 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Pattern Detection via Template Matching and Regression
Aug 25, 2025



We address the problem of few-shot pattern detection, which aims to detect all instances of a given pattern, typically represented by a few exemplars, from an input image. Although similar problems have been studied in few-shot object counting and detection (FSCD), previous methods and their benchmarks have narrowed patterns of interest to object categories and often fail to localize non-object patterns. In this work, we propose a simple yet effective detector based on template matching and regression, dubbed TMR. While previous FSCD methods typically represent target exemplars as spatially collapsed prototypes and lose structural information, we revisit classic template matching and regression. It effectively preserves and leverages the spatial layout of exemplars through a minimalistic structure with a small number of learnable convolutional or projection layers on top of a frozen backbone We also introduce a new dataset, dubbed RPINE, which covers a wider range of patterns than existing object-centric datasets. Our method outperforms the state-of-the-art methods on the three benchmarks, RPINE, FSCD-147, and FSCD-LVIS, and demonstrates strong generalization in cross-dataset evaluation.
Affogato: Learning Open-Vocabulary Affordance Grounding with Automated Data Generation at Scale
Jun 13, 2025Affordance grounding-localizing object regions based on natural language descriptions of interactions-is a critical challenge for enabling intelligent agents to understand and interact with their environments. However, this task remains challenging due to the need for fine-grained part-level localization, the ambiguity arising from multiple valid interaction regions, and the scarcity of large-scale datasets. In this work, we introduce Affogato, a large-scale benchmark comprising 150K instances, annotated with open-vocabulary text descriptions and corresponding 3D affordance heatmaps across a diverse set of objects and interactions. Building on this benchmark, we develop simple yet effective vision-language models that leverage pretrained part-aware vision backbones and a text-conditional heatmap decoder. Our models trained with the Affogato dataset achieve promising performance on the existing 2D and 3D benchmarks, and notably, exhibit effectiveness in open-vocabulary cross-domain generalization. The Affogato dataset is shared in public: https://huggingface.co/datasets/project-affogato/affogato
Memory-Modular Classification: Learning to Generalize with Memory Replacement
Apr 08, 2025We propose a novel memory-modular learner for image classification that separates knowledge memorization from reasoning. Our model enables effective generalization to new classes by simply replacing the memory contents, without the need for model retraining. Unlike traditional models that encode both world knowledge and task-specific skills into their weights during training, our model stores knowledge in the external memory of web-crawled image and text data. At inference time, the model dynamically selects relevant content from the memory based on the input image, allowing it to adapt to arbitrary classes by simply replacing the memory contents. The key differentiator that our learner meta-learns to perform classification tasks with noisy web data from unseen classes, resulting in robust performance across various classification scenarios. Experimental results demonstrate the promising performance and versatility of our approach in handling diverse classification tasks, including zero-shot/few-shot classification of unseen classes, fine-grained classification, and class-incremental classification.
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Dec 20, 2024



Self-supervised visual foundation models produce powerful embeddings that achieve remarkable performance on a wide range of downstream tasks. However, unlike vision-language models such as CLIP, self-supervised visual features are not readily aligned with language, hindering their adoption in open-vocabulary tasks. Our method, named dino.txt, unlocks this new ability for DINOv2, a widely used self-supervised visual encoder. We build upon the LiT training strategy, which trains a text encoder to align with a frozen vision model but leads to unsatisfactory results on dense tasks. We propose several key ingredients to improve performance on both global and dense tasks, such as concatenating the [CLS] token with the patch average to train the alignment and curating data using both text and image modalities. With these, we successfully train a CLIP-like model with only a fraction of the computational cost compared to CLIP while achieving state-of-the-art results in zero-shot classification and open-vocabulary semantic segmentation.
In Defense of Lazy Visual Grounding for Open-Vocabulary Semantic Segmentation
Aug 09, 2024We present lazy visual grounding, a two-stage approach of unsupervised object mask discovery followed by object grounding, for open-vocabulary semantic segmentation. Plenty of the previous art casts this task as pixel-to-text classification without object-level comprehension, leveraging the image-to-text classification capability of pretrained vision-and-language models. We argue that visual objects are distinguishable without the prior text information as segmentation is essentially a vision task. Lazy visual grounding first discovers object masks covering an image with iterative Normalized cuts and then later assigns text on the discovered objects in a late interaction manner. Our model requires no additional training yet shows great performance on five public datasets: Pascal VOC, Pascal Context, COCO-object, COCO-stuff, and ADE 20K. Especially, the visually appealing segmentation results demonstrate the model capability to localize objects precisely. Paper homepage: https://cvlab.postech.ac.kr/research/lazygrounding
A Flexible 2.5D Medical Image Segmentation Approach with In-Slice and Cross-Slice Attention
Apr 30, 2024



Deep learning has become the de facto method for medical image segmentation, with 3D segmentation models excelling in capturing complex 3D structures and 2D models offering high computational efficiency. However, segmenting 2.5D images, which have high in-plane but low through-plane resolution, is a relatively unexplored challenge. While applying 2D models to individual slices of a 2.5D image is feasible, it fails to capture the spatial relationships between slices. On the other hand, 3D models face challenges such as resolution inconsistencies in 2.5D images, along with computational complexity and susceptibility to overfitting when trained with limited data. In this context, 2.5D models, which capture inter-slice correlations using only 2D neural networks, emerge as a promising solution due to their reduced computational demand and simplicity in implementation. In this paper, we introduce CSA-Net, a flexible 2.5D segmentation model capable of processing 2.5D images with an arbitrary number of slices through an innovative Cross-Slice Attention (CSA) module. This module uses the cross-slice attention mechanism to effectively capture 3D spatial information by learning long-range dependencies between the center slice (for segmentation) and its neighboring slices. Moreover, CSA-Net utilizes the self-attention mechanism to understand correlations among pixels within the center slice. We evaluated CSA-Net on three 2.5D segmentation tasks: (1) multi-class brain MRI segmentation, (2) binary prostate MRI segmentation, and (3) multi-class prostate MRI segmentation. CSA-Net outperformed leading 2D and 2.5D segmentation methods across all three tasks, demonstrating its efficacy and superiority. Our code is publicly available at https://github.com/mirthAI/CSA-Net.
Contrastive Mean-Shift Learning for Generalized Category Discovery
Apr 15, 2024



We address the problem of generalized category discovery (GCD) that aims to partition a partially labeled collection of images; only a small part of the collection is labeled and the total number of target classes is unknown. To address this generalized image clustering problem, we revisit the mean-shift algorithm, i.e., a classic, powerful technique for mode seeking, and incorporate it into a contrastive learning framework. The proposed method, dubbed Contrastive Mean-Shift (CMS) learning, trains an image encoder to produce representations with better clustering properties by an iterative process of mean shift and contrastive update. Experiments demonstrate that our method, both in settings with and without the total number of clusters being known, achieves state-of-the-art performance on six public GCD benchmarks without bells and whistles.
Distilling Self-Supervised Vision Transformers for Weakly-Supervised Few-Shot Classification & Segmentation
Jul 07, 2023



We address the task of weakly-supervised few-shot image classification and segmentation, by leveraging a Vision Transformer (ViT) pretrained with self-supervision. Our proposed method takes token representations from the self-supervised ViT and leverages their correlations, via self-attention, to produce classification and segmentation predictions through separate task heads. Our model is able to effectively learn to perform classification and segmentation in the absence of pixel-level labels during training, using only image-level labels. To do this it uses attention maps, created from tokens generated by the self-supervised ViT backbone, as pixel-level pseudo-labels. We also explore a practical setup with ``mixed" supervision, where a small number of training images contains ground-truth pixel-level labels and the remaining images have only image-level labels. For this mixed setup, we propose to improve the pseudo-labels using a pseudo-label enhancer that was trained using the available ground-truth pixel-level labels. Experiments on Pascal-5i and COCO-20i demonstrate significant performance gains in a variety of supervision settings, and in particular when little-to-no pixel-level labels are available.
* Accepted at CVPR 2023
Few-shot Metric Learning: Online Adaptation of Embedding for Retrieval
Nov 14, 2022Metric learning aims to build a distance metric typically by learning an effective embedding function that maps similar objects into nearby points in its embedding space. Despite recent advances in deep metric learning, it remains challenging for the learned metric to generalize to unseen classes with a substantial domain gap. To tackle the issue, we explore a new problem of few-shot metric learning that aims to adapt the embedding function to the target domain with only a few annotated data. We introduce three few-shot metric learning baselines and propose the Channel-Rectifier Meta-Learning (CRML), which effectively adapts the metric space online by adjusting channels of intermediate layers. Experimental analyses on miniImageNet, CUB-200-2011, MPII, as well as a new dataset, miniDeepFashion, demonstrate that our method consistently improves the learned metric by adapting it to target classes and achieves a greater gain in image retrieval when the domain gap from the source classes is larger.
Integrative Few-Shot Learning for Classification and Segmentation
Mar 29, 2022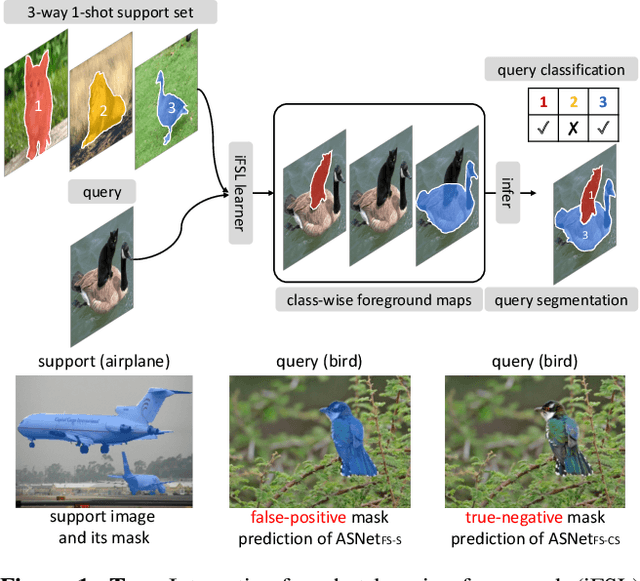
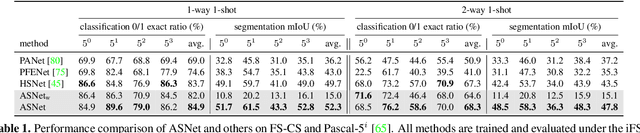
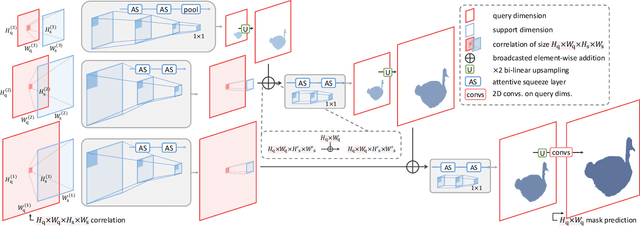
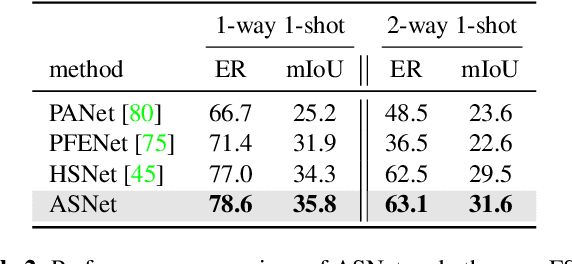
We introduce the integrative task of few-shot classification and segmentation (FS-CS) that aims to both classify and segment target objects in a query image when the target classes are given with a few examples. This task combines two conventional few-shot learning problems, few-shot classification and segmentation. FS-CS generalizes them to more realistic episodes with arbitrary image pairs, where each target class may or may not be present in the query. To address the task, we propose the integrative few-shot learning (iFSL) framework for FS-CS, which trains a learner to construct class-wise foreground maps for multi-label classification and pixel-wise segmentation. We also develop an effective iFSL model, attentive squeeze network (ASNet), that leverages deep semantic correlation and global self-attention to produce reliable foreground maps. In experiments, the proposed method shows promising performance on the FS-CS task and also achieves the state of the art on standard few-shot segmentation benchmarks.