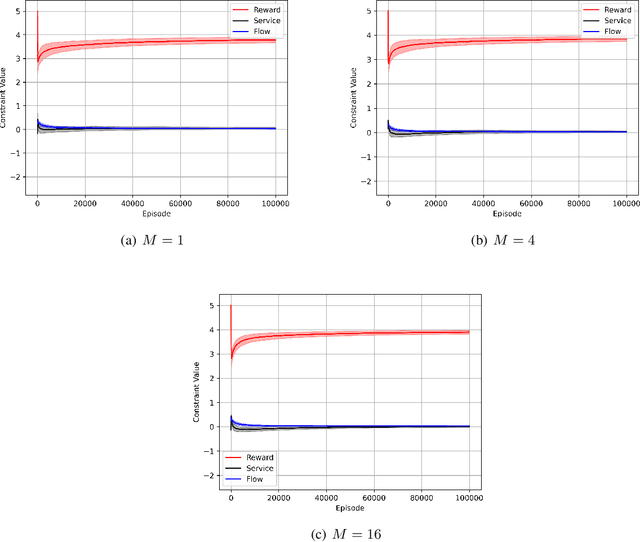
Many engineering problems have multiple objectives, and the overall aim is to optimize a non-linear function of these objectives. In this paper, we formulate the problem of maximizing a non-linear concave function of multiple long-term objectives. A policy-gradient based model-free algorithm is proposed for the problem. To compute an estimate of the gradient, a biased estimator is proposed. The proposed algorithm is shown to achieve convergence to within an $\epsilon$ of the global optima after sampling $\mathcal{O}(\frac{M^4\sigma^2}{(1-\gamma)^8\epsilon^4})$ trajectories where $\gamma$ is the discount factor and $M$ is the number of the agents, thus achieving the same dependence on $\epsilon$ as the policy gradient algorithm for the standard reinforcement learning.
Model-Free Algorithm and Regret Analysis for MDPs with Long-Term Constraints
Jun 10, 2020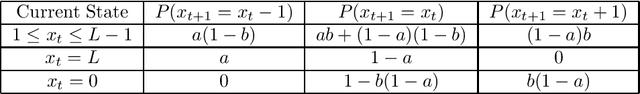
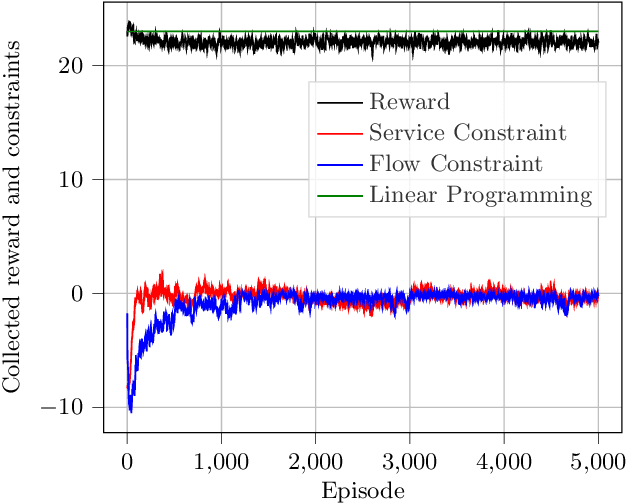
In the optimization of dynamical systems, the variables typically have constraints. Such problems can be modeled as a constrained Markov Decision Process (CMDP). This paper considers a model-free approach to the problem, where the transition probabilities are not known. In the presence of long-term (or average) constraints, the agent has to choose a policy that maximizes the long-term average reward as well as satisfy the average constraints in each episode. The key challenge with the long-term constraints is that the optimal policy is not deterministic in general, and thus standard Q-learning approaches cannot be directly used. This paper uses concepts from constrained optimization and Q-learning to propose an algorithm for CMDP with long-term constraints. For any $\gamma\in(0,\frac{1}{2})$, the proposed algorithm is shown to achieve $O(T^{1/2+\gamma})$ regret bound for the obtained reward and $O(T^{1-\gamma/2})$ regret bound for the constraint violation, where $T$ is the total number of steps. We note that these are the first results on regret analysis for MDP with long-term constraints, where the transition probabilities are not known apriori.
Model-Free Algorithm and Regret Analysis for MDPs with Peak Constraints
Mar 11, 2020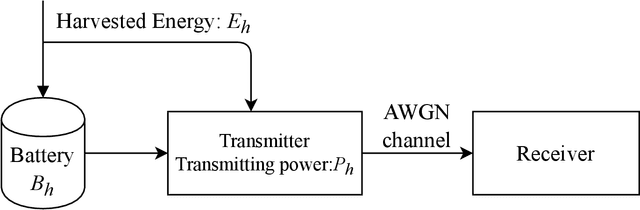
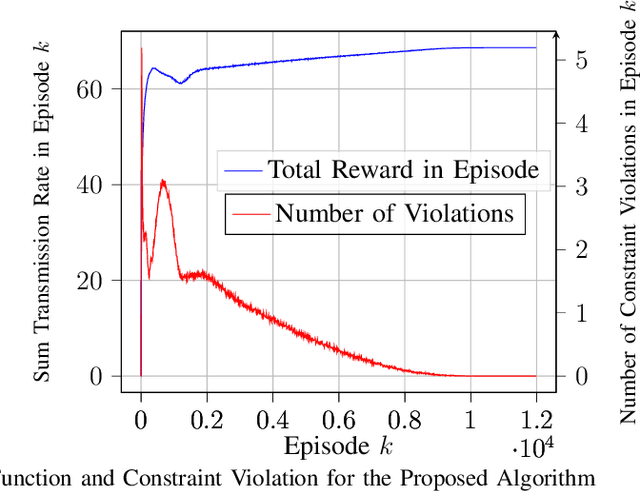
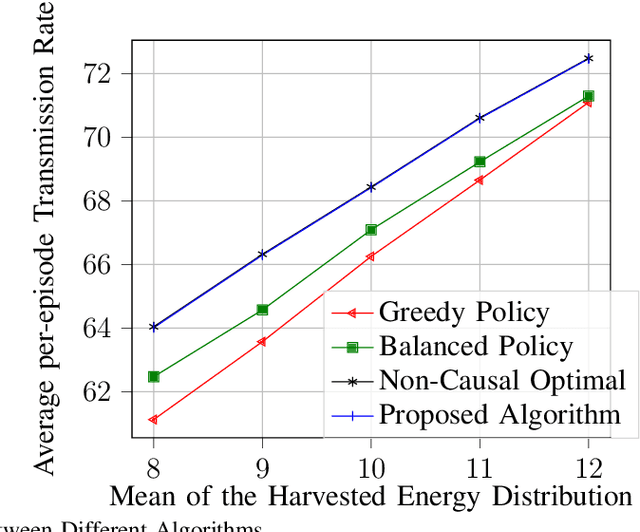
In the optimization of dynamic systems, the variables typically have constraints. Such problems can be modeled as a constrained Markov Decision Process (MDP). This paper considers a model-free approach to the problem, where the transition probabilities are not known. In the presence of peak constraints, the agent has to choose the policy to maximize the long-term average reward as well as satisfy the constraints at each time. We propose modifications to the standard Q-learning problem for unconstrained optimization to come up with an algorithm with peak constraints. The proposed algorithm is shown to achieve $O(T^{1/2+\gamma})$ regret bound for the obtained reward, and $O(T^{1-\gamma})$ regret bound for the constraint violation for any $\gamma \in(0,1/2)$ and time-horizon $T$. We note that these are the first results on regret analysis for constrained MDP, where the transition problems are not known apriori. We demonstrate the proposed algorithm on an energy harvesting problem where it outperforms state-of-the-art and performs close to the theoretical upper bound of the studied optimization problem.